JVM学习笔记 02、JVM的内存结构
- 2026-04-22 17:34:52
点击上方蓝字关注我们


前言
本篇博客是跟随黑马程序员JVM完整教程,全网超高评价,全程干货不拖沓的学习JVM的笔记,若文章中出现相关问题,请指出!
所有博客文件目录索引:博客目录索引(持续更新)
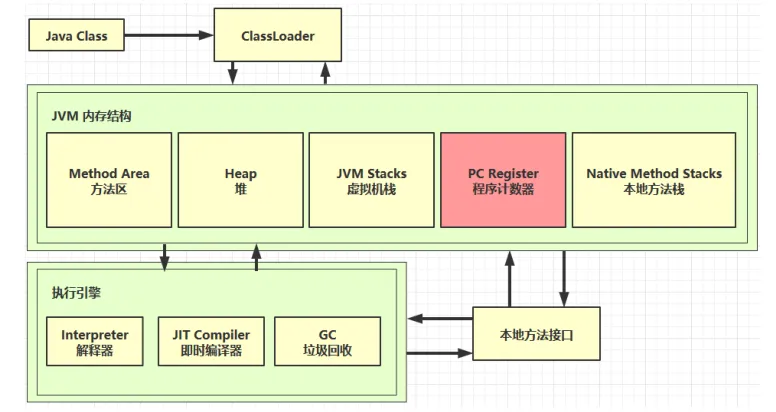
JVM整体视角
一、程序计数器(私有)
1.1、介绍
Program Counter Register 程序计数器(寄存器)
作用:是记住下一条jvm指令的执行地址
特点:
1. 是线程私有的 2. 不会存在内存溢出
1.2、作用
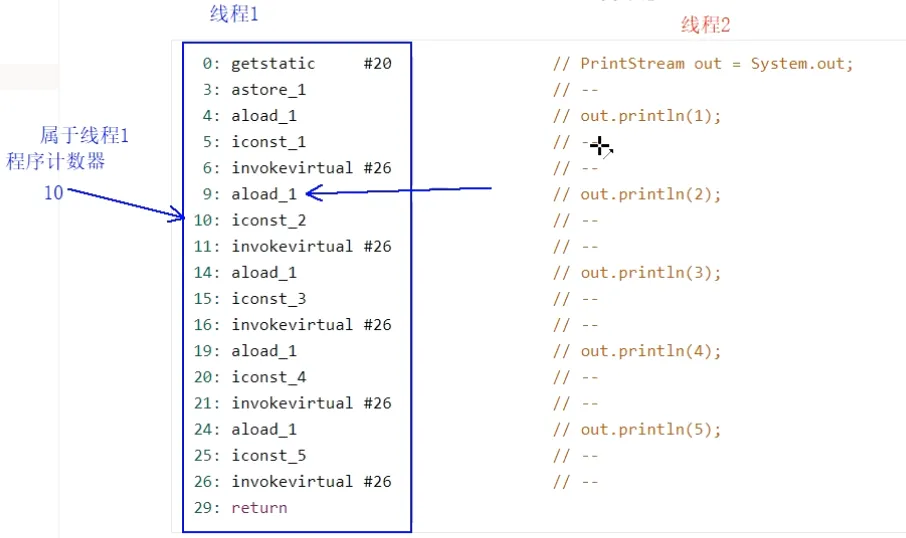
java从编写到执行过程:首先是java源代码,使用javac编译成字节码文件(java代码->字节码),接着使用解释器来将字节码转为机器码交由CPU来执行。

• 可以看到对应的字节码左边都有执行的顺序编号,指的就是指令的内存地址,当这些指令被加载到虚拟机以后,就可以根据这些地址信息来找到对应的命令。 • 过程:解释器拿到一条字节码指令将其转为机器码执行,与此同时程序计数器中就已经记住了下一条jvm指令的执行地址,解释器会去程序计数器中取到对应的执行地址,进而来执行下一条字节码指令。
程序计数器功能:记住下一条jvm指令的执行地址。方便之后解释器执行完一条命令接着从计数器中取下一条指定。
• 物理上是使用寄存器来实现的,寄存器是读取速度最快的一个单元,用来存储地址读取地址。
1.3、特点
①线程私有
每个线程都有其自己的程序计数器
②不会存在内存溢出
JVM本身提到了程序计数器不会内存溢出的特点,所以一些厂商在实现自己jvm过程中也不需要考虑该问题。
二、虚拟机栈(私有)
2.1、初识
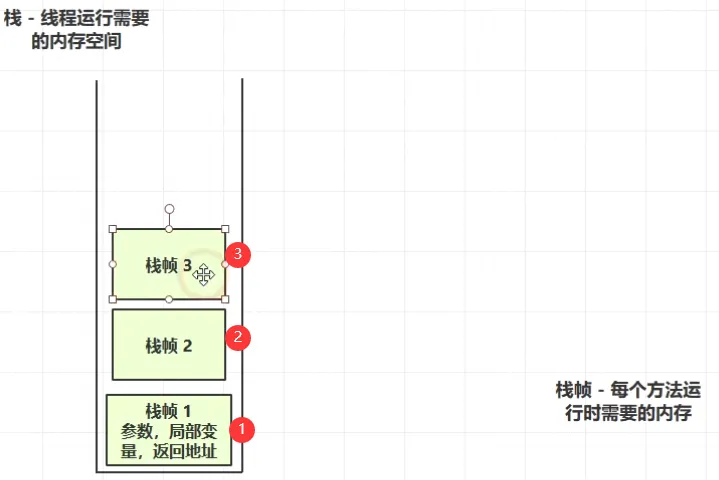
栈:线程运行时所需要的内存空间,一个栈内分为多个栈帧组成,栈帧指的是每个方法所需要的运行内存。
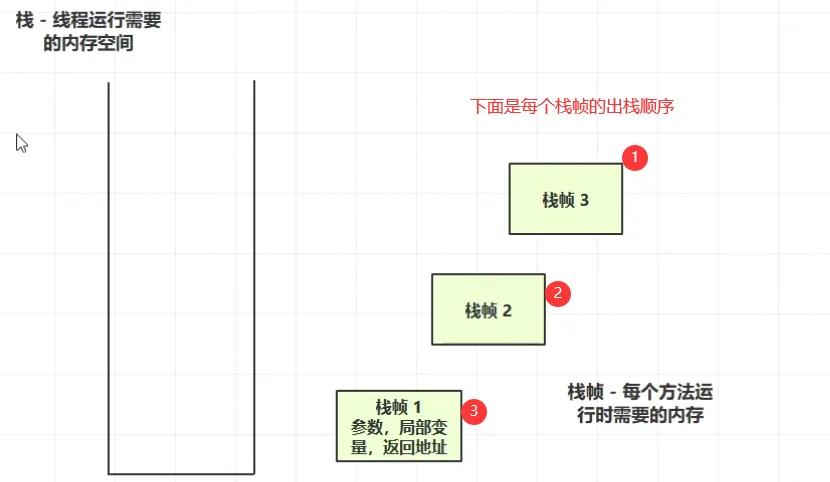
过程:线程执行方法1(方法1入栈),方法1中调用方法2(方法2入栈),方法2调用方法3(方法3入栈),入栈的都是栈帧,栈帧中保存了参数、局部变量、返回地址...,一旦某个方法结束,该栈帧就会出栈(也就是相当于释放该栈帧内存)。
2.2、定义
Java Virtual Machine Stacks (Java 虚拟机栈)
1. 每个线程运行时所需要的内存,称为虚拟机栈。 2. 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存。 3. 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
帧栈的演示:
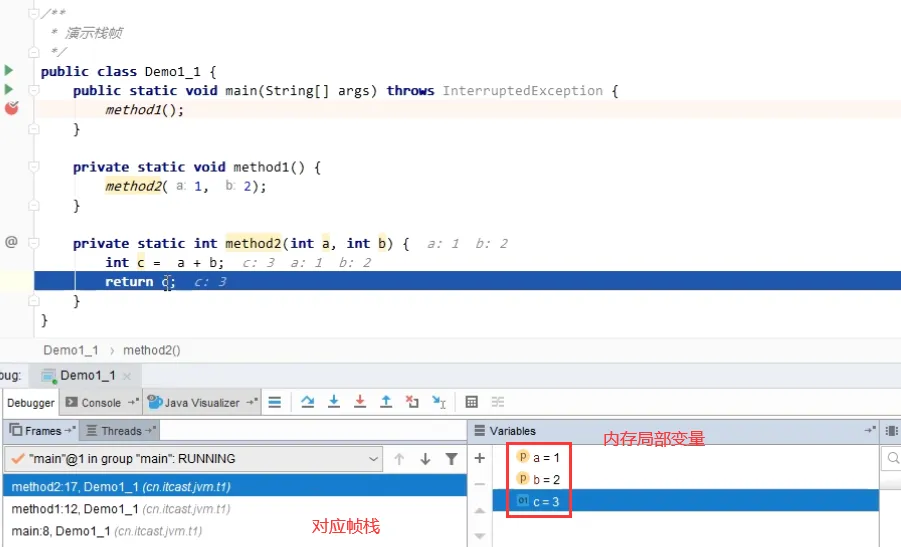
2.3、问题辨析(3个)
问题辨析
1. 垃圾回收是否涉及栈内存? 2. 栈内存分配越大越好吗? 3. 方法内的局部变量是否线程安全?
• 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的 • 如果是局部变量引用了对象,并逃离方法的作用范围(作为返回对象、引用类型作为参数传递到方法),需要考虑线程安全。
解答:
1. 栈帧内存无非就是方法调用而产生的栈帧内存,栈帧内存在每次方法调用之后都会被释放掉根本就不需要垃圾回收来进行回收。 2. 栈内存可以通过运行虚拟机时的参数所设定,如指令: -Xss size,默认三个平台(linux、macos、oracle solaries)都是1024KB,而windows的话根据虚拟内存来决定的。栈内存越大,反而会让你的线程数越少。划分大了仅仅只是能够更多次的递归调用,不会增强你运行的效率,反而会影响线程数目的变少。3. 看是否是线程安全,主要看这个变量是公有的还是私有的。若是staic这类公有变量每个线程都能够对该变量进行操作,那么就是线程不安全的。
2.4、栈内存溢出(案例演示)
说明
栈帧过多导致栈内存溢出:不断的进行方法调用,始终没有出栈,导致栈帧的内存超过了栈的内存。例如:递归调用一直没有出口,导致有无限方法一直被调用帧栈一直在入栈,就会出现栈内存溢出。
栈帧过大导致栈内存溢出:某个栈帧过大直接将你的栈内存给占满了。
案例演示
①栈帧过多:无线递归调用
class Main { private static int count; public static void main(String[] args) { try { test(); }catch (StackOverflowError e){ e.printStackTrace(); System.out.println(count); } } public static void test(){ count++; test(); }}结果: ①直接运行,最终报错,输出41385。也就是说递归调用41385次出现了栈内存溢出。 ②在运行时设置虚拟机参数-Xss256k,最终报错输出2738,表示调用了2738次。结论:通过设置-Xss参数可以调节栈的内存空间大小。②帧栈过多的演示二:
两个类循环引用之后,例如使用一些转json的工具类也会导致stackoverflow
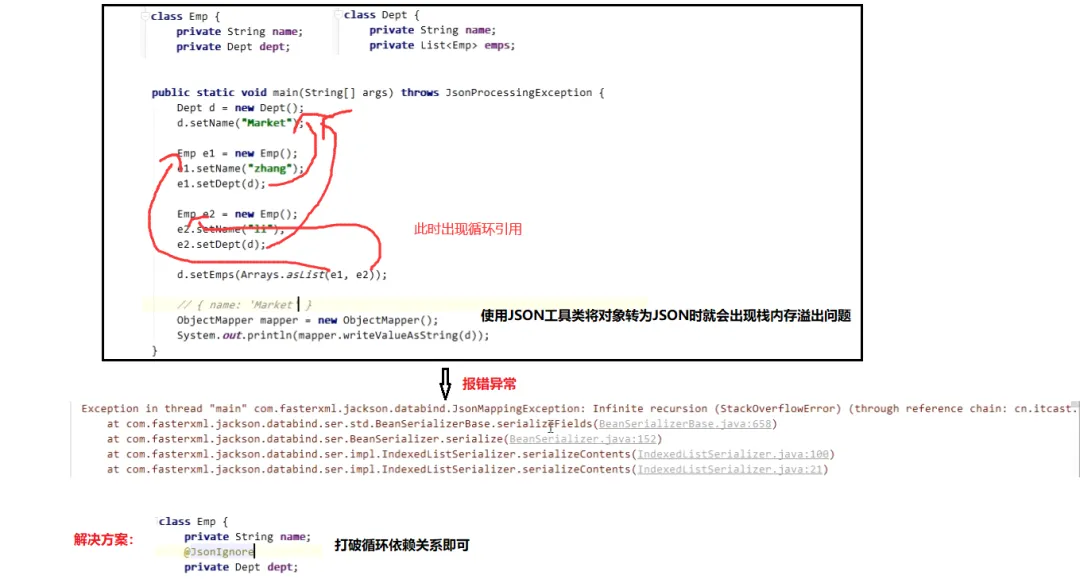
class Test2{ public String name; public Test1 test1;}class Test1{ public String name; public Test2 test2;}class Main { public static void main(String[] args) throws JsonProcessingException { //类与类之间循环引用 Test1 test1 = new Test1(); Test2 test2 = new Test2(); test1.test2 = test2; test2.test1 = test1; ObjectMapper objectMapper = new ObjectMapper(); System.out.println(objectMapper.writeValueAsString(test1)); }}这里的话,由于对象与对象之间出现循环依赖,所以使用ObjectMapper将其转为JSON时就会不断无线递归下去。
在Spring中也有循环引用的情况,使用循环依赖三级缓存来解决。
2.5、线程运行诊断
2.5.1、案例1: cpu 占用过多
定位过程:
1. 用 top命令定位哪个进程对cpu的占用过高:只能定位到某个进程号。2. ps H -eo pid,tid,%cpu | grep 进程id:用ps命令进一步定位是哪个线程引起的cpu占用过高。# H表示所有的线程数,将信息都展示出来,-eo表示对哪些应用感兴趣,如pid、tid、cpu,tid就是对应的线程号# 能够查看所有线程的指标了ps H -eo pid,tid,%cpu# 若是想要定位某个进程号的线程,此时就能够定位到指定的一个线程ps H -eo pid,tid,%cpu | grep 进程号# 更详细的信息:列出了进程id, 线程id和cpu占有率,同时按照cpu占有率排序ps H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpu3. jstack 进程id,可以根据线程id 找到有问题的线程,进一步定位到问题代码的源码行号。接着会打印多个线程的信息,此时要注意的是我们需要根据之前使用ps排查到cpu占用过大的线程号来进行找到指定的线程执行的代码。
需要将十进制的线程编号换算为十六进制,接着使用这十六进制在jstack中进行查找定位。32665 => 7f9b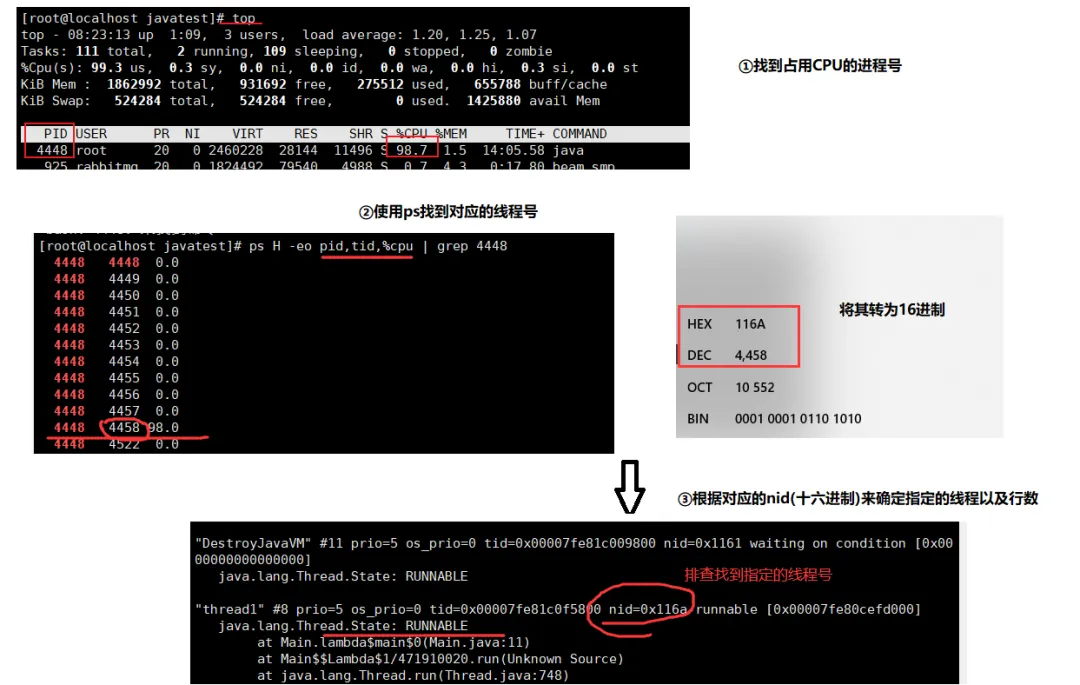
//问题代码public class Main { public static void main(String[] args) { new Thread(null,()->{ System.out.println("1..."); while(true){ } },"thread1").start(); new Thread(null,()->{ System.out.println("2..."); try { Thread.sleep(100000L); } catch (InterruptedException e) { e.printStackTrace(); } },"thread2").start(); new Thread(null,()->{ System.out.println("3..."); try { Thread.sleep(100000L); } catch (InterruptedException e) { e.printStackTrace(); } },"thread3").start(); }}2.5.2、案例2:程序运行很长时间没有结果
有可能是线程发生了死锁导致最终没有得到结果。
同样使用命令:jstack 进程号,若是有死锁问题在最后会有对应的死锁提示信息。
三、本地方法栈(私有)
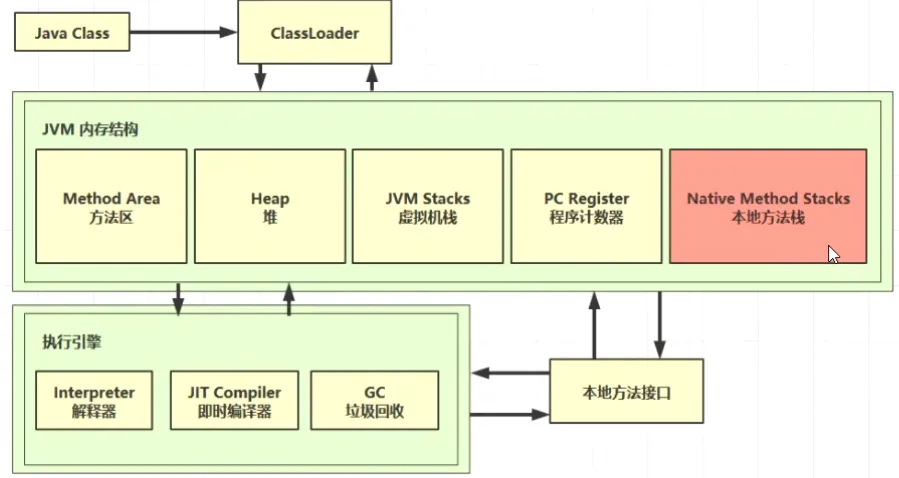
不是由java代码编写的方法,java代码有一定的限制,不能够直接跟操作系统底层打交道,所以需要用c或者c++编写的本地方法来真正与操作系统、底层的API来打交道,而java通过调用本地方法来去调用一些底层的功能,这些本地方法使用的内存就是本地方法栈。
作用:给本地方法的运行提供内存空间!
使用的位置:java的基础类库、执行引擎中都会使用、调用本地方法。
本地方法使用native来进行声明!
四、堆(公共)
4.1、定义
Heap 堆:通过 new 关键字,创建对象都会使用堆内存
特点:
1. 它是线程共享的,堆中对象都需要考虑线程安全的问题 2. 有垃圾回收机制:堆中不再被引用的对象就会被当成垃圾进行回收。
4.2、堆内存溢出(案例演示)
说明
介绍:对象当做垃圾回收的条件:没人再使用它。但是如果我不断的产生对象,而产生的新对象仍然有人在使用它们,此时就意味着这些对象不能作为垃圾,这样的对象达到一定的数量就会导致堆内存被耗尽,也就是堆内存溢出。
描述:默认的堆空间为4G。有时候内存占用非常大可能不会立刻暴露出内存溢出的问题,随着时间的累计若是编码不当就会出现内存溢出的问题!
排查堆内存溢出问题:可以通过设置-Xmx参数,尽可能设小,能够让程序更快的暴露堆内存的问题。
代码演示
import java.util.ArrayList;import java.util.List;public class Main { public static void main(String[] args) { String message = "changlu"; int count = 0; List<String> list = new ArrayList<>(); try { while (true) { list.add(message); message += message; count++; } }catch (Throwable t){ t.printStackTrace(); System.out.println(count); } }}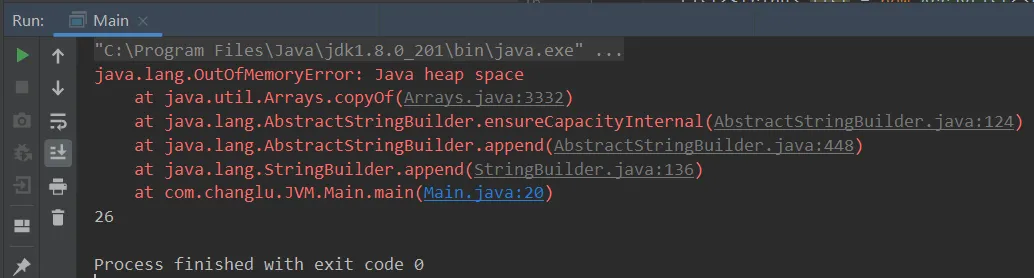
通过设置-Xmx参数将堆内存空间设小:

此时就能够更快的报出异常错误,让我们更快的去检测问题
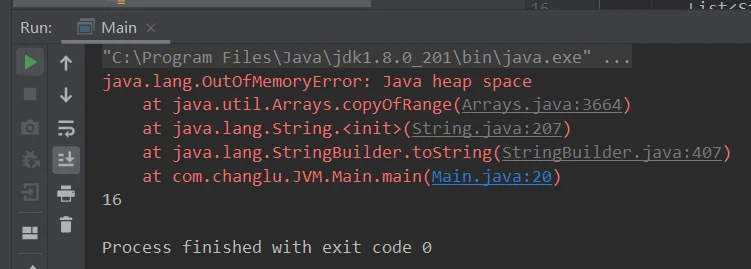
4.3、堆内存诊断(三个工具)
工具介绍
1. jps:打印当前运行java的所有进程号。2. jmap:查看当前时间段堆内存占用情况。如:jmap - heap 进程id3. jconsole:内存、线程监控工具。
案例演示
三个阶段:阶段1是不创建任何对象。阶段2创建一个10MB的数组。阶段3垃圾回收。这三个阶段能够让我们看到对应的堆内存的起伏现象!
public class Main { public static void main(String[] args) throws InterruptedException { System.out.println("1..."); Thread.sleep(30000); byte[] array = new byte[1024 * 1024 * 10]; // 10 Mb System.out.println("2..."); Thread.sleep(20000); array = null; System.gc();//进行垃圾回收 System.out.println("3..."); Thread.sleep(1000000L); }}jps:确定运行的进程号
D:\workspace\workspace_idea\mavenexer>jps16016 Main189922880 Jps4660 Launcherjmap工具:分别查看三个阶段的堆内存状态
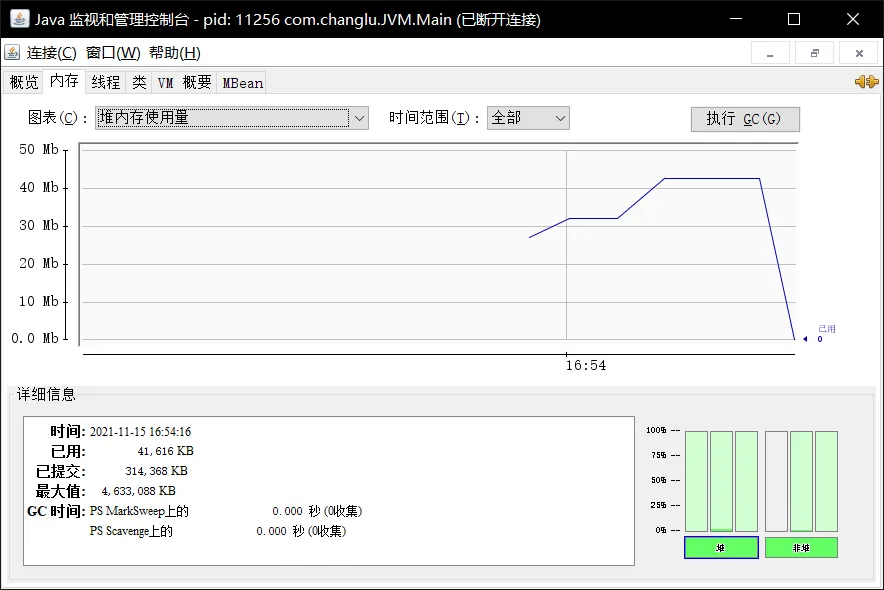
# 阶段1:没有任何手动创建对象D:\workspace\workspace_idea\mavenexer>jmap -heap 16016Attaching to process ID 16016, please wait...Debugger attached successfully.Server compiler detected.JVM version is 25.201-b09using thread-local object allocation.Parallel GC with 8 thread(s)Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 5337251840 (5090.0MB) # 可以看到默认最大堆内存空间为5G NewSize = 111673344 (106.5MB) MaxNewSize = 1778909184 (1696.5MB) OldSize = 223870976 (213.5MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB)Heap Usage:PS Young Generation# 新生代Eden Space: capacity = 84410368 (80.5MB) used = 8441304 (8.050254821777344MB) # 当前已经使用8MB free = 75969064 (72.44974517822266MB) 10.000316548791732% usedFrom Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% usedTo Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% used# 老年代PS Old Generation capacity = 223870976 (213.5MB) used = 0 (0.0MB) free = 223870976 (213.5MB) 0.0% used3169 interned Strings occupying 260032 bytes.# 阶段2:创建了一个10MB空间的数组D:\workspace\workspace_idea\mavenexer>jmap -heap 16016Attaching to process ID 16016, please wait...Debugger attached successfully.Server compiler detected.JVM version is 25.201-b09using thread-local object allocation.Parallel GC with 8 thread(s)Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 5337251840 (5090.0MB) NewSize = 111673344 (106.5MB) MaxNewSize = 1778909184 (1696.5MB) OldSize = 223870976 (213.5MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB)Heap Usage:PS Young GenerationEden Space: capacity = 84410368 (80.5MB) used = 18927080 (18.050270080566406MB) # 可以看到当前使用空间为18MB free = 65483288 (62.449729919433594MB) 22.422695752256406% usedFrom Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% usedTo Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% usedPS Old Generation capacity = 223870976 (213.5MB) used = 0 (0.0MB) free = 223870976 (213.5MB) 0.0% used3170 interned Strings occupying 260080 bytes.# 阶段3:进行了一次垃圾回收D:\workspace\workspace_idea\mavenexer>jmap -heap 16016Attaching to process ID 16016, please wait...Debugger attached successfully.Server compiler detected.JVM version is 25.201-b09using thread-local object allocation.Parallel GC with 8 thread(s)Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 5337251840 (5090.0MB) NewSize = 111673344 (106.5MB) MaxNewSize = 1778909184 (1696.5MB) OldSize = 223870976 (213.5MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB)Heap Usage:PS Young GenerationEden Space: capacity = 84410368 (80.5MB) used = 1688224 (1.610015869140625MB) # 可以看到当前只使用了一点多MB空间大小 free = 82722144 (78.88998413085938MB) 2.0000197132181676% usedFrom Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% usedTo Space: capacity = 13631488 (13.0MB) used = 0 (0.0MB) free = 13631488 (13.0MB) 0.0% usedPS Old Generation capacity = 223870976 (213.5MB) used = 1302384 (1.2420501708984375MB) free = 222568592 (212.25794982910156MB) 0.581756520327137% used3156 interned Strings occupying 259088 bytes.使用jconsole可以实时进行监控:并且在右边我们可以执行GC垃圾回收
4.4、jvisualvm工具
案例引出
接下来我们借助一个案例来引出这个jvisualvm工具,它能够给我们具体分析出指定方法中哪个类里的实例大小。
public class Main { public static void main(String[] args) throws InterruptedException { List<Student> students = new ArrayList<>(); for (int i = 0; i < 200; i++) { //200MB students.add(new Student());// Student student = new Student(); } Thread.sleep(1000000000L); }}class Student { private byte[] big = new byte[1024*1024];//1MB}该程序在运行时,会向集合中不断添加对象,每个对象内存空间为1MB,那么最终就会添加200MB内存的空间,我们先使用jconsole来看一下:
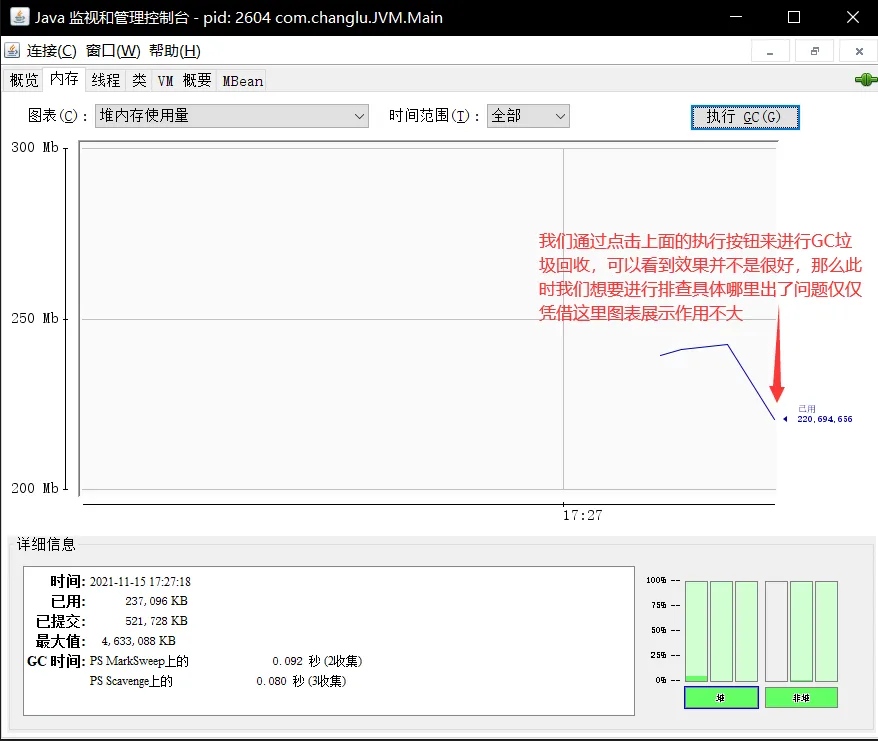
若是想要具体分析哪里产生出这么大的内存空间,光只是使用jconsole是不够的,接着我们来进行使用jvisualvm工具。
jvisualvm工具
该工具也是jdk自带的,我们只需要执行jvisualvm即可:
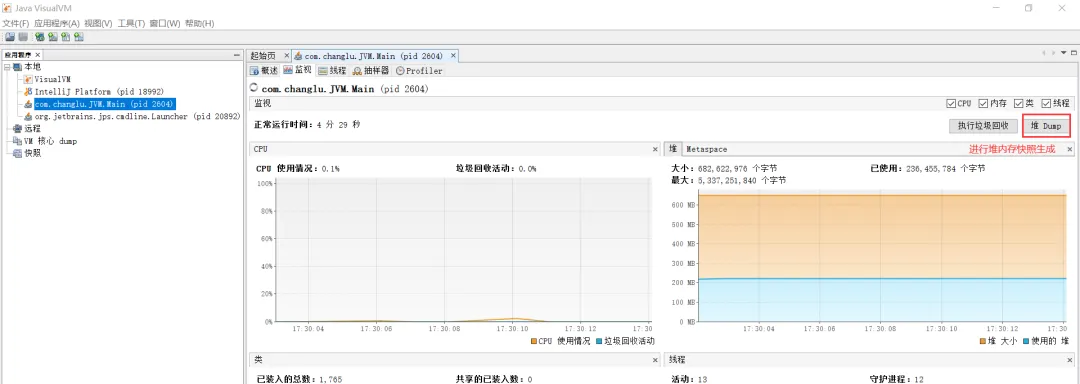
可以看到下面有堆Dump按钮,点击它可进行堆转储,将堆内存快照抓取下来进行对堆进行分析,我们来进行查询最大的前20个对象:
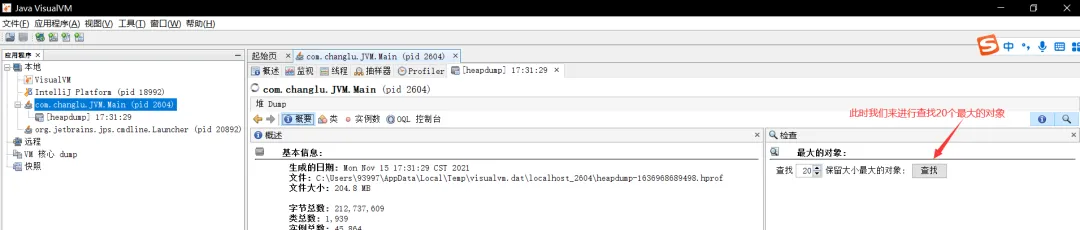
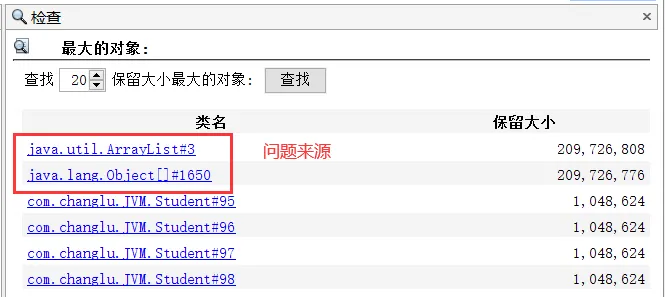
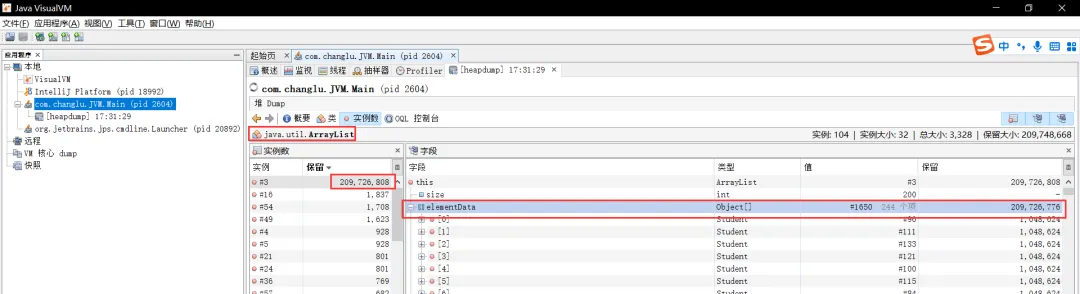
此时我们点击进入查看详细内容,可以看到问题原因就出在了这个集合中
五、方法区(公共)
5.1、介绍与组成
介绍
方法区规范—Oracle官方
所有java虚拟机中线程的共享区域。存储了跟类的结构相关的信息,如成员变量、方法数据、成员方法与构造器方法代码部分,特殊方法(类的构造器)、运行时常量池。
方法区在虚拟机启动时被创建。方法区逻辑上是堆的组成部分(概念上定义了方法区),具体的jvm厂商不一定会坚持jvm逻辑上的定义,不同的厂商实现方式上不一样。
• 例如Hotspot:JDK8以前就是使用了一个永久代,就是使用了堆的一部分来作为方法区。 • 在1.8以后,将永久代移除了,换了个名字叫做元空间,用的不是堆的内存,而是本地内存、操作系统的内存空间。
方法区内存溢出定义:方法区若是申请内存时发现不足了,也会让虚拟机抛出一个内存溢出的错误。
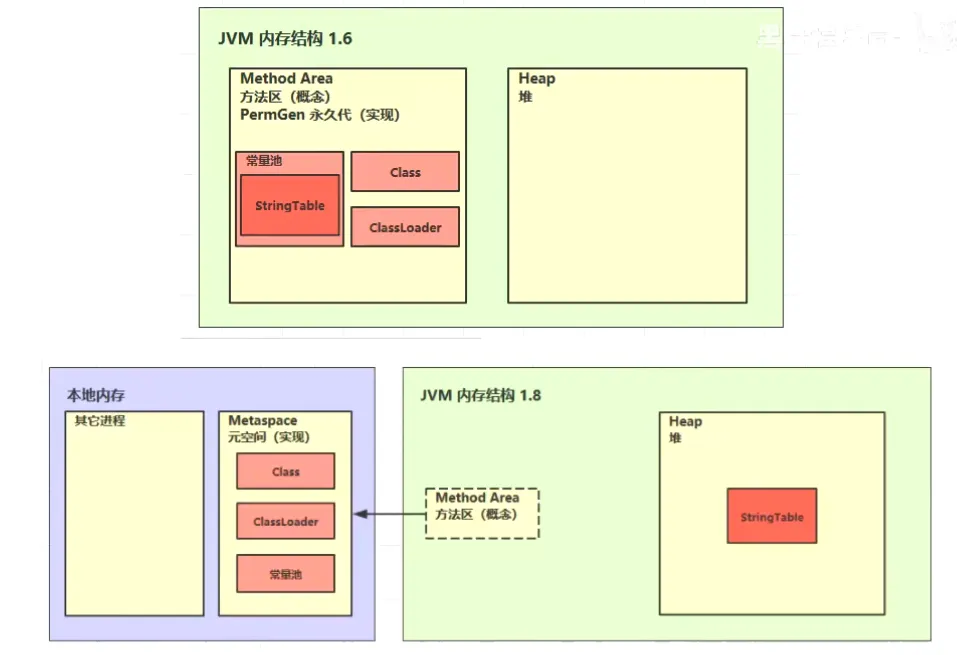
方法区组成(HotSpot)
JDK1.6:可看到方法区是属于在JVM中,由JVM来进行管理的,此时的常量池在方法区里。
JDK1.8:方法区已经不再jvm中,被移动到本地内存里,由操作系统来进行管理,并且可以看到常量池被移动到了堆中。
5.2、方法区内存溢出
元空间默认不会设置上限。
应用场景:在使用一些框架时就会进行动态加载一些代理类,若是在此过程中出现了内存溢出,我们要去查看一下是否是框架使用不当而导致的结果。
下面的代码是使用ClassWriter来生成字节码的一系列信息,接着让类加载器进行加载,这一过程就是在给方法区添加类的结构信息:
JDK1.8
JDK1.8:在jdk1.8中并不是在jvm虚拟机范围,而是由操作系统来进行管理,叫做元空间,此时并没有给其设置最大上限,所以我们需要设置一个指定的元空间大小,使用该参数:-XX:MaxMetaspaceSize=8m
import jdk.internal.org.objectweb.asm.ClassWriter;import jdk.internal.org.objectweb.asm.Opcodes;/** * 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace * -XX:MaxMetaspaceSize=8m */public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码 public static void main(String[] args) { int j = 0; try { Demo1_8 test = new Demo1_8(); for (int i = 0; i < 10000; i++, j++) { // ClassWriter 作用是生成类的二进制字节码 ClassWriter cw = new ClassWriter(0); // 版本号, public, 类名, 包名, 父类, 接口 cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); // 返回 byte[] byte[] code = cw.toByteArray(); // 执行了类的加载 test.defineClass("Class" + i, code, 0, code.length); // Class 对象 } } finally { System.out.println(j); } }}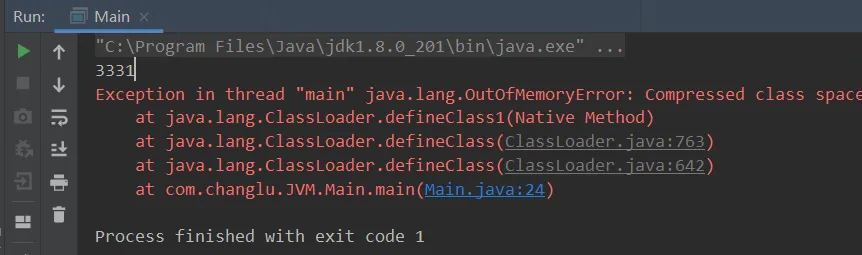
JDK1.6
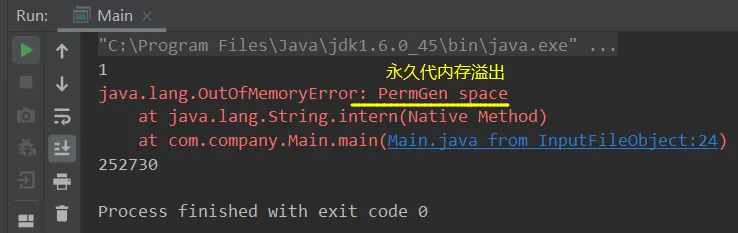
JDK1.6:在jdk1.6中叫做永久代,其是在堆中的,要是想设定值需要使用其他的参数:-XX:MaxPermSize=8m
import com.sun.xml.internal.ws.org.objectweb.asm.ClassWriter;import com.sun.xml.internal.ws.org.objectweb.asm.Opcodes;/** * 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space * -XX:MaxPermSize=8m */public class Demo1_8 extends ClassLoader { public static void main(String[] args) { int j = 0; try { Demo1_8 test = new Demo1_8(); for (int i = 0; i < 20000; i++, j++) { ClassWriter cw = new ClassWriter(0); cw.visit(Opcodes.V1_6, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); byte[] code = cw.toByteArray(); test.defineClass("Class" + i, code, 0, code.length); } } finally { System.out.println(j); } }}测试结果:在我本地竟然没有测出来jdk1.6的,无论设置多小都能够正常加载20000个。
5.3、运行时常量池
常量池的作用:就是给我们的指令提供一些常量符号,根据常量符号以查表的方式来查到它,这样虚拟指令才能够查到并执行。
下面是我们要进行反编译的java代码:
public class Main{ // 注释 public static void main(String[] args) { System.out.println("Hello,world!"); }}执行反编译命令:javap -v 类名.class,反编译java字节码文件,-v表示显示详细信息。
//1、类的基本信息Classfile /D:/workspace/workspace_idea/mavenexer/target/classes/com/changlu/JVM/Main.class Last modified 2021-11-15; size 548 bytes //修改时间 MD5 checksum bd7bd37fdebcba045aeaafc9a6251d35 //签名 Compiled from "Main.java"public class com.changlu.JVM.Main //类的信息 minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER //类的访问修饰符//2、常量池Constant pool: #1 = Methodref #6.#20 // java/lang/Object."<init>":()V #2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream; #3 = String #23 // Hello,world! #4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V #5 = Class #26 // com/changlu/JVM/Main #6 = Class #27 // java/lang/Object #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 Lcom/changlu/JVM/Main; #14 = Utf8 main #15 = Utf8 ([Ljava/lang/String;)V #16 = Utf8 args #17 = Utf8 [Ljava/lang/String; #18 = Utf8 SourceFile #19 = Utf8 Main.java #20 = NameAndType #7:#8 // "<init>":()V #21 = Class #28 // java/lang/System #22 = NameAndType #29:#30 // out:Ljava/io/PrintStream; #23 = Utf8 Hello,world! #24 = Class #31 // java/io/PrintStream #25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V #26 = Utf8 com/changlu/JVM/Main #27 = Utf8 java/lang/Object #28 = Utf8 java/lang/System #29 = Utf8 out #30 = Utf8 Ljava/io/PrintStream; #31 = Utf8 java/io/PrintStream #32 = Utf8 println #33 = Utf8 (Ljava/lang/String;)V{ //3、类的方法定义 public com.changlu.JVM.Main(); //默认构造 descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 4: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Lcom/changlu/JVM/Main; public static void main(java.lang.String[]); //main方法 descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=1, args_size=1 //4、虚拟机指令 0: getstatic #2 //获取静态变量 // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #3 //加载一个参数 // String Hello,world! 5: invokevirtual #4 //执行虚方法调用 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 8: return LineNumberTable: line 6: 0 line 7: 8 LocalVariableTable: Start Length Slot Name Signature 0 9 0 args [Ljava/lang/String;}SourceFile: "Main.java"可以看到67-69行中的#数字,表示的是查表编号,在jvm使用解释器去执行时,会根据这个#数字去常量池进行查表调用方法
5.4、StringTable特性
5.4.1、总结
1、常量池中的字符串仅是符号,第一次用到时才变为对象
2、利用串池的机制,来避免重复创建字符串对象
3、字符串变量拼接的原理是 StringBuilder (1.8)
4、字符串常量拼接的原理是编译期优化
5、可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
• 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回 • 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
5.4.2、案例演示
5.4.2.1、常量(字节码)
public static void main(String[] args) { //这三个常量在javac一开始编译时就存储了常量池 String s = "a"; String s1 = "b"; String s2 = "ab";}//反编译字节码Constant pool: #1 = Methodref #6.#24 // java/lang/Object."<init>":()V #2 = String #25 // a #3 = String #26 // b #4 = String #27 // ab #5 = Class #28 // com/changlu/JVM/Test #6 = Class #29 // java/lang/Objectstack=1, locals=4, args_size=1 0: ldc #2 // String a,根据#2直接从常量池中取出a 2: astore_1 //存储到变量表中的slot1 3: ldc #3 // String b 根据#3直接从常量池中取出b 5: astore_2 //存储到变量表中的slot2 6: ldc #4 // String ab 根据#4直接从常量池中取出ab 8: astore_3 //存储到变量表中的slot3 9: returnLocalVariableTable: //本地变量表 Start Length Slot Name Signature 0 10 0 args [Ljava/lang/String; 3 7 1 s Ljava/lang/String; 6 4 2 s1 Ljava/lang/String; 9 1 3 s2 Ljava/lang/String;5.4.2.2、常量拼接、常量与字符串对象拼接
+拼接操作:
①常量+常量
public static void main(String[] args) { String s2 = "a" + "b";//对常量直接进行拼接的在javac编译时会直接将拼接好的放入常量池}// 反编译Constant pool: #1 = Methodref #4.#20 // java/lang/Object."<init>":()V #2 = String #21 // ab #3 = Class #22 // com/changlu/JVM/Test #4 = Class #23 // java/lang/ObjectCode: stack=1, locals=2, args_size=1 0: ldc #2 // String ab 2: astore_1 3: return②先常量,后拼接
public static void main(String[] args) { String s = "a"; String s1 = "b"; String s2 = "a" + "b";//javac在编译期间进行优化,直接会将拼接好的字符串放入常量池}// 反编译stack=1, locals=4, args_size=1 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab // 8: astore_3 9: return③常量+对象
public static void main(String[] args) { //1、javac编译期间,会将"a","b"存入到常量池中 //2、java执行,也就是jvm进行执行时首先会进行stringbuilder实例化,接着append("a"),接着从常量池中取到"b",进行String实例化(new String("b")),接着传入到append()方法中,最后toString()返回新的对象 //2完整过程:new StringBuilder().append("a").append(new String("b")).toString() String s = "a" + new String("b");}//反编译Constant pool: #1 = Methodref #11.#27 // java/lang/Object."<init>":()V #2 = Class #28 // java/lang/StringBuilder #3 = Methodref #2.#27 // java/lang/StringBuilder."<init>":()V #4 = String #29 // a #5 = Methodref #2.#30 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; #6 = Class #31 // java/lang/String #7 = String #32 // bCode: stack=4, locals=2, args_size=1 //字节码过程与我上面叙述的大致相同 0: new #2 // class java/lang/StringBuilder 3: dup 4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V 7: ldc #4 // String a 9: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 12: new #6 // class java/lang/String 15: dup 16: ldc #7 // String b 18: invokespecial #8 // Method java/lang/String."<init>":(Ljava/lang/String;)V 21: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore_1 28: return总结:
1. 仅仅对于"xxx"常量,无论是单独声明还是拼接,在javac编译期间就会进行优化直接将拼接好的放入到常量池中。 2. 对于new String("xxx"),在javac编译时就会先将对应的字符串作为常量放入到常量池中,真正在java执行过程中会从常量池里取到"xxx",再进行String的实例化。
5.4.2.3、intern 方法详解
①JDK8
情况1:若是当前字符串在常量池中已经存在,那么本身字符串就不会放入常量池,其返回值是常量池的。
public class Test { public static void main(String[] args) { //*****情况1:先将ab放置到常量池****** String s = "ab"; //********************************** String str = new String("a") + new String("b");//对象 String intern = str.intern();//在本题中"ab"原本就在常量池里,所以这里不需要把str再放入常量池(其本身还是对象),其返回值是常量池中的 System.out.println(s == str); System.out.println(s == intern); }}
情况2:若是当前字符串在常量池中不存在,那么就会将本身字符串放入到常量值(这里指str),其返回值同样也是常量池的。
public class Test { public static void main(String[] args) { String str = new String("a") + new String("b");//对象 String intern = str.intern();//由于常量池中没有"ab",此时就会将str放置到常量池,str指向常量池而不再指向对象,返回值也是常量池中的 //*****情况2:后使用常量"ab",此时就是引用常量的了****** String s = "ab"; //********************************** System.out.println(s == str); System.out.println(s == intern); }}
JDK1.6
②JDK1.6:与1.8实现不同的是,当调用intern()方法时会先对自己本身进行复制一份,若是原本常量池中有则将拷贝那份放入,若是没有就不放入,自身不变,返回值为常量池那份。
所以上面两种情况代码,在jdk1.6中运行都是一样的结果,str本身在调用intern()无论常量池中是否存在其自身都不会改变

5.4.3、面试题
JDK1.8
public class Test { public static void main(String[] args) { String s1 = "a"; String s2 = "b"; String s3 = "a" + "b"; //"ab" String s4 = s1 + s2; // new String("ab")。 String s5 = "ab"; String s6 = s4.intern(); //"ab" 由于调用该方法前常量池已经存在"ab",所以s4本身不会改变,返回值依旧是常量池中的 // 问 System.out.println(s3 == s4);//false System.out.println(s3 == s5);//true System.out.println(s3 == s6);//true String x2 = new String("c") + new String("d");//new String("cd") x2.intern(); //由于"cd"在常量池中并不存在,所以x2会将自己放置到常量池中,x2="cd" String x1 = "cd"; System.out.println(x1 == x2);//true }}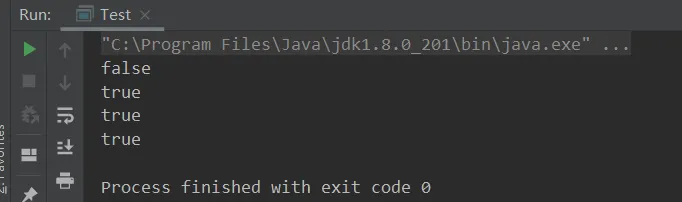
若是14、15行互换
String x1 = "cd"; x2.intern(); //由于"cd"在常量池中存在,所以x2不会将自己放置到常量池中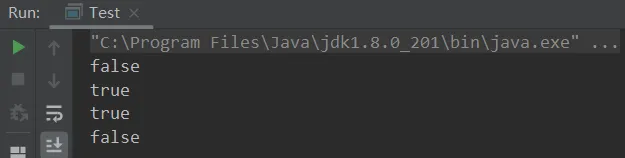
JDK1.6
由于执行intern()会进行拷贝一份,无论常量池中是否存在都会对拷贝的那份进行操作,而不会改变本身,所以无论上下位置是哪里最终都是false
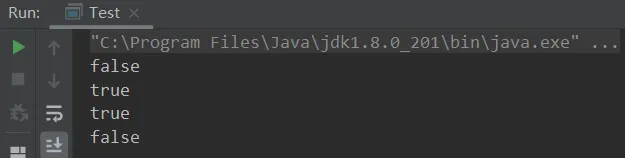
5.5、StringTable的位置(含案例)
示例
JDK1.8常量池在堆中。
JDK1.6在永久代里。
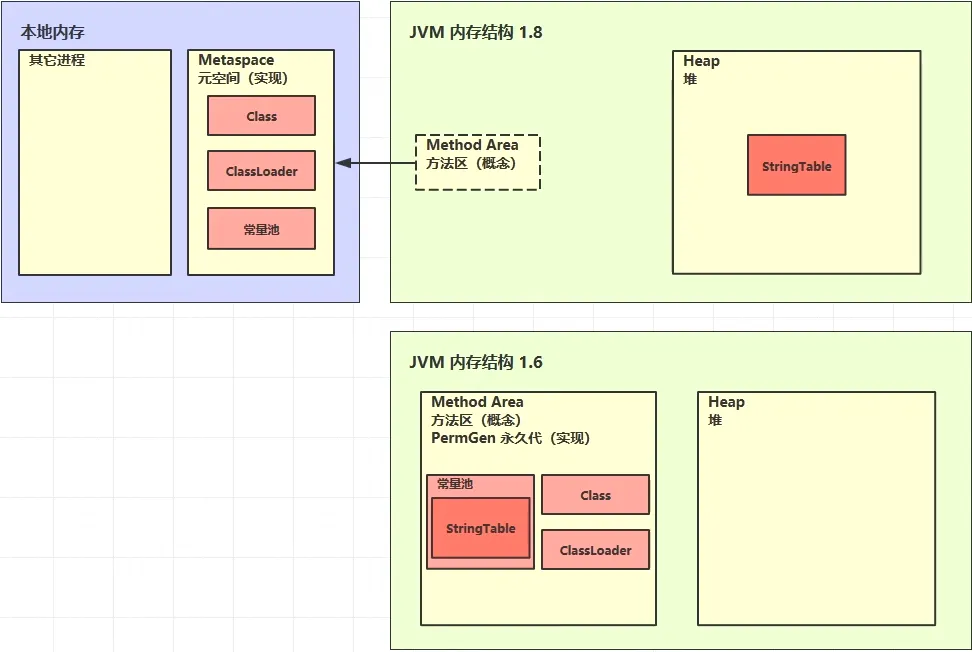
对于JDK8与JDK1.6的位置改变原因:永久代的内存回收效率很低,需要父GC的时候才会触发永久代的垃圾回收,对于父GC需要等待老年代的GC后才会进行GC,触发的时机比较晚,间接的导致StringTable的回收效率并不高。
更改位置后效果:StringTable存储的是十分频繁的常量,若是它的回收效率不高就会占用大量的内存,进而导致永久代的内存不足,因为这个原因自JDK1.7将StringTable转义到堆中,只需要每秒GC都会触发垃圾回收,能够大大减轻了内存的占用。
程序代码
在JDK6和8中进行运行。
/** * 演示 StringTable 位置 * 在jdk8下设置 -Xmx10m -XX:-UseGCOverheadLimit * 在jdk6下设置 -XX:MaxPermSize=10m */public class Main { public static void main(String[] args) throws InterruptedException { List<String> list = new ArrayList<String>(); int i = 0; try { for (int j = 0; j < 260000; j++) { list.add(String.valueOf(j).intern()); i++; } } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } }}①JDK1.6:添加jvm参数选项-XX:MaxPermSize=10m,设置最大永久代容量为10MB
②JDK1.8:-Xmx10m -XX:-UseGCOverheadLimit,两个参数第一个是设置堆内存空间为10MB,第二个参数是针对于将GCOverheadLimit开关关闭(-表示关闭开关,默认开启),若是不关闭jvm会自动进行检测垃圾回收时间大于98%,并且只回收了2%时会直接先抛出GC overhead limit exceeded,而不是堆空间溢出,如下图:
• -XX:+UseGCOverheadLimit介绍
只设置参数:-Xmx10m
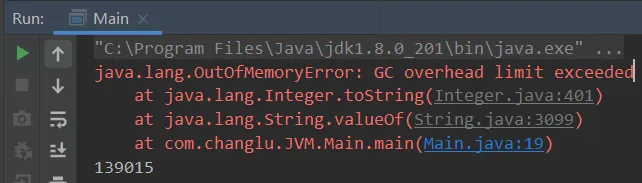
若是我们想要看到堆空间溢出的报错信息需要将检测开关关闭,那么就需要添加上后一条指令:-Xmx10m -XX:-UseGCOverheadLimit
5.6、StringTable的垃圾回收
JDK1.8下演示
使用jvm参数:-Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
首先不创建常量查看信息:
/** * 演示 StringTable 垃圾回收 * -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc * 10MB堆内存 打印常量表信息 打印GC细节 */public class Main { public static void main(String[] args) throws InterruptedException { int i = 0; try { //暂为空 } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } }}//进行了一次垃圾回收[GC (Allocation Failure) [PSYoungGen: 2048K->504K(2560K)] 2048K->933K(9728K), 0.0011077 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]0//堆内存的信息Heap //年轻代、老年代、元空间(方法区) PSYoungGen total 2560K, used 1053K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000) eden space 2048K, 26% used [0x00000000ffd00000,0x00000000ffd89668,0x00000000fff00000) from space 512K, 98% used [0x00000000fff00000,0x00000000fff7e010,0x00000000fff80000) to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000) ParOldGen total 7168K, used 429K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000) object space 7168K, 5% used [0x00000000ff600000,0x00000000ff66b4f0,0x00000000ffd00000) Metaspace used 3132K, capacity 4496K, committed 4864K, reserved 1056768K class space used 337K, capacity 388K, committed 512K, reserved 1048576K//符号表:类名、方法名、变量名等等,读入到内存中,之后以查表方式查询SymbolTable statistics:Number of buckets : 20011 = 160088 bytes, avg 8.000Number of entries : 12988 = 311712 bytes, avg 24.000Number of literals : 12988 = 558664 bytes, avg 43.014Total footprint : = 1030464 bytesAverage bucket size : 0.649Variance of bucket size : 0.649Std. dev. of bucket size: 0.806Maximum bucket size : 6//常量表,底层是hashtable(数组+链表),数组的个数为桶StringTable statistics:Number of buckets : 60013 = 480104 bytes, avg 8.000 //桶个数Number of entries : 1720 = 41280 bytes, avg 24.000 //键值对个数Number of literals : 1720 = 155176 bytes, avg 90.219 //字符串常量//占用的总字节数,约0.6MBTotal footprint : = 676560 bytesAverage bucket size : 0.029Variance of bucket size : 0.029Std. dev. of bucket size: 0.170Maximum bucket size : 2接着我们来创建常量后进行测试
//在上面代码11行添加如下代码,创建常量,这里的字符串常量并没有被引用,所以能够被垃圾回收for (int j = 0; j < 100000; j++) { // j=100, j=10000 String.valueOf(j).intern(); i++;}//可以看到进行垃圾回收了三次[GC (Allocation Failure) [PSYoungGen: 2048K->504K(2560K)] 2048K->965K(9728K), 0.0010164 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC (Allocation Failure) [PSYoungGen: 2552K->504K(2560K)] 3013K->1005K(9728K), 0.0027719 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC (Allocation Failure) [PSYoungGen: 2552K->488K(2560K)] 3053K->1013K(9728K), 0.0024140 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]100000Heap PSYoungGen total 2560K, used 2394K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000) eden space 2048K, 93% used [0x00000000ffd00000,0x00000000ffedc828,0x00000000fff00000) from space 512K, 95% used [0x00000000fff00000,0x00000000fff7a020,0x00000000fff80000) to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000) ParOldGen total 7168K, used 525K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000) object space 7168K, 7% used [0x00000000ff600000,0x00000000ff6834f0,0x00000000ffd00000) Metaspace used 3247K, capacity 4500K, committed 4864K, reserved 1056768K class space used 350K, capacity 388K, committed 512K, reserved 1048576KSymbolTable statistics:Number of buckets : 20011 = 160088 bytes, avg 8.000Number of entries : 13236 = 317664 bytes, avg 24.000Number of literals : 13236 = 566320 bytes, avg 42.786Total footprint : = 1044072 bytesAverage bucket size : 0.661Variance of bucket size : 0.662Std. dev. of bucket size: 0.814Maximum bucket size : 6StringTable statistics: //可以看到当前常量池的数量为35830个,垃圾回收了最起码6万个左右的常量Number of buckets : 60013 = 480104 bytes, avg 8.000Number of entries : 35830 = 859920 bytes, avg 24.000Number of literals : 35830 = 2065872 bytes, avg 57.658Total footprint : = 3405896 bytes //统计总占用为约3MBAverage bucket size : 0.597Variance of bucket size : 0.492Std. dev. of bucket size: 0.702Maximum bucket size : 4结论:在JDK1.8中,由于常量池在堆里,所以很容易能够进行垃圾回收GC,并且在java程序中内存一不够就会自动触发垃圾回收。
5.7、JVM调优
5.7.1、StringTable
总结:若是桶的个数比较多,就比较分散,那么哈希碰撞的几率就会减少,查找的速度也会变快;反之碰撞的几率较大,链表较长,查找的速度也会受到影响。
结论:若是字符串常量比较多的话,可以适当的将字符串也就是字符串常量表设置大,让其有更好的哈希分布,减少哈希冲突。
JDK1.8
程序说明:读取具有46万个左右的字符串,(约4.5MB左右),将字符串全部放入到常量池中。接下里我们来看一下如何进行常量池调优。
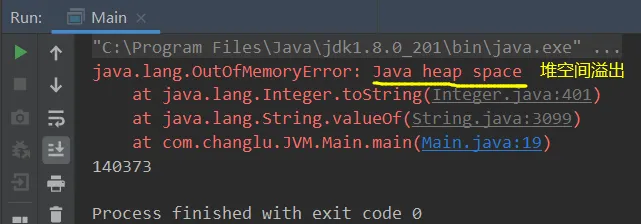
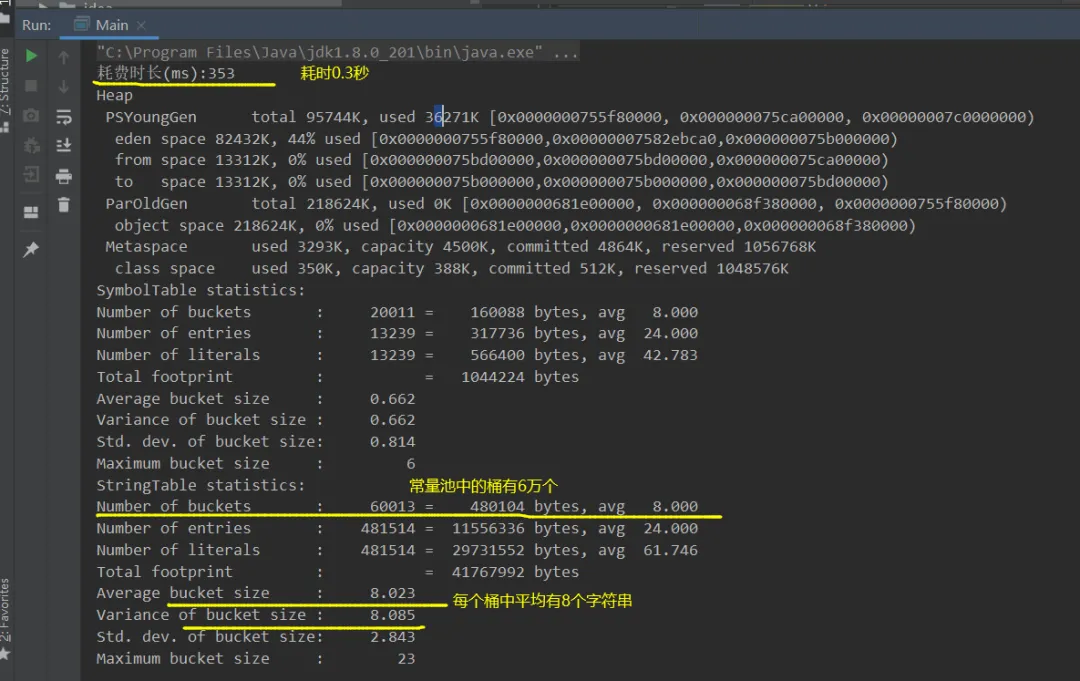
/** * 演示串池大小对性能的影响 * -Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=1009 */public class Main { public static void main(String[] args) throws IOException{ try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), StandardCharsets.UTF_8))){ String line = null; long start = System.nanoTime(); while (true) { line = reader.readLine(); if (line == null){ break; } line.intern();//放入常量池 } //1ms => 1000000ns System.out.println("耗费时长(ms):" + (System.nanoTime() - start) / 1000 / 1000); } }}1、首先来看一下原始常量池中的桶数量以及运行的效率
vm参数:-XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc。打印常量池表以及GC垃圾回收信息
分析:jdk1.8的常量池在堆中,堆一般为4G,所以不会在此次运行过程中不会触发垃圾回收。
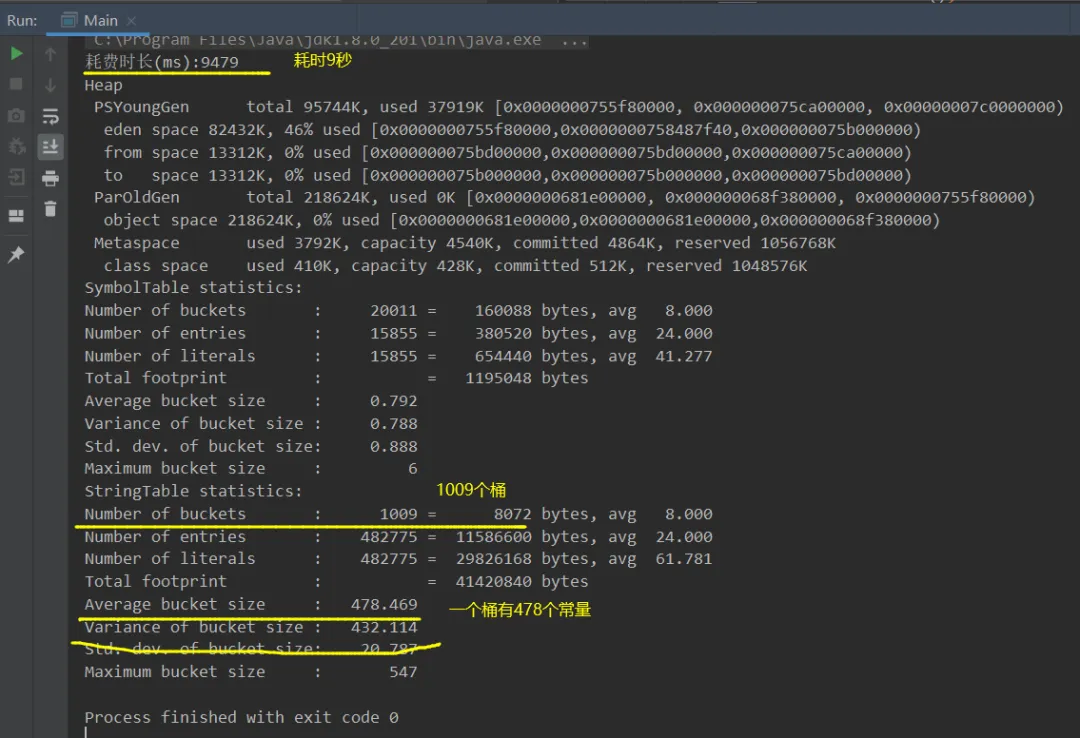
错误示范:将常量池中的桶数量设置最小1009个
• vm参数: -XX:StringTableSize=1009 -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
分析:由于桶数量只有1009个,字符串常量有48万左右,那么就很容易出现哈希碰撞,并且每个桶(数组某个)的链表过长,若是出现哈希冲突,每插入一个字符串常量就会比对大量此时,此时也就造成了我们程序运行时长很长的问题!
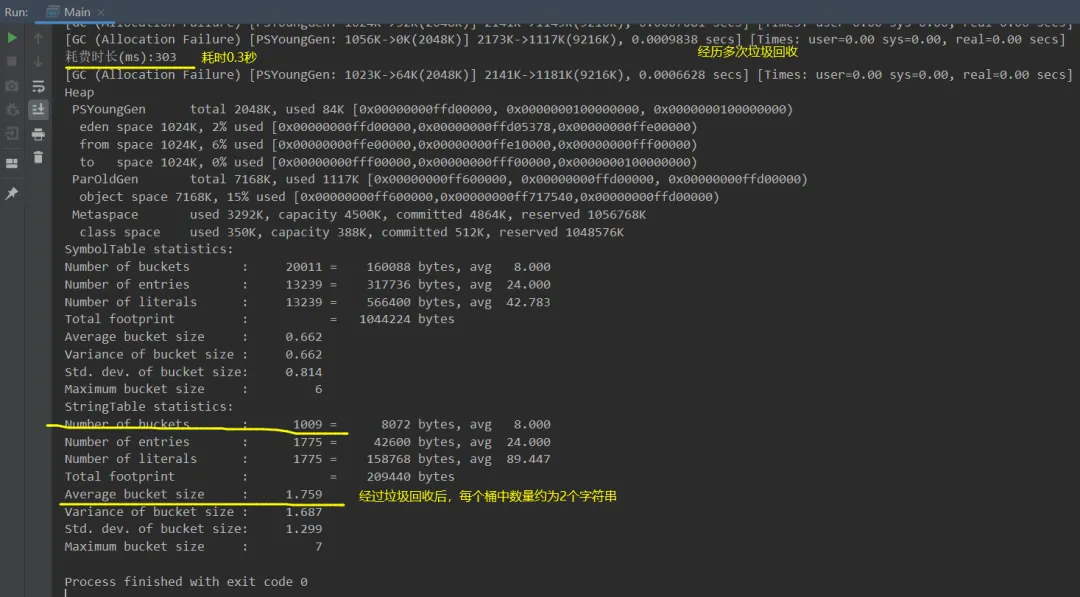
调优1:若是设置桶1009个情况下,我们可以通过限制堆内存来让程序给我们进行GC垃圾回收,减少常量池中的常量数量,达到优化的效果。
• vm参数: -Xmx10m -XX:StringTableSize=1009 -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc。这里设置堆内存为10MB,这样能够不断进行GC垃圾回收。
调优2:设置一个适宜的堆内存空间以及能够均匀分配指定数量的桶个数
• vm参数: -Xms200m -Xmx200m -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc。设置桶的个数为20万个,这样每个桶就平均装2个,减少哈希碰撞与链表比较。
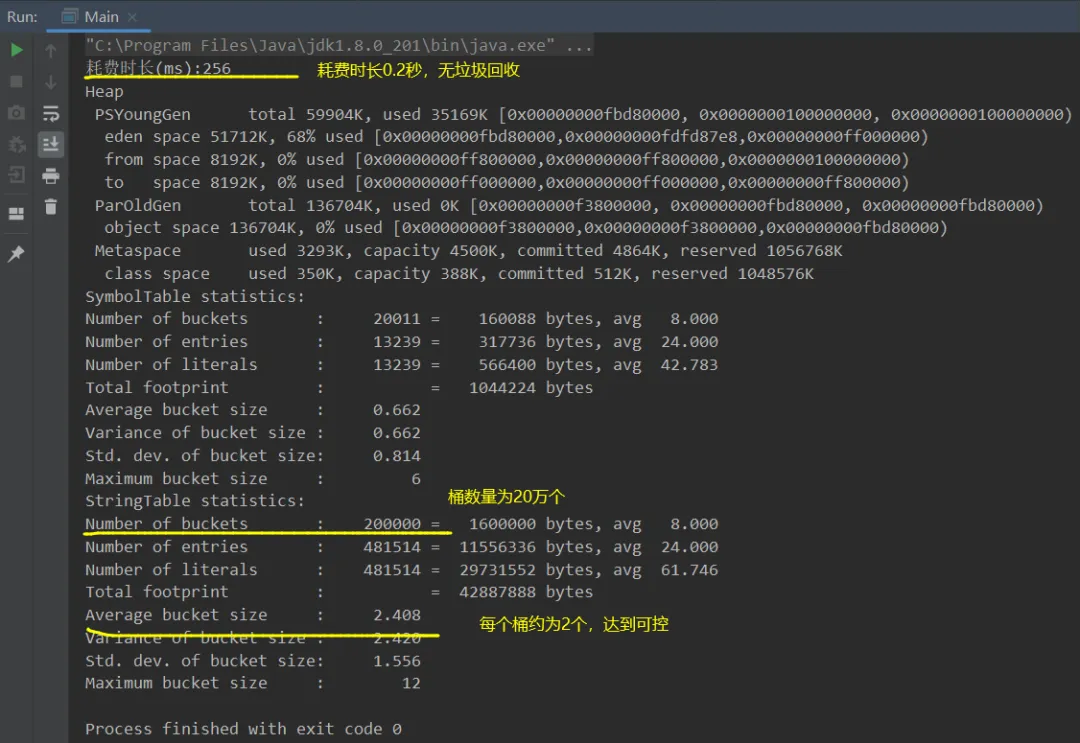
5.7.2、大量重复的字符串案例(调优)
案例描述:若是程序中有大量的重复字符串创建,我们可以通过将字符串放入常量池的方式来节省内存!
/** * 演示 intern 减少内存占用 * -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics * -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000 */public class Main { public static void main(String[] args) throws IOException { List<String> address = new ArrayList<>(); System.in.read();//敲回车向下执行 for (int i = 0; i < 10; i++) { //循环10次模拟出大量字符串重复情况 //读取48万个字符串 try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) { String line = null; long start = System.nanoTime(); while (true) { line = reader.readLine(); if(line == null) { break; } address.add(line);//直接将字符串添加到集合中 //address.add(line.intern()); } System.out.println("cost:" +(System.nanoTime()-start)/1000000); } } System.in.read(); }}使用第21行代码来将字符串添加到记录中,使用jvisualvm来进行检测:
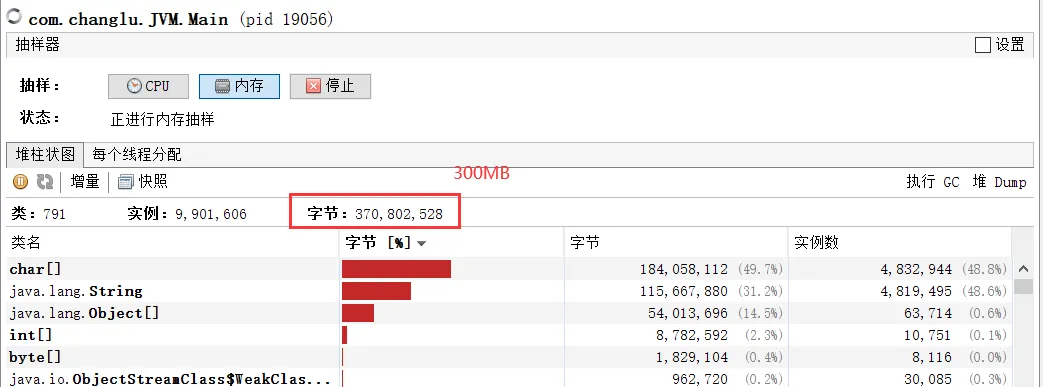
可以看到使用了300MB的内存,接下来我们通过修改代码来进行优化:
//第21行代码修改为intern()address.add(line.intern());结果:可以看到再次运行时占用的字节数为55MB,减少了6倍。
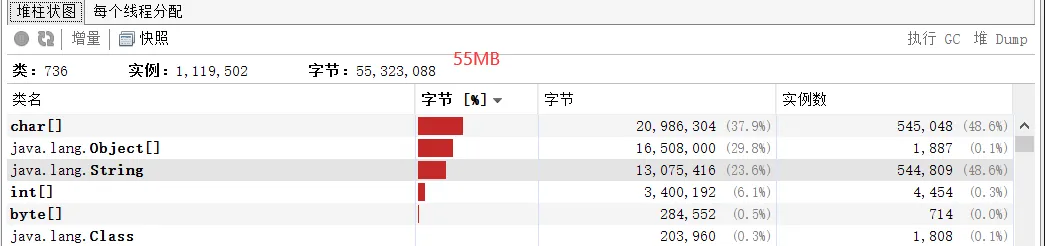
分析:使用了intern()会进行尝试将当前的字符串对象放入到常量池中,若是常量池有则放入,没有则不放入,返回的是常量池中的字符串引用(相同字符串引用的都是同一个地址),那么此时集合中添加的就不是堆中的引用,过程中在堆中创建的字符串对象由于没有被引用会被垃圾回收掉!
六、直接内存
6.1、定义
Direct Memory:直接内存,并不属于java虚拟机的内存管理,而是属于操作系统的内存。
• NIO有一个ByteBuffer,这个ByteBuffer所使用与分配的内存就是直接内存,它不属于jvm管理。 • 传统的IO是阻塞IO。
三个特点:
1. 常见于 NIO 操作时,用于数据缓冲区。 2. 分配回收成本较高,但读写性能高。 3. 不受 JVM 内存回收管理。(通过一个虚引用来进行的)
6.2、IO与直接内存比较
6.2.1、比较案例演示
案例描述:一个是使用普通IO进行输入输出、另一个使用直接内存来进行输入输出。操作的视频大小为310MB。
import java.io.*;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;public class Main { static final String FROM = "C:\\Users\\93997\\Desktop\\新建文件夹\\from\\math.mp4"; static final String TO = "C:\\Users\\93997\\Desktop\\新建文件夹\\to\\math1.mp4"; static final int _1Mb = 1024 * 1024; public static void main(String[] args) { io(); // io 用时:606.3063 directBuffer(); // directBuffer 用时:246.3773 } private static void directBuffer() { long start = System.nanoTime(); try (FileChannel from = new FileInputStream(FROM).getChannel(); FileChannel to = new FileOutputStream(TO).getChannel(); ) { ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);//反转指针指向:读/写指针position指到缓冲区头部 while (true) { int len = from.read(bb); if (len == -1) { break; } bb.flip(); to.write(bb); bb.clear(); } } catch (IOException e) { e.printStackTrace(); } long end = System.nanoTime(); System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0); } private static void io() { long start = System.nanoTime(); try (FileInputStream from = new FileInputStream(FROM); FileOutputStream to = new FileOutputStream(TO); ) { byte[] buf = new byte[_1Mb]; while (true) { int len = from.read(buf); if (len == -1) { break; } to.write(buf, 0, len); } } catch (IOException e) { e.printStackTrace(); } long end = System.nanoTime(); System.out.println("io 用时:" + (end - start) / 1000_000.0); }}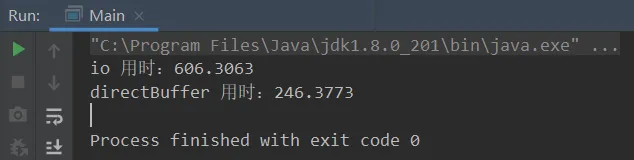
结论:使用直接内存来进行读取输出效率比普通IO要高!
6.2.2、直接内存原理分析
传统的IO操作:
1. 首先会从用户态切换到内核态(CPU的状态变化),切换到内存态之后可以使用c语言的函数去真正读取磁盘文件的内容。 2. 切换到内存态之后会在操作系统中划分出来一块缓冲区(系统缓冲区),接着会先将磁盘文件的内容读取到系统缓冲区,注意java代码是不能够对磁盘文件进行读写操作的。 3. java的话会在堆内存之中分配一块java缓冲区(如new byte[1024]),之后就会不断的从系统缓冲区读取数据到java缓冲区。 4. CPU会再次切换到用户态后进行读取输入输出文件操作(针对于java缓冲区进行操作),最终将文件复制到目标位置。
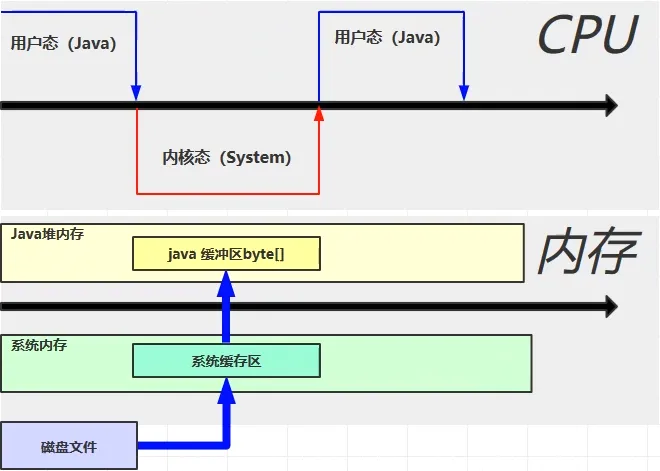
在这个过程中实际相当于会复制两份的操作,造成不必要的数据复制,效率不是很高。
直接内存(direct memory):会划分出一块直接内存区域,在这块区域我们java代码可以直接进行访问,系统也同样可以访问,两块代码是系统共享的一块区域,之后磁盘读取的文件会读取到直接内存,之后java代码同样也可以访问到这块直接内存中。
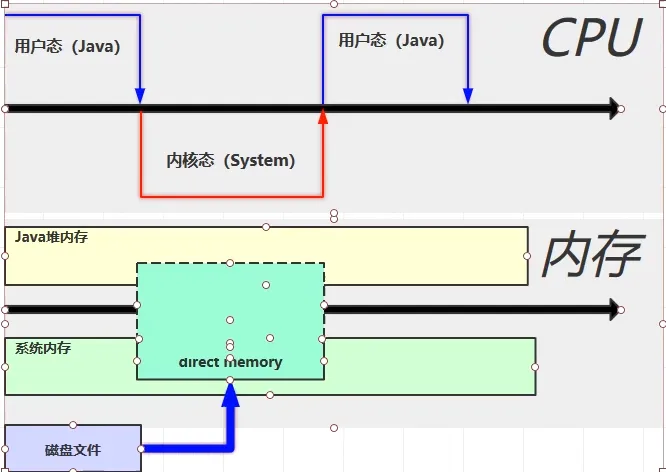
本质:比之前的IO少复制了一次缓冲区的操作,提高了效率。
6.2.3、直接内存-内存溢出
代码说明:每次分配1G直接内存空间,不断循环直到抛出内存溢出报错。
public class Main { static int _100Mb = 1024 * 1024 * 100; public static void main(String[] args) throws IOException { List<ByteBuffer> list = new ArrayList<>(); int i = 0; System.in.read(); try { while (true) { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);//分配直接内存1G list.add(byteBuffer); i++; } } finally { System.out.println(i); System.in.read(); } }}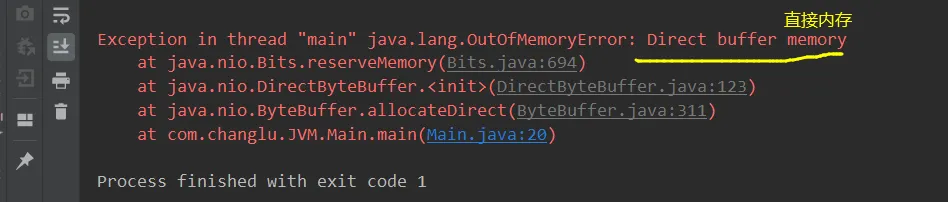
说明:直接内存不由JVM来进行管理,但是对于直接内存的申请创建也是有限制的,差不多4G左右内存。
6.3、直接内存(释放原理)
6.3.1、GC垃圾回收释放?
下面的程序我们来尝试使用显示GC垃圾回收的方式来释放直接内存:
import java.io.*;import java.nio.ByteBuffer;public class Main { static int _1Gb = 1024 * 1024 * 1024; /* * -XX:+DisableExplicitGC 显式的 */ public static void main(String[] args) throws IOException { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb); System.out.println("分配完毕..."); System.in.read(); System.out.println("开始释放..."); byteBuffer = null; System.gc(); // 显式的垃圾回收,Full GC,对年轻代、老年代都进行垃圾回收,开销较大 System.in.read(); }}可以看到当前分配了1G的内存空间


此时就会有疑问了,之前不是说直接内存不受JVM管理嘛,那为什么这里调用GC垃圾回收方法能够将直接内存回收呢?答案:借助虚引用实现,真正分配与释放借助Unsafe这个类。
6.3.2、释放与分配原理探究(Unsafe类)
Unsafe类:干一些分配或释放直接内存的事情,一般都是JDK内部会进行这样一些操作。
案例描述:通过Unsafe来进行分配与释放直接内存。
import sun.misc.Unsafe;import java.io.*;import java.lang.reflect.Field;public class Main { static int _1Gb = 1024 * 1024 * 1024; public static void main(String[] args) throws IOException { Unsafe unsafe = getUnsafe(); // 分配内存 long base = unsafe.allocateMemory(_1Gb); unsafe.setMemory(base, _1Gb, (byte) 0); System.out.println("已分配直接内存"); System.in.read(); // 释放内存 unsafe.freeMemory(base); System.out.println("释放直接内存"); System.in.read(); } //借助反射来获取到Unsafe实例 public static Unsafe getUnsafe() { try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); Unsafe unsafe = (Unsafe) f.get(null); return unsafe; } catch (NoSuchFieldException | IllegalAccessException e) { throw new RuntimeException(e); } }}效果:可以看到通过Unsafe类可以对直接内存进行分配与释放,那么其实我们可以联想到之前的分配内存空间以及垃圾回收肯定也与这个Unsafe类有关!
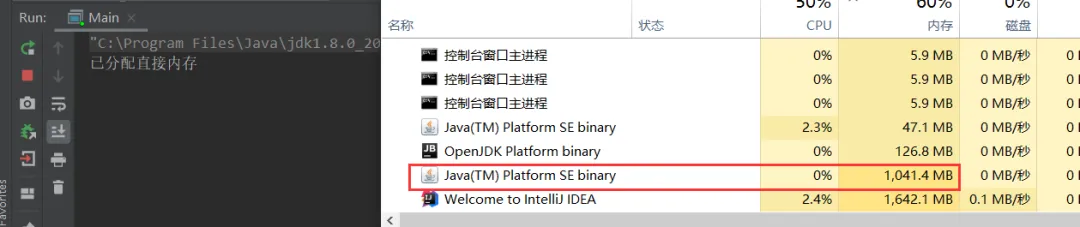

6.3.3、源码深入(案例+源码)
之前分配直接内存、释放直接内存的代码我们调用的是如下两条:
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);//分配直接内存System.gc();//显示垃圾回收 Full GC分配直接内存
直接看源码即可:内部通过Unsafe来进行分配内存,并且与此同时创建一个虚引用绑定该ByteBuffer实体类,一旦该实体类不被引用进行垃圾回收时就会调用clean()方法来进行
public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity);}DirectByteBuffer(int cap) { super(-1, 0, cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L, (long)cap + (pa ? ps : 0)); Bits.reserveMemory(size, cap); long base = 0; try { base = unsafe.allocateMemory(size);//使用Unsafe类来进行分配直接内存 } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); if (pa && (base % ps != 0)) { // Round up to page boundary address = base + ps - (base & (ps - 1)); } else { address = base; } //Cleaner:虚引用类型,若是所关联的对象(指的是bb)被回收时,那么Cleaner就会触发该虚引用的clean方法,该方法中就会执行对应的回调方法(就是第二个参数Deallocator中的run()方法)。对应在后台一个reference线程里执行,该线程会专门检测这些虚引用的情况,一旦虚引用对象关联的实际对象被回收掉以后就会调用该虚引用的clean方法。然后执行任务对象,最终任务对象再来真正执行freeMemory方法。 cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); att = null;}//************看一下Cleaner类**************public class Cleaner extends PhantomReference<Object> { private Cleaner(Object var1, Runnable var2) { super(var1, dummyQueue); this.thunk = var2; } //第二个参数就是调用指定的回调方法 public static Cleaner create(Object var0, Runnable var1) { return var1 == null ? null : add(new Cleaner(var0, var1)); } //一旦虚引用关联的对象被回收就会执行这个方法 public void clean() { if (remove(this)) { try { //触发回调方法,来进行垃圾回收,见下面的 this.thunk.run(); } catch (final Throwable var2) { AccessController.doPrivileged(new PrivilegedAction<Void>() { public Void run() { if (System.err != null) { (new Error("Cleaner terminated abnormally", var2)).printStackTrace(); } System.exit(1); return null; } }); } } }}//真正进行直接内存回收的位置private static class Deallocator implements Runnable{ private static Unsafe unsafe = Unsafe.getUnsafe(); private long address; private long size; private int capacity; private Deallocator(long address, long size, int capacity) { assert (address != 0); this.address = address; this.size = size; this.capacity = capacity; } //clean()方法执行触发该run()方法,还是调用的Unsafe来执行清理直接内存操作 public void run() { if (address == 0) { // Paranoia return; } //清理直接内存 unsafe.freeMemory(address); address = 0; Bits.unreserveMemory(size, capacity); }}System.gc();//显示垃圾回收 Full GC
接下来说明一下为什么要额外进行调用下面的代码来进行直接内存的垃圾回收:
byteBuffer = null; //不进行引用System.gc(); // 显式的垃圾回收,Full GC,对年轻代、老年代都进行垃圾回收,开销较大一般来说只有在内存空间不足的情况下会进行垃圾回收,若是byteBuffer不进行引用,可能不会触发GC垃圾回收。这也就是为什么我们还要显示调用GC的原因。
一旦byteBuffer不被引用,那么对应的虚引用就会被触发其中的clean()方法来进行释放直接内存操作,这一操作是一个守护进程完成的!
总结:垃圾回收只能释放java的内存,对于直接内存需要我们手动来去调用unfase的freeMemory方法来完成对内存的释放。
6.3.4、直接内存释放最好方式
若是直接使用显示GC方法调用来进行清理直接内存,其实是不太妥当的,因为该显示调用是进行Full GC,无论是年轻代还是老年代都会进行垃圾回收操作,在程序中占用的开销较大。
推荐使用unsafe来进行手动管理直接内存。就是6.3.2案例来进行直接内存的垃圾回收!
6.4、JVM调优(禁用GC垃圾回收)
JVM参数:-XX:+DisableExplicitGC,禁止显示进行GC垃圾回收。
原因:避免程序中有手动进行GC垃圾回收的操作,显示GC是Full GC,会有一定的开销,所以在进行调优时禁用。
import java.io.*;import java.nio.ByteBuffer;public class Main { static int _1Gb = 1024 * 1024 * 1024; /* * -XX:+DisableExplicitGC 显式的 */ public static void main(String[] args) throws IOException { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb); System.out.println("分配完毕..."); System.in.read(); System.out.println("开始释放..."); byteBuffer = null; System.gc(); // 显式的垃圾回收,Full GC,对年轻代、老年代都进行垃圾回收,开销较大 System.in.read(); }}
参考文章
[1]. java.nio.Buffer 中的 flip()方法


END

扫码二维码
获取更多精彩
感谢您的关注




