企业IT资产定期巡检是保障企业整体运维安全的关键环节。而传统的巡检模式存在诸多痛点。首先是费时费力,登录服务器、敲命令、查日志、看监控大盘,一台台机器折腾下来,半天时间就没了;然后是数据离散分布,技术指标(CPU、内存、数据库性能数据等)分散在Prometheus的各类监控面板中,而业务状态等非技术指标则记录在JumpServer等业务系统里,各系统之间缺乏关联,难以形成完整的资产健康视图;报告方面,不同的人执行巡检,得出的结论和报告格式往往五花八门,难以标准化和存档。而巡检操作通常也比较僵化,大部分的巡检报告只是数据的堆砌,缺乏对潜在风险的预判和根因分析。
在AI时代,系统巡检应该有更好的解决办法。基于MaxKB开源企业级智能体平台的工作流编排能力,结合Prometheus和大语言模型(LLM),我们尝试为JumpServer堡垒机打造了一套自动化、智能化的巡检系统。这套巡检系统可以将系统巡检时间从数小时缩短至分钟级别,并且可以输出具有一致性和专业性的巡检报告。
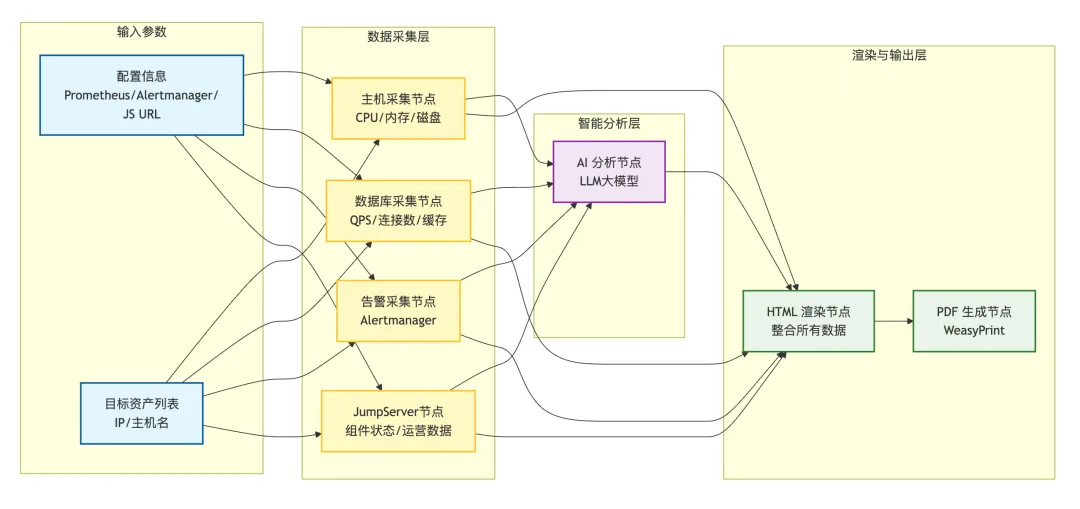
本方案采用的是“数据采集+智能分析+报告渲染”的分层架构设计,通过MaxKB工作流串联各个环节。该系统的核心组件包括:
■ MaxKB:作为总控大脑,负责工作流编排、Python脚本执行、LLM调度以及对话交互;
■ Prometheus+Exporter:作为数据源,采集主机、MySQL等核心指标;
■ Alertmanager:提供实时告警事件数据;
■ JumpServer API:获取组件状态及运营统计数据;
■ LLM(大语言模型):负责解读数据,生成人类可读的分析建议;
■ WeasyPrint:负责将HTML模板渲染为精美的PDF报告。
▲图1 MaxKB实现JumpServer自动化巡检流程示意
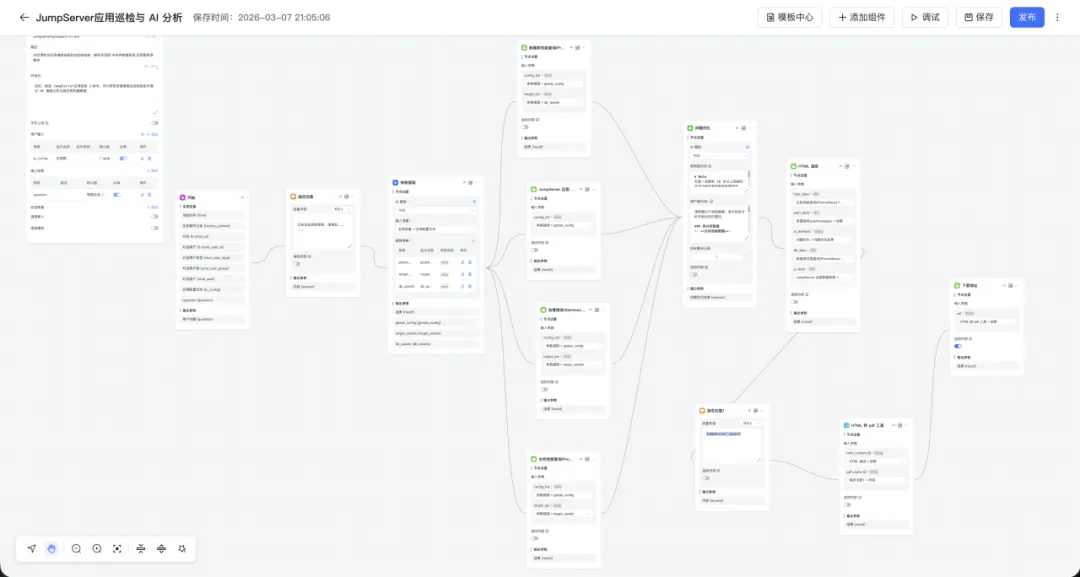
▲图2 MaxKB实现JumpServer自动化巡检工作流
基于MaxKB搭建JumpServer自动化巡检工作流主要涉及三个核心环节,分别是数据采集、数据分析、渲染与交付。其实现步骤的注意事项如下:
1. 数据采集层:打破数据孤岛
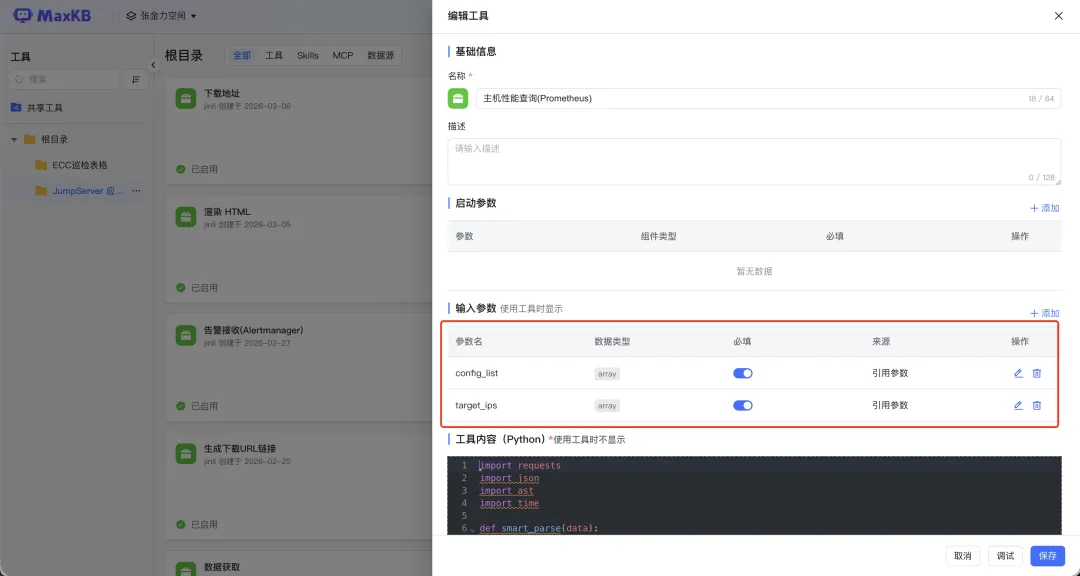
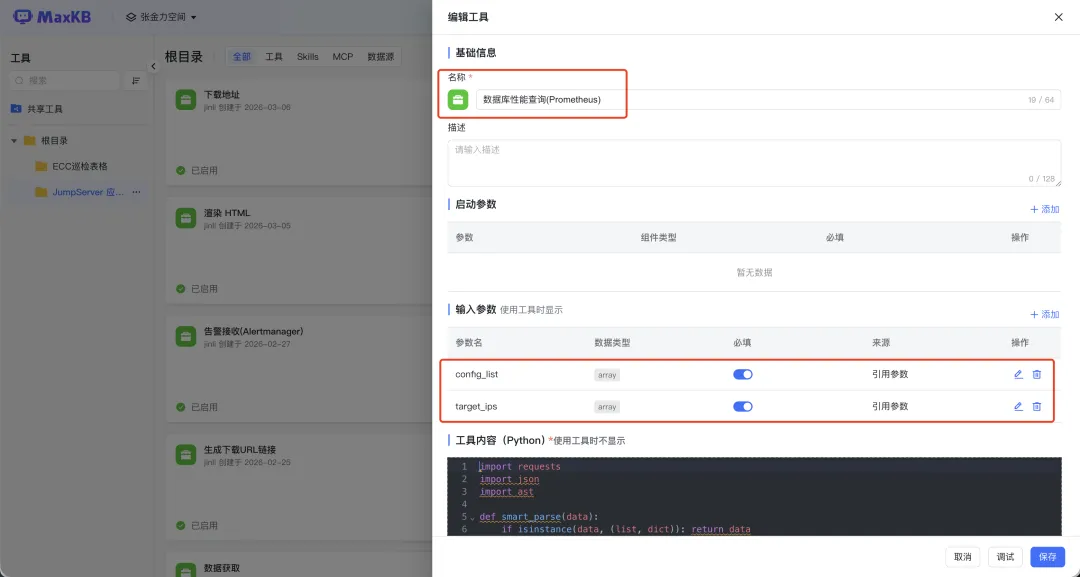
利用MaxKB的工具扩展能力编写Python脚本,实现智能体编排,并行采集多维度的数据。
■ 主机性能采集:通过Prometheus API查询node_exporter指标。为了解决Prometheus中instance标签格式不统一(含有IP或主机名)的问题,在代码中设计了双重匹配逻辑,以确保数据的准确抓取。同时在代码中内置了“阈值计算”逻辑,直接在采集阶段标记出告警状态;
■ 数据库深度巡检:不仅监控基础连接数,更引入了TPS/QPS、Buffer Pool命中率、行锁等待等深度指标,让数据库健康状况一目了然;
■ 业务组件联动:通过JumpServer API,实时获取Core、Koko、Lion等组件的存活状态及运行负载。
这是本方案的核心创新点。我们将采集到的结构化数据喂给LLM:
Prompt 示例: "当前JumpServer01磁盘使用率99.69%,JumpServer02使用率 94.73%。请分析风险并给出建议。"
LLM会给出分析结果:
AI 分析结果: “系统整体功能运行正常,但存在严重的磁盘空间告警风险...磁盘满将直接导致JumpServer服务崩溃——无法写入会话录像...根因分析:JumpServer 默认长期保留全量会话录像,未配置自动清理策略...”
通过这种方式,JumpServer巡检报告就包含了专家级的诊断建议。具体的提示词参考如下:
Role你是一名拥有 10 年以上经验的资深运维专家和数据库管理员 (DBA)。你的任务是分析通过自动化工具采集的 JumpServer 应用巡检数据,并生成一份专业的《综合分析与优化建议》。你的分析必须遵循以下原则:1. **数据驱动**:严格基于提供的 JSON 数据进行分析,不要编造或臆测不存在的指标。2. **风险优先**:优先关注标记为“告警”、“异常”或“离线”的指标,以及数值接近阈值(如 CPU > 80%, 磁盘 > 85%)的情况。3. **专业深入**: - 对于主机问题,需结合 Linux 系统原理(如上下文切换、IO 等待)进行分析。 - 对于数据库问题,需结合 MySQL 原理(如 InnoDB 缓冲池、锁机制、索引优化)进行分析。 - 对于 JumpServer 应用,需考虑到其作为堡垒机的特性(如审计日志占用磁盘、会话录像占用空间)。4. **落地可行**:提供的优化建议必须具体、可操作,包含具体的命令示例或配置修改方向。请直接输出分析结果,不要包含任何开场白或无关的寒暄。请根据以下巡检数据,进行综合分析并给出优化建议。待分析数据1. **主机性能数据**:{{主机性能查询(Prometheus).result}}2. **数据库性能数据**:{{数据库性能查询(Prometheus).result}}3. **告警事件数据**:{{告警接收(Alertmanager).result}}4. **JumpServer 应用运营信息**:{{JumpServer 运营数据获取.result}}分析要求请按照以下结构输出分析报告:**一、整体健康度评估**(一句话总结当前系统运行状态,如:“系统整体运行平稳,但存在磁盘空间不足的风险。”)**二、关键风险分析**(请列出 3-5 个关键风险点,按严重程度排序。如果一切正常,请说明“当前未发现明显风险”。)1. **[风险名称]**- **现状**:(引用具体数据,如“主机 192.168.1.10 磁盘使用率达到 95%”)- **影响**:(说明该问题可能导致的后果,如“可能导致 JumpServer 无法记录审计日志,影响合规性”)- **根因分析**:(简要推测原因,如“JumpServer 会话录像文件堆积”)**三、优化与整改建议**(针对上述风险,给出具体的解决方案)1. **针对磁盘空间不足**:- **临时措施**:(如:清理 `/opt/jumpserver/data/media` 目录下 30 天前的录像文件,命令:`find ... -mtime +30 -exec rm -f {} \;`)- **长期规划**:(如:对数据目录进行扩容或配置日志轮转策略。)2. **针对数据库性能**:- (如涉及慢查询,建议开启慢查询日志分析工具;如涉及缓冲池命中率低,建议调整 `innodb_buffer_pool_size`。)**四、总结**(简要概括本次巡检的结论,并提醒运维人员关注的重点事项。)
为了让JumpServer巡检报告更专业,我们选择“HTML模板+PDF渲染”的路线。在模板设计方面,使用Jinja2模板语法,设计了包含封面、目录、详细表格、AI建议模块的HTML模板。通过CSS控制white-space: pre-wrap,很好地解决了AI输出的Markdown格式在PDF中排版混乱的问题;文件名处理方面,为了避免生成的PDF文件名包含空格导致链接截断,将时间格式标准化为%Y-%m-%d_%H-%M-%S,确保用户在聊天框点击链接即可直接下载PDF报告。
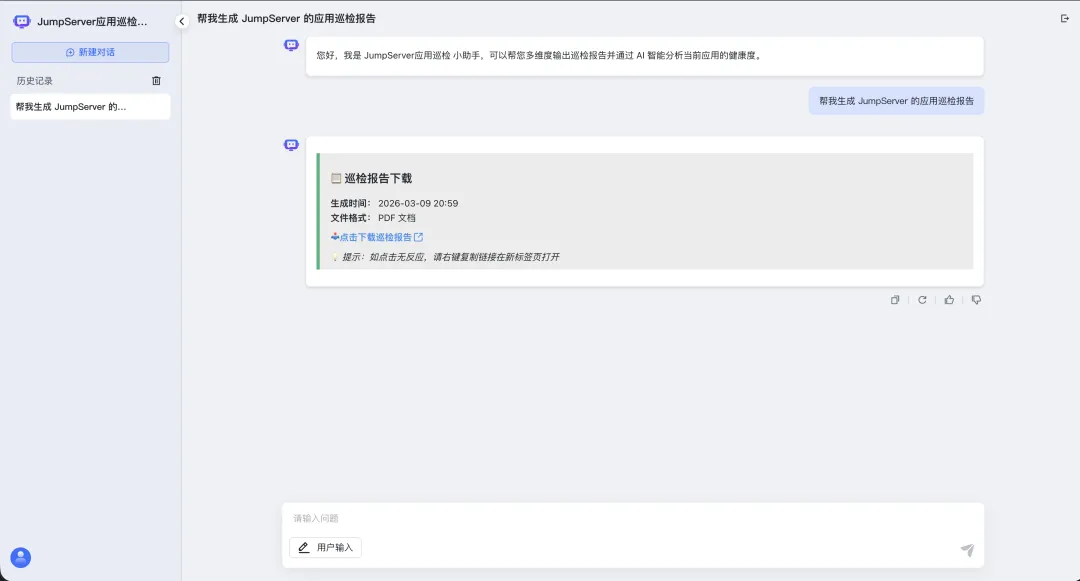
借助MaxKB和大模型能力,我们可以将IT资产的定期巡检工作从数小时缩短至分钟级,同时还可以渲染出专业的巡检报告。在系统搭建和调试好之后,用户只需要在MaxKB的对话框输入“巡检”字样,即可触发巡检流程,无需关心底层技术细节。巡检完成后,系统自动生成统一格式的巡检报告,符合等保及审计要求。而LLM的加入弥补了传统监控工具“只报故障、不分析原因”的短板。
▲图6 在MaxKB中通过对话生成JumpServer巡检报告
在此基础上,我们可以继续引入新的技术元素,增加新的功能。比如,可以通过引入RAG(检索增强生成),让LLM结合JumpServer官方文档进行更加精准的故障诊断;引入Grafana将图表插入报告中,按照每周、每月、每季度的维度进行数据趋势分析,对比历史巡检数据,预测资源增长趋势。