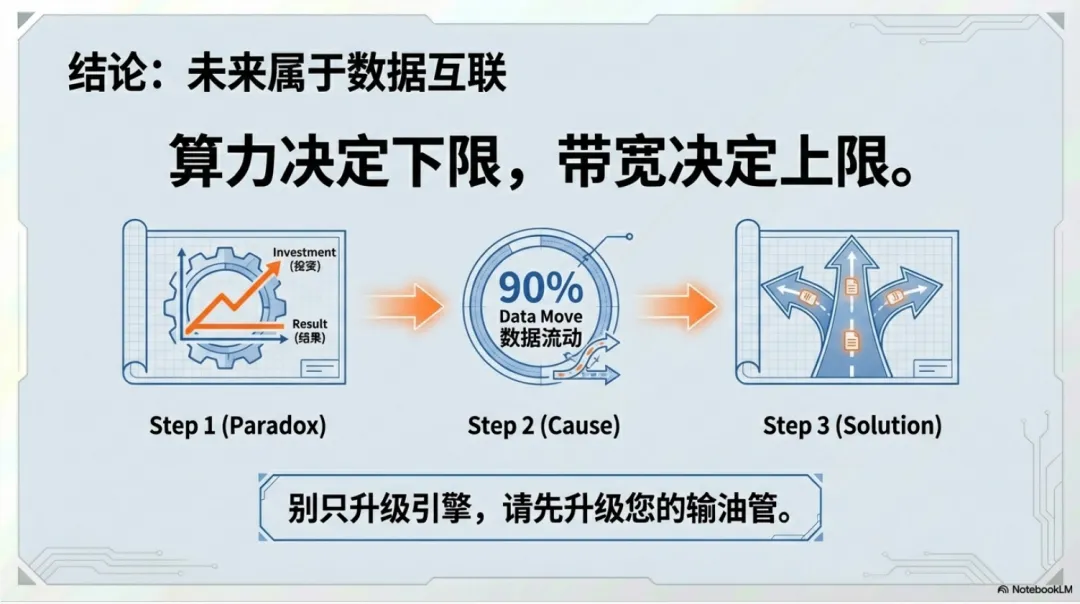
基于对人工智能推理工程实践的现状分析,分析企业级AI部署面临的核心矛盾:算力投入持续增加,但业务体验未获相应提升。
原因是推理瓶颈已从计算能力转向数据流通效率。分析AI显存相关的HBM、GDDR、LPDDR三条技术路线特点,评估不同规模下的系统约束。
分析企业推理算力决策的应对策略,未来AI基础设施的竞争重点将转向数据互联能力建设。
一、问题背景与现状分析
企业级用户在人工智能推理服务部署中普遍面临投入产出失衡的问题。具体表现为:
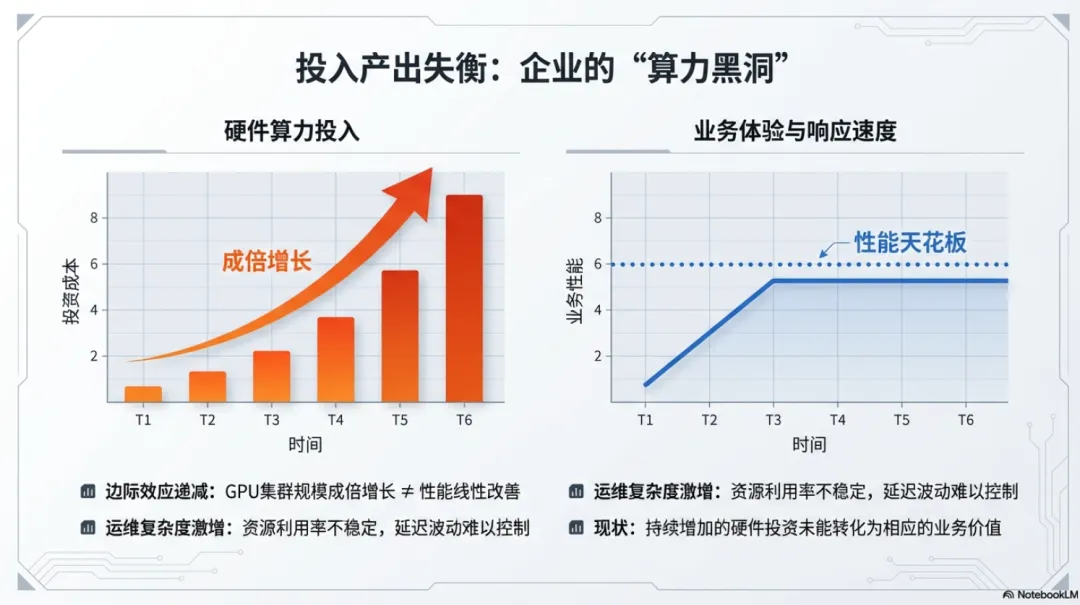
- 算力投入与业务体验脱节GPU数量与集群规模成倍增长,但用户感知的响应速度、服务稳定性并未获得线性改善。
- 系统扩容效果边际递减增加硬件设备后,系统吞吐能力提升有限,部分场景甚至出现性能倒退。
- 运维管理复杂度激增高峰期延迟波动、资源利用率不稳定等问题,增加了系统运维难度和成本。
- 资本市场信号:炒作焦点从GPU制造商转向内存条、存储厂和互联方案供应商。资本可能看不懂晶体管密度,但清楚一个朴素逻辑:算力需要数据来喂,而数据的搬运效率决定了算力的实际产出。
从决策层面看,这一问题已从单纯的技术挑战上升为经营管理课题。持续增加的硬件投资未能转化为相应的业务价值,影响了数字化转型的投资效益。
二、核心问题识别
通过分析发现,人工智能推理效能的瓶颈正在发生根本性转移:
主要矛盾转移:推理瓶颈从"芯片计算能力不足"转向"数据供给不畅"。在大模型推理过程中,超过90%的时间消耗在数据搬运环节,而非实际计算。
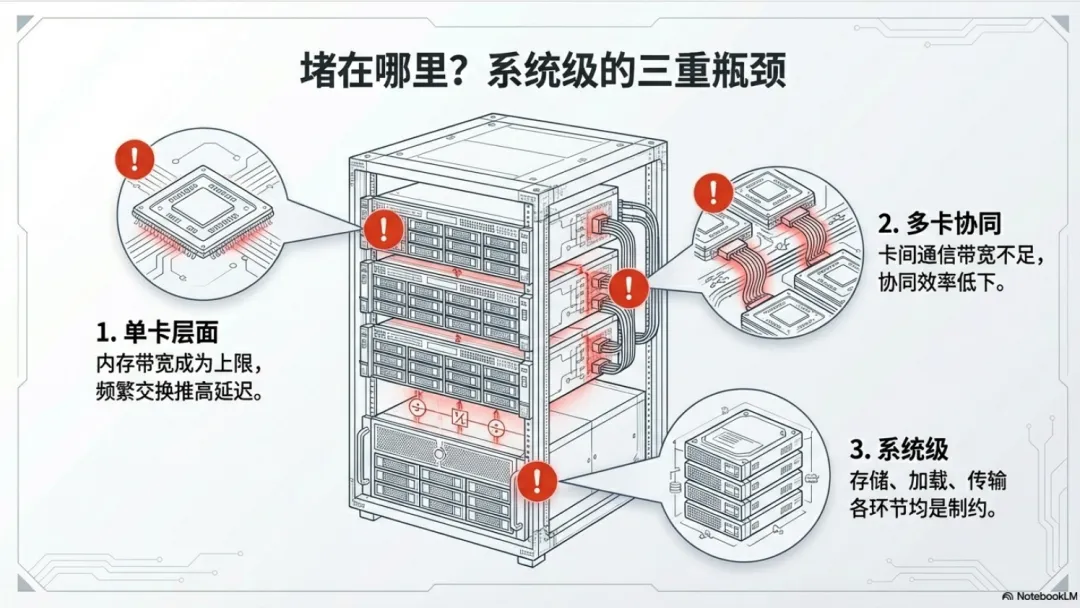
三个层面的瓶颈表现:
- 单卡层面内存带宽成为性能上限,频繁的数据交换推高处理延迟。
- 多卡协同层面
- 系统级层面
这一转变具有重要启示:单纯增加计算单元已无法有效提升系统性能,必须同步优化数据流通路径。
三、AI显存技术原理及路线比较分析
3.1、AI内存基本原理
很多人仍然习惯从PFLOPS角度讨论AI算力。但在推理阶段,真正决定性能稳定性的,是内存与数据通路。
可以把大模型推理简化成一个公式:
推理结果生成时间 ≈ 数据搬运时间 + 计算时间
而在当前架构下,数据搬运时间占比越来越高。
这也是为什么资本市场开始炒作HBM、存储、互联芯片——不是因为“内存更性感”,而是因为:
AI算力的上限,不再由算术能力决定,而由数据带宽决定。
当前AI硬件的分化,本质上是三条内存路线的分化。
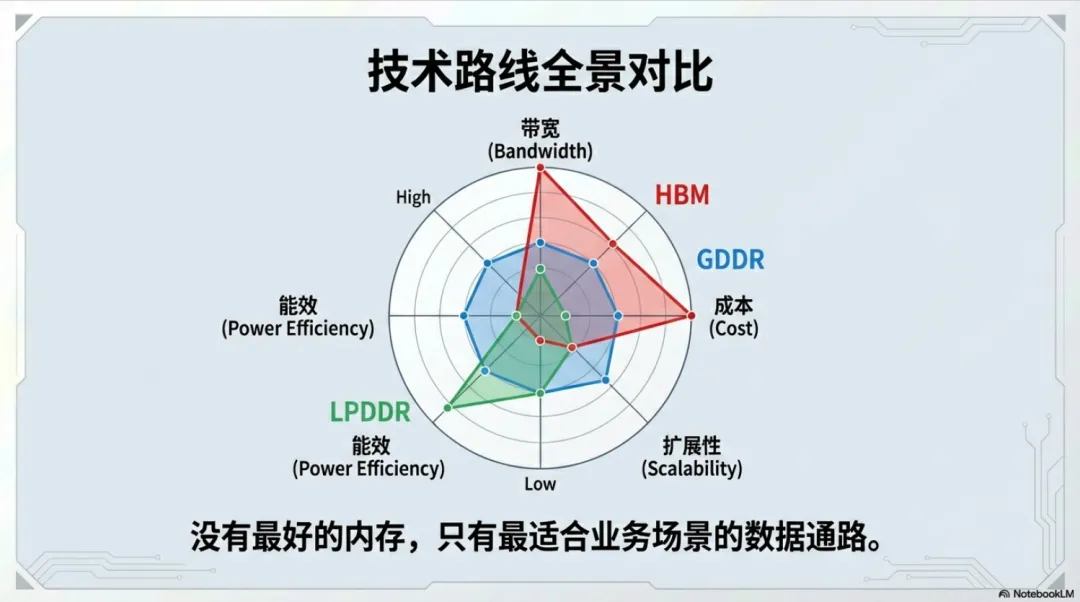
3.2、当前市场存在三条主要技术路线,各自特点如下:

| | | |
|---|
| HBM(高带宽内存) | | | |
| GDDR(图形内存) | | | |
| LPDDR(低功耗内存) | | | |
HBM(High Bandwidth Memory)采用堆叠封装,紧贴GPU核心,带宽达到TB/s级别。
优势在于:带宽极高、延迟极低,适用于超大模型训练和高端推理场景。
但问题也很明显:成本高、容量扩展受限、封装复杂度高
HBM路线,本质是“用带宽解决问题”。
GDDR是当前大部分数据中心GPU采用的显存方案。
特点是:带宽高于传统DDR、成本相对可控、容量较灵活;适用于主流推理场景。
但在多卡并行时,GDDR的优势会被卡间互联限制抵消。
LPDDR常见于端侧设备和边缘计算场景。
优势:功耗低、成本低
但带宽能力有限,不适合超大模型。
代表的是“规模分散,而非集中堆算力”。
真正的分化不是“谁算得快”,而是:
谁的数据路径更短,谁的带宽更高,谁的搬运延迟更低。
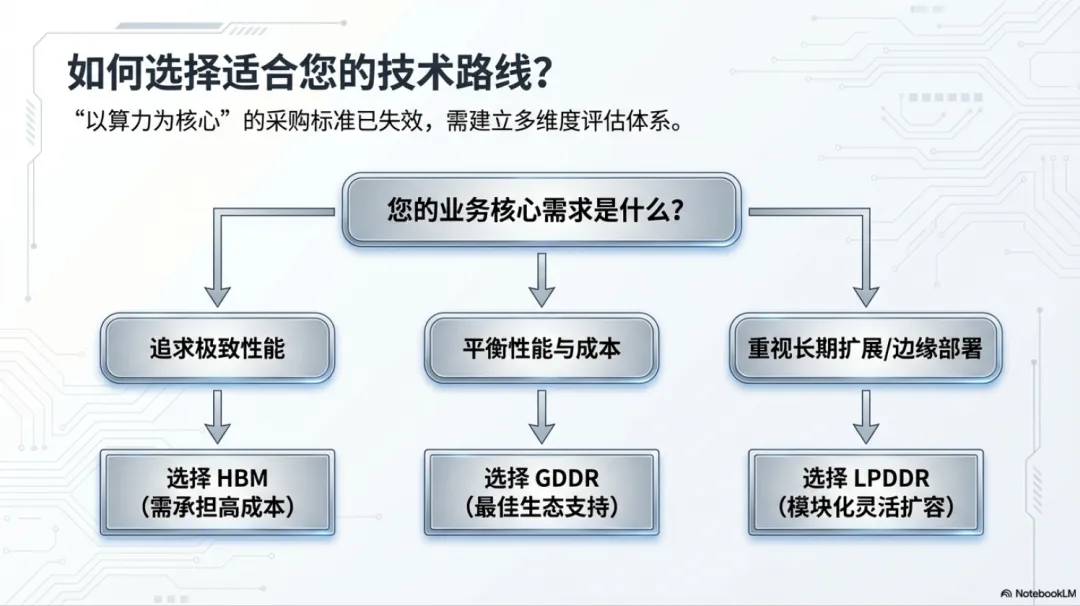
技术选择建议:
四、对企业级推理决策者的影响评估
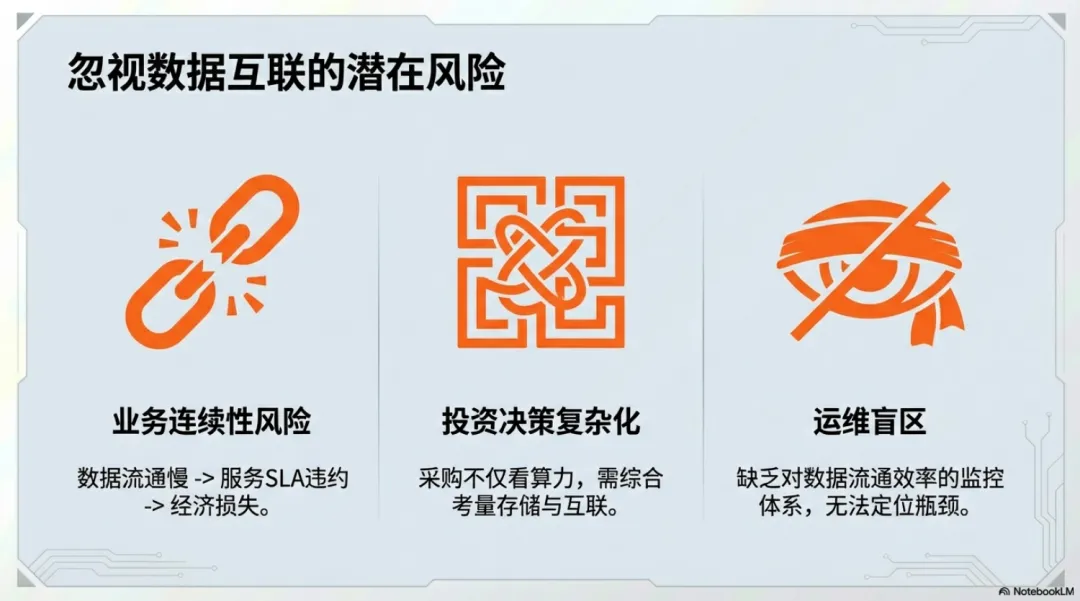
数据互联瓶颈对企业级用户产生多方面影响:
1. 投资决策复杂性增加硬件采购需综合考虑计算、存储、互联等多维度指标,"以算力为核心"的采购标准已不适用大规模推理场景。
2. 业务连续性风险上升数据流通效率直接影响服务稳定性,可能引发服务等级协议违约,造成直接经济损失。
3. 技术选型战略价值凸显选择适合自身业务特点的技术路线,成为影响长期竞争力的关键因素。
4. 运维管理要求提高需要建立对数据流通效率的监控体系,及时发现并解决瓶颈问题。
五、结论与展望
主要结论:
- 人工智能推理效能的瓶颈已从计算能力转向数据流通效率。
- 单纯增加硬件投入难以持续提升系统性能,必须优化数据路径设计。
发展趋势判断:
- 技术评价标准迁移
- 产业生态重构
- 专业化分工深化
政策启示:
- 在相关产业政策制定中,应重视数据流通基础设施的建设。
- 加强跨领域协同,推动计算、存储、网络技术的融合发展。