算电协同学习笔记(二):从任务分类看数据中心负荷特性
- 2026-05-13 11:42:17
如果所有算力都能搬到西部,那算电协同就简单了。问题在于,很多算力任务根本搬不走;而真正能调的那部分,可能又没有想象中那么大。
上一篇在算电协同学习笔记(一)中我们挖了一个坑:不是所有数据中心都适合搬到西部,也不是所有算力任务都是弹性的。上篇文章的评论区也有声音认为算电协同是个不可落地的宏观构想。
要想回答上面的问题,我们得研究一下算力中心的负荷特性。
这一篇尝试从算力任务分类入手,继续攒吹牛的墨水。
01 算力任务不是一种负荷
很多时候,我们会笼统地说“数据中心耗电”、“AI 算力很吃电”、“算力要跟着绿电走”。这些说法都对,但还不够精确。
因为数据中心里跑的不是一种任务,而是一堆性格完全不同的任务。
-有些任务像微信支付、汽车导航,必须马上响应。
-有些任务像双十一网购下单,用户一多就会瞬间冲高。
-有些任务比如AI大模型训练,一跑就是几天几周。
-还有些任务像数据备份、仿真实验,可以等到电价低谷、绿电大发时再慢慢跑。
所以,算电协同不能简单理解为“把数据中心搬到西部”,也不是单纯地“让数据中心跟着电价随开随停”。
真正的问题是:
什么任务必须靠近用户?什么任务可以放到西部?什么任务需要通过预测优化容量?什么任务可以通过电力交易和调度实现降本?
如果从电力系统视角看数据中心,很容易把它看成一个大负荷。
但如果从算力系统内部看,它其实是由很多不同任务叠加而成的。从阿里、谷歌公开的数据可以看到跑在数据中心的任务有几十、上百种。
我想从非IT专业的视角,或者干脆从电力人的视角出发,把这些任务从两个维度交叉分类。
一是时延敏感性:能不能等?
二是中断容忍度:能不能停?
两两组合,我们可以延伸为四个场景。
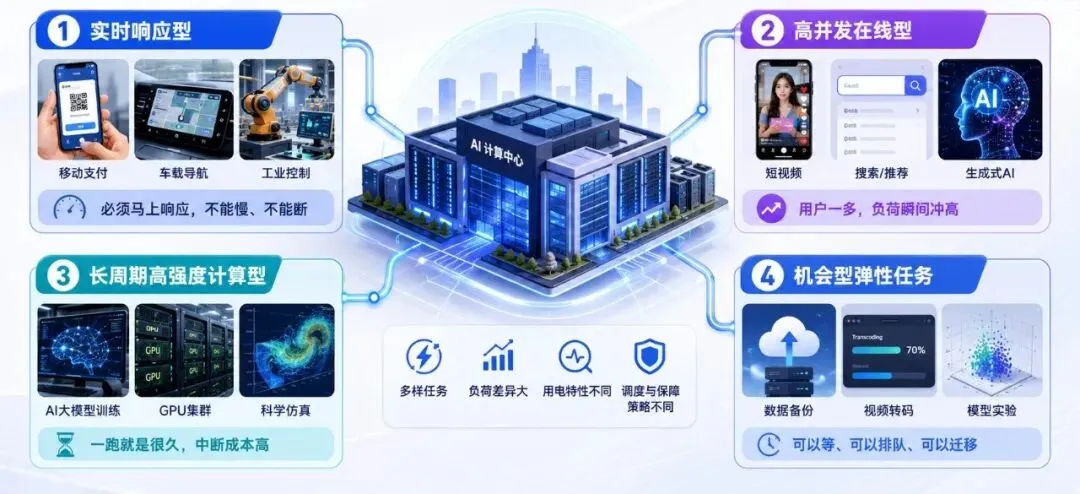
02 实时响应型在线任务:马上要答案
第一类是实时响应型在线任务。
比如金融交易、支付风控、汽车导航、网约车派单、工业控制、自动驾驶边缘计算等。
这类任务的特点是:用户或者设备正在等结果,时延敏感性非常高,中断容忍度非常低。
比如像我这种开车重度依赖导航的人,一旦车机导航反应慢,我能在西直门桥上玩一天;打王者的时候关键团战一个460ms延迟,大概率就是掉星加被队友举报;还有像扫码支付的时候,如果支付界面一直转圈会让人心态瞬间炸裂。
这些场景我们需要计算任务必须快速响应,不能慢、不能断、不能随便迁移。
所以它们必须靠近用户、交易所、工厂和业务现场。对这类任务来说,算电协同的核心不是“省电”,而是保供、低时延、高可靠。
这类任务不是拿来调节电网的,而是需要电力系统重点保障的数字基础设施。
03 高并发在线型任务:人一多就冲高
第二类是高并发在线型任务。
比如搜索、推荐、短视频、直播、在线广告、生成式AI等。
这类任务不一定像金融交易那样追求毫秒级响应,但它们高度依赖用户行为。用户什么时候集中访问,算力负荷就什么时候上来。
晚上刷短视频的人多,推荐系统就忙;电商促销季,搜索、推荐、广告、支付链路都会冲高;热点事件发生后,AI问答请求可能突然暴增。
这类负荷不是完全刚性,但也不能简单停掉。它更适合通过访问量预测、GPU利用率预测、排队时延预测来提前做容量优化。
近1年生成式AI需求井喷式爆发,我们研究了阿里开源的cluster-trace-GenAI数据包,里面提供了文生图、图生图等需求调用数据,在建立算力-时间-电力的映射关系后,我们得到了下面这个曲线。
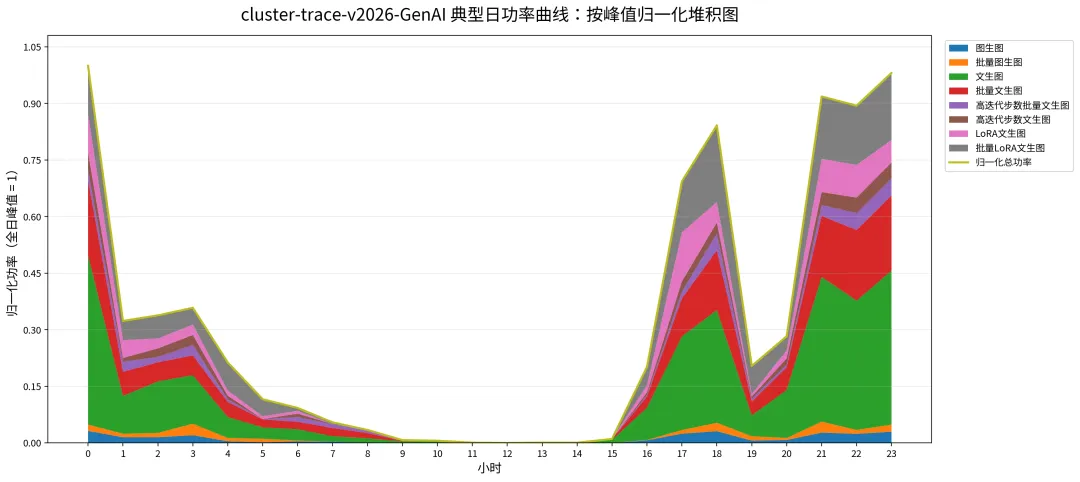
这类任务算是比较典型的高并发任务,本质上由“用户娱乐/创作行为驱动”。白天大家在工作、上课、开会,创作的需求少;晚上下班后,用户开始刷内容、做图、试prompt、调模型、改图片,算力需求就上来了
这类任务时延敏感性没有那么高,允许分钟级别的响应,也可以接受排队。但是从曲线形状上来看,和光伏的出力特性是正好相反的。
(需要注意的是,生成式 AI 推理内部也不是一种负荷。AI 聊天、简单文生图更接近在线服务,需要尽快响应;批量出图、高迭代步数生成、批量视频生成,则可以排队和错峰,具备一定柔性。)
04 长周期高强度计算任务:一跑就很久
第三类是长周期高强度计算任务。
比如大模型训练、自动驾驶模型训练、工业仿真、科学计算等。
这类任务的特点是:不一定要马上开始,但一旦开始,最好连续运行。因为训练任务中断虽然可以通过断点续训,但仍然会带来时间损失、资源浪费和调度成本。
有点类似炼钢,什么时候开火可以商量,一旦炉子烧起来了,突然断火就很麻烦。
从电力系统看,这类任务往往形成高功率、长持续的算力基荷。它们非常适合与西部新能源、电力交易、绿电直连结合。
我们对阿里开源的cluster-trace-gpu-v2020的数据包做了统计,数据来自阿里巴巴人工智能平台的一个大型生产集群,该集群拥有超过6500个GPU(分布在约1800台机器上)。
做典型日归一化处理后,发现长周期GPU训练任务(持续时间中位数271小时)占据了大量的算力需求,可以将其理解为数据中心的“基荷”。
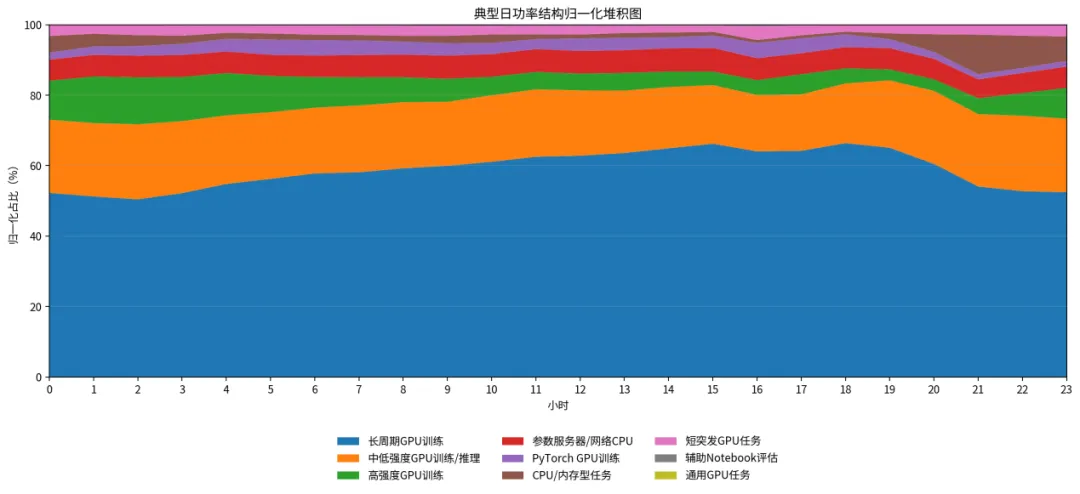
这类任务不适合频繁响应电价或电网调度,但可以做提前排程、绿电合约匹配。
数据中心选址优化、跨区域算力迁移。
05 机会型弹性任务:有空再算、便宜时多算
第四类是机会型弹性任务。
比如数据备份、离线报表、视频转码、模型实验、参数搜索、低优先级训练、批量后台生成等。
这类任务的特点是:可以等、可以排队、可以中断、可以迁移。
就像电动汽车停楼下充电,不一定非要现在充,可以等到夜间电价便宜或者新能源大发的时候再充。
这类任务就是算电协同里(从电网视角看)最有价值的柔性负荷。
不过根据阿里公布的cluster-trace-v2026-spot-gpu数据集,机会型弹性任务的占比无论是任务数量还是占用的GPU时长都很小。

虽然这些数据集不是所有数据中心全貌,不过也侧面说明了一个问题:算电协同不能指望调动整个数据中心负荷,真正能调的是边际柔性负荷,比例可能不高,但只要规模足够大、调度机制足够成熟,仍然可以形成有价值的需求响应资源池。
06 总结
用一张表概括上面四类算力任务场景:
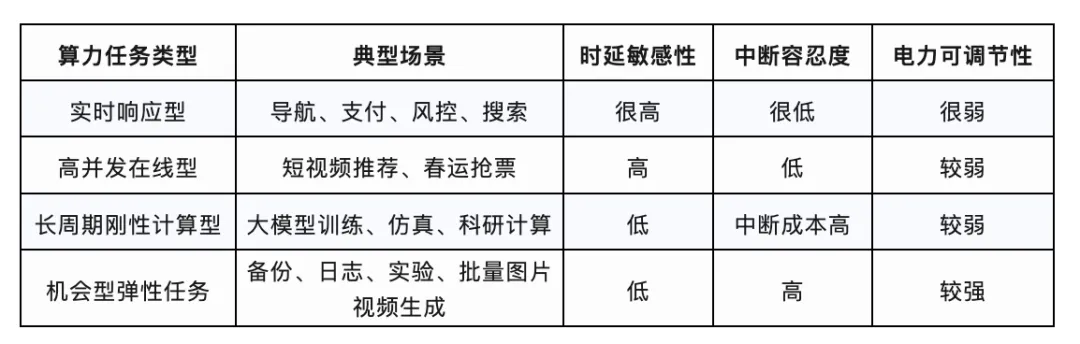
到这我们可以尝试回答开篇的问题了。
算力任务的时延要求、优先级、中断容忍度和迁移能力,决定了它应该在哪里算、什么时候算、用什么电、如何参与市场。
所以,东数西算不是“所有数据都往西搬”,而是“实时任务靠近用户,训练任务靠近绿电,在线任务依靠预测,弹性任务跟随电价。”
算电协同像是情侣谈恋爱,是一个相互看见、相互磨合、甚至相互妥协的过程。一旦一方只提要求不提付出,协同大概率不会有理想的结果。
对于电网和算力中心来说,现阶段可能是“一个协同、各自表述”的时期,电不了解算、算也不了解电。
所以,我理解算电协同真正要改变的,不只是数据中心的供电方式,而是算力产业的运行方式。如何让电力系统看得见算力任务,如何让算力系统看得见电价、绿电和电网约束,才是算电协同从概念走向工程落地的关键。
以上粗浅认知还请专业人士批判。

