Claude Code 学习笔记之二:理解 Sessions 机制
- 2026-04-22 08:06:48
本系列之前的文章:
Claude Code 学习笔记之一:理解 Agentic Loop 与内置工具
笔者每天的日常工作,在命令行里进入某个代码工程文件夹下,执行 claude 命令行进入 Claude Code 的交互模式。
使用命令 /status 可以看到当前新创建的会话 ID,下图是一个例子。
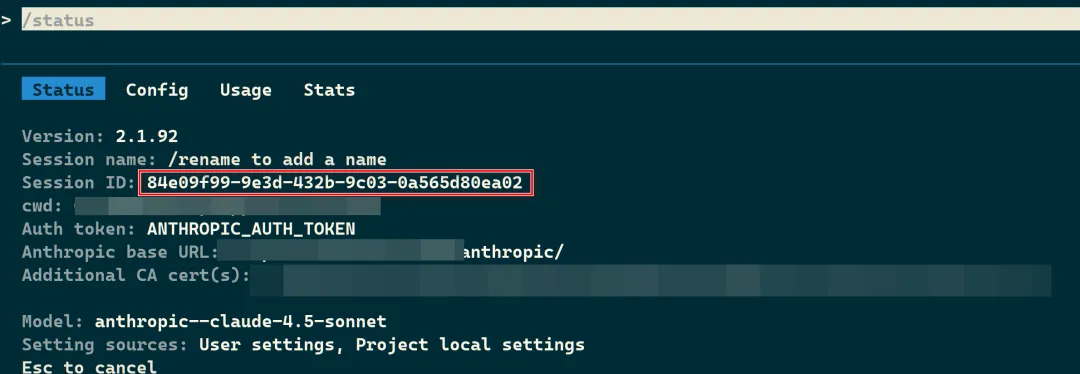
Claude Code 在我们工作时会自动将对话保存到本地。
每一条消息、每一次工具调用及其结果,也就是笔者前一篇文章提到的 Agentic Loop 的细节,都会被写入到 ~/.claude/projects/ 目录下的纯文本 JSONL 文件中。
笔者上图新建的以 ea02 结尾的 session ID,对应下图这个本地文件:
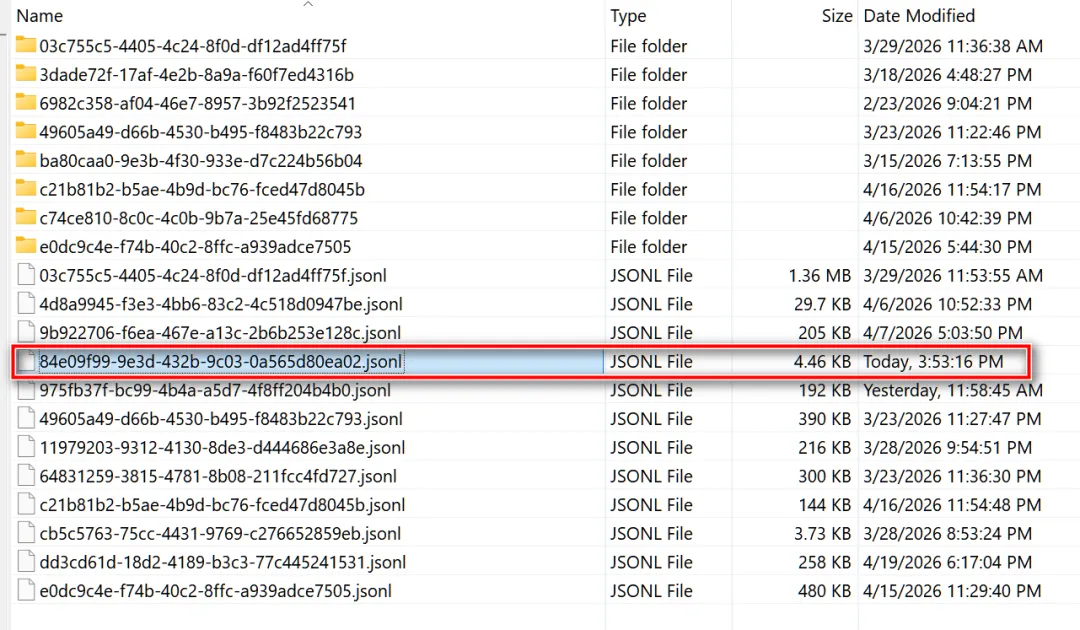
这种设计是 Claude Code 会话的回退(rewind)、恢复(resume)和分支(fork)等功能的技术实现基础。
在 Claude Code 修改代码之前,它还会为受影响的文件创建快照,方便我们在需要时进行回滚。
Claude Code 创建的会话彼此之间是相互独立的。
每个新会话都从一个全新的上下文窗口开始,不会继承之前会话的对话历史。
Claude Code 可以通过自动记忆(auto memory)机制在不同会话之间持久化学习成果。
所谓 auto memory,是 Claude Code 在 ~/.claude/projects/
这套系统会自动记录用户的角色偏好、反馈意见、项目信息和外部资源引用等关键信息。
每条记忆都以独立的 Markdown 文件存储,包含名称、描述和类型等元数据。
当我们在新会话中继续工作时,Claude Code 会根据当前对话的相关性自动加载这些记忆,让 AI 能够记住我们的工作习惯、技术偏好和项目背景。
这种机制避免了每次新建会话都要重新解释上下文的麻烦,特别是对于长期维护的项目来说,auto memory 让 Claude Code 能够真正"认识"我们和我们的代码库。
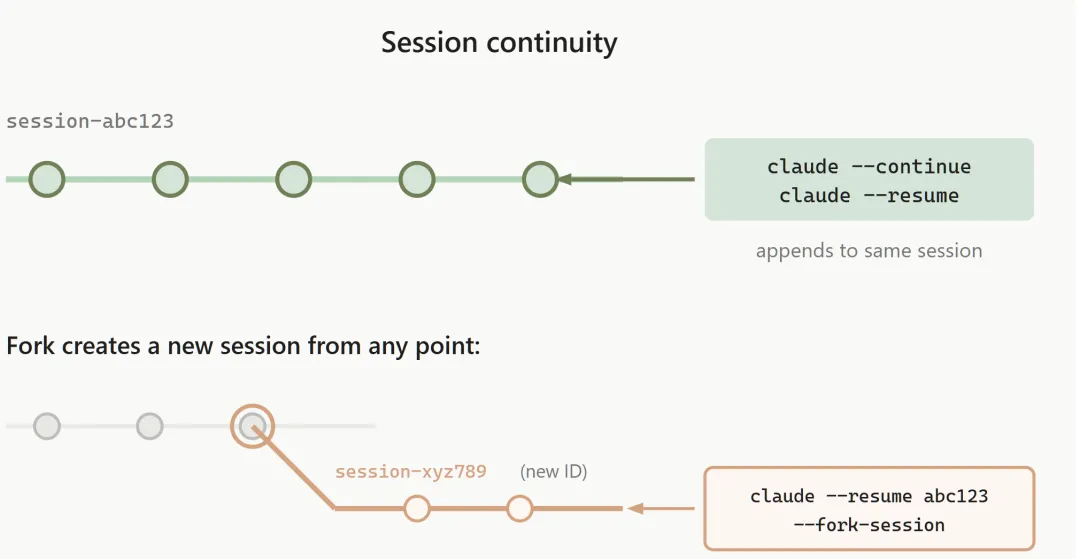
恢复或分支会话
当我们使用 claude --resume 命令行之后,会看到一个过去进行过的会话列表。使用上下箭头可以选择要恢复的会话,之后即在原来的会话上继续工作,会话 ID 保持不变。
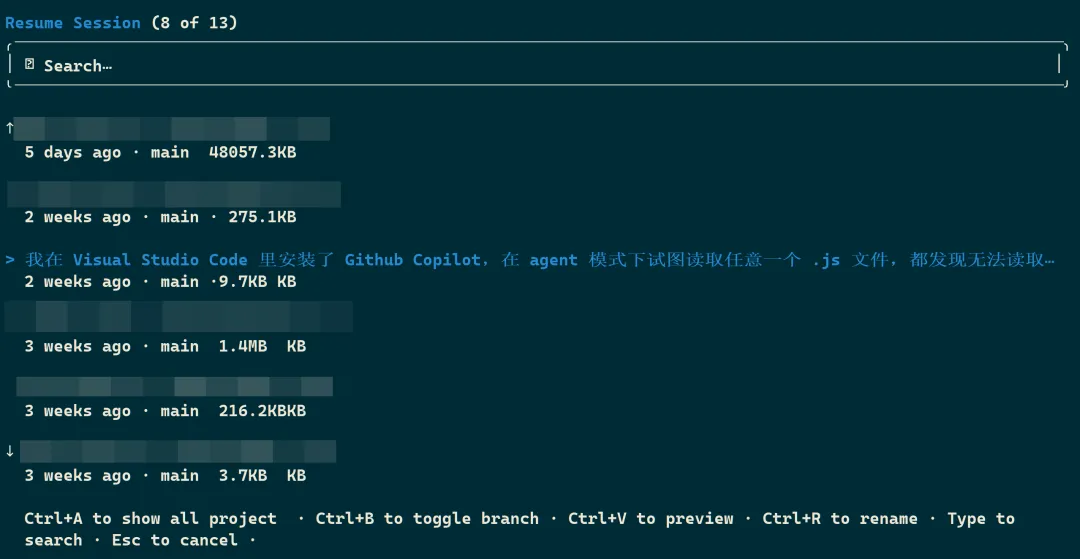
新的消息会追加到现有对话中。虽然完整的对话历史会被恢复,但会话级别的权限设置不会被保留,我们需要重新审批这些权限。
比如恢复会话后,仍然需要显式批准下面这种操作系统层级命令行的执行:
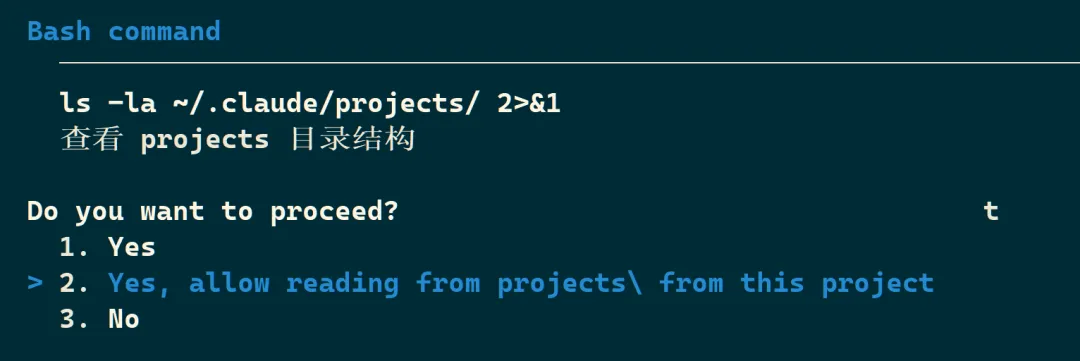
resume 命令延续的是同一个会话,而 fork 则创建一个新的分支,并生成新的会话 ID。
如果我们想尝试不同的实现思路,又不想影响原始会话,可以使用 --fork-session 标志:
claude --continue --fork-session这个命令的设计思路类似 git 的分支概念,会创建一个新的会话 ID,同时保留到分支点为止的所有对话历史,而原始会话始终保持不变。
如果我们在多个终端窗口中恢复同一个会话,这些终端会同时写入同一个会话文件。来自不同终端的消息会交错出现,就像两个人在同一个笔记本上写字一样。
我们可以回顾一下 ChatGPT 的会话概念,一个 chat 内可以进行多轮会话,用 guid 标识。
不过因为是运行在浏览器端,所以本地没有持久化,每次访问 url 时,从服务器端获取 chat 内容。
下面是一个例子。
https://chatgpt.com/c/69e72e46-1df0-83ab-81ba-35b84d19e074
ChatGPT 的 chat 内部也没有版本控制功能。
当我们使用 Claude Code 准备修改文件时,系统会自动扫描即将被修改的文件,将其编辑前的原始内容备份到 file-history 目录下。
这些备份内容通过分别的文件进行单独存储,文件命名规则为内容的哈希值加上 @v2, @v3 等后缀。文件可以用文本编辑器打开。
比如 5a63a8f23e018b90@v2

这些不同版本的备份文件是 Claude Code 撤销操作的核心数据源。
当我们对 Claude Code 的代码修改不满意时,可以按下两次 Esc 作为快捷键来触发撤销流程。系统会从 file-history 中读取备份的原始内容,覆盖当前文件,完成撤销操作。

