Vulkan 学习笔记(十三) 着色器模块(Shader modules)
- 2026-04-25 01:53:20
Vulkan 学习笔记(十三) 着色器模块(Shader modules)
介绍
与早期API不同,Vulkan中的着色器代码必须以字节码格式指定,而不是像GLSL和HLSL这样人类可读的语法。这种字节码格式称为SPIR-V,设计用于Vulkan和OpenCL(都是Khronos的API)。这是一种可以编写图形和计算着色器的格式,但在本教程中,我们将专注于Vulkan图形管线中使用的着色器。
💡 术语解释:字节码 vs 人类可读代码
想象你是一位厨师,有两种食谱选择:一种是用只有专业厨师才懂的速记符号写的(字节码),另一种是用普通语言写的详细步骤(GLSL/HLSL)。
字节码的优势在于:不同国家的厨师(GPU厂商)可能对"适量盐"这种模糊描述有不同理解,但对精确的"5克盐"(字节码指令)不会有歧义。SPIR-V就像一份精确到毫克的国际标准食谱,确保你的"图形大餐"在任何厨房(GPU)都能以相同方式烹饪!
这解决了历史上GLSL的"方言问题"——某些GPU厂商对标准的"创造性解释",导致同样的着色器在不同显卡上表现不一致,甚至直接报错。SPIR-V让Vulkan真正实现了"一次编写,到处运行"的承诺。
使用字节码格式的优势在于,GPU厂商编写的将着色器代码转换为原生代码的编译器会显著简化。历史表明,使用GLSL这样人类可读的语法时,某些GPU厂商对标准的解释相当灵活。如果你恰好为其中一个厂商的GPU编写了非平凡的着色器,那么你可能会面临其他厂商的驱动程序因语法错误而拒绝你的代码的风险,或者更糟的是,由于编译器bug,你的着色器运行方式完全不同。希望使用SPIR-V这样直接的字节码格式可以避免这种情况。
然而,这并不意味着我们需要手动编写这些字节码。Khronos已经发布了自己的供应商无关编译器,可以将GLSL编译为SPIR-V。这个编译器旨在验证你的着色器代码是否完全符合标准,并生成一个可以随程序一起发布的SPIR-V二进制文件。你也可以将此编译器作为库包含在内,以在运行时生成SPIR-V,但在本教程中我们不会这样做。
虽然我们可以直接通过glslangValidator.exe使用这个编译器,但我们将使用Google的glslc.exe。glslc的优势在于它使用与GCC和Clang等知名编译器相同的参数格式,并包含一些额外功能,比如包含文件。它们都已经包含在Vulkan SDK中,因此你不需要额外下载任何东西。
GLSL是一种具有C风格语法的着色语言。用它编写的程序有一个main函数,该函数为每个对象调用。GLSL不使用参数作为输入和返回值作为输出,而是使用全局变量来处理输入和输出。该语言包含许多有助于图形编程的功能,比如内置的向量和矩阵原语。它包含用于叉积、矩阵-向量乘积和围绕向量反射等操作的函数。向量类型称为vec,后面跟着一个表示元素数量的数字。例如,3D位置将存储在vec3中。
💡 术语解释:着色器入口点 (Shader Entrypoints)
想象你有一个多功能工具箱,里面装满了各种工具(函数)。入口点就像是工具箱的"主开关"——当你按下它时,特定的工具组合会启动。
在Vulkan中,一个着色器模块可以包含多个函数,但你需要指定哪个函数作为起点(通常是
main)。这就像一个瑞士军刀:你可以有开瓶器、小刀、剪刀等功能,但每次只能选择一个主要功能来使用。通过指定不同的入口点,你可以从同一个着色器文件中创建不同的行为,而无需复制代码——就像用同一个工具箱完成不同的任务!
可以使用.x等成员访问单个组件,但也可以同时从多个组件创建新向量。例如,表达式vec3(1.0, 2.0, 3.0).xy将生成vec2。向量的构造函数也可以采用向量对象和标量值的组合。例如,vec3可以用vec3(vec2(1.0, 2.0), 3.0)构造。
正如前一章提到的,我们需要编写顶点着色器和片段着色器才能在屏幕上显示三角形。接下来的两节将涵盖这两个着色器的GLSL代码,之后我将向你展示如何生成两个SPIR-V二进制文件并将它们加载到程序中。
顶点着色器
顶点着色器处理每个传入的顶点。它接收属性作为输入,如模型空间位置、颜色、法线和纹理坐标。输出是裁剪坐标中的最终位置以及需要传递给片段着色器的属性,如颜色和纹理坐标。这些值随后将由光栅化器在片段之间进行插值,以产生平滑的渐变。
裁剪坐标是顶点着色器中的四维向量,随后通过将整个向量除以其最后一个分量转换为归一化设备坐标。这些归一化设备坐标是齐次坐标,将帧缓冲区映射到[-1, 1] × [-1, 1]的坐标系,如下所示:
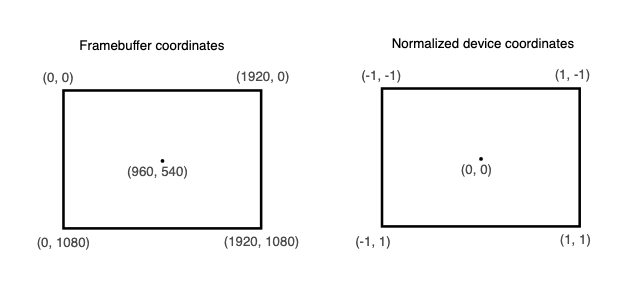
如果你之前接触过计算机图形学,应该已经熟悉这些。如果你之前使用过OpenGL,那么你会注意到Y坐标的符号现在翻转了。Z坐标现在使用与Direct3D相同的范围,从0到1。
对于我们的第一个三角形,我们不会应用任何变换,而是直接将三个顶点的位置指定为归一化设备坐标,以创建以下形状:
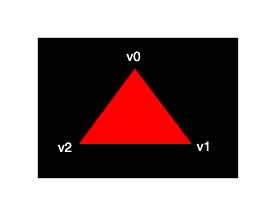
我们可以通过在顶点着色器中将它们作为裁剪坐标输出,并将最后一个分量设置为1,直接输出归一化设备坐标。这样,将裁剪坐标转换为归一化设备坐标的除法操作不会改变任何内容。
通常这些坐标会存储在顶点缓冲区中,但在Vulkan中创建顶点缓冲区并用数据填充它并不简单。因此,我决定将此推迟到我们看到三角形出现在屏幕上的满足感之后。在此期间,我们将做一些不太正统的事情:将坐标直接包含在顶点着色器中。代码如下:
#version 450
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
}main函数为每个顶点调用。内置变量gl_VertexIndex包含当前顶点的索引。这通常是顶点缓冲区中的索引,但在我们的情况下,它将是硬编码顶点数据数组中的索引。从着色器中的常量数组访问每个顶点的位置,并与虚拟的z和w分量组合,以生成裁剪坐标中的位置。内置变量gl_Position作为输出。
片段着色器
由顶点着色器的位置形成的三角形在屏幕上填充了一个区域,包含多个片段。片段着色器在这些片段上调用,为帧缓冲区(或多个帧缓冲区)生成颜色和深度。一个简单的片段着色器,为整个三角形输出红色颜色,如下所示:
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0, 0.0, 0.0, 1.0);
}main函数为每个片段调用,就像顶点着色器的main函数为每个顶点调用一样。GLSL中的颜色是4分量向量,R、G、B和alpha通道在[0, 1]范围内。与顶点着色器中的gl_Position不同,没有内置变量来为当前片段输出颜色。你必须为每个帧缓冲区指定自己的输出变量,其中layout(location = 0)修饰符指定了帧缓冲区的索引。红色颜色写入此outColor变量,该变量链接到索引0处的第一个(也是唯一的)帧缓冲区。
每顶点颜色
让整个三角形都是红色不是很有趣,下面这样的效果会不会好看很多?
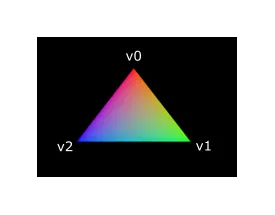
我们需要对两个着色器进行一些更改来实现这一点。首先,我们需要为三个顶点中的每一个指定不同的颜色。顶点着色器现在应该包含一个颜色数组,就像它对位置所做的那样:
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);现在我们只需要将这些每顶点颜色传递给片段着色器,以便它可以将它们的插值输出到帧缓冲区。在顶点着色器中添加颜色输出,并在main函数中写入它:
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}接下来,我们需要在片段着色器中添加匹配的输入:
layout(location = 0) in vec3 fragColor;
void main() {
outColor = vec4(fragColor, 1.0);
}输入变量不一定使用相同的名称,它们将通过location指令指定的索引链接在一起。main函数已被修改为输出颜色以及alpha值。如上图所示,fragColor的值将自动为三个顶点之间的片段进行插值,从而产生平滑的渐变。
编译着色器
在项目的根目录中创建一个名为shaders的目录,并将顶点着色器存储在名为shader.vert的文件中,将片段着色器存储在名为shader.frag的文件中。GLSL着色器没有官方扩展名,但这两个扩展名通常用于区分它们。
shader.vert的内容应为:
#version 450
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}而shader.frag的内容应为:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}我们现在将使用glslc程序将这些编译为SPIR-V字节码。
💡 术语解释:glslc 编译器
想象你有一个神奇的翻译器,能把莎士比亚的英文剧本(GLSL代码)翻译成只有演员(GPU)才能理解的表演指令(SPIR-V字节码)。
glslc就是这样一个翻译器,而且它特别友好——它使用你熟悉的GCC/Clang风格的命令行参数。为什么不用更直接的
glslangValidator?因为glslc就像是为开发者量身定制的"智能翻译器":
• 它理解 #include指令,让你可以组织复杂的着色器代码• 它的错误信息更友好,像是一位耐心的老师而不是严厉的考官 • 它支持标准的编译器工作流程,让你感觉就像在编译C++代码一样 这个工具是Vulkan SDK的"瑞士军刀"之一,专为让开发者生活更轻松而设计!
Windows
创建一个包含以下内容的compile.bat文件:
C:/VulkanSDK/x.x.x.x/Bin/glslc.exe shader.vert -o vert.spv
C:/VulkanSDK/x.x.x.x/Bin/glslc.exe shader.frag -o frag.spv
pause将glslc.exe的路径替换为你安装Vulkan SDK的路径。双击文件运行它。
Linux
创建一个包含以下内容的compile.sh文件:
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.vert -o vert.spv
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.frag -o frag.spv将glslc的路径替换为你安装Vulkan SDK的路径。使用chmod +x compile.sh使脚本可执行,然后运行它。
这两个命令告诉编译器读取GLSL源文件,并使用-o(输出)标志输出SPIR-V字节码文件。
如果你的着色器包含语法错误,编译器会告诉你行号和问题,正如你所期望的。尝试省略一个分号,例如,然后再次运行编译脚本。还可以尝试不带任何参数运行编译器,以查看它支持哪些标志。例如,它也可以将字节码输出为人类可读的格式,这样你就可以准确地看到你的着色器在做什么,以及在此阶段应用了哪些优化。
在命令行上编译着色器是最直接的选择之一,也是我们在本教程中将使用的选项,但也可以直接从你自己的代码中编译着色器。Vulkan SDK包含libshaderc,这是一个库,可以在程序内将GLSL代码编译为SPIR-V。
加载着色器
现在我们有了生成SPIR-V着色器的方法,是时候将它们加载到我们的程序中,以便在某个时候将它们插入图形管线。我们首先编写一个简单的辅助函数,从文件中加载二进制数据。
#include <fstream>
...
static std::vector<char> readFile(const std::string& filename){
std::ifstream file(filename, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
throw std::runtime_error("failed to open file!");
}
}readFile函数将读取指定文件中的所有字节,并将它们返回到由std::vector管理的字节数组中。我们首先使用两个标志打开文件:
• ate: 从文件末尾开始读取• binary: 将文件作为二进制文件读取(避免文本转换)
从文件末尾开始读取的优势在于,我们可以使用读取位置来确定文件大小并分配缓冲区:
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize);之后,我们可以回溯到文件开头,并一次性读取所有字节:
file.seekg(0);
file.read(buffer.data(), fileSize);最后关闭文件并返回字节:
file.close();
return buffer;我们现在将从createGraphicsPipeline中调用此函数,以加载两个着色器的字节码:
void createGraphicsPipeline(){
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
}通过打印缓冲区的大小并检查它们是否与实际文件大小(以字节为单位)匹配,确保着色器正确加载。注意,代码不需要以空字符终止,因为它是二进制代码,我们稍后会明确指定其大小。
创建着色器模块
在将代码传递给管线之前,我们必须将其包装在VkShaderModule对象中。让我们创建一个辅助函数createShaderModule来完成此操作。
VkShaderModule createShaderModule(const std::vector<char>& code){
}该函数将使用字节码的缓冲区作为参数,并从中创建VkShaderModule。
创建着色器模块很简单,我们只需要指定指向字节码缓冲区的指针及其长度。这些信息在VkShaderModuleCreateInfo结构中指定。唯一需要注意的是,字节码的大小以字节为单位指定,但字节码指针是uint32_t指针而不是char指针。因此,我们需要使用reinterpret_cast转换指针,如下所示。当你执行这样的转换时,还需要确保数据满足uint32_t的对齐要求。幸运的是,数据存储在std::vector中,其中默认分配器已经确保数据满足最坏情况的对齐要求。
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = code.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data());然后,可以通过调用vkCreateShaderModule创建VkShaderModule:
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("failed to create shader module!");
}参数与之前对象创建函数的参数相同:逻辑设备、指向创建信息结构的指针、可选的指向自定义分配器的指针和句柄输出变量。创建着色器模块后,可以立即释放包含代码的缓冲区。不要忘记返回创建的着色器模块:
return shaderModule;💡 术语解释:着色器模块生命周期
想象你是一个舞台剧的导演,着色器模块就像是演员的剧本。一旦演员(GPU管线)记住了台词(编译成了机器码),剧本本身就可以被收起来了!
Vulkan的设计非常"环保"——着色器模块只是SPIR-V字节码的薄包装器。真正的编译和链接(将SPIR-V转换为GPU机器码)发生在创建图形管线时。这意味着一旦管线创建完成,着色器模块就可以被销毁,因为GPU已经把"台词"记在心里了!
这就是为什么我们将着色器模块作为局部变量而不是类成员——它们只是创建管线的"一次性工具",用完就可以安全丢弃,不会浪费宝贵的内存资源。
着色器模块只是我们之前从文件加载的着色器字节码及其定义的函数的薄包装器。SPIR-V字节码到机器码的编译和链接,以供GPU执行,直到创建图形管线时才会发生。这意味着我们可以在管线创建完成后立即销毁着色器模块,这就是为什么我们将在createGraphicsPipeline函数中将它们作为局部变量,而不是类成员:
void createGraphicsPipeline(){
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
VkShaderModule vertShaderModule = createShaderModule(vertShaderCode);
VkShaderModule fragShaderModule = createShaderModule(fragShaderCode);然后,通过添加两个对vkDestroyShaderModule的调用来在函数末尾进行清理。本章中剩余的所有代码都将插入到这些行之前。
...
vkDestroyShaderModule(device, fragShaderModule, nullptr);
vkDestroyShaderModule(device, vertShaderModule, nullptr);
}着色器阶段创建
要实际使用着色器,我们需要通过VkPipelineShaderStageCreateInfo结构将它们分配给特定的管线阶段,作为实际管线创建过程的一部分。
我们将从填充顶点着色器的结构开始,同样在createGraphicsPipeline函数中。
VkPipelineShaderStageCreateInfo vertShaderStageInfo{};
vertShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
vertShaderStageInfo.stage = VK_SHADER_STAGE_VERTEX_BIT;第一步,除了强制性的sType成员外,是告诉Vulkan着色器将在哪个管线阶段使用。有一个枚举值对应前一章描述的每个可编程阶段。
vertShaderStageInfo.module = vertShaderModule;
vertShaderStageInfo.pName = "main";接下来的两个成员指定包含代码的着色器模块,以及要调用的函数,称为入口点。这意味着可以将多个片段着色器组合到单个着色器模块中,并使用不同的入口点来区分它们的行为。在本例中,我们将坚持使用标准的main。
还有一个(可选的)成员,pSpecializationInfo,我们这里不会使用,但值得讨论。它允许你为着色器常量指定值。你可以使用单个着色器模块,通过为其中使用的常量指定不同的值,在管线创建时配置其行为。这比在渲染时使用变量配置着色器更高效,因为编译器可以进行优化,例如消除依赖于这些值的if语句。如果你没有任何这样的常量,那么可以将成员设置为nullptr,我们的结构初始化会自动完成此操作。
💡 术语解释:特殊化常量 (Specialization Constants)
想象你有一个多功能咖啡机,可以通过按不同的按钮来制作不同的饮品:美式咖啡、拿铁、卡布奇诺。特殊化常量就像是这些按钮——在"开机"(创建管线)时设置,而不是在"倒水"(渲染时)时调整。
在Vulkan中,特殊化常量让你可以在管线创建时"烘焙"配置值到着色器中。例如:
• 你可以有一个着色器模块,通过设置 MAX_LIGHTS=4或MAX_LIGHTS=8来支持不同数量的光源• 或者通过 USE_SHADOWS=true/USE_SHADOWS=false来启用/禁用阴影GPU驱动知道这些值在管线生命周期内不会改变,因此可以进行激进的优化:完全移除未使用的代码路径、简化数学运算、甚至重新组织内存访问模式。这就像咖啡机根据你选择的饮品类型,预先加热到最佳温度,而不是在每次倒水时都重新调整!
修改结构以适应片段着色器很简单:
VkPipelineShaderStageCreateInfo fragShaderStageInfo{};
fragShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
fragShaderStageInfo.stage = VK_SHADER_STAGE_FRAGMENT_BIT;
fragShaderStageInfo.module = fragShaderModule;
fragShaderStageInfo.pName = "main";最后,定义一个包含这两个结构体的数组,我们稍后将在实际管线创建步骤中引用它们。
VkPipelineShaderStageCreateInfo shaderStages[] = {vertShaderStageInfo, fragShaderStageInfo};描述管线的可编程阶段就是这些。在下一章中,我们将介绍固定功能阶段。
[C++ 代码]https://vulkan-tutorial.com/code/09_shader_modules.cpp

