生成对抗网络(GAN)从原理到实战:手把手教你实现第一个生成模型
点击下方卡片,关注“人工智能陈小白”
视觉/大模型/图像重磅干货,第一时间送达!
导语
生成对抗网络(Generative Adversarial Networks,GAN)是深度学习领域最具影响力的创新之一。自2014年Ian Goodfellow提出以来,GAN彻底改变了我们对生成模型的认知,为图像生成、风格迁移、超分辨率、虚拟人创建等领域开辟了全新道路。
本文将从数学原理出发,结合PyTorch代码实现,带你从零开始理解并实现自己的第一个GAN模型。无需深厚的数学基础,只需掌握基础的深度学习和Python知识,即可跟随本文完成实战。
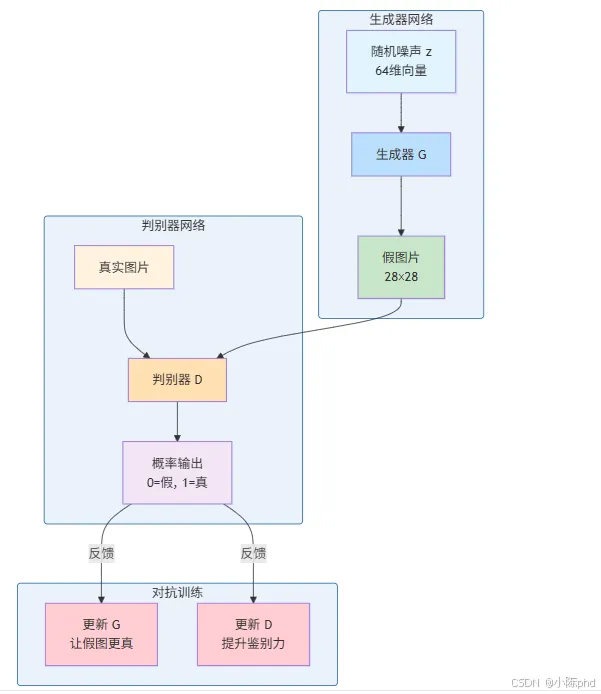
1. GAN 核心思想:对抗的艺术
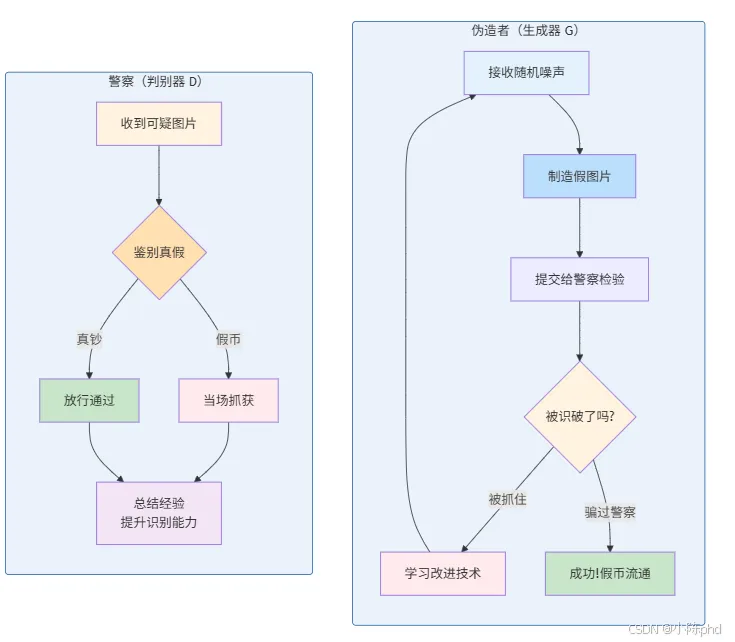
1.1 类比理解:警察与伪造者
想象一个场景:
- • 伪造者(Generator):试图制造假币,希望骗过警察
- • 警察(Discriminator):试图识别假币,抓住伪造者
两者不断博弈:
- • 最终达到平衡:伪造者制造的假币足以乱真,警察只能随机猜测
这就是GAN的核心思想——通过对抗训练,让生成器学会生成逼真的数据。
1.2 数学框架
GAN由两个神经网络组成:
生成器 G(z; θg):
- • 输入:随机噪声 z ~ p(z)(通常为标准正态分布)
判别器 D(x; θd):
- • 输出:概率 D(x) ∈ [0, 1],表示 x 是真实样本的概率
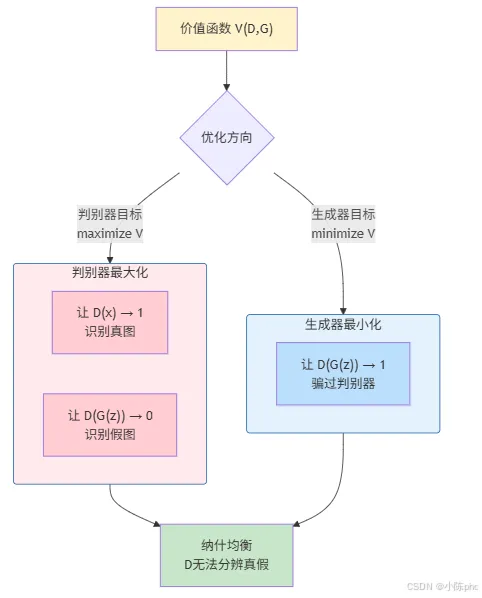
1.3 目标函数(Minimax Game)
GAN的训练是一个极小极大博弈问题:
直观理解:
- • 判别器 D 希望最大化 V:对真图输出接近1,对假图输出接近0
- • 生成器 G 希望最小化 V:让 D(G(z)) 接近1(骗过判别器)
2. 网络架构设计
2.1 生成器(Generator)
生成器的任务是将低维噪声映射到高维数据空间(如图像)。
设计原则:
- • 输出:与真实数据同维度的样本(如28×28=784维图像)
为什么用Sigmoid输出?
- • Sigmoid将输出压缩到 (0, 1),符合像素值范围
2.2 判别器(Discriminator)
判别器的任务是判断输入是真实数据还是生成数据。
设计原则:
为什么用LeakyReLU而不是ReLU?
- • ReLU在负数区域梯度为0,可能导致"神经元死亡"
- • LeakyReLU在负数区域有微小斜率(如0.2),保持梯度流动
3. PyTorch 代码实现
3.1 完整代码
# encoding: utf-8
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, utils
# ==================== 超参数配置 ====================
LATENT = 64# 噪声维度Z:生成器的输入维度
EPOCHS = 20# 训练轮数
BATCH = 128# 批次大小
LR = 2e-4# 学习率
device = ("cuda"if torch.cuda.is_available()
else"mps"ifgetattr(torch.backends, "mps", None) and torch.backends.mps.is_available()
else"cpu")
print("算力选择:", device)
# ==================== 生成器 ====================
classGenerator(nn.Module):
"""
生成器:将随机噪声映射为假图片
输入: [batch, LATENT] 的随机噪声
输出: [batch, 1, 28, 28] 的假图片(MNIST格式)
"""
def__init__(self):
super().__init__()
self.net = nn.Sequential(
# 第1层: 64 -> 256
nn.Linear(LATENT, 256),
nn.ReLU(True),
# 第2层: 256 -> 512
nn.Linear(256, 512),
nn.ReLU(True),
# 第3层: 512 -> 784 (28*28)
nn.Linear(512, 28*28),
nn.Sigmoid() # 输出范围 (0, 1),符合像素值
)
defforward(self, z):
"""
前向传播
z: [batch, LATENT] 随机噪声
return: [batch, 1, 28, 28] 生成的假图片
"""
x = self.net(z)
return x.view(-1, 1, 28, 28) # reshape为图片格式
# ==================== 判别器 ====================
classDiscriminator(nn.Module):
"""
判别器:判断输入图片是真是假
输入: [batch, 1, 28, 28] 的图片
输出: [batch, 1] 的概率值(0=假,1=真)
"""
def__init__(self):
super().__init__()
self.net = nn.Sequential(
# 将图片展平为向量
nn.Flatten(),
# 第1层: 784 -> 512
nn.Linear(28*28, 512),
nn.LeakyReLU(0.2, inplace=True),
# 第2层: 512 -> 256
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
# 第3层: 256 -> 1
nn.Linear(256, 1),
nn.Sigmoid() # 输出概率
)
defforward(self, x):
"""
前向传播
x: [batch, 1, 28, 28] 输入图片
return: [batch, 1] 真假概率
"""
returnself.net(x)
# ==================== 训练流程 ====================
defmain():
# 1. 准备数据集:MNIST手写数字
ds = datasets.MNIST(
root="./data", # 数据保存路径
train=True, # 使用训练集
download=True, # 自动下载
transform=transforms.ToTensor() # 转为tensor,范围[0,1]
)
dl = DataLoader(ds, batch_size=BATCH, shuffle=True, num_workers=0)
# 创建输出目录
os.makedirs("samples", exist_ok=True)
# 2. 初始化模型
G = Generator().to(device) # 生成器
D = Discriminator().to(device) # 判别器
# 3. 优化器(分别优化G和D)
opt_G = torch.optim.Adam(G.parameters(), lr=LR, betas=(0.5, 0.999))
opt_D = torch.optim.Adam(D.parameters(), lr=LR, betas=(0.5, 0.999))
# 4. 损失函数:二分类交叉熵
criterion = nn.BCELoss()
# 固定噪声,用于观察生成器的进步过程
fixed_z = torch.randn(64, LATENT, device=device)
# 5. 训练循环
for ep inrange(1, EPOCHS+1):
for real, _ in dl: # real: [batch, 1, 28, 28]
real = real.to(device)
bs = real.size(0) # 当前batch大小
# ==================== 训练判别器 ====================
# 5.1 生成假图(detach阻止梯度传到G)
z = torch.randn(bs, LATENT, device=device)
fake = G(z).detach()
# 5.2 D对真图和假图的判断
pred_real = D(real) # 对真图的判断,应该接近1
pred_fake = D(fake) # 对假图的判断,应该接近0
# 5.3 判别器损失:让真图→1,假图→0
loss_D = criterion(pred_real, torch.ones_like(pred_real)) + \
criterion(pred_fake, torch.zeros_like(pred_fake))
# 5.4 更新判别器
opt_D.zero_grad()
loss_D.backward()
opt_D.step()
# ==================== 训练生成器 ====================
# 5.5 重新生成假图(这次要训练G)
z = torch.randn(bs, LATENT, device=device)
fake = G(z)
# 5.6 D对假图的判断
pred_fake = D(fake)
# 5.7 生成器损失:让D认为假图是真的(输出1)
loss_G = criterion(pred_fake, torch.ones_like(pred_fake))
# 5.8 更新生成器
opt_G.zero_grad()
loss_G.backward()
opt_G.step()
# 6. 每个epoch保存生成结果
with torch.no_grad():
fake = G(fixed_z)
utils.save_image(fake, f"samples/gan_fake_ep{ep}.png", nrow=8)
print(f"Epoch {ep}/{EPOCHS} loss_D={loss_D.item():.3f} loss_G={loss_G.item():.3f}")
if __name__ == "__main__":
main()
4. 代码逐段解析
4.1 超参数设计
LATENT = 64# 噪声维度
EPOCHS = 20# 训练轮数
BATCH = 128# 批次大小
LR = 2e-4# 学习率
设计考量:
- • LATENT=64:足够表达多样性,又不会太大导致训练困难
- • LR=2e-4:GAN对学习率敏感,过大导致不稳定,过小收敛慢
- • betas=(0.5, 0.999):GAN常用配置,加速收敛
4.2 生成器详解
classGenerator(nn.Module):
def__init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(LATENT, 256), nn.ReLU(True),
nn.Linear(256, 512), nn.ReLU(True),
nn.Linear(512, 28*28), nn.Sigmoid()
)
defforward(self, z):
x = self.net(z)
return x.view(-1, 1, 28, 28)
维度变化:
输入 z: [128, 64] (batch=128, latent=64)
经过Linear1: [128, 256]
经过Linear2: [128, 512]
经过Linear3: [128, 784]
reshape后: [128, 1, 28, 28] (batch, channel, height, width)
4.3 判别器详解
classDiscriminator(nn.Module):
def__init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 512), nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1), nn.Sigmoid()
)
维度变化:
输入图片: [128, 1, 28, 28]
Flatten后: [128, 784]
经过Linear1: [128, 512]
经过Linear2: [128, 256]
经过Linear3: [128, 1] # 每个样本一个概率值
4.4 训练流程图解
关键理解:
- •
detach():阻断梯度回传,训练D时不更新G - • 训练G时,D只作为"评判标准",不更新D的参数
5. 训练过程与结果分析
5.1 损失函数解读
5.2 训练过程可视化
5.3 常见问题与解决
6. 扩展与进阶
6.1 从GAN到DCGAN
DCGAN使用卷积层替代全连接层:
- • 生成器:ConvTranspose2d(反卷积)上采样
6.2 从GAN到条件GAN
条件GAN(cGAN)引入类别信息:
6.3 GAN在虚拟人中的应用