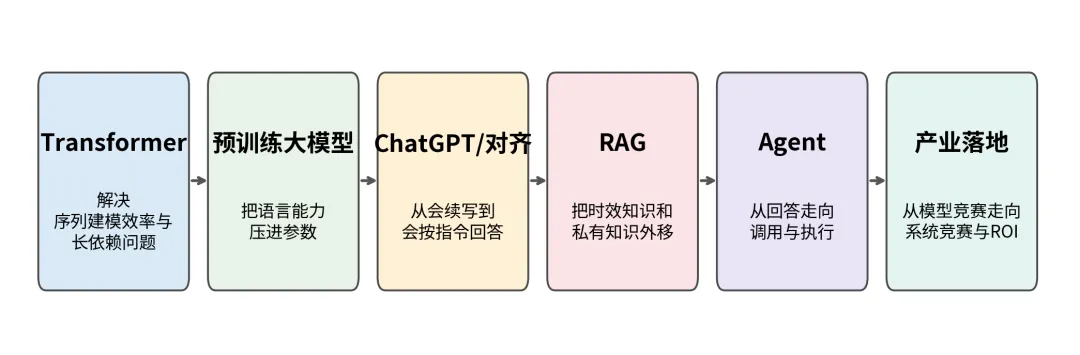
图 1从“模型输出”到“系统能力”:大模型技术路线的演化主线
前文讲了“大模型内部如何运转”,这里重点说明“为什么行业会自然演化出 RAG、Agent、推理系统和产业重构”,解释技术路线为何从‘模型能力竞争’转向‘系统能力与落地能力竞争’。 |
有时模型越强,现实世界的问题反而越清晰地暴露出来:知识会过时,私有数据不会自动进入参数,复杂任务不只是回答问题,还要检索、判断、调用、执行、回写与追踪;同时,推理成本会随着调用量上升而迅速成为新的约束。因此,大模型的下半场不再是单纯比谁的参数更多,而是比谁更能把模型、检索、工具、流程、治理和成本结构实现系统级的优化整合。
一、下半场源于行业约束条件的变化
把大模型的发展理解成“上半场/下半场”,并不是说某个自然日之后技术突然换代,而是说行业的约束条件发生了变化。
上半场的核心问题是:模型能不能学会语言、形成抽象表征、在大规模数据上获得泛化能力(scalling law)。Transformer、预训练、指令微调与偏好对齐,就主要回答的是这些问题。
下半场的核心问题则变成:模型如何接入外部知识,如何在现实业务中保持正确性,如何完成多步任务,如何控制推理成本,如何在组织中被审计、被部署、被采购、保证持续稳定运营。
阶段 | 关键矛盾 | 主要技术抓手 | 衡量指标 |
上半场 | 模型是否足够聪明 | 预训练、对齐、模型架构、数据规模 | 通用能力、benchmark、对话体验 |
下半场 | 模型是否足够可用、可控、可负担 | RAG、Tool Use、Agent、Serving、治理 | 准确率、成功率、延迟、单位成本、ROI |
这意味着研究视角也要改变。面对一个新的大模型产品,不能只问“它比前一代聪明多少”,还要问四件事:它如何接知识、如何接工具、如何嵌入流程、如何控制优化成本。
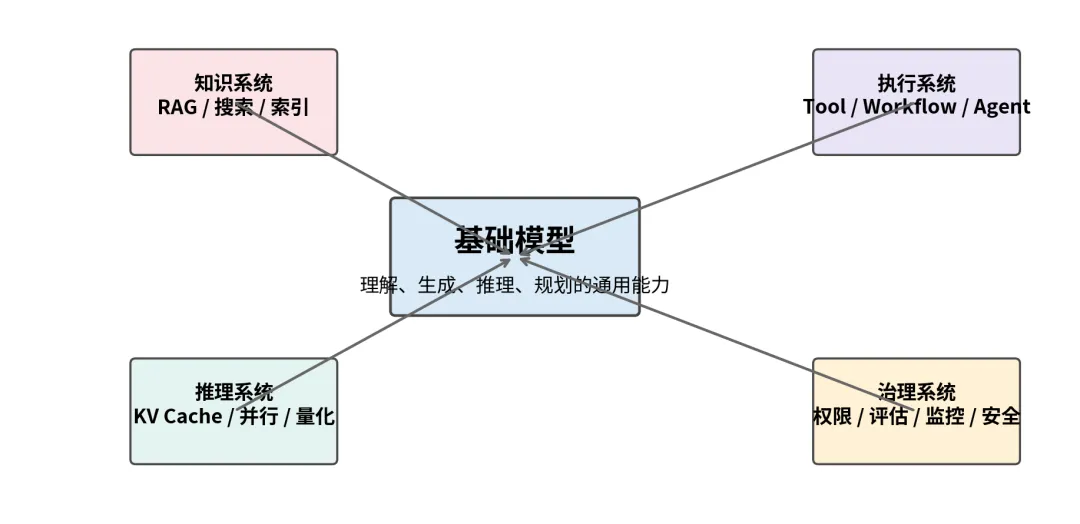
图 2下半场的系统分工:模型只是中心,不再是全部
二、更强的基础模型并不能自动解决真实世界问题
只靠把模型做大,并不能自动跨越现实业务中的三类问题:知识缺口、任务目标和成本约束。
第一是知识缺口。基础模型的大量知识被压进参数,优点是调用时不必重新查库,缺点是参数里的知识更新慢、来源不透明、难以只针对某个企业的私有数据进行控制式刷新。
第二是任务目标。现实任务常常不是“回答一个问题”,而是“在多步约束下完成一个目标”。例如先查询数据库,再比对规则,再生成草稿,再回写工单,再通知人类审核。单次生成并不等于可执行任务。
第三是成本约束。训练成本虽然高,但往往是一次性的资本投入;推理成本才是随业务规模长期发生的现金流压力。调用越多,部署优化和资源调度的重要性越高。
三、RAG 率先成为企业落地的第一站
RAG(Retrieval-Augmented Generation)之所以成为企业落地的高频答案,不是因为它时髦,而是因为它对三种限制形成了较低成本的解决方案:知识时效性、私有知识接入、回答可解释性。
RAG 的本质不是“给模型外挂知识库”这么简单,而是把“知识存储”从模型参数中部分外移。模型负责理解问题、组织证据、整合表达;外部系统负责保存、更新与召回知识。
这一设计非常符合企业环境。企业大量知识原本就分散在文档、表格、数据库、Wiki、客服记录和工单系统里。与其试图把这些全部重新蒸馏进参数,不如先通过检索把相关证据在回答时注入上下文。
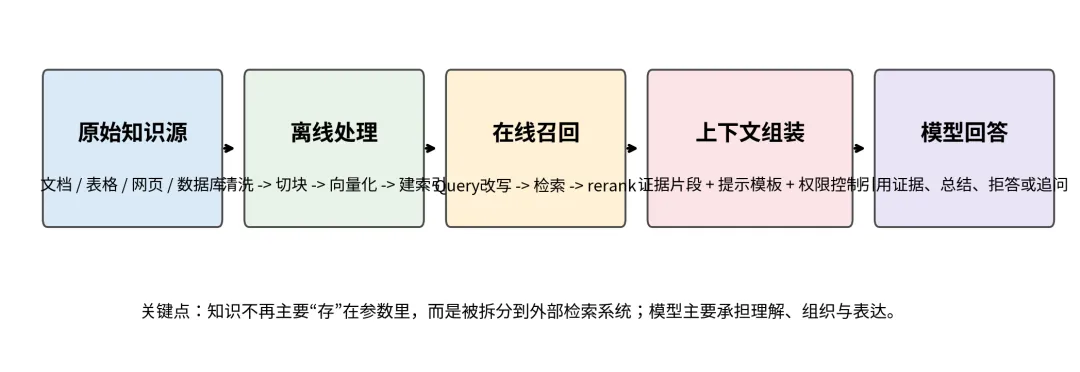
图 3RAG 的真正价值:让知识系统与模型系统分工,而不是混在一起
1. RAG 解决了什么
• 让知识更新频率从“重新训练模型”变成“更新索引或文档”。
• 让私有知识可以按权限接入,而不必直接污染通用参数。
• 让回答更容易绑定证据来源,便于审计、人工复核。
• 在许多企业问答、知识助手、文档总结场景里,以较低成本提升正确率。
2. RAG 没有解决什么
• 它不自动解决推理能力不足。如果问题本身需要复杂逻辑,只有证据并不保证推理过程正确。
• 它不自动解决检索质量问题。召回错了、切块碎了、排序失真了,模型会在坏证据上继续认真作答。
• 它不自动解决业务动作执行。模型知道答案,不代表系统已经完成查询、审批、回写或通知。
3. 企业 RAG 项目真正难在哪
难点 | 为什么难 | 常见后果 |
切块(chunking) | 切得过大导致噪声高,切得过小导致上下文断裂 | 答非所问、引用片段不完整 |
召回与 rerank | 相似度未必等于业务相关度 | 命中率不稳、长尾问题表现差 |
权限与版本 | 同一问题对不同用户可见文档不同 | 越权、旧版本答案混入 |
评估 | 通用 benchmark 不能代表企业任务 | 上线前看起来好,上线后满意度低 |
所以,RAG 不是一个单点模型技巧,而是一条完整的数据与系统链:离线建库、在线召回、上下文组装、答案生成、引用展示与效果评估。很多项目的成败,最后决定于数据工程和治理,而不是决定于提示词。
四、RAG 之后,继续走向 Tool Use 与 Agent
RAG 解决的是“知道得更多”,但现实世界中还有另一类需求:不仅要知道,还要做。于是系统进一步演化到工具调用、工作流和 Agent。
从能力上看,可以把它们理解成一条逐步放权的阶梯。普通聊天模型只负责回答;Tool Use 允许模型在需要时调用一个函数或外部 API;Workflow 把任务分解为一组预定义步骤;Agent 则在目标与约束下,动态规划多步行动。
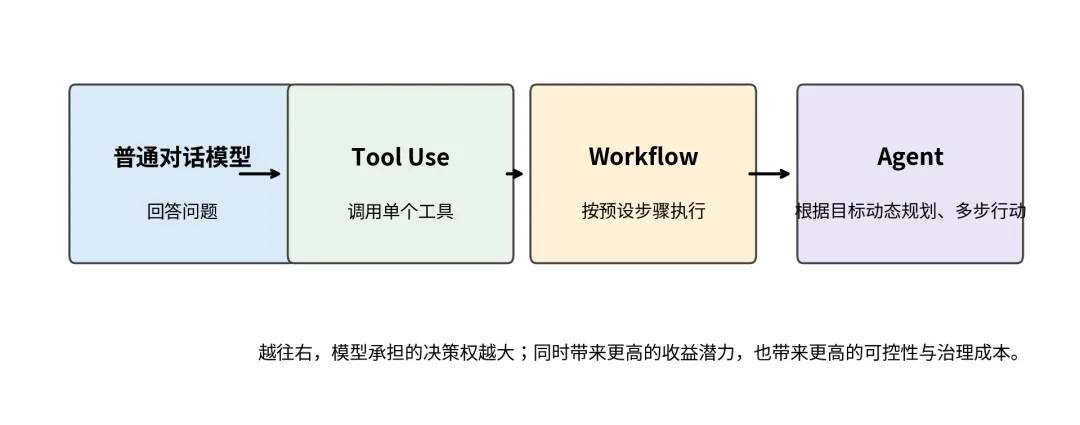
图 4从回答到行动:Tool Use、Workflow 与 Agent 的能力边界
1. 为什么 Agent 会被需要
• 很多任务的正确性依赖交互式过程,而不是单步输出。例如搜集多源信息、生成方案、校验约束、修正路径。
• 任务环境会变化,固定模板无法覆盖所有路径,系统需要边执行边决定下一步。
• 真正有业务价值的工作经常不是“写一句答案”,而是“把一件事推进到完成”。
2. 为什么很多所谓 Agent 实际上更像 Workflow
因为企业最在意的不是“像不像自主智能体”,而是“结果可不可以预测、权限能不能控制、责任能不能界定”。
只要一个任务的步骤相对稳定,Workflow 通常比完全自治的 Agent 更便宜、更稳、更容易审计。Agent 的价值主要出现在路径高度不确定、需要跨系统判断与多轮反馈的场景。
3. 真正的 Agent 难点不在提示词,而在系统工程
模块 | 核心问题 | 如果做不好会怎样 |
规划 | 下一步做什么、是否需要改计划 | 走偏、循环、无效调用 |
记忆 | 保留哪些状态、遗忘哪些上下文 | 短期聪明、长期失控 |
工具权限 | 能访问什么、能写入什么 | 误操作、越权、风险外溢 |
回退与监控 | 失败后怎么恢复、如何被观察 | 看似能跑,实则不可运营 |
因此,Agent 更像“以大模型为核心的任务操作系统”,而不是一个魔法提示词。
五、从训练竞赛到部署竞赛:产业价值重新分层
当行业从“模型能不能做出来”进入“系统能不能持续交付”,价值链就会重新分层。
算力基础设施层受益于训练与推理需求;模型与推理层控制通用能力和成本效率;系统层把检索、工作流、治理与观测接进来;应用层则争夺真实入口、真实工作流和真实数据。
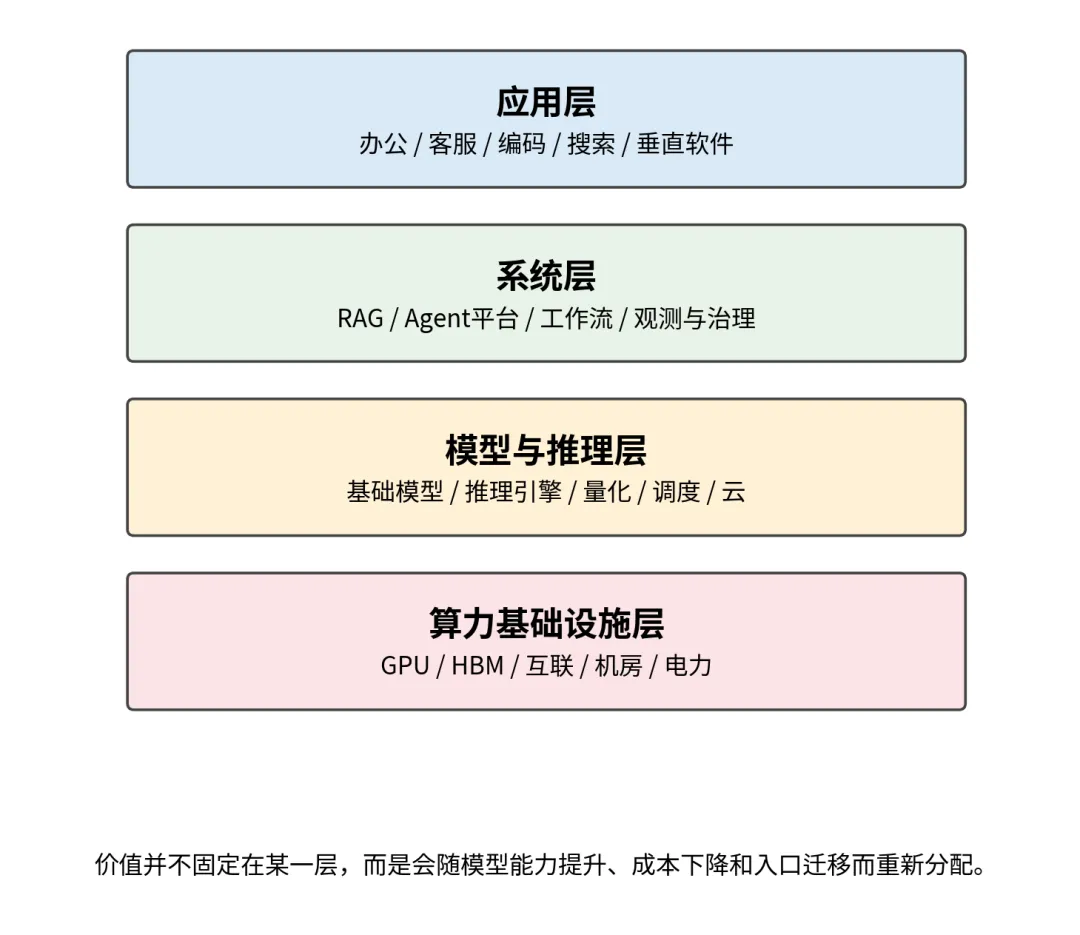
图 6下半场的产业栈:价值会迁移,但系统层的重要性持续上升
这里最容易被忽略的一点是:模型能力越强,不一定意味着中间系统层都会被挤压。相反,只要工作环境仍然存在私有数据、权限体系、复杂流程、合规要求与旧系统集成,中间的系统层就会长期存在。
层级 | 长期价值来源 | 容易被压缩的部分 |
算力基础设施 | 稀缺资源、规模效应、供给约束 | 纯拼装式、低差异化供给 |
基础模型/推理层 | 能力边界、成本效率、生态与开发体验 | 同质化的小模型外壳 |
系统层(RAG/Agent) | 数据接入、流程嵌入、治理与可观测性 | 只停留在提示词封装的轻层工具 |
应用层 | 入口、场景深度、工作流替代与结果责任 | 无数据、无分发、无流程粘性的浅应用 |
面对“要不要上 Agent”具体业务需求时,最重要是考虑知识正确性和结果的准确率。很多项目失败,原因不在模型,而在权限、接口、责任边界和人工复核流程。尤其是能用检索和工作流稳定解决的问题,不必过早追求 fully autonomous agent;只有当任务路径高度不确定、且执行收益足够大时,才值得为 Agent 额外支付改造成本。
Transformer 依然是基础,但它不再单独构成全部竞争力。RAG 的出现,说明知识需要从参数中部分外移;Agent 的出现,说明语言能力必须连接执行能力;推理系统的崛起,说明商业化最终要通过成本与延迟来兑现;产业分层的变化,则说明价值正在从单纯的模型竞赛,转向模型、系统、数据、入口与基础设施的重新分工。大模型下半场,形成一种系统视角:模型负责什么,检索负责什么,工具负责什么,流程负责什么,成本又由谁承担。

