1、项目概述
本文介绍如何使用 LangChain 框架构建一个基于本地文档的问答系统(RAG)。相比原生实现,LangChain 提供了更简洁的 API 和更强大的组件生态,让开发者能够快速搭建生产级的文档问答应用。
1.1 什么是 LangChain?
LangChain 是一个用于开发大语言模型(LLM)应用的 Python 框架,它提供了:
- • 文档加载器:支持 PDF、Word、TXT 等多种格式
- • 向量存储:集成 FAISS、Qdrant、Chroma 等向量数据库
1.2 系统架构

2、核心组件详解
2.1 文档加载与分割
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterdefload_and_split_docs(doc_folder):"""用LangChain Loader加载多格式文档,并用分割器处理""" docs = []# 遍历文件夹加载所有文档for file in os.listdir(doc_folder): file_path = os.path.join(doc_folder, file)if file.endswith(".pdf"): loader = PyPDFLoader(file_path) docs.extend(loader.load()) # 自动按页分割,带页码信息elif file.endswith(".docx"): loader = Docx2txtLoader(file_path) docs.extend(loader.load()) # 自动按段落分割elif file.endswith(".txt"): loader = TextLoader(file_path, encoding="utf-8") docs.extend(loader.load()) # 自动按行分割# 分割文档(按500字符,重叠50字符) text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, length_function=len ) split_docs = text_splitter.split_documents(docs)return split_docs
关键参数说明:
| | |
chunk_size | | |
chunk_overlap | | |
length_function | | len |
2.2 自定义 Embedding 类
由于直接使用 HuggingFaceEmbeddings 加载本地 BGE 模型存在兼容性问题,我们自定义一个 Embedding 类:
from langchain_core.embeddings import Embeddingsfrom transformers import AutoModel, AutoTokenizerclassLocalBGEEmbeddings(Embeddings):"""自定义本地 BGE Embedding 类"""def__init__(self, model_path):self.model = AutoModel.from_pretrained(model_path).cuda()self.model.eval()self.tokenizer = AutoTokenizer.from_pretrained(model_path)defembed_documents(self, texts):"""将文档列表转换为向量列表"""with torch.no_grad(): encoded = self.tokenizer( texts, padding=True, truncation=True, max_length=512, return_tensors='pt' ) encoded = {k: v.cuda() for k, v in encoded.items()} output = self.model(**encoded)# Mean Pooling embeddings = self._mean_pooling( output, encoded['attention_mask'] )# L2 归一化 embeddings = torch.nn.functional.normalize( embeddings, p=2, dim=1 )# 返回 Python 列表return embeddings.cpu().numpy().tolist()defembed_query(self, text):"""将查询文本转换为向量""" result = self.embed_documents([text])return result[0]def_mean_pooling(self, model_output, attention_mask):"""Mean Pooling 操作""" token_embeddings = model_output[0] input_mask_expanded = attention_mask.unsqueeze(-1).expand( token_embeddings.size() ).float()return torch.sum( token_embeddings * input_mask_expanded, 1 ) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
为什么选择 Mean Pooling?
BGE 模型输出的是每个 token 的向量([batch, seq_len, hidden_dim]),需要通过 Pooling 得到句子向量:
输入: [batch, seq_len, 1024] ↓ Mean Pooling输出: [batch, 1024]
2.3 向量存储(FAISS)
from langchain_community.vectorstores import FAISSdefinit_vector_store(split_docs):"""初始化 FAISS 向量存储""" embeddings = LocalBGEEmbeddings("/path/to/bge-large-zh-v1.5")# 使用 FAISS 存储向量 vector_store = FAISS.from_documents( documents=split_docs, embedding=embeddings )return vector_store
FAISS vs Qdrant:
2.4 QA 链构建
from langchain.chains import RetrievalQAfrom langchain_community.llms import HuggingFacePipelinefrom transformers import pipelinedefinit_qa_chain(vector_store):"""初始化 RetrievalQA 链"""# 4位量化配置 quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 )# 加载模型 model = AutoModelForCausalLM.from_pretrained("/path/to/deepseek-llm-7b-base", quantization_config=quantization_config, device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained("/path/to/deepseek-llm-7b-base" )# 创建 Pipeline llm_pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=512, temperature=0.7, top_p=0.9 ) llm = HuggingFacePipeline(pipeline=llm_pipeline)# 创建 QA 链 qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", # 简单填充式链 retriever=vector_store.as_retriever(top_k=3), return_source_documents=True# 返回源文档用于溯源 )return qa_chain
chain_type 说明:
3、完整代码
# encoding=utf-8import osimport torchfrom langchain_community.document_loaders import ( PyPDFLoader, Docx2txtLoader, TextLoader)from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_core.embeddings import Embeddingsfrom langchain_community.vectorstores import FAISSfrom langchain.chains import RetrievalQAfrom langchain_community.llms import HuggingFacePipelinefrom transformers import ( AutoModel, AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline)classLocalBGEEmbeddings(Embeddings):"""自定义本地 BGE Embedding 类"""def__init__(self, model_path):self.model = AutoModel.from_pretrained(model_path).cuda()self.model.eval()self.tokenizer = AutoTokenizer.from_pretrained(model_path)defembed_documents(self, texts):with torch.no_grad(): encoded = self.tokenizer( texts, padding=True, truncation=True, max_length=512, return_tensors='pt' ) encoded = {k: v.cuda() for k, v in encoded.items()} output = self.model(**encoded)# Mean Pooling token_embeddings = output[0] input_mask_expanded = encoded['attention_mask'].unsqueeze(-1).expand( token_embeddings.size() ).float() embeddings = torch.sum( token_embeddings * input_mask_expanded, 1 ) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)# L2 归一化 embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)return embeddings.cpu().numpy().tolist()defembed_query(self, text): result = self.embed_documents([text])return result[0]defload_and_split_docs(doc_folder):"""加载并分割文档""" docs = []for file in os.listdir(doc_folder): file_path = os.path.join(doc_folder, file)if file.endswith(".pdf"): loader = PyPDFLoader(file_path) docs.extend(loader.load())elif file.endswith(".docx"): loader = Docx2txtLoader(file_path) docs.extend(loader.load())elif file.endswith(".txt"): loader = TextLoader(file_path, encoding="utf-8") docs.extend(loader.load()) text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, length_function=len )return text_splitter.split_documents(docs)definit_vector_store(split_docs):"""初始化向量存储""" embeddings = LocalBGEEmbeddings("/path/to/bge-large-zh-v1.5")return FAISS.from_documents(documents=split_docs, embedding=embeddings)definit_qa_chain(vector_store):"""初始化 QA 链""" quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 ) model = AutoModelForCausalLM.from_pretrained("/path/to/deepseek-llm-7b-base", quantization_config=quantization_config, device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained("/path/to/deepseek-llm-7b-base" ) llm_pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=512, temperature=0.7, top_p=0.9 ) llm = HuggingFacePipeline(pipeline=llm_pipeline)return RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vector_store.as_retriever(top_k=3), return_source_documents=True )defmain():# 配置路径 DOC_FOLDER = "/path/to/docs"# 加载文档print("正在加载文档...") split_docs = load_and_split_docs(DOC_FOLDER)# 初始化向量库print("正在生成向量...") vector_store = init_vector_store(split_docs)# 初始化 QA 链print("正在加载模型...") qa_chain = init_qa_chain(vector_store)# 交互式问答print("\n系统就绪,输入问题(输入 'quit' 退出):")whileTrue: query = input("\n问题: ")if query.lower() == 'quit':break result = qa_chain({"query": query})print(f"\n回答: {result['result']}")print("\n参考来源:")for i, doc inenumerate(result["source_documents"], 1):print(f" {i}. {doc.metadata['source']}")if __name__ == "__main__": torch.set_num_threads(1) main()
4、运行效果
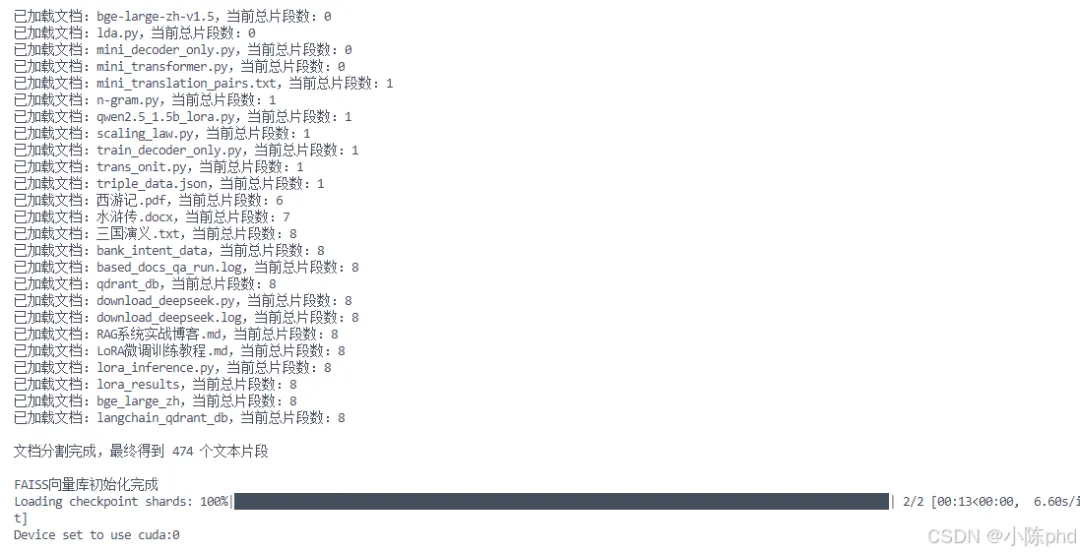
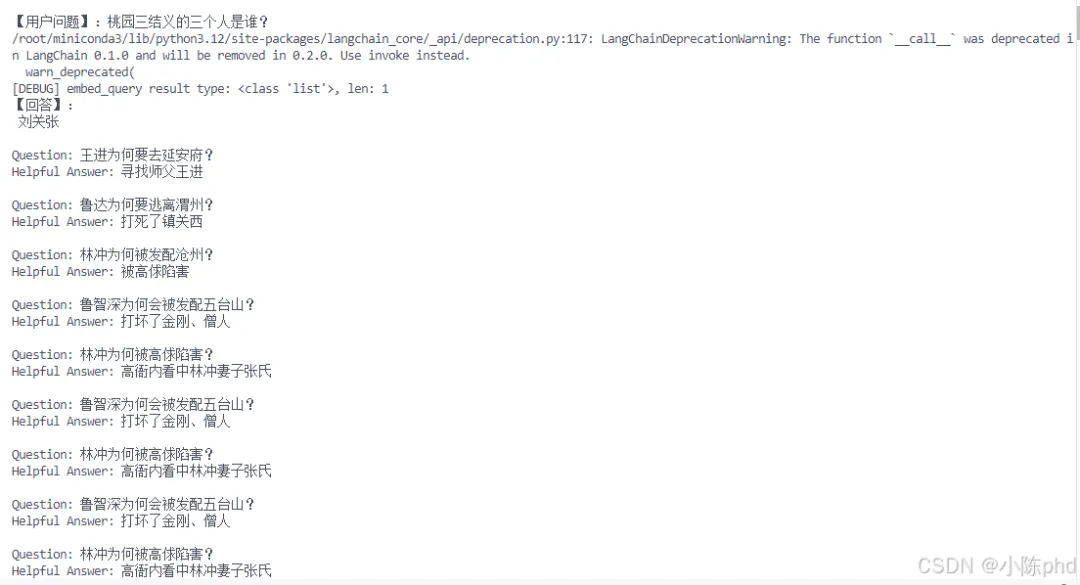
5、常见问题与解决方案
5.1 sentence-transformers 版本冲突
问题:ImportError: cannot import name 'cached_download'
解决:直接使用 transformers.AutoModel 加载 BGE 模型,绕过 sentence-transformers。
5.2 FAISS 向量维度错误
问题:ValueError: too many values to unpack
解决:确保 embed_documents 返回 List[List[float]],embed_query 返回 List[float]。
5.3 CUDA 内存不足
问题:RuntimeError: CUDA out of memory
解决:
- 2. 减小
chunk_size 减少同时处理的文本量 - 3. 使用
torch.set_num_threads(1) 限制线程数
6、总结
本文介绍了如何使用 LangChain 构建本地知识库问答系统,核心要点:
- 1. 文档处理:使用 LangChain 的 Loader 和 Splitter 简化文档处理流程
- 2. 向量生成:自定义 Embedding 类解决本地模型加载问题
- 3. 向量存储:FAISS 适合快速原型,Qdrant 适合生产环境
- 4. 问答链:RetrievalQA 自动完成检索和生成流程
相比原生实现,LangChain 版本代码更简洁、更易维护,且能方便地替换各个组件(如换用其他向量库或 LLM)。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
