GWAS学习笔记:DeepVariant你真的好快!
❝
小师妹:师兄~ 我做群体遗传学,有好几个T的重测序数据来做SNP Calling,但是用GATK真的好慢啊!
大师兄:没事啊!你去试试谷歌研发的DeepVariant!亲测很快!
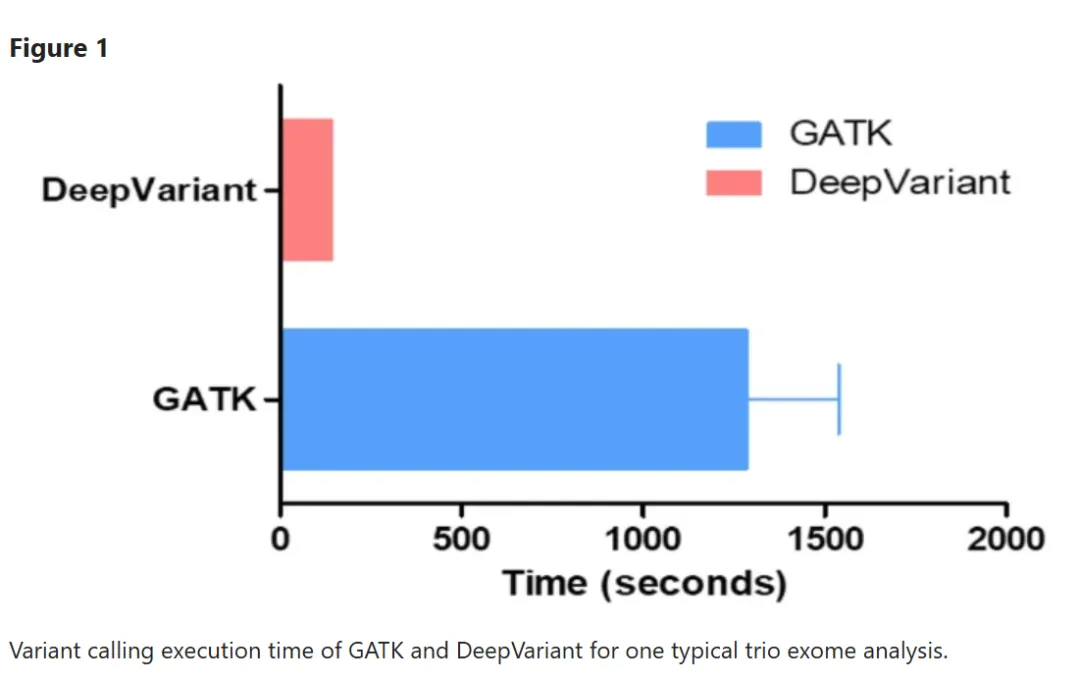
对于小基因组来说,用于变异检测软件的速度差异并不大,但是对于大基因组来说数据量的剧增则会产生很大的差异。长期以来,GATK(Genome Analysis Toolkit)凭借成熟的统计模型占据主流地位,但随着深度学习技术的崛起,Google 推出的 DeepVariant 正以黑马之姿改写规则。今天就来深度拆解,看看 DeepVariant 究竟强在哪?
GATK先通过隐马尔可夫模型(HMM)计算读取序列的可能性,再用逻辑回归建模碱基错误,最后靠高斯混合模型过滤假阳性。这种方法依赖专家手工设计特征,比如碱基质量值、测序深度等,就像一位经验丰富但循规蹈矩的老医生,诊断依据清晰但应对复杂情况时灵活性不足。这也是GATK慢的原因!
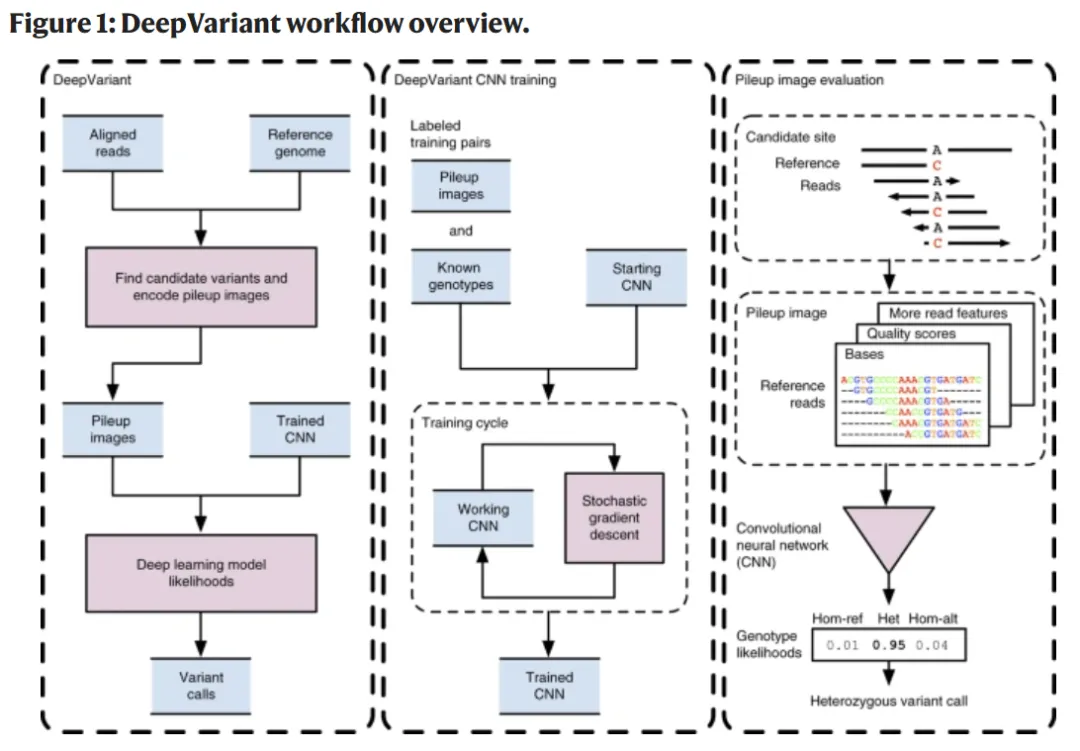
DeepVariant:把变异检测变成 "图像识别"
DeepVariant 将基因测序数据转换成 "堆积图"(pileup image),再用卷积神经网络(CNN)像识别图片一样判断变异。简单来说:
先把参考基因组、测序 reads、质量分数等信息编码成 RGB 图像;
用 Inception 架构的 CNN 学习 "真实变异" 和 "测序错误" 的图像差异;
直接输出纯合参考、杂合变异、纯合变异三种基因型的概率。
这种方式无需手工设计特征,CNN 能自动捕捉 reads 间的复杂依赖关系,就像一位自带 AI 大脑的新医生,能从海量数据中总结规律,应对不同测序技术的能力更强。
根据已经发表的文献,从准确性、效率、通用性、成本四个核心维度,用实验数据说话:
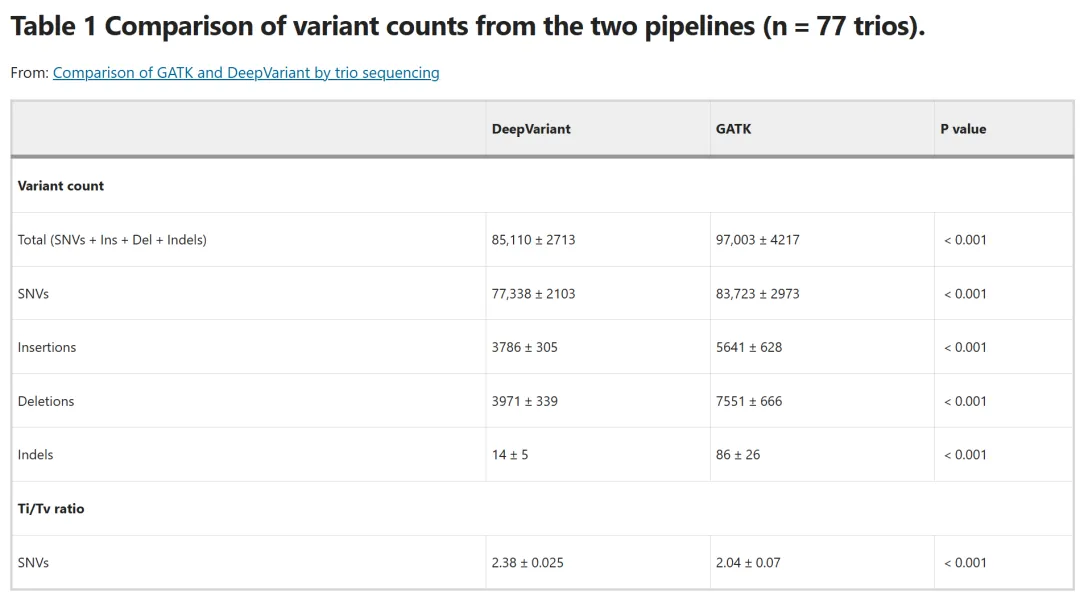
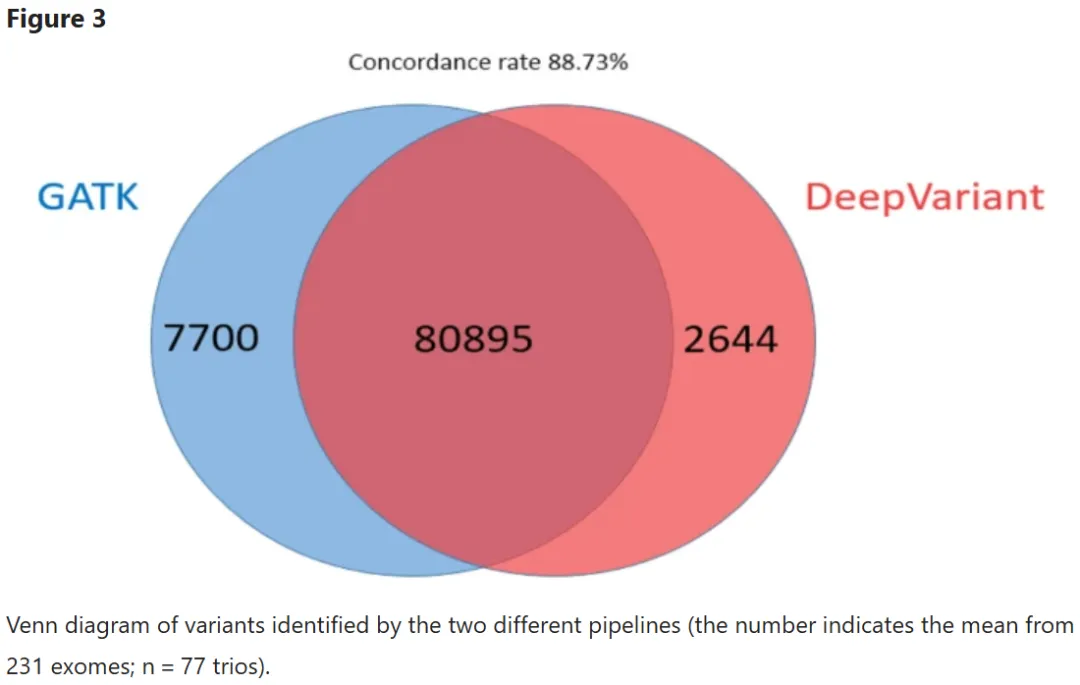
孟德尔错误率:在 77 个临床家系数据中,DeepVariant 的错误率仅 3.09%,而 GATK 高达 5.25%(p<0.001)。这意味着 DeepVariant 的结果更符合遗传规律,减少假阳性诊断。
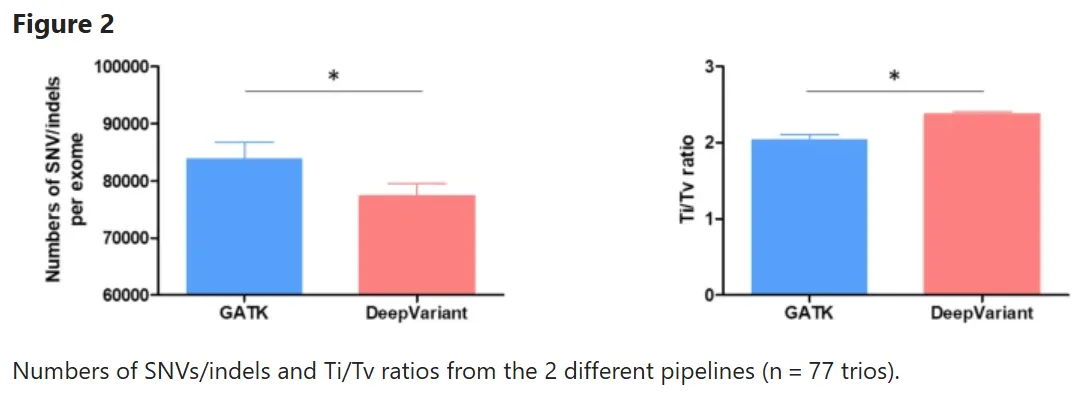
Ti/Tv 比率:该比率越高,真实变异比例越高。DeepVariant 的 Ti/Tv 比率为 2.38,显著高于 GATK 的 2.04,说明其调用的变异更可能是真实有效的。
1000 基因组项目验证:在 2504 个样本的深度测序中,DeepVariant 的 SNP F1 错误比 GATK 低 17.6 倍,插入缺失(indel)F1 错误低 2.6 倍,且违反哈迪 - 温伯格平衡的位点减少 32%。
推荐使用docker拉下来使用,源代码和conda安装会出现一些问题
docker pull google/deepvariant:1.9.0
docker pull ghcr.io/dnanexus-rnd/glnexus:v1.4.1
docker run --rm \
-v "${INPUT_MOUNT}:/input" \
-v "${OUTPUT_MOUNT}:/output" \
google/deepvariant:"${BIN_VERSION}" \
/opt/deepvariant/bin/run_deepvariant \
--model_type=WGS \
--ref="${REF_PATH}" \
--reads="${container_bam}" \
--output_vcf="/output/${sample_id}/${sample_id}_output.vcf.gz" \
--output_gvcf="/output/${sample_id}/${sample_id}_output.g.vcf.gz" \
--num_shards=${SINGLE_SHARDS} \
--vcf_stats_report=true \
--disable_small_model=true \
--logging_dir="${container_log}" \
--dry_run=false
docker run --rm \
-v "${INPUT_MOUNT}:/in" \
-v "${GLNEXUS_OUTPUT_DIR}:/out" \
ghcr.io/dnanexus-rnd/glnexus:"${GLNEXUS_VERSION}" \
glnexus_cli --config DeepVariant --list /out/gvcf_list.txt
完整的合并脚本可以通过关注、收藏和转发后私信领取!
作者:Dongji Club; 校对:Dongji Club; 发布:Dongji Club;








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
