先理解一句话
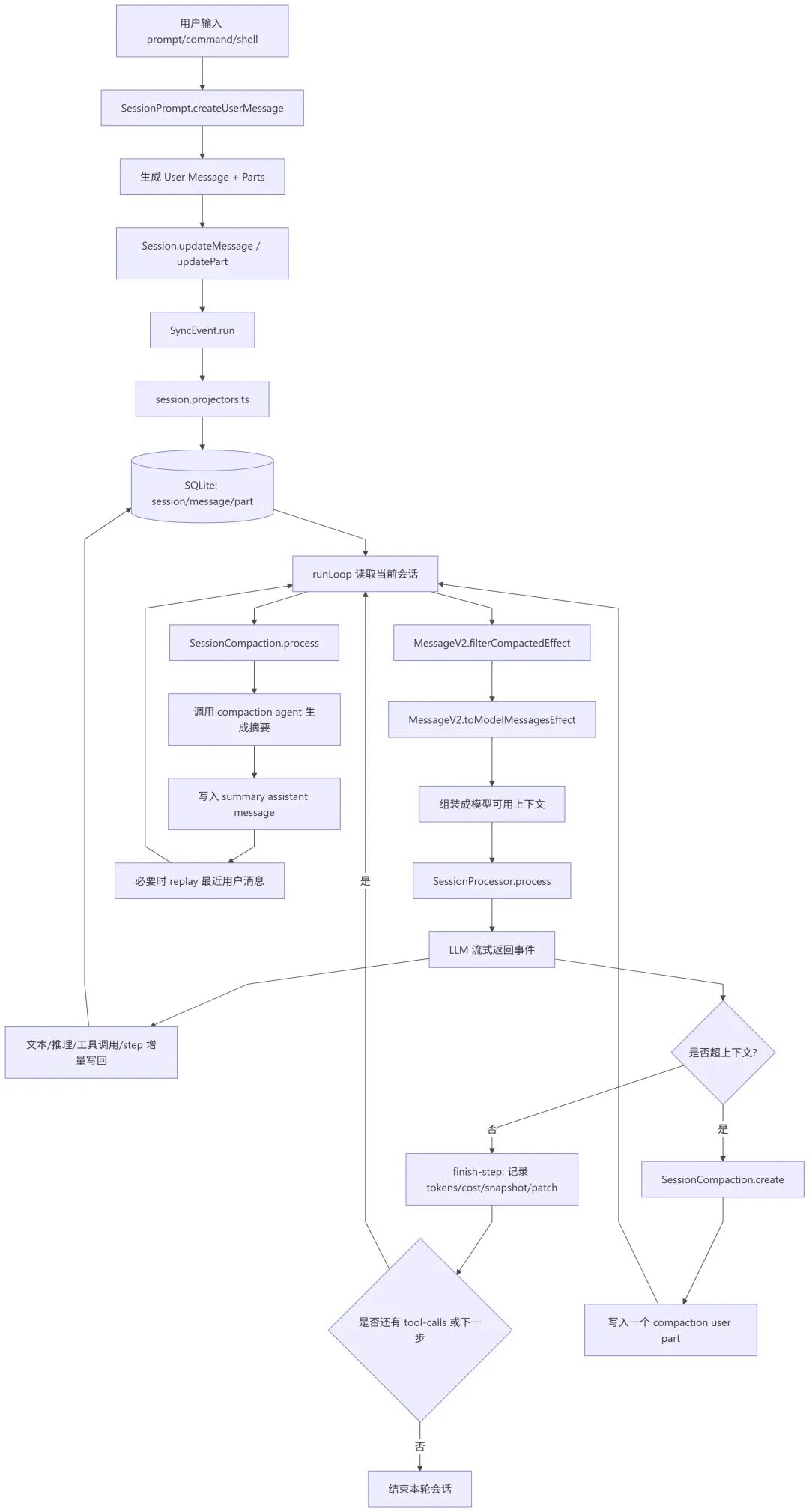
用户说一句话 -> OpenCode 保存下来 -> 拼出上下文发给模型 -> 模型边回答边写回数据库 -> 如果上下文太长就自动压缩总结 -> 再继续聊。
一些概念
Session 像一个“会话文件夹”,里面装着这一轮对话的所有内容。Message 像一条“发言记录”,比如用户说的话、AI 回的话。Part 像“发言里的小片段”,比如正文、推理、工具调用、附件、补丁结果。SQLite 像“本地档案柜”,所有会话都最终存进去。LLM 就是大模型。Compaction 就像“会议太长了,先写个摘要,再继续开会”。
第一步:用户输入是怎么进系统的
- 你在界面里输入 prompt,或者执行 command、shell,系统先进入 prompt.ts 的
SessionPrompt.createUserMessage 这一层。 - 系统不会把你的输入当成一整坨文本直接塞进去,而是拆成“消息 + 片段”。
- 比如你只是打字,它会生成一个
user message 和一个 text part。 - 如果你还附带了文件、图片、agent、子任务,它会生成多个不同类型的
part。
第二步:为什么还要拆成 Message 和 Parts
- 因为 AI 回复不是一次性完整出来的,而是“流式”出来的。
- 如果只存一整条消息,AI 打字到一半、工具执行到一半,就很难实时更新。
- 所以 OpenCode 能边生成边显示,这就是它比较强的地方。
第三步:数据怎么真正落库
系统调用index.ts里的 Session.updateMessage / Session.updatePart。- 这里不会立刻直接写数据库,而是先触发
SyncEvent.run。 - 然后由 projectors.ts 统一把这些事件“投影”到数据库表中。
- 你可以把它理解成:业务逻辑先“记一条事件”,再由专门的“记账员”把事件写到账本里。
第四步:数据库里到底存了什么
session表:存“这次会话”的信息,比如标题、目录、父子关系、更新时间。message表:存“这条消息”的基本信息,比如 role 是 user 还是 assistant。part表:存“这条消息的具体内容碎片”,比如文本、tool、file、reasoning。
第五步:模型回答前,系统会先把历史对话整理一遍
- 主循环
runLoop 会先把当前会话的历史记录读出来,代码在 prompt.ts。 - 先经过
MessageV2.filterCompactedEffect。 - 如果以前已经做过“摘要压缩”,那一些已经被摘要覆盖的旧消息,就不必再整段喂给模型了。
- 然后进入
MessageV2.toModelMessagesEffect,把数据库里的 message + part 转成模型真正能理解的上下文格式。
第六步:为什么还需要“组装上下文”
- 因为数据库里的结构是给系统存储用的,不是直接给模型看的。
1.text part要变成模型消息里的文本内容。2.tool part要变成 tool-call / tool-result。3.file part要变成附件。
第七步:模型开始工作后发生什么
- 上下文组装完成后,进入
SessionProcessor.process,代码在 processor.ts。
1.开始输出文本
2.输出一小段文本
3.开始 reasoning
4.输出 reasoning 片段
5.发起一次工具调用
6.工具执行成功或失败
7.一个 step 结束
第八步:为什么 AI 的回复可以一边生成一边显示
- 因为每收到一个流式事件,系统就会把增量内容写回数据库。
- 2.来一个 reasoning 增量,就更新 reasoning part4.工具完成,就把 tool part 状态改为 completed
- 所以前端并不是“猜 AI 在干嘛”,而是直接读取数据库里这些实时变化的 part。
- 这也是为什么 OpenCode 的会话回放会比较完整。
第九步:finish-step 是干什么的
- 这条“没超上下文”的分支里,
finish-step 会记录很多关键信息:
1.本轮 token 用量
2.本轮 cost
3.快照 snapshot
4.代码改动 patch
1.费用统计
2.会话总结
3.上下文超限判断
4.文件变更回溯
相关逻辑在 processor.ts。
第十步:为什么结束后还可能继续回到
- 如果模型刚才只是调用了工具,或者还有后续步骤没做完,那就不能停。
- 于是重新读取当前会话,再组一次上下文,再喂给模型。
- 你可以理解成:AI 每做完一步,都会重新看看现场,再决定下一步做什么。
第十一步:什么叫“超上下文”
- 模型能看的历史不是无限的,它有 token 上限。
- 当这轮对话越来越长,历史、附件、工具输出越来越多,就可能塞不进模型上下文窗口。
- 它还会额外预留一部分缓冲,不会把窗口塞到 100%。
第十二步:超上下文后为什么不是直接报错
- OpenCode 比较聪明,它会先尝试“压缩会话”,而不是直接失败。
- 先走
SessionCompaction.create。 - 它会写入一个特殊的
compaction user part。 - 你可以把这个 part 理解成一句系统内部的提示:
第十三步:压缩流程是怎么工作的
- 下一轮 runLoop 读到这个 compaction part,就知道现在不能直接正常继续,而是要先进入
SessionCompaction.process。 - 系统调用一个专门的
compaction agent,让它根据旧对话生成摘要。
1.用户目标是什么
2.已完成什么
3.当前做到哪一步
4.哪些文件相关
5.之后该继续什么
第十四步:摘要生成后怎么接回原对话
- 摘要会被写成一条
summary assistant message。 - 也就是说,系统会把很长的旧对话浓缩成一条“可续聊摘要”。
- 这是为了避免只保留摘要后,模型忘了“刚刚最后一个具体问题是什么”。
- 然后重新回到主循环,基于“摘要 + 最近关键消息”继续往下做。
第十五步:为什么压缩后还能继续工作
- 这就是
filterCompactedEffect 存在的意义。
第十六步:整张图里最关键的 4 个模块
- processor.ts:负责模型流式执行,像“执行引擎”。
- message-v2.ts:负责消息结构和上下文转换,像“翻译器 + 数据结构层”。
- compaction.ts:负责超长上下文压缩,像“摘要秘书”。
如果还看不懂,可以记住这条最简单主线
一句更白话的总结
先记账再思考边思考边记账太长了就先写总结然后接着干