“人工智能训练师”培训学习-课堂笔记(四级/中级---三级/高级)
- 2026-05-08 17:58:53
AI
人工智能训练师需要学习哪些内容?

根据《人工智能训练师》职业技能等级证书考试要求不同等级新增学习重点有所不同,以下是三级(高级)和四级(基础)新增学习重点:
三级(高级)新增学习重点:
1.高级算法应用能力
· 独立制定智能训练方案,涵盖数据处理、模型训练全流程,明确各环节标准、目标和风险点。
· 设计多维度算法测试方案(功能、性能、稳定性),用准确率、召回率、F1值等量化分析,撰写标准化测试报告并提出优化建议。
· 识别模型过拟合、欠拟合、不收敛等问题,通过调整学习率、迭代次数、特征工程等方式提升模型效果。
· 针对NLP(文本分词、分类)、CV(图像归一化、分类)、语音(语音识别)等场景,设计专属训练策略。
2.数据算法与分析能力
· 独立制定数据处理规范,撰写可落地的规范文档,明确数据清洗规则、标注标准、质量校验要求。
· 设计数据质量全流程管控方案,用Kappa系数评估标注一致性,处理复杂数据噪声和异常值。
· 分析数据特征对模型效果的影响,通过特征筛选、特征工程提升数据有效性。
· 制定智能系统数据监控指标,识别数据异常并提出解决办法,实现数据与算法联动应用。
3.业务理解与需求分析能力
· 将模糊的业务目标转化为AI训练的具体指标(如“提升用户搜索准确率”转化为“召回率≥90%”)。
· 结合业务特点,判断不同算法、数据方案的适配性,提出合理的AI应用建议。
· 根据业务场景设计专属训练方案,确保训练结果贴合实际业务需求。
· 从业务视角评估模型效果(如“是否降低人工审核成本”),并根据业务变化及时调整训练方案。
4.通用软实力
· 独立完成算法测试报告、数据处理规范、需求转化方案等专业文档撰写。
· 能指导五级、四级人员完成基础操作(如标注规范讲解、简单数据处理指导)。
· 总结训练项目中的问题,提出优化方向,形成复盘报告。
四级(基础)新增学习重点:
1.数据处理与标注进阶
· 掌握更复杂的数据清洗方法,如处理多类型缺失值、异常值,以及数据格式转换。
· 熟练使用标注工具(如LabelImg、LabelStudio)进行图像、文本、语音数据标注,确保标注质量符合业务要求。
· 学习数据可视化技术,使用Excel或Python的Matplotlib库生成图表,直观展示数据分布和特征。
2.模型训练与评估基础
· 掌握常用机器学习模型(如线性回归、逻辑回归、决策树)的搭建和训练方法,能划分训练集、验证集、测试集。
· 学习模型评估指标(如准确率、均方误差),能通过简单调参(如学习率、迭代次数)优化模型性能。
· 了解模型过拟合、欠拟合的基本概念,能通过增加数据量、调整模型复杂度等方式改善模型效果。以上重点内容需结合实操练习,通过完成具体项目(如智能客服系统、图像分类系统)巩固技能,提升解决实际问题的能力。《人工智能训练师》国家职业技能标准-职业编码:4-04-05-05(职业技能等级证书考试学习)


以下是第一次课的课堂笔记,加油。
3.1.1~3.1.5
1.Excel插入透视表时,鼠标要放在任意有数据的单元格上。
2.按哪个字段进行统计,透视表中的Rows就放哪个字段。
3.按哪个字段进行排序,可右键第一列(Row),点“更多排序方式”,选具体要排序的字段。
4.按时间段进行分析
1)若时间戳字段的数据类型是“自定义”,即日期类型,可直接通过插入透视表,然后右击“分组”中只选“Hours”进行统计。
2)若时间戳字段的数据类型是“通用”(General),需将该时间戳列的数据进行拆分,拆出“小时”的数据放入新列“小时”,然后插入透视表,按“小时”进行统计。
3)若时间戳的值有“分 秒”,则统计时统计区间需少选1个小时。 eg: 统计6点-12点,小时要选“6,7,8,9,10,11”
若时间戳的值没有“分 秒”,直接到“时”,则统计时直接选统计的小时区间。 eg:统计6点-12点,小时要选“6,7,8,9,10,11,12”
1.1.1~1.1.3
1.read_csv('xxx.csv') 读取csv
2.data['xx'] 创建新列xx
3.np.where(条件,真值,假值) 根据条件进行分类
4.value_counts() 分组统计数量
5.xx.counts()/len(data) 计算某个值占总数的比例(除以data的长度,即数据总行数)
6.pd.cut(列xx,bins=**,labels=##) 对列xx的数据,按bins分界点**进行区间切分,各区间的值显示为labels ##
7.groupby().apply(lambda=) 分组后进行计算
data.groupby('BMIRange')['RiskLevel'].apply(lambda x: (x == '高风险患者').mean())
根据BMIRange进行分组,分组后计算“风险等级RiskLevel的值为"高风险患者"的比例 (lambda表示循环,mean表示均值)
8.data.groupby().agg(['count','mean']) 对分组后的数据集应用聚合函数count、mean,多个计算因此用数组形式[xx,xx]
9.isin([A,B]) 筛选出值为A、B的数据
data['SensorType'].isin(['Temperature','Humidity']) 筛选SensorType的值为Temperature或Humidity的记录
10.fillna() 填充空值
fillna(method='ffill', inplace=True) 向前填充数据中的空值(指用上一行的数据进行填充)
fillna(method='bfill', inplace=True) 向后填充数据中的空值(指用下一行的数据进行填充)
11.drop(columns=['xx']) 删除xx列
12.to_csv('xxx.csv') 将数据保存为xxx.csv
13.isnull() 检查数据中是否存在空值
14.duplicated() 检查数据中是否存在重复值
15.sum() 对数据进行加和计算
16.between(下限,上限) 判断数值是否在某个范围内
17.described() 对数据进行描述性统计
18.~:表示取反
data[~data['is_valid']] 取值不是is_valid的记录


以下是第二次课的课堂笔记,加油。
1.1.4~1.1.5
1.head() 打印前5行
2.dropna() 删除空白行(删除缺失值)
3.data['A'].astype(int) 将A列的数据类型转为整型
data['B']= data['B'].astype(float)将B列的数据类型转为浮点型
4.数据标准化处理: (这组数据-这组数据的均值)/这组数据的标准差
eg: 对“PurchaseAmount”进行标准化处理:
data['PurchaseAmount'] = (data['PurchaseAmount'] - data['PurchaseAmount'].mean() )/ data['PurchaseAmount'].std()
5.gender_stats=data.groupby('Gender').agg({'Speed':'mean','TravelDistance':'mean','TravelTime':'mean'}) 阅卷标准答案
--用“键值对”的形式传参给agg,来统计不同性别的平均车速、行驶距离和行驶时间。 (用键值对的好处是可对各字段用不同方法的统计)
--此题都是求均值,因此都传mean, 与该代码功能相同:gender_stats = data.groupby('Gender')[['Speed','TravelDistance','TravelTime']].mean()
2.1.1~2.1.5
1.read_csv('xxx.csv') 读取csv
read_csv('xxx.csv',encoding='gbk') 加载数据集,并指定编码为gbk
2.data.dtypes显示每一列的数据类型
3.data.info() 输出表的基本结构
4.data.isnull().sum() 显示每一列的空缺值数量
5.to_numeric(data['xx'], errors='coerce') 将列xx的数据转换为数值类型,如果转换不成功,则用NA表示
data['horsepower'] = pd.to_numeric(data['horsepower'], errors='coerce')
6.data['就诊日期'] = pd.to_datetime(data['就诊日期']) 规范日期类型
7.shape 查看维度
data.shape[0]返回数据集有多少行
data.shape[1] 返回数据集有多少列
8.select_dtypes(include=[ , ]) 选择某数据类型的列
data.select_dtypes(include=['float64', 'int64'])
9.data.rename({'原列名':'现列名'}) 修改列名
data.rename(columns={'病人ID':'患者ID'}, inplace=True)修改列名, inplace=True表示需要替换
10.dropna(subset='xx') 删除指定列xx中的缺失值
11.data.drop_duplicates()删除重复行
12.to_csv('xxx.csv', index=False)保存到xxx.csv,不加索引
13.scaler.fit_transform(data[xxx]): 对数据进行拟合转换,所有的归一化、标准化都需要用到该方法
eg:data[numerical_features] = scaler.fit_transform(data[numerical_features]) #numerical_features为需要处理的数据字段
14.定义特征和目标
target_variable = 'SeriousDlqin2yrs' 定义目标列名
X = data_cleaned.drop(columns=[target_variable])数据集中删去y,剩下的就都是X
y = data_cleaned[target_variable]定义目标列
15.train_test_split 用于将数据集划分为训练集和测试集
传参1:train_test_split(X,y,test_size=0.2, random_state=42)
传参2:train_test_split(data_filled,test_size=0.2, random_state=42)data_filled为前期定义好的数据集
X:代表输入自变量,即影响因素
y:代表输出因变量,即预测对象(目标对象)
test_size:训练集尺寸
random_state:随机种子,以保障每次划分都固定
16.concat合并数据
pd.concat([X,y], axis=1) #将X,y按列拼接,axis=1表示从列进行合并,axis=0则从行进行合并
17.使用IQR处理异常值
quantile() 某字段的分位数
Q1 = data[numeric_cols].quantile(0.25)#找到0.25点位 即1/4点位
Q3 = data[numeric_cols].quantile(0.75) #找到3/4点位
IQR = Q3-Q1#IQA计算公式 (箱子的宽度) #移除异常值
data_cleaned = data[~((data[numeric_cols] < (Q1 - 1.5 * IQR)) | (data[numeric_cols] > (Q3 + 1.5 * IQR))).any(axis=1)]
18.数据.plot.xxx 绘图,不知道列名用plot方式一:数据.plot(kind='bar', stacked=True)案例中用于绘制柱状图
方式二:数据.plot.pie()案例中用于绘制饼图
19.plt.scatter(data['年龄'], data['疾病严重程度']) 绘制散点图, 传横坐标与纵坐标参数 (知道列名plt直接绘制)
2.1.1~2.1.5 数据清洗和标注规范
制定数据清洗规范 (答到1个点得1分,最高得2分)
1.数据加载和初步检查
使用pandas库加载数据集并显示前五行数据,以了解数据的基本结构和内容。
2.缺失值或重复值处理
检查缺失值并删除缺失值所在行,检查并移除数据集中的重复值,以确保数据的唯一性和完整性。记录删除的重复行数。
3.异常值处理
将不符合数据规范的数据结构转换成指定的数据类型如数值型或日期型,并对转换过程中异常值进行处理。
4.检查处理后的数据
对清洗后的数据进行数据检查,查看每一列的数据类型和是否存在缺失值或重复值。
制定特征工程规范(答到1个点得1分,最高得3分)
1.数据归一化或标准化处理
使用MinMaxScaler(工具看题)对数值变量进行标准化或归一化处理,将数据缩放到0和1之间,以确保所有特征在相似的范围内。
2特征工程
创建新的特征,设定特征数据集,主要是加快数据计算,减小内存存储。
3.目标变量设定
将XX(看题目)设为目标变量,(并进行后续的标注和划分。
4.数据标注和划分
使用train_test_split将数据集划分为训练集和测试集,常用的划分比例为80-20,以验证模型的性能。
5.数据整合
将特征和目标变量合并到一个数据框中,以便数据浏览。
6.数据保存
将清洗和预处理后的数据保存为CSV文件,文件命名为xxx.csv,以供进一步分析或模型开发使用。


以下是第三次课“2.2.1~2.2.5算法测试”相关内容的课堂笔记,加油。
算法测试代码框架的主要思想是:
定义模型>训练模型>保存模型>用训练好的模型进行预测>模型性能分析>生成测试报告
2.2.1~2.2.5
1. 定义模型
(1)定义Logistic回归模型,最大迭代次数为1000次
model=LogisticRegression(max_iter=1000)
(2)定义线性回归模型
model=LinearRegression()
(3)创建随机森林回归模型实例,决策树的数量为100
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
(4)创建XGBoost回归模型
xgb_model= xgb.XGBRegressor(n_estimators=100, random_state=42) 构建100棵树
xgb_model=XGBRegressor(n_estimators=1000,learning_rate=0.05,subsample=0.8,max_depth=5, colsample_bytree=0.8)
构建1000课树,学习率为0.05,每棵树的最大深度为5
(5)创建包含标准化和线性回归的管道
pipeline=Pipeline([('scaler',StandardScaler()),('linreg',LinearRegression())])
2.训练模型
(1)model.fit(X_train,y_train) 用模型,传入训练集数据(X,y)进行训练
(2)pipeline.fit(X_train,y_train) 用管道,传入训练集数据(X,y)进行训练
3.保存模型
(1)with open('2.2.1_model.pkl', 'wb') as file:
pickle.dump(model,file)
* wb:将模型以字节流的形式写入
* dump:将训练好的模型导入文件
(2)model_filename = '2.2.4_model.pkl'
joblib.dump(model,model_filename)
*dump 将训练好的模型导入文件
4.预测模型
(1)通过模型,传入测试集X进行预测
model.predict(X_test)
(2)通过管道,传入测试集X进行预测
y_pred = pipeline.predict(X_test)
5.模型性能分析
(1)model.score(x_train,y_train) 直接计算模型准确率得分
pipeline.score(X_train, y_train):训练集得分,传入训练集(X,y)
pipeline.score(X_test, y_test):测试集得分,传入测试集(X,y)
(2)均方误差MSE,越接近0越好 mse = mean_squared_error(y_test,y_pred)
*传真实值和预测值
*预测值:为测试集x通过训练好的模型进行预测得到的结果y
(3)决定系数R2,越接近1越好
r2 = r2_score(y_test,y_pred) 传真实值和预测值
(4)平均绝对误差MAE,越接近0越好
mean_absolute_error(y_test,y_pred)传真实值和预测值
(5)accuracy_resampled = (y_test==y_pred_resampled).mean()用均值分析结果
6.生成测试报告
report = classification_report(y_test, y_pred, zero_division=1)
with open('2.2.1_report.txt', 'w') as file:
file.write(report)
*w:表示写入
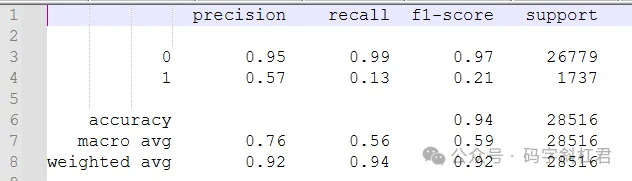
生成的报告如下图,包含准确率、召回率、f1-socre和support
8. SMOTE重采样技术
作用是解决样本不均衡问题,用差值化增加样本量
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train,y_train)
通过重采样,生成新的样本数据
9.运用哑变量方法,将特征变量转为数值变量
X = df[['Your gender', 'How important is exercise to you ?', 'How healthy do you consider yourself?']]
X = pd.get_dummies(X)
*哑变量:把值变成了列
10.将年龄段转为数值变量
y = df['Your age'].apply(lambda x: int(x.split(' ')[0]))
因为"Your age"的数据是个区间(eg: 19 to 25),因此这里通过按'空格'分隔后转为整型数组,然后从数组中取第一个位置的值,即取19。
11.去掉列名左右的空格(检查和清理列名)
df.columns = df.columns.str.strip()
2.2.1~2.2.5问答部分
错误分析和改进各写2条即可, 可从数据清洗,特征工程变量选择,模型选择,模型优化这几个方面去答题。
错误分析
特征工程:当前使用的特征可能没有完全捕捉到影响目标变量的所有重要信息。 模型选择:(线性回归模型)可能不是最适合这个问题的模型。可以尝试其他更复杂的模型 过拟合:训练集得分略高于测试集得分,可能存在轻微的过拟合现象。意味着模型在训练数据上表现良好,但在未见过的数据上表现稍差。 欠拟合:R2值接近于零,表明模型可能欠拟合,即模型未能很好地捕捉到数据中的模式。这也可能是因为特征的选择不够充分或者特征之间的关系不是线性的。 数据质量和数量:数据可能存在质量问题,如异常值、缺失值等,或者数据量不足,无法提供足够的信息来训练一个有效的模型。
0(没有严重逾期):
模型在0类表现较好,准确度很高,达到95%,召回率也很高,达99%。
可能的错误主要来自于少数漏报或误报情况,即极少数实际没有严重逾期的样本被错误预测为有严重逾期。
1(有严重逾期):
模型在1类性能较差,准确度较低只有57%,召回率也很低,F1-Score仅为0.21。主要问题在于存在大量漏报(真正有严重逾期的样本被预测为没有)和一定的误报情况(将没有严重逾期的样本预测为有逾期)。
改进建议
特征工程:
(1)探索数据集,增加更多潜在特征。
(2)特征选择:使用特征选择技术来确定哪些特征对于预测最有帮助,减少冗余特征。
(3)特征变换:对现有特征进行变换,如对数变换、多项式特征等。
(4)特征构造:创建新的特征组合,比如将多个特征结合起来形成更有意义的衍生特征。
2.模型选择与调参:(1)尝试其他模型,可以考虑使用其他回归模型,如支持向量机(SVM),神经网络或集成方法(如随机森林、梯度提升机)。
(2)调整模型参数:对选定模型进行超参数调优,以找到最佳参数组合。
使用交叉验证来评估模型性能,避免过拟合。
3.数据处理策略调整重采样技术:由于数据集存在明显的不平衡,可以考虑使用重采样技术或欠采样技术来平衡两个类别的数量。


以下是第三次课“3.2.1~3.2.5人机交互流程设计”相关内容的课堂笔记,加油。
本章节主要是使用已有模型对图像进行识别,主要思想如下:
读取标签文件>加载模型>加载图像>图像预处理>进行图像识别>获取预测结果>打印结果
感觉识别图像后获取预测结果这部分还是需要花一些时间去理解里面的数据结构的。
3.2.1~3.2.5 代码部分
1. 标签文件的读取相关
场景一:读取标签文件中的记录,并去除行首尾的空白字符
class_names = [name.strip() for name in open('voc-model-labels.txt').readlines()]
场景二:定义情感类别与数字标签的映射表
emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, 'anger':4, 'disgust':5, 'fear':6, 'contempt':7}
场景三:加载类别标签
with open('labels.txt') as f:
labels = [line.strip() for line in f.readlines()]
2.创建会话,加载onnx模型
session =onnxruntime.InferenceSession('resnet.onnx')
3.加载图像
(1)image = Image.open('xxx.jpg').convert('RGB')
加载图片,并将颜色属性转换为RGB
(2)image = Image.open('xxx.png').convert('L')
加载图片,并转为灰度图
4.图像预处理
场景一:
image = image.resize((28, 28))
调整大小
image_array = np.asarray(image, dtype=np.float32)
转为numpy数组
image_array = np.expand_dims(image_array, axis=0)
添加通道维度
image_array = np.expand_dims(image_array, axis=0)
添加通道维度(把原来二维的图片调整为四维的,并无实际意义)
场景二:
img_path = os.path.join(path, file_path)
orig_image = cv2.imread(img_path)
使用 OpenCV 读取图像文件
image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
将图像从 BGR 颜色空间转换为 RGB 颜色空间
image = cv2.resize(image, (320, 240))
将图像调整为 320x240 的尺寸
image_mean = np.array([127, 127, 127])
定义图像归一化的均值数组
image = (image - image_mean) / 128
对图像进行归一化处理,减去均值并除以 128
image = np.transpose(image, [2, 0, 1])
将图像的维度从 (高度,宽度, 通道数) 转换为 (通道数,高度,宽度)
image = np.expand_dims(image, axis=0)
在第一个维度上扩展一个维度
image = image.astype(np.float32)
将图像数据类型转换为 float32 类型
time_time = time.time()
记录开始时间,用于计算模型推理的耗时
confidences, boxes = ort_session.run(None, {input_name: image})
使用 ONNX Runtime 运行模型,输入图像数据,得到模型输出的置信度和边界框
print("cost time:{}".format(time.time() - time_time))
计算并打印模型推理的耗时
5.run(...) 执行预测,并输出预测结果
场景一预测图片所属哪个类别:
input_name = session.get_inputs()[0].name
获取模型输入名称
output_name = session.get_outputs()[0].name
获取模型输出名称
output = session.run([output_name], {input_name: processed_image})[0]
进行图片识别
probabilities = scipy.special.softmax(output, axis=-1)
应用 softmax 函数获取概率
top5_idx =np.argsort(probabilities[0])[-5:][::-1]
top5_prob = probabilities[0][top5_idx]
获取最高的5个概率和对应的类别索引
print("Top 5 predicted classes:")
for i in range(5):
print(f"{i+1}: {labels[top5_idx[i]]} - Probability: {top5_prob[i]}")
打印结果
场景二:识别图片是哪个数字:
ort_inputs = {ort_session.get_inputs()[0].name: image_array}
返回模型输入列表
ort_outs = ort_session.run(None, ort_inputs)
执行预测,执行结果是预测到0到9的概率
predicted_class = np.argmax(ort_outs[0])
获取预测结果,即最大值对应的位置
print(f"Predicted class: {predicted_class}")
打印结果
场景三:识别图片中人物的情感
predicted_label = np.argmax(ort_outs[0])
解码模型输出,找到预测概率最高的情感类别
predicted_emotion =list(emotion_table.keys())[predicted_label]
根据预测的标签找到对应的情感名称
print(f"Predicted emotion: {predicted_emotion}")
输出预测的情感
场景四
output = session.run([output_name], {input_name: processed_image})[0]
进行图片识别
accuracy = scipy.special.softmax(output, axis=-1)
应用 softmax 函数获取识别分类后的准确率
predicted_idx = np.argmax(accuracy[0])
获取预测(概率最大值)的类别索引
prob_percentage =accuracy[0][predicted_idx]*100
获取预测的准确值,因为后面会转为百分比,因此这里先乘以100
predicted_label = labels[predicted_idx]
获取预测的类别标签
print(f"Predicted class: {predicted_label}, Accuracy: {prob_percentage:.2f}%")
输出预测结果,包含百分比形式的概率
6.保存结果
if not os.path.exists(result_path):
os.makedirs(result_path)
如果保存结果的目录不存在,则创建该目录
3.2.1~3.2.5 问答部分
给出在图像/情感/...识别评估系统中使用“xxx.onnx”模型的一种人机交互的最优方式。
下列写六条即可。
1.用户界面设计:提供简洁直观的用户界面,方便用户上传图片和查看识别结果。
2.模型加载:系统启动时预加载模型和标签,减少用户等待时间。
3.图像上传与预处理:允许用户上传图片,并自动进行必要的预处理。
4.图像识别:后台使用“xxonnx”模型处理预处理后的图片。
5.结果展示:清晰展示识别结果,包括最可能的类别和概率。
6.交互反馈:提供用户反馈选项,以改进模型性能。
7.帮助与支持:内置帮助文档和客服支持,提升用户体验。
8.性能优化:优化系统响应速度和模型处理能力。
9.安全性考虑:确保用户数据安全和隐私保护。
10.多语言支持:界面支持多语言,满足全球用户需求。
11.可访问性:确保UI无障碍,方便所有用户操作。

 点亮在推荐看分享给更多朋友~
点亮在推荐看分享给更多朋友~

