大家好,我是AI小白,上节课我们学到了深度学习的入门,知道了什么是线性回归,今天我们将学习深度的学习的基本流程,下面是我的学习笔记,欢迎大家一起讨论、学习。上节课我们学到了loss函数的最小值的计算过程,下面我们以y = 2x^2为例,回顾一下线性回归的过程,如下:import torchimport torch.nn as nnimport torch.optim as optimdef train_linear_model(): # 固定随机种子确保可复现 torch.manual_seed(42) # 生成模拟数据:100个样本,13个特征,1个目标值 X = torch.randn(100, 13) Y = torch.randn(100, 1) # 线性层:输入13,输出1 linear_layer = nn.Linear(13, 1) # 损失函数与优化器 loss_func = nn.MSELoss() optimizer = optim.SGD(linear_layer.parameters(), lr=0.01) # 训练轮数 num_epochs = 1000 for epoch in range(num_epochs): optimizer.zero_grad() # 重置梯度 predictions = linear_layer(X) # 前向传播 loss = loss_func(predictions, Y) loss.backward() # 反向传播 optimizer.step() # 参数更新 # 可选:每200轮打印一次损失(不影响最终逻辑) if (epoch + 1) % 200 == 0: print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.6f}") # 输出模型参数 print("线性回归模型的权重:", linear_layer.weight) print("线性回归模型的偏置:", linear_layer.bias)if __name__ == "__main__": train_linear_model()
| |
| 正向传播的两副面孔: 训练时 —— 把X喂给model得到y_pred,同时自动构建计算图,记录每一步操作,链式求导铺路(比如h(g(f(x)))的导数 = f′g′h′)。 推理时 —— 只做正向计算,不建图,直接拿到 y_pred,轻量高效。 |
| |
| 只负责前向传播 forward,不负责后向传播 backward |
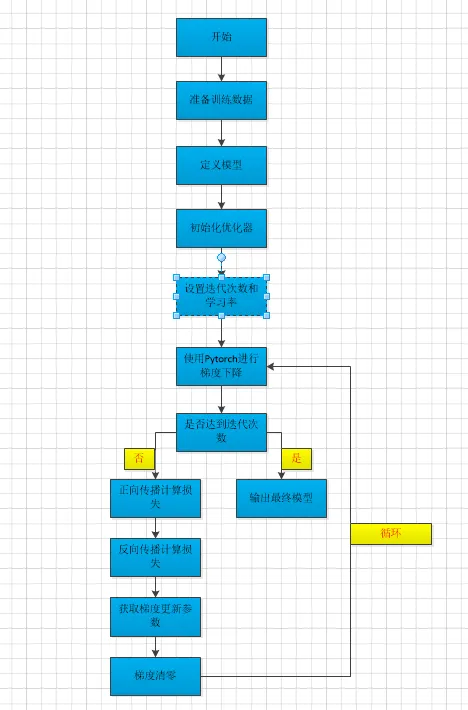
数据加载:从训练集中采样一个 mini-batch,包含样本特征 X 和标签 y。
前向传播:将 X 喂给模型 model,计算预测输出 y_pred。
损失评估:调用损失函数 loss = f(y_pred, y),得到当前 batch 的误差值。
反向传播:基于 loss 进行梯度回传,自动求出每个可训练参数(w, b)的梯度。
参数更新:优化器 optimizer 利用梯度下降法,沿负梯度方向更新参数。
梯度复位:优化器将模型参数的梯度清零,防止下次累加。
收敛判断:反复执行 1~6,直至达到预设迭代次数或 loss 低于阈值。
加载输入:读入一条(或一批)待预测的样本 X,它只包含特征,不含真实标签。
前向计算:让模型 model 对 X 进行一次正向传播,得到原始输出 y_pred。
结果翻译:根据任务需求对 y_pred 进行解析(例如:回归值取小数、分类取 argmax),最后将处理后的结果返回给调用方。
🔁 前面的总结我们已经掌握了深度学习的三部曲:
📦 工程的现实真实数据通常很大,不能一次全塞进模型。所以必须加一步:把数据分成多个小批量(mini-batch)。
🏠 案例演示为了让理解更落地,我们沿用机器学习中的经典案例——波士顿房价预测,把它改写成深度学习的版本,看看整体流程如何实现。
1、批量化打包
提效率:利用GPU并行计算,同时处理一批样本,比单条串行快数倍至数十倍。
稳训练:批量计算损失和梯度的平均值,能平滑噪声,避免单个样本的异常值使参数剧烈震荡。
省内存:不必一次性加载全部数据到显存,每个迭代只保存当前批次,降低硬件门槛。
生成器记录了一个规则,每次调用生成器就会返回一个批次数据。
from torch.utils.data import DataLoader, TensorDataset# 批量化打包数据示例代码dataset = TensorDataset(x_tensor, y_tensor)# 创建数据集和数据加载器data_loader = DataLoader(dataset, batch_size=16, shuffle=True)
所谓构建模型,就是搭出一个神经网络的骨架——定好有几层、每层有多少个神经元、用哪种激活函数,让这个骨架能学会解决你手头的问题。在深度学习中,构建模型的方式有很多。这里先介绍两种最常用的:
Sequential模型:你可以把它想象成“搭积木”——一层接一层,按顺序堆叠起来。这种方式最简单直观,适合大多数顺序处理数据的网络结构。
Class子类化模型:这种方式更灵活,就像自己从头设计一个零件。通过继承框架提供的模型基类,你可以完全自定义模型的结构和计算逻辑,满足更复杂、个性化的需求。
当然,还有像迁移学习、模型组合、模型集成、自动机器学习(AutoML)、超网络(Hypernetwork)等其他构建方式,不过它们不是这一讲的重点,这里先不展开。
3、筹备训练
它是什么?损失函数用来衡量“模型的预测结果”和“真实答案”之间有多大差距。你可以把它理解成一张“成绩单”——差距越小,说明模型学得越好。
为什么需要它?损失函数就是优化算法要去“最小化”的目标。模型通过不断降低损失值,来学习到正确的内部参数。
常见的损失函数有:
它是什么?优化器负责根据损失函数的结果,去更新模型的参数。它的工作就是一次又一次地调整模型,让损失值越来越小。
为什么需要它?只有定义了优化器,模型才知道“朝着哪个方向、怎么调整参数”才能让损失函数降到最低。
常见的优化算法有:
它是什么?训练次数指的是“把整个训练数据集完整地在模型上训练多少遍”。每完整地遍历一次全部数据,就叫做一个训练周期(Epoch)。
有什么用?适当增加训练次数,能让模型更充分地学习数据中的规律和特征,从而提高模型对没见过数据的表现能力(即泛化能力),同时也有助于减少过拟合。
它是什么?学习率是优化算法中一个非常重要的超参数。它决定了模型在每次迭代中,参数沿着梯度方向更新的步长大小——步子迈多大,由学习率说了算。
为什么需要它?学习率选得好,模型训练既快又稳,更容易接近最优解;学习率太大:训练容易“跑偏”甚至不收敛;学习率太小:训练慢得像“挪步”,还可能被困在不够好的局部最优解里。
4、训练模型
1️⃣ 盯着两个关键指标
在模型训练时,不能只看它“学没学”,还要看学得怎么样。最常用的两个“仪表盘”是:
准确率:模型猜对的概率有多高
损失值:模型预测和真实答案之间的差距有多大
通过观察它们的变化,你就能知道模型是越学越好,还是在“瞎蒙”。
2️⃣ 记得保存模型参数
模型训练好的那一刻,它的“知识和记忆”都藏在参数里。一定要把这些参数存下来,下次想用它做推理(比如回答问题、识别图片)时,直接加载就行,不用从头再训练一遍。
就像做饭记下菜谱,下次直接照着做,不用重新发明味道。
3️⃣ 小心“过拟合”
过拟合听起来复杂,其实意思很简单:模型把训练题背得太熟,一换新题就不会了。它的表现是:训练时准确率很高,一遇到没见过的数据就掉链子。
所以要主动采取一些方法(比如数据增强、正则化、早停等),让模型学得更“灵活”,而不是死记硬背
5、推理模型
我们一起走完了深度学习的基本流程:从回顾损失函数的最小值求解,到搞清楚模型的前向、反向传播;再从真实工程中的批量化打包,到搭建模型、筹备训练(损失函数、优化器、训练次数、学习率)、真正训练与推理。可以说,你已经从“知道深度学习是什么”迈向了“知道深度学习怎么做”。
下一节课,我们会真正拿一个完整的项目(比如房价预测)从头到尾跑一遍代码,把今天学到的流程全部串起来,让你亲手感受一个模型从零到一的全过程。你可以看到:数据怎么分批次、模型怎么搭、训练怎么调、指标怎么看、参数怎么存——每一个环节都在代码里落地。
如果你觉得这份笔记对你有帮助,欢迎点赞、在看、转发,也请关注我的公众号。我会继续用“AI小白也能听懂”的方式,和你一起探索大模型和深度学习的更多玩法。
咱们下节课见 👋