前几篇回答的是“大模型如何工作”和“为什么行业会从基础模型走向 RAG、Workflow 与 Agent”;这一篇更进一步,试图回答一个更接近现实世界的问题:当模型能力逐渐从实验室进入组织流程和商业系统后,产业真正变化的是什么,未来又会沿着什么方向展开。为了方便阅读和图谱,这里先贴一份产业图谱。
图 1AI产业链全景图
本文围绕以下几个判断展开:
一、产业化已经进入第二阶段
如果把过去三年大模型产业的发展分成两个阶段,第一阶段的关键词是“能力证明”,第二阶段的关键词则是“现实嵌入”。前一阶段,行业最关心的是模型是否足够强,是否能在写作、编程、问答和推理上表现出令人惊讶的跃迁(如Anthropic的爆发);后一阶段,产业更关心的是模型能否稳定接入真实数据、真实权限、真实业务流程,以及在可控成本下持续运行。
值得一提的是,产业的进展有“快”和“慢”两个变量。模型的能力已经从“展示能力”转向“嵌入系统”。当模型第一次证明自己具备通用语言能力时,它带来的冲击主要是认知层面的;而当模型开始进入搜索、客服、办公、研发、财务、法务和工业流程时,它带来的冲击开始变成结构性的。后者比前者慢,但更深。
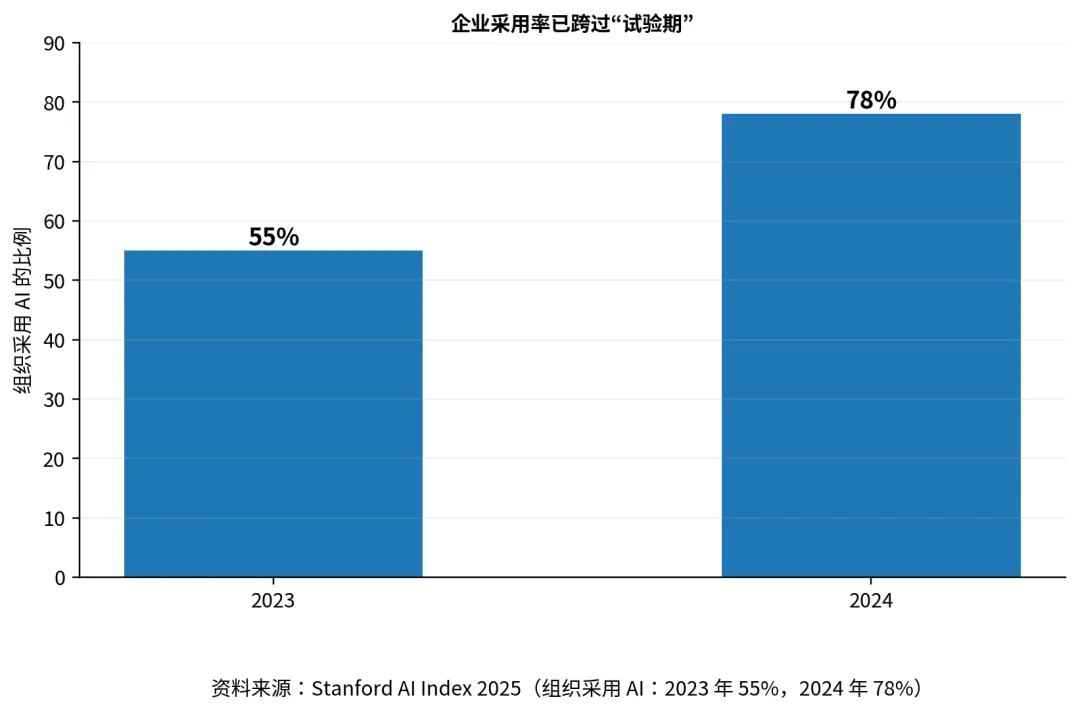
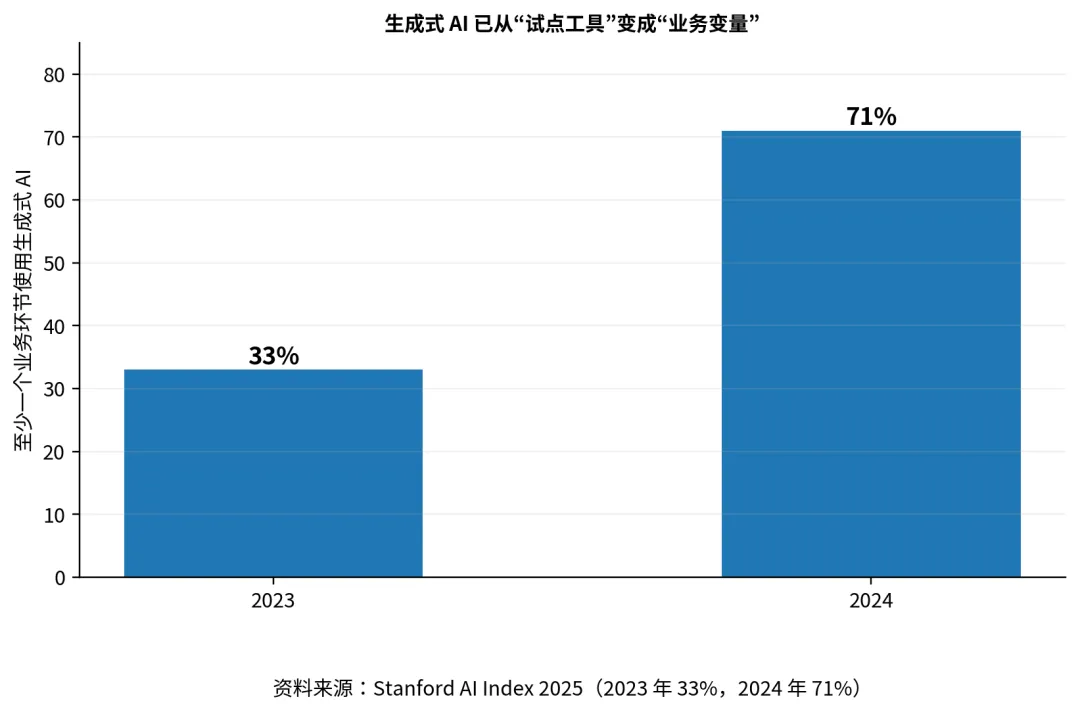
图 2企业采用率已跨过“试验期”图 3生成式 AI 在业务环节中的使用快速扩展Stanford AI Index 2025 给出的数字很有代表性:2024 年,有 78% 的组织报告在使用 AI,而 2023 年这一数字还是 55%;使用生成式 AI 的组织比例也从 33% 跳升到 71%。这些数字的重要性不在于“增长很快”本身,而在于它们表明 AI 已跨过一种门槛:它不再只是创新部门的试验品,而开始成为组织层面必须面对的变量。
二、泡沫与革命同时成立
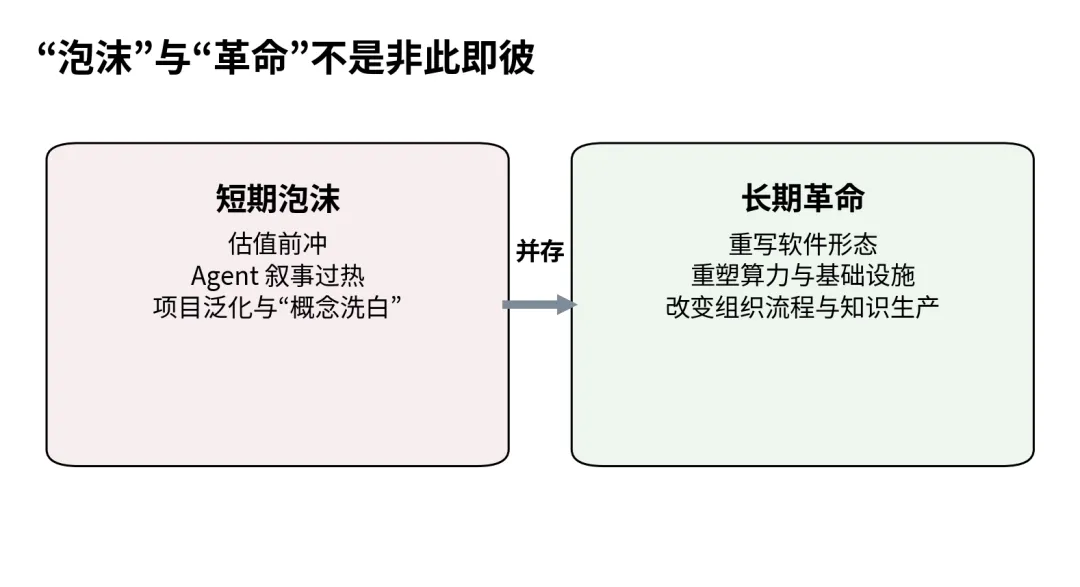
围绕 AI 的社会讨论,经常摇摆在两个极端之间。一种说法是,这不过是一轮被资本和媒体放大的泡沫;另一种说法是,这将像电气化、互联网和移动通信那样,成为一轮长期的技术产业革命。若从不同时间尺度看,这两种说法其实并不矛盾。
短期看,泡沫成分确实存在。估值与叙事往往先于兑现,Agent 的概念外延被不断拉宽,很多演示型项目把“能做出一个 demo”误当成“已经具备交付能力”。有专家预计,到 2027 年,超过 40% 的 agentic AI 项目可能被取消,这恰恰说明局部泡沫与概念洗白并非边角现象,而是产业早期扩张的常态。
但若把时间尺度拉长,革命性的部分同样明显。AI 的意义并不只在于让某些问答更聪明,而在于它把“语言、知识、推理与指令执行”第一次以通用接口的形式交给了软件系统。这会改写三个层面:第一,软件交互从菜单与表单走向自然语言与工作流协同;第二,算力需求从图形计算转向大规模推理与数据中心重构;第三,组织中大量知识型工作将被重新切分、自动化与再分工。
因此,更成熟的判断不是在“泡沫”与“革命”之间二选一,而是承认它们同时存在:短期泡沫是新产业前冲时的表层噪音,长期革命则是生产函数被改变后的深层趋势。
图 4大模型既伴随泡沫化叙事,也正在形成长期的产业重构。三、使用者先形成共识,而社会反应仍然滞后
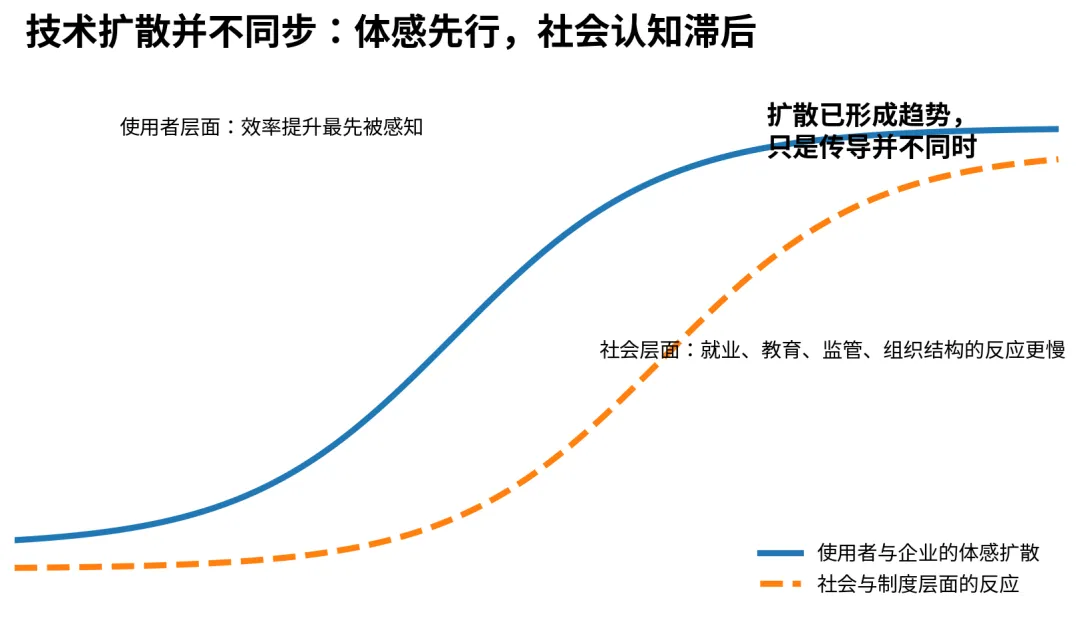
图 5技术扩散并不同步:体感先行,制度与社会反应滞后。从一线使用者视角看,大模型对效率、信息获取、内容生产和研发方式的影响,已经很难再被简单否认。写作、编程、翻译、研究、客服、知识问答、文档归纳和流程协同,这些领域都已经出现明显的边际改进。直接使用工具的人最先感受到红利,因此他们的共识往往形成得最快。
但社会层面的反应之所以滞后,并不是因为趋势不存在,而是因为社会系统比技术系统更慢。教育体系、组织架构、劳动市场、法律治理、预算流程和公共认知,都需要比个人使用更长的调整周期。技术扩散先进入个体,再进入团队,再进入企业流程,最后才会表现为宏观层面的制度变化。很多时候,社会承认某一轮技术革命,往往不是在技术初现之时,而是在其深度嵌入生产系统之后。
四、主战场正在转向系统能力与基础设施
图 6从应用层到底层机柜,推理经济学是一条完整的链。大模型下半场,KV Cache、连续批处理、量化、MoE、服务调度、显存管理和机柜级基础设施,会从工程细节上升为商业主变量。换句话说,成本效益原则被放到了更优先考虑的位置上。
过去,行业更愿意把注意力放在参数量、训练数据量和 benchmark 排名上;现在,行业越来越清楚地看到,单位 token 成本、首 token 延迟、吞吐量、并发能力、长上下文的显存压力和总拥有成本,才决定模型能否进入广泛业务场景。训练阶段再昂贵,也可能被视为一次性资本开支;而推理阶段的成本,却会随着每一次调用、每一条工作流、每一个在线用户持续地累积。
因此,大模型产业竞赛的重心来到了“谁能把模型在推理侧做得更经济、更稳定、更可扩展”上。
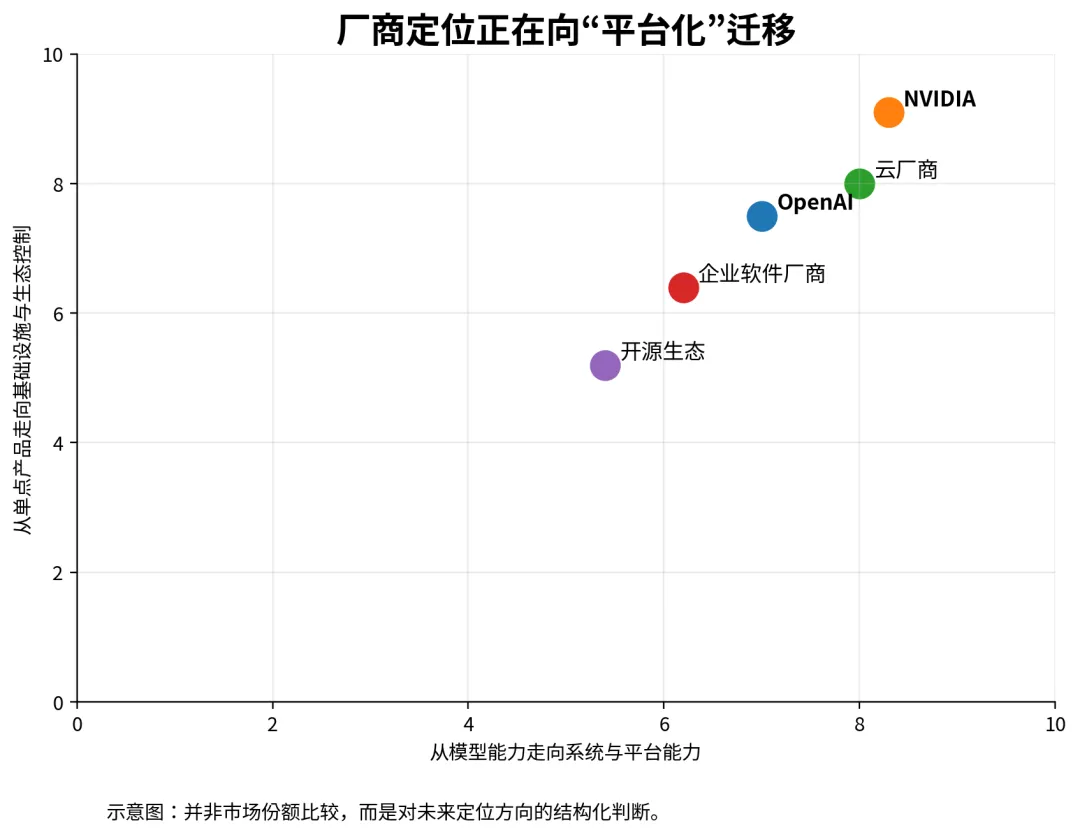
图 7厂商定位正在从单点产品转向平台、基础设施与生态控制。产业重心的迁移,也迫使关键厂商重新定义自己。OpenAI 已越来越不像一个单纯的模型研究机构,而更像一个“通用 AI 平台 + 企业工作流入口 + 应用生态核心”。它一方面继续推进前沿模型,另一方面则持续将 ChatGPT 企业版、API、编程助手和企业合作网络向更深的工作流层推进。2025 年的企业报告更直接给出了这一信号:企业使用不再停留在零散问答上,而是朝着更深的流程集成演进。
NVIDIA 的转变同样典型。它已经不再只是以 GPU 厂商的身份出现,而是在把自己重新塑造成一家面向 AI 工厂时代的基础设施平台公司。无论是 Vera Rubin 平台、DSX AI Factory 参考设计,还是围绕机柜、互联、网络、BlueField 与数字孪生的整体布局,其含义都很明确:未来卖出的不仅是算力芯片,更是一套可规模化部署的 AI 生产系统。厂商关注点从“峰值算力”转向“推理时代的系统吞吐、部署效率和总成本”,这本身就是产业阶段切换的信号。
云厂商和企业软件厂商的定位也在变化。前者试图把模型、推理、数据和权限体系封装成一体化能力;后者则试图把 AI 直接嵌入用户已有工作流,借助入口优势控制使用频次、反馈数据和商业化触点。谁更靠近工作流、谁更实现数据闭环,谁就更可能在未来拥有稳定的议价能力。
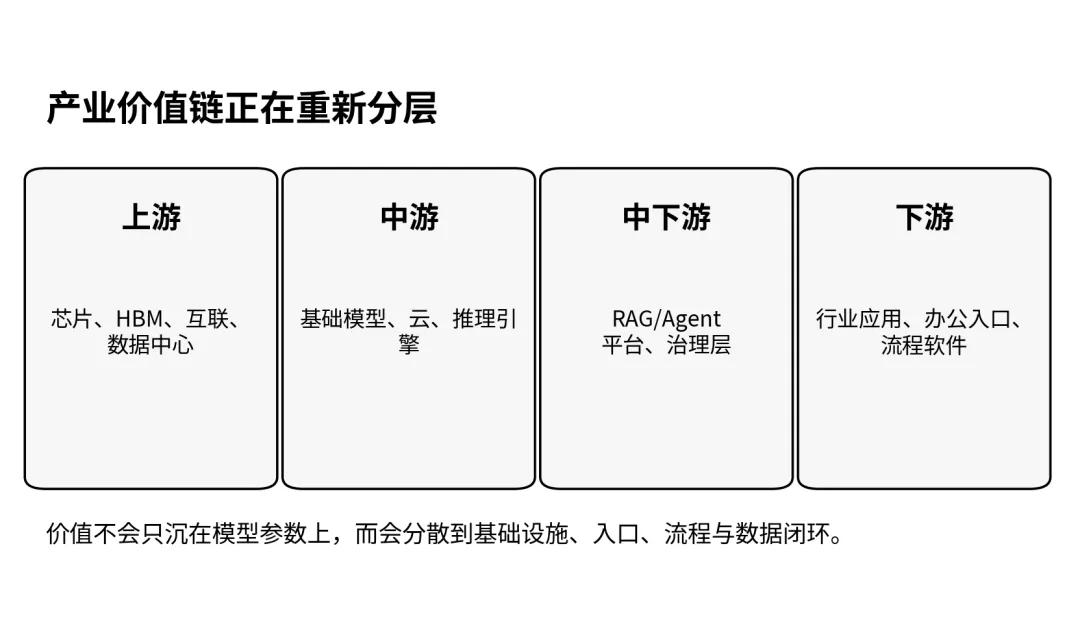
五、产业价值链将重塑
图 8大模型价值链的重心,正在向基础设施、入口和流程层扩散。产业史一再表明,能力并不等于壁垒。当基础模型能力不断提升时,市场容易产生一种误解:似乎未来的全部价值都会沉在模型参数本身上。模型能力当然重要,它决定了系统的能力上限;但当模型能力逐渐扩散、开源生态追赶、闭源模型平台化后,真正可持续的价值会更多地沉到几个环节上。
第一类是推理基础设施。高性能 GPU、HBM、互联、机柜级设计、电力与散热,是大模型产业化最重的资本层。它不是所有公司都能跨越的门槛。
第二类是工作流入口。谁掌握高频的办公入口、开发入口、客服入口和行业软件入口,谁就更容易控制使用习惯与反馈闭环。
第三类是数据与流程。并不是“有数据”就一定有壁垒,而是“能将高质量私有数据、反馈信号与具体流程绑定起来”才构成壁垒。
第四类是治理与集成能力。大模型进入组织后,权限、审计、监控、回退和责任边界都变成必需品。
六、未来:三条主线与三种分化
对未来五年的判断,最忌讳的是写成“无条件乐观”的趋势清单。更稳妥的方式,是承认行业会沿着几条主线继续推进,同时在一些关键位置上发生分化。
第一条主线,是推理成本会继续下降,但不会自动带来商业成功。更好的推理芯片、更成熟的服务栈、更深的量化和更合理的模型结构,会让单位成本不断下降;但价值落地仍然取决于场景选择、工作流重构和组织接纳。
第二条主线,是 Agent 会继续升温,但真正大规模落地的,将主要是 workflow-agent 与人机协同形态,而不是完全自治的代理。
第三条主线,是多模态与实时交互会持续扩张,但最先释放价值的,仍将是高频、高投入产出比、可嵌入的现有流程场景。
其一,模型层与应用层分化。模型越来越强,但应用并不会因此自动提升性能、体验更好,只有与入口和流程绑定的应用才更稳、建立壁垒。
其二,Agent 分化为概念型与可交付型 。前者擅长展示,后者擅长交付。
其三,社会认知与企业实践分化。实践领先,认知滞后。一线组织中的技术渗透将快速推进,宏观层面的认知、教育和制度转身可能稍慢。
图 9未来五年的主要演化方向,不是单线推进,而是主线与分化并存。九、AI 正在以基础设施的方式进入现实世界
AI 不再只是一个“看上去很聪明”的工具,而正在变成一种能够嵌入组织流程、重构成本曲线、改写基础设施需求的现实系统。它不会以一次性颠覆的方式改变世界,而更可能以持续渗透、逐步替换、不断重组的方式进入现实经济。
因此,对今天的大模型产业,最成熟的判断既不是简单乐观,也不是简单怀疑。它既有泡沫,也有革命;既有过热,也有深层重构;既会经历失败项目、概念证伪和估值波动,也会形成真正的新基础设施、新软件形态和新的产业分工。真正值得关注的,不只是下一个更强模型,而是模型如何被装进现实世界,如何与工作流、数据、基础设施和组织能力相互结合。谁更早看清这一点,谁就更接近未来。