开个坑。认真阅读下 Claude Code 文档。努力搞清楚关于 Claude Code 的一切。
今天来学习Claude Code 的记忆(Memory)
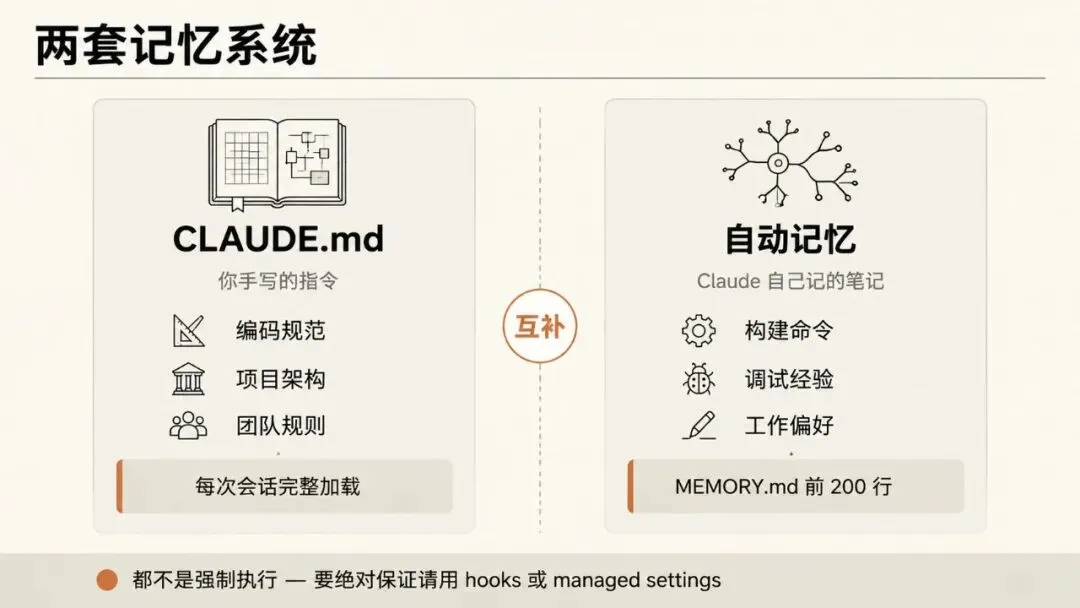 图注:CLAUDE.md(手写的指令)和自动记忆(Claude 自己记的小本本)是两套完全不同的记忆系统 - 谁写的、写了什么、什么时候读,全都不一样。
图注:CLAUDE.md(手写的指令)和自动记忆(Claude 自己记的小本本)是两套完全不同的记忆系统 - 谁写的、写了什么、什么时候读,全都不一样。
Claude Code 的记忆其实分两种。一种是你塞给它的"工作手册",一种是它自己边干活边记的"小笔记"。各管各的:
| | |
|---|
| 谁写的 | | |
| 写了啥 | | |
| 管多宽 | | 每个仓库单独一份,同一仓库不管你开了几个窗口都共享 |
| 什么时候读 | | |
| 适合放什么 | | |
这两种方式,都不是"强制执行"的。也就是说,Claude 读是读了,也会尽量照着做,但它不保证一定照办。打个比方:CLAUDE.md 就像你跟同事说:"一般我们都这么干",但是其实也有不是一般的情况😂。如果某件事必须强制执行 - 比如绝对不准用某个命令、每次提交前必须跑某个检查 - 那应该用 hooks 或者托管设置,不是 CLAUDE.md。
CLAUDE.md:你的工作手册
CLAUDE.md 就是一个普通的 Markdown 文件,Claude 每次开始跟你聊天的时候都会读一遍。目的就是为了不用让你每次都重复解释:项目是什么架构、代码规范是什么、怎么构建、怎么跑测试、团队有什么约定。
啥时候该往里面加东西?
记住官方给的case:同一件事你跟 Claude 解释过两次以上,就写进去。比如:
- • Code review 的时候发现它不知道一些项目常识
CLAUDE.md 里放的是"每次会话都需要的事实"。比如:"API 代码在 src/api/handlers/"、"缩进用 2 格"、"提 PR 之前跑一下 npm test"。
那什么不该放?例如:多步骤的工作流程、只对项目某一块有效的规则 — 这些更适合放到 skill 或者后面要讲的路径规则里。
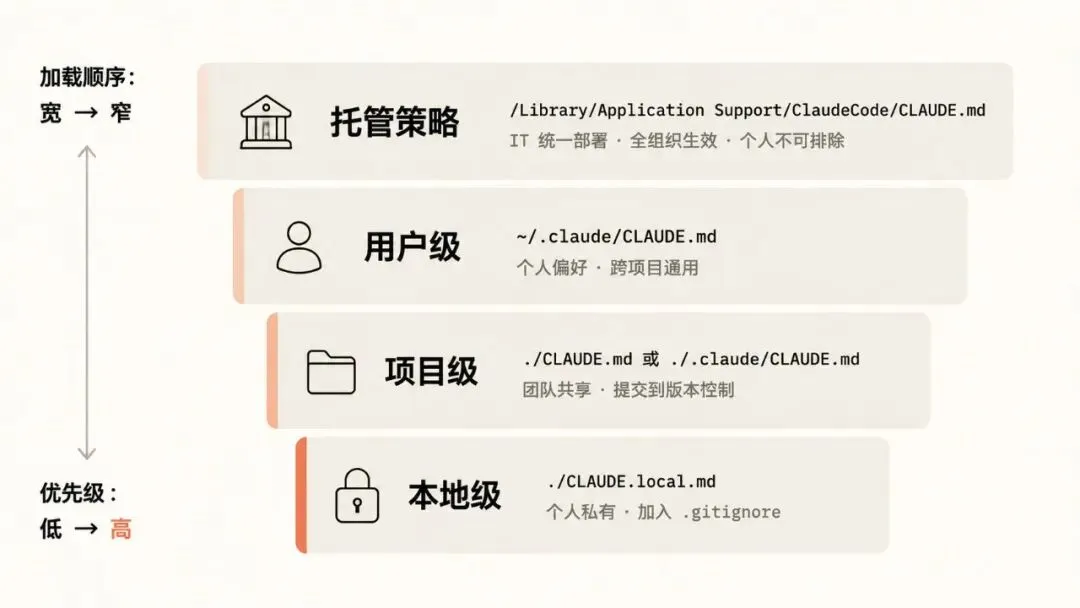
四个层级,从大到小
CLAUDE.md 可以放在好几个地方,各有各的势力范围。Claude 按从大到小的顺序读,越靠近你写代码的目录越后读,影响力也越大:
- 1. 公司级(macOS 上在
/Library/Application Support/ClaudeCode/CLAUDE.md,Linux 上在 /etc/claude-code/CLAUDE.md):IT 或 DevOps 统一推的,全公司都生效。公司编码标准、安全要求、合规规定放这层。你个人关不掉,也排不掉。(不过这个我们基本都碰不到,忽略。) - 2. 个人级(
~/.claude/CLAUDE.md):你自己的偏好,不管你打开哪个项目都生效。比如你爱用什么代码风格、习惯的快捷键、常用的 Shell 命令。跟着你走,跨项目通用。 - 3. 项目级(
./CLAUDE.md 或 ./.claude/CLAUDE.md):团队共享的,应该提交到 git 里。项目架构、构建测试命令、命名规范、常见工作流。谁 clone 这个仓库,谁就拿到同一套。 - 4. 本地级(
./CLAUDE.local.md):你个人对这个项目的偏好,不能提交 - 比如你本地的测试地址、偏好的测试数据、个人快捷键。记得加进 .gitignore。
这一套分层下来,你可以同时拥有:个人习惯 + 项目约定 + 你在这个项目上的特殊偏好。全都在一次会话里生效,越靠近底层的越后生效,所以优先级也越高。
 图注:CLAUDE.md 可以放在四个不同的位置,从全公司的硬规矩到你自己的小偏好。越靠近你写代码的目录,优先级越高。
图注:CLAUDE.md 可以放在四个不同的位置,从全公司的硬规矩到你自己的小偏好。越靠近你写代码的目录,优先级越高。
文件到底怎么找的:往上翻目录
Claude Code 不是只看你当前目录有没有 CLAUDE.md。它会从你启动的位置一路往上翻,把每个父目录里的 CLAUDE.md 和 CLAUDE.local.md 都找出来。
比如说你在 foo/bar/ 目录下启动 Claude Code,它会加载 foo/bar/CLAUDE.md、foo/CLAUDE.md,以及这一路上碰到的所有 CLAUDE.local.md。所有文件拼在一起,不互相覆盖。内容从最外层排到最里层,离你最近的那个最后读 - 所以影响力最大。
Claude 也会发现你工作目录下面的子目录里有没有 CLAUDE.md,但它不会一上来就读。什么时候用到了那个子目录的文件,才临时去读。这是一种节省上下文的策略。
这个查找目录的机制,在大公司的 monorepo 里可能会出问题:父目录里别的团队的 CLAUDE.md 也会被带进来。解决办法是用 claudeMdExcludes 排除掉:
{ "claudeMdExcludes": [ "**/monorepo/CLAUDE.md", "/home/user/monorepo/other-team/.claude/rules/**" ]}
怎么写才能让 Claude 真的听话?
CLAUDE.md 不是硬规矩,是"建议"。你写得怎么样,直接影响 Claude 能不能准确执行。
三条原则:
要具体。 "缩进用 2 格" 比 "代码风格要规范"管用一百倍。"提 PR 前跑 npm test" 比" 记得测试" 管用。"API 代码在 src/api/handlers/" 比 "文件要放对地方"管用。具体到没有歧义。
要精简。 每份 CLAUDE.md 控制在 200 行以内。太长了不光浪费上下文,还让 Claude 抓不住重点,准确度反而下降。东西多了就拆成路径规则,只在相关的文件被处理时才加载。@路径 导入能帮你组织文件,但它不省上下文 - 导入的文件还是启动的时候就加载了。
要一致。 两份 CLAUDE.md 说了互相矛盾的话,Claude 就可能随机挑一个用。定期把四个层级的东西都扫一遍 - 公司级、个人级、项目级、本地级 - 删掉过时的、修掉冲突的。用 HTML 注释(<!-- 这是给人类看的备注 -->)写内部提示,Claude 加载到上下文之前会自动删掉,不浪费 token。
用 @ 导入其他文件
CLAUDE.md 里可以用 @路径 引用别的文件,不用把 README、package.json 或团队工作流文档的内容复制过来,类似:
See @README.md for project overview and @package.json for available scripts.# Additional Instructions- git workflow @docs/git-workflow.md
相对路径和绝对路径都行。注意:相对路径是相对于包含这个 @ 导入的那份 CLAUDE.md 的位置,不是你启动 Claude Code 的工作目录。导入最多嵌套四层。Claude Code 第一次碰到外部文件的导入会弹个确认框;你拒绝了它就关掉,以后不再提示。
如果你用多个 worktree:加了 .gitignore 的 CLAUDE.local.md 只在你创建它的那个 worktree 里存在。想在多个 worktree 之间共享你的个人指令,可以从 home 目录导入:
# Individual Preferences- @~/.claude/my-project-instructions.md
跟 AGENTS.md 等其他工具配置一起用
很多仓库已经有一个 AGENTS.md 文件,给 Cursor、Windsurf 这类工具用的。Claude Code 读的是 CLAUDE.md,不认识 AGENTS.md。最好的做法是让 CLAUDE.md 把 AGENTS.md 导入进来:
@AGENTS.md## Claude CodeUse plan mode for changes under `src/billing/`.
这样两套工具读同一份核心指令,不用维护两份。Claude 专属的额外内容写在导入下面就行。如果你不需要额外内容,直接建个软链接(符号链接)也行:ln -s AGENTS.md CLAUDE.md。另外,跑 /init 命令的时候,如果仓库里有 AGENTS.md、.cursorrules、.windsurfrules,Claude 会自动读并整合进去。
--add-dir 和记忆加载
--add-dir 让你能访问工作目录以外的额外目录。但默认情况下,额外目录里的 CLAUDE.md 不会被加载。要让它生效,得设个环境变量(可以在 cc-switch 里面添加通用配置):
CLAUDE_CODE_ADDITIONAL_DIRECTORIES_CLAUDE_MD=1 claude --add-dir ../shared-config
设了这个变量之后,额外目录里的 CLAUDE.md、.claude/CLAUDE.md、.claude/rules/*.md 和 CLAUDE.local.md 都会一起拉进来。
.claude/rules/:把规则拆开、按需加载
项目大起来,一个 CLAUDE.md 真的塞不下。.claude/rules/ 让你把指令拆成按主题的小文件 - testing.md、api-design.md、security.md - 还能按子目录分组:
your-project/├── .claude/│ ├── CLAUDE.md│ └── rules/│ ├── code-style.md│ ├── testing.md│ ├── security.md│ ├── frontend/│ │ ├── components.md│ │ └── styling.md│ └── backend/│ └── api-design.md
普通规则文件启动时和 .claude/CLAUDE.md 一起加载。但真正好用的是路径限定规则 - 只在 Claude 处理特定文件的时候才加载,平时不占地方。
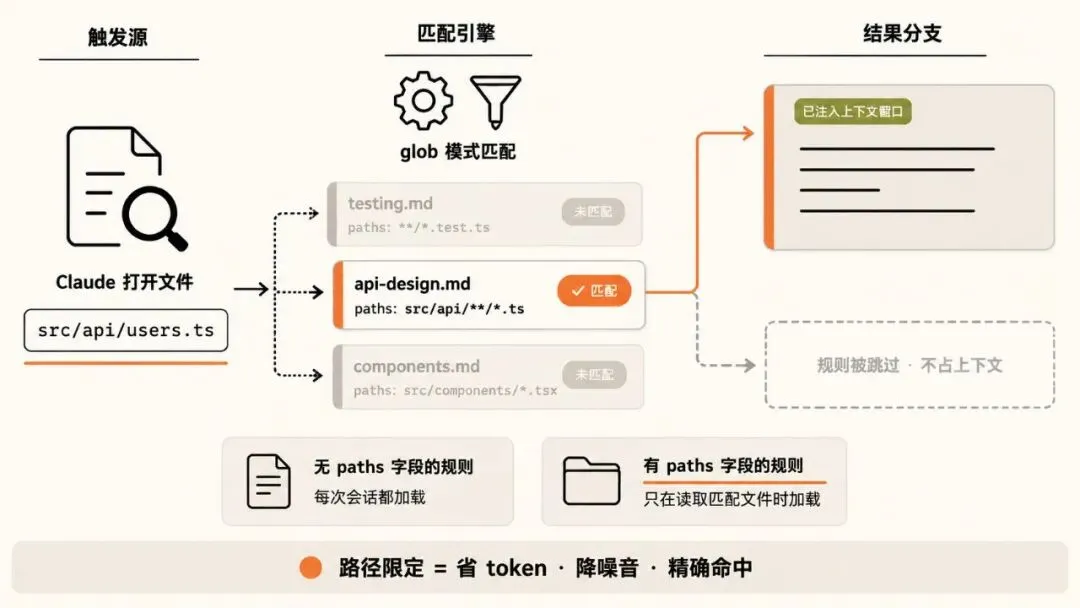
路径限定:什么时候读什么
路径限定规则在文件头上用 YAML 的 paths 字段指定触发条件:
---paths: - "src/api/**/*.ts"---# API 开发规范- 所有 API 端点必须有输入校验- 使用标准错误响应格式- 包含 OpenAPI 文档注释
 图注:路径限定规则在文件最前面用 YAML 里写 glob 匹配模式,告诉 Claude "只有处理这些文件的时候才读这份规则"。
图注:路径限定规则在文件最前面用 YAML 里写 glob 匹配模式,告诉 Claude "只有处理这些文件的时候才读这份规则"。
上面这条规则,只有 Claude 在处理 src/api/ 下的 TypeScript 文件时才会加载。你在改前端组件或者写文档的时候,这条规则,不占上下文、不会自行操作。
Glob 匹配模式举例:
| |
|---|
**/*.ts | |
src/**/* | src/ |
*.md | |
src/components/*.tsx | |
可以组合多个模式,也可以用花括号:"src/**/*.{ts,tsx}" 同时匹配 TS 和 TSX。
注意:放到 rules/ 目录里,不等于它就自动"按需加载"了。
你必须在文件头上写那个 paths 才能触发按需加载。没写 paths 的话,它跟 CLAUDE.md 一模一样 - 每次会话一上来就读完,白拆了。
还有一个容易误解的地方:paths 规则不是 "Claude 在干跟这些文件有关的事的时候" 加载,而是 Claude 真的打开了那个文件的时候才加载。差别在哪?
比如你写了一条规则匹配 *.test.ts:
- • 你以为:Claude 跑测试的时候会加载它 ← 不会。
- • 实际:你让 Claude 打开 user.test.ts 来改的时候,它才会加载这条规则。
也就是说,路径规则跟"任务类型"无关,只跟"读了哪个文件"有关。
用软链接共享规则
.claude/rules/ 支持软链接。你可以维护一套共享规则库,软链接到多个项目,不用复制粘贴:
ln -s ~/shared-claude-rules .claude/rules/sharedln -s ~/company-standards/security.md .claude/rules/security.md
循环链接会自动检测出来,不会出问题。
个人级规则
~/.claude/rules/ 里的规则,对你电脑上所有项目都生效。放那些不局限于单个项目的偏好 - 比如你习惯的 commit message 格式、想让 Claude 用哪种 Shell、一些跨仓库的约定。
个人级规则比项目规则先加载,所以项目规则优先级更高(后加载的覆盖先加载的)。
企业级:公司统一管
如果你在带团队推广 Claude Code,记忆系统里有一些给 IT 和 DevOps 用的控制手段。
公司级 CLAUDE.md 在加载顺序的最顶层。可以通过 MDM、Group Policy 或者 Ansible 这类工具统一部署,公司里每台电脑上的每次 Claude Code 会话都会读到。公司编码标准、安全策略、合规要求,就放这里。个人关不掉。
策略内容比较简单的话,可以直接写在 managed-settings.json 的 claudeMd 字段里,不用单独维护一个文件:
{ "claudeMd": "Always run `make lint` before committing.\nNever push directly to main."}
公司级 CLAUDE.md 和公司级 settings 的作用不一样,别搞混了。CLAUDE.md 塑造的是 Claude 的行为 - 代码风格、质量指南、合规提醒。Settings 强制的是技术约束 - 禁用某些工具、强制开沙箱、锁定认证方式。简单说:CLAUDE.md 告诉 Claude "你要做什么",settings 拦住 Claude "你不能做什么"。
自动记忆(Auto Memory):Claude 自己的日记本
自动记忆是记忆系统的另一半,工作方式跟 CLAUDE.md 完全不同。不是你写的,是 Claude 自己写的。
它在干活的时候会观察你的习惯:你老是敲哪个构建命令、怎么组织调试输出、偏好什么测试流程。觉得这件事值得记住,就自己存下来。
需要 Claude Code v2.1.59 以上版本,默认就开着。会话里敲 /memory 可以开关,项目设置里设 autoMemoryEnabled: false,或者设环境变量 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 关掉。
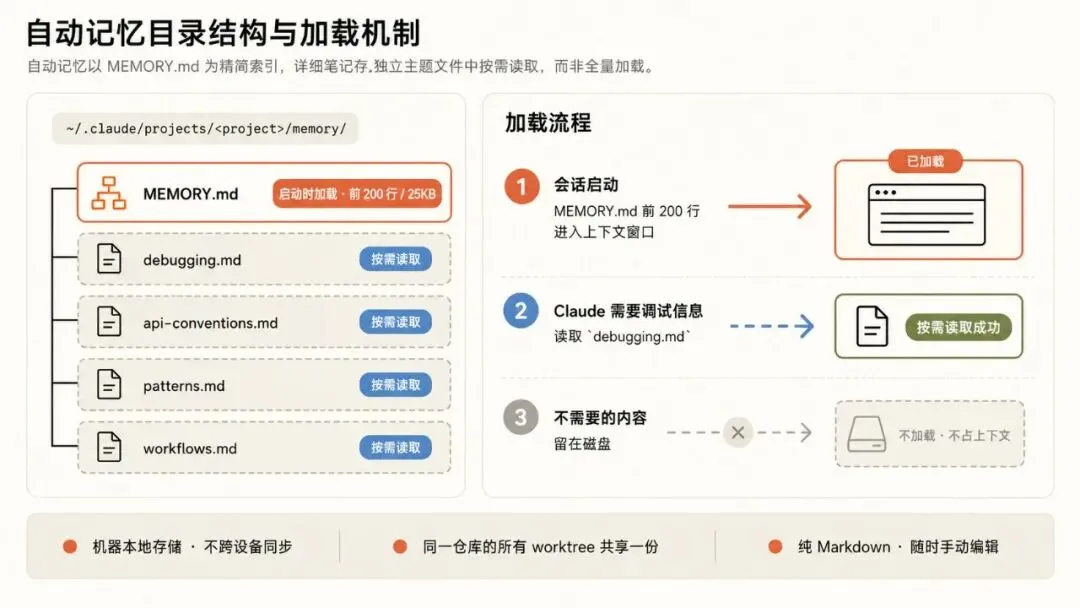 图注:自动记忆用 MEMORY.md 做目录索引,详细的笔记存到独立的主题文件里。Claude 不是一股脑全读,而是用到哪个才读哪个。
图注:自动记忆用 MEMORY.md 做目录索引,详细的笔记存到独立的主题文件里。Claude 不是一股脑全读,而是用到哪个才读哪个。
存在哪
每个项目有自己的记忆目录:
~/.claude/projects/<project>/memory/├── MEMORY.md # 目录索引,每次会话都读├── debugging.md # 调试相关的笔记├── api-conventions.md # API 设计的经验└── ... # Claude 自己创建的其他文件
<project> 这个路径是从 git 仓库名衍生出来的。同一个仓库的所有 worktree 和子目录,共用一份自动记忆。不在 git 仓库里的时候,用项目根目录。你可以用 autoMemoryDirectory 设置项换存储位置(必须是绝对路径或以 ~/ 开头)。
自动记忆是存在你本机上的,不会跨机器或云同步。每台电脑各自攒各自的记忆。
怎么读的
只有 MEMORY.md 在启动时加载,而且只加载前 200 行或 25KB,哪个先到算哪个。超出的部分不加载。这不是 bug,是故意的:Claude 会把详细笔记挪到单独的主题文件(debugging.md、patterns.md 之类的),保持 MEMORY.md 精简。
那些主题文件不在启动时加载。Claude 需要的时候才用标准文件工具去读。这种"用到再读"的办法可以节省上下文,需要的时候又不缺细节。
当你在 Claude Code 界面看到 "Writing memory" 或者 "Recalled memory" 的时候,就是 Claude 在读写记忆目录。全是纯 Markdown,你随时可以打开看、改、删。
子 Agent(Sub Agent) 也有记忆
Claude 派出去干活的子 agent - 就是那些处理并行任务或委派任务的专项 agent - 也可以有自己的自动记忆。一个经常搞数据库迁移的子 agent,可以慢慢攒出自己的一套模式和偏好,跟主会话的 Claude 独立。
/memory 命令:记忆控制台
/memory 是管理两套记忆系统的统一入口,能帮你做三件事:
- 1. 看看加载了哪些文件:当前会话里到底有哪些 CLAUDE.md、CLAUDE.local.md 和规则文件,列表一目了然。Claude 实际看到了什么,不用猜。
- 2. 开关自动记忆:给当前项目打开或关掉自动记忆。
- 3. 打开记忆文件夹:直接浏览和编辑自动记忆里的文件。
一个用法小贴士:你跟 Claude 说 "记住我们一直用 pnpm,不要用 npm" 或 "记住 API 测试需要本地 Redis",Claude 会存到自动记忆里。你要是想存到 CLAUDE.md 里,就得明确说:"把这个加到 CLAUDE.md。"
常见问题
Claude 不按我写的 CLAUDE.md 来做
先跑 /memory 看一眼,确认文件确实被加载了。如果列表里没有,那就是没加进去。常见原因是文件放在 Claude 遍历不到的位置,或者文件名写错了。
然后检查你写的是不是够具体。"代码风格要好" 这种模糊的话,确实很难照着做。再看看不同层级有没有冲突 - 个人级说用 A,项目级说用 B,Claude 可能就随便挑一个了。
最后,如果某个指令必须在特定时机执行(比如每次提交前、每次编辑文件后),那应该用 hook,不是写 CLAUDE.md 指令。Hook 是在固定事件点直接跑 Shell 命令的,不依赖 Claude 的 "自觉"。
"我不知道自动记忆里存了啥"
在 claude code 中运行 /memory 打开记忆文件夹。全是 Markdown 文件,随时可以看、可以改、可以删。没有任何你看不见的状态。
"CLAUDE.md 太大了"
用路径限定规则,只让相关的东西在需要的时候才加载。@路径 导入能帮你组织得好看一点,但它不省上下文 - 被导入的文件还是启动时就加载。
"/compact 之后有些指令不见了"
/compact 就是你跟 Claude 聊太久了,上下文快满了,它把前面的聊天压缩成一份摘要,然后重新开始腾出上下文空间继续干活。
问题出在"重新开始"这一步:
根目录的 ./CLAUDE.md:compact 之后 Claude 会主动去磁盘上重新读一遍,所以里面的规则马上恢复,不受影响。
子目录里的 CLAUDE.md(比如 src/api/CLAUDE.md):它是懒加载的 - 只有你让 Claude 去读那个子目录的文件时才会触发。compact 之后它不会主动重读,得等你下次再碰 src/api/ 的文件才回来。中间这段时间它不在。
只在聊天里口头说的东西:更惨,根本没存盘。compact 把聊天压成摘要了,口头交代就丢了。
所以 compact 之后发现 Claude 忘了什么规矩,要么是没写进文件,要么写在子目录的 CLAUDE.md 里还没触发。解决办法:重要的规则写进根目录的 CLAUDE.md。
一份合理的配置
看个实际例子最直接。
~/.claude/CLAUDE.md(个人的):
# 个人偏好- 包管理器用 pnpm,不用 npm- vitest 偏好参数:--reporter=verbose --no-color- 写 Python 用 uv 管包- SQL 关键字用小写
./CLAUDE.md(项目的,提交到 git):
@AGENTS.md# 构建与测试- 构建:pnpm build- 测试:pnpm test- Lint:pnpm lint- 类型检查:pnpm typecheck# 架构- API 路由:src/app/api/- 数据库查询:src/lib/db/- 共享组件:src/components/ui/# 规范- 用 2 格缩进- 优先服务端组件,必须时才加 "use client"- 错误响应按 RFC 7807 格式
./.claude/rules/testing.md(路径限定,只在处理测试文件时加载):
---paths: - "**/*.test.ts" - "**/*.spec.ts"---# 测试规范- 用 describe/it 块,不用 test()- 测试文件放源文件旁边,不单独放 tests/ 目录- 用 msw mock 外部 API,不用 vi.mock
./CLAUDE.local.md(加了 .gitignore):
# 我的本地配置- 开发服务器:http://localhost:3000- 测试数据库端口:5433- 测试认证:test@example.com / hunter2
这一套配下来,Claude 每次会话都知道:项目怎么构建、代码怎么组织、规范是什么、测试有什么要求,还有你个人的偏好。不用任何人重复解释。
记忆是上下文,不是强制令
关于 Claude Code 记忆,最重要的一句话:说到底它们都是上下文。你写的 CLAUDE.md 也好,Claude 自己攒的自动记忆也好,最后都以对话的形式塞进上下文窗口。Claude 读了、尽量照着来,但没有强制执行机制。
这是故意设计成这样的,有好处也有边界。好处是灵活 - 你可以用大白话写指令,Claude 自己判断什么时候适用。如果你不想要这种灵活,就是要绝对保证某件事一定发生或一定不发生,那就换别的工具:hooks、托管 settings、或者 --append-system-prompt。
CLAUDE.md 和自动记忆是为 "中间地带"(约定、模式、习惯照办最好,不照办也不至于出大事) 设计的。它们让 Claude 不再像第一天认识你的项目,而是像已经在这干了几个月的老同事。
How Claude remembers your project by Anthropic


