PyTorch学习笔记|基本优化思想和最小二乘法
- 2026-05-08 17:57:11

在正式开始神经网络建模之前,我们还需要掌握一些基本数学工具,在Pytorch中,最核心的就是梯度计算工具,也就是Pytorch的autograd(自动微分)模块。当然,要使用好微分工具,我们还是要了解一些基本的优化思想。
所谓优化思想,指的是利用数学工具求解复杂问题的基本思想,同时也是近现代机器学习算法在实际建模过程中经常使用基础理论在实际建模过程中,我们往往会先给出待解决问题的数值评估指标,并在此基础之上构建方程、采用数学工具、不断优化评估指标结果,以期达到可以达到的最优结果。本节,我们将先从简单线性回归入手,探讨如何将机器学习建模问题转化为最优化问题,然后考虑使用数学方法对其进行求解。
简单线性回归的机器学习建模思路
上篇文章我们使用逆矩阵来解出线性方程的系数,但是这不是一般方法,这篇文章将从优化思想的方法来求线性方程的系数。
A = torch.tensor([[1.0,1],[3,1]])
B = torch.tensor([2.0,4])
torch.mv(torch.inverse(A), B)
# result
tensor([1., 1.])
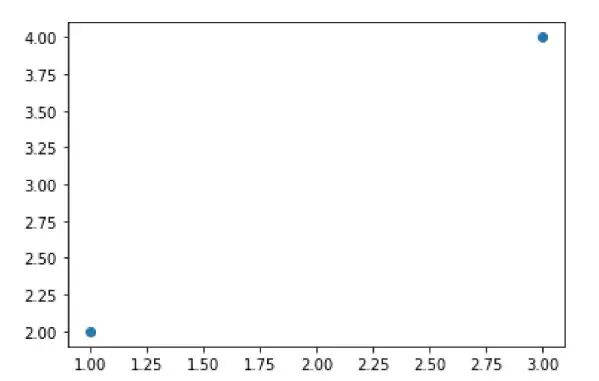
我觉得最优化问题其实简单的来说就是确定优化目标函数,然后求解优化目标函数最小值的过程,让我们试试如何将上面的问题转化为优化问题。
如果我们希望通过一条直线拟合二维平面空间上分布的点,最核心的目标,毫无疑问,就是希望方程的预测值和真实值相差较小。假设真实的y值用y表示,预测值用ŷ表示,带入a、b参数,则有数值表示如下:

那这两个预测值和真实值相差:
我们希望ŷ和y尽量接近,所以我们就可以用误差总和,为了避免正负相抵消,我们就用平方和来表示:
上面所说的就是误差平方和SSE。
至此,我们已经将原问题转化为了一个最优化问题,接下来我们的问题就是,当a、b取何值时,SSE取值最小?值得注意的是,SSE方程就是我们优化的目标方程(求最小值),因此上述方程也被称为目标函数,同时,SSE代表着真实值和预测值之间的差值(误差平方和),因此也被称为损失函数(预测值距真实值的损失)。值得注意的是,目标函数和损失函数并不完全等价,但大多数目标函数都由损失函数构成。
那怎么求解了,我们先把上面的目标函数展示出来给大家看一下。可以看出这个函数是凸函数,而对于一个凸函数来说,全域最小值明显存在,基于凸函数的数学定义,我们可以进一步给出求解上述SSE凸函数最小值的一般方法,也就是著名的最小二乘法,那就是求函数各个自变量的偏导数都为0的点。
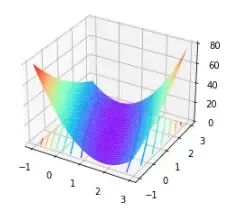
所以,我们可以通过下面计算得到最终结果,这就是最小二乘法。

建模一般流程
提出基本模型(y=ax+b) 确定损失函数和目标函数(SSE) 根据目标函数特征,选择优化方法,求解目标函数。(最小二乘法)
深入学习最小二乘法
如果是多元函数,我们可以通过下列公式来表示。
令,,则上式可写为
那就可以这样进行计算得到w和b。

矩阵的表达形式如下:

最后求得
我们用代码来实现一下:
x = torch.tensor([[1.,1],[3,1]])
y = torch.tensor([[2.],[4]])
w = torch.mm(torch.inverse(torch.mm(x.t(),x)),torch.mm(x.t(),y))
#result
tensor([[1.0000],
[1.0000]])
autograd初上手
我们也可以反向验证,看下损失函数SSE在a=1,b=1时偏导数是否都为0。此时就需要借助PyTorch中的autograd模块来进行偏导计算。严格意义上来讲,autograd模块是PyTorch中的自动微分模块,我们可以通过autograd模块中的函数进行微分运算,在神经网络模型中,通过自动微分运算求解梯度是模型优化的核心。
a = torch.tensor(1.,requires_grad=True) #通过设置requires_grad属性为True、规定张量可微分即可
b = torch.tensor(1.,requires_grad=True)
sse = torch.pow((2 - a - b), 2)+torch.pow((4 - 3*a - b), 2)
print(torch.autograd.grad(sse,[a,b]))
# result
(tensor(-0.), tensor(-0.))
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【西班牙语学习资料大全】(入门+词典+基础西语+从零开始学西语+一月通)
- No.1989 腾讯金融科技服务业务学习笔记
- 《易经》学习笔记17——谦卦
- 学习笔记之60:扎根:小企业“活下去”的三大基石
- 缠论原文、答疑及大盘学习笔记第20课(一)
- 【护资备考资料】2025-2026护士资格证备考学习资料集锦(含课程+真题+讲义等),PDF可下载打印
- 「0373-世界现代设计史」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
- 「0510-写作基础教程」电子版+学习笔记+知识点总结+期末考试重点+复习+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
- 「0377-中医养生方法学」电子版+学习笔记+知识点总结+期末考试重点+复习+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
- 「0505-关务基础知识」电子版+学习笔记+知识点总结+期末考试重点+复习+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
