有限马尔可夫决策过程 Finite Markov Decision Processes(有限 MDP)- MDP 兼具评估式反馈(同老虎机问题)与关联决策(不同状态下选择不同动作)两大特性。
- 动作不仅影响即时奖励,还会改变后续状态与未来奖励,存在奖励延迟,需要权衡即时回报与长期回报。
- MDP 是强化学习的数学理想化模型,可精确定理推导;引入回报、价值函数、贝尔曼方程等核心要素。
智能体 - 环境交互框架(Agent–Environment Interface)
1. 基本定义
- 智能体 Agent:学习者、决策者。
- 环境 Environment:智能体以外所有事物,与智能体持续交互。
- 交互逻辑:智能体选动作 → 环境响应、更新状态、给出奖励 Reward(智能体长期最大化的数值信号)。
2. 时序交互轨迹
5. 马尔可夫性质 Markov Property
当前状态已包含所有历史交互信息,未来仅依赖当前状态与动作,与更早历史无关。全书默认满足马尔可夫性质;后续会学习不依赖该性质的近似方法、非马尔可夫观测构建马尔可夫状态。
6. MDP 框架的抽象灵活性
- 时间步:不局限真实固定时间间隔,可指代任意决策阶段。
- 动作层级:低层控制(机器人电机电压)/ 高层决策(是否升学、就餐)。
- 状态形式:底层传感器数据 / 高层抽象符号 / 记忆、主观心理状态。
7. 智能体与环境边界划分规则
- 边界≠物理躯体边界:机器人电机、传感硬件、生物肌肉感官都归环境;奖励虽在系统内部计算,但视为外部信号。
- 边界可按需划定、分层设定;一旦确定状态 / 动作 / 奖励,决策任务与边界即固定。
8. 典型案例
生物反应器状态:热电偶传感读数、原料与目标化学品符号输入;动作:目标温度、搅拌速率;奖励:有用化学品实时产出速率。
分拣机器人动作:关节电机电压;状态:关节角度、速度;奖励:成功拾取放置 + 1,运动抖动施加负奖励。
回收机器人状态:电池电量高 / 低;动作:搜索、等待、回充(低电量可用);奖励:捡到易拉罐正向奖励、电量耗尽大额负奖励;构成典型有限 MDP 转移与回报模型。
回报与回合 Returns and EpisodesDynamic Programming 动态规划
4. 随机策略扩展
多动作同时最优时,可给所有最优动作分配概率,次优动作概率为 0,仍满足策略改进。
LESSON 1 - 马尔可夫决策过程(MDP)与强化学习基础Bull → BuyBear → SellCrash → Sell
Asynchronous Dynamic Programming 异步动态规划Generalized Policy Iteration 广义策略迭代 GPIEfficiency of Dynamic Programming 动态规划的效率
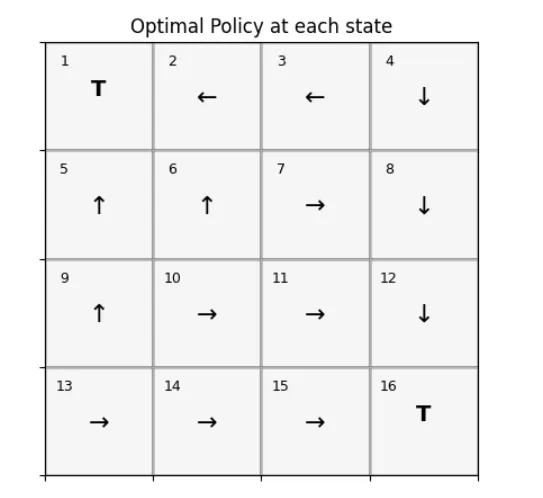
LESSON 2- 强化学习:网格世界
本节课基于4×4 网格世界环境,实现了强化学习中最经典的策略迭代算法(策略评估 + 策略提升),求解最优策略;并拓展了随机风场网格世界,理解环境随机性对最优策略的影响。核心工具:贝尔曼方程、马尔可夫决策过程(MDP)、确定性 / 迭代策略评估、策略提升。
一、基础网格世界(确定性环境)
LESSON 3-强化学习用于资产配置:投资组合轮动本节课将强化学习(马尔可夫决策过程MDP、策略迭代)应用于真实金融市场,构建资产配置组合轮动策略。
核心目标:改进传统60/40固配组合,利用市场状态切换股债权重,实现更高风险调整收益。
1. 资产与基准策略:60/40组合
1.1 三类交易资产(ETF)
SPY:标普500 ETF(美股大盘权益资产)
IEF:7-10年期美债ETF(中长期债券)
SHY:1-3年期短债(现金替代,本章节未使用)
数据区间:2004年1月 — 2025年10月,使用月度收益率。
1.2 经典基准:60/40投资组合
1.3 资产表现对比
股票(SPY):年化收益最高、波动率最大
债券(IEF):收益最低、波动最小
60/40组合:收益介于两者之间,夏普比率最优(风险调整收益最好)
1.4 传统策略痛点
60/40权重固定,无法根据市场行情切换配置;不会择时、不会轮动。本课用RL解决:在不同市场状态下动态调整股债比例。
2. 金融MDP建模(RL环境搭建)
沿用前面网格世界的MDP框架:状态、动作、奖励、转移概率,全部从真实历史数据中统计得到。
2.1 状态 States(共12种市场状态)
由三个市场指标组合生成:
股票动量:过去6个月收益(正/负)
债券动量:过去6个月收益(正/负)
波动区间:12个月滚动波动率(低/中/高)
组合:2 × 2 × 3 = 12个离散状态
2.2 动作 Actions(5种资产配置)
智能体选择股债权重:
100% 股票 (1.0, 0.0)
75% 股票 + 25% 债券
50% 股票 + 50% 债券
25% 股票 + 75% 债券
100% 债券 (0.0, 1.0)
4. 回测结果(测试集 2017—2025)
4.1 对比标的
RL最优策略 VS 传统60/40固定权重组合
4.2 关键结论
RL策略累计收益显著高于60/40
波动率更低,回撤更小
夏普比率大幅优于传统组合
即使扣除交易成本,RL轮动策略依旧稳健超额
本节课总结
5.1 知识点串联
将网格世界MDP框架完全迁移到金融资产配置
状态:市场行情(动量+波动);动作:股债配置权重
奖励:月度收益率;转移:市场状态切换概率
5.2 RL相比传统投资的优势
不主观判断行情,纯数据驱动
根据市场12种状态动态调仓
自动规避高波动、弱势行情
比固定60/40组合更灵活、收益更高、风险更低
5.3 局限性
依赖历史数据,存在数据拟合偏差
市场极端黑天鹅事件无法识别
状态数量有限,对复杂市场刻画不足
Q-learning: 离策略TD控制
Q-learning是经典的离策略(Off-policy)TD控制算法,核心目标是让学习到的动作价值函数Q直接逼近最优动作价值函数q₊,且不依赖于当前遵循的策略(即行为策略与目标策略分离)。
为什么Q-learning是离策略控制方法?
因为Q-learning的行为策略与目标策略相互独立:
行为策略:用于选择动作、生成经验(如ε-贪婪策略),目的是探索环境。
目标策略:始终是基于当前Q值的贪婪策略(取max Q(S',a)),是算法最终要学习的最优策略。
更新Q值时,不依赖行为策略的选择,而是直接采用最优动作的Q值作为目标,因此属于离策略。
若动作选择为贪婪策略(ε=0),Q-learning与Sarsa是否完全相同?
不完全相同,动作选择和权重更新可能存在差异:
核心总结
Q-learning核心:离策略TD控制,直接逼近q₊,更新时取下一状态的最优Q值,与当前行为策略无关。
关键区别(与Sarsa):Q-learning“不管当前策略,只学最优”,探索时风险高;Sarsa“跟着当前策略学,更保守”。
收敛条件:充分探索(所有(s,a)无限次更新)+ 合理步长。
LESSON 4 - 强化学习在资产配置中的应用:Q 学习五、实证结果与原因分析
- 测试集上 Q-learning 与经典 60/40 策略表现接近;
- 训练 / 验证 / 测试窗口划分不能完全代表未来市场状态;
六、结论
- 成功实现基于 Q-learning 的资产轮动算法;
- Q-learning 与策略迭代表现有差异,模型未充分调优,仍有改进空间;
- 后续课程引入网络理论 (Network theory) ,拓展投资组合与交易的复杂计算方法。
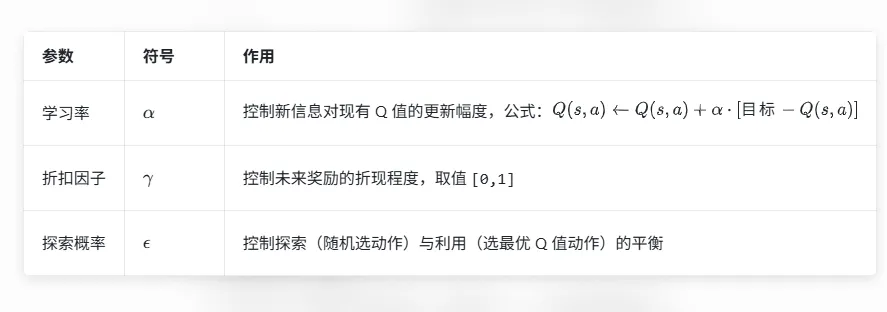
三、算法核心:Q-learning 基础
1. 核心参数与作用