用了Seedance一段时间了,今天特意花时间整理一份学习笔记,记录了一些成功or失败的经验。相信大家已经看到了不少攻略,但自己生成视频的时候效果没有那么顺畅,可以看一下我后面生成视频时的坑,是不是踩了不少。很多人喜欢上来直接就用seedance去生成视频,这种做法可控性很差,有句话说得好:seedance在工作流中时间占比越低,生成的视频效果越好。
这就是说你需要在生成视频前,想好你的场景、人物、剧情脚本,然后再输入到seedance中去,才可以生成一个效果不错的视频,直接扔一个指令进去就是真“抽卡”了,是没办法做多视频的。场景与人物
如果要求不高,可以直接使用即梦他们家自带的图像生成模型,办了标准会员后可以免费使用图片5.0 Lite和图片4.6模型。不过说实话这俩模型在审美方面有点一般,我有时用他们的4.5模型(即梦中付费使用,豆包中免费使用,可以小薅一下),大部分时间还是用MJ+Nano Banana。游戏CG风格,极具艺术感,震撼人心,色彩丰富,暗部叠加,特写镜头,超高清。落叶飞溅,前景落叶虚化,动态模糊,背景动态虚化,阳光灿烂,蓝天白云,光影交错,仰拍特写镜头,突出速度感和视觉冲击力,强透视。
从生成难度上讲,越接近真实的图片越难生成,真人图像在没有光影和滤镜加持的情况下非常容易出现塑料感,离现实越远的图像反而更加容易。刚开始做视频以真人为目标来做是一个极为困难的开始,容易产生违和感,反而是脱离现实的场景更加简单。下面两个图都是用seedream 4.5生成的,图1真人使用了摄像机镜头、90s质感、噪点等方式模拟真人感,图2增加了更多滤镜,虽然效果上看已经很不错了,经常使用AI做图的朋友肯定也是一眼能看出来问题,如果使用虚拟场景中的形象就不存在这种现象。1:A cinematic candid shot , featuring a stunning Asian woman with short messy bob hair in a crowded 90s night club. She wears a shimmering champagne halter dress. High film grain, heavy ISO noise, 35mm vintage film photography aesthetic. Nostalgic mood, soft focus。
2:A cinematic candid shot, featuring a stunning Asian woman with short messy bob hair in a crowded 90s night club. She wears a shimmering champagne halter dress. The image is characterized by extreme low-shutter speed motion blur due to the dark environment, creating significant movement streaks. High film grain, heavy ISO noise, 35mm vintage film photography aesthetic. Nostalgic mood, soft focus, with dim lighting that has a prominent aged yellow-green color tint and slightly faded, desaturated tones.
对于虚拟场景,可以参考即梦或者mj主页的prompt,有大量可以参考的案例,素材图基本决定了视频视觉调性,这部分要认真对待。视频生成
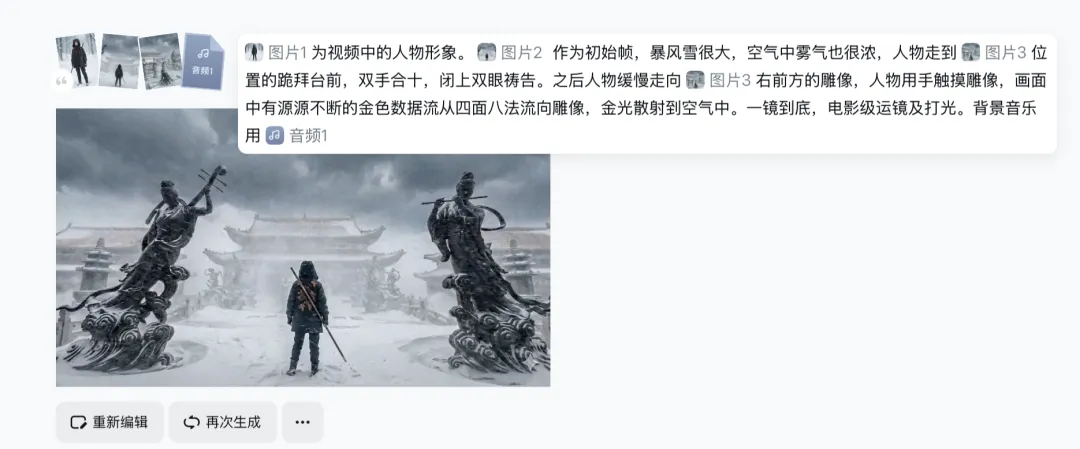
在前面已经做好人物、场景图之后,一致性问题其实已经可以通过seedance 2.0的全能参考解决了,后面就是要设计脚本,分批次输出视频。一次性输出一个完整可用视频的可能性很低,尤其是现在用的人多了,多少感觉上有点降智,可以无脑生成三个,然后去简单剪辑一下。脚本的设计网上已经有比较全的教程,基本上就是场景+人物+景别+运镜+风格这几个要素,大家可以自行学习,我就不赘述了,如果不是特别擅长写这个可以用豆包、ds帮忙改改,注意用词不要太抽象。另外要注意模型的注意力有限,如果指令过于复杂,模型就没办法完全遵循,只能挑着来。下面我总结出来了几条经常遇到但并不怎么被提及的经验供大家参考:1.尽量使用seedance 2.0,而不要使用seedance 2.0 fast。积分上有一点点折扣,但效果上差了很远,无脑使用前者即可,fast在注意力不够,没办法适应复杂场景,比方说下面这个没用识别出来九宫图:2. 如果你是刚开始做一个项目,第一次不要选择15s的视频生成,先从5s左右的开始,看一下自己的提示词会产生什么样的效果,然后再去调整。最好是能找到别人的提示词,在他的提示词基础上进行更改3. 目前网上比较网红的提示词看起来都比较臃肿,很多词自己看着似乎没太有必要。但如果去掉了一两个效果上还真可能大打折扣,如果没有钞能力反复实验的话还是不要乱动那些看起来没用的提示词4. 如果不是一次性生成完整视频,不要让AI生成BGM,否则后面剪辑的时候BGM会有突变。后面需要BGM可以用Gemini里的Lyria 3生成,用起来也比较丝滑,没有版权问题。5. 使用全能参考时要注意参考图的跨度不能太大,模型会计算两个参考图之间的关联,如果它找不到过度,那就会生搬硬套。这里伏地魔在天上飞就比较生硬(哈利波特的ip已经被禁掉了,现在生成不了了)6. 模型会对人物的在场景中的相对位置进行定位,如果你的视频有位置的概念,那么参考图中的位置也必须准确,否则人物会产生意想不到的移动。下面这个例子首帧和尾帧都是在涩谷十字路口,本来是想让人物可以垂直下落,但因为模型识别到了十字路口其实在人物背后,强行把人物往后拉了一段距离7. 生成视频之前一定要脑子里过一遍脚本画面,选择一个合理的时间。如果你指令很多但给的时间不足,模型就会压缩你的指令,产生不可控的结果。下面这个我给了15s时间,一镜到底让人物从门口走到跪拜的地方,但因为距离实在是太远了,走过去花费时间非常长,因此模型就在这里切了镜头,打破了一镜到底的要求。以上就是近期踩坑感悟,如果大家有兴趣,欢迎关注我,一起加群学习,附带一个小成片。