定时器在 RPC 框架中无处不在:超时控制、重试定时、心跳检测。bthread 的定时器是如何实现的?与前面拆解的同步原语(基于 butex)不同,定时器线程使用了一种完全不同的设计——分桶(Bucket)、最小堆(Min-Heap)、ResourcePool 和 futex 的组合。一、TimerThread:单线程的定时器引擎
TimerThread 的设计理念很简洁:一个独立的 pthread,在指定时间执行回调函数。
┌───────────────────────────┐ Thread A ──────────>│ Bucket[0] ───┐ │ Thread B ──────────>│ Bucket[1] ───┤ │ Thread C ──────────>│ Bucket[2] ───┼── TimerThread (pthread) ... │ ... │ │ │ Thread N ──────────>│ Bucket[12] ──┘ │ │ └────────────────────┼──────┘ │ run() 主循环: 1. 从桶中拉取任务 2. 最小堆排序 3. 执行到期任务 4. futex 等待
关键约束:任意时刻最多只有一个任务在运行。不要在回调中放入耗时操作,否则会显著延迟其他任务。
二、数据结构
2.1 TimerThread
class TimerThread { bool _started; // 是否已启动 butil::atomic<bool> _stop; // 停止标志 TimerThreadOptions _options; // 配置(桶数量等) Bucket* _buckets; // 桶数组 FastPthreadMutex _mutex; // 保护 _nearest_run_time int64_t _nearest_run_time; // 所有桶中最近的执行时间 int _nsignals; // futex 唤醒信号 pthread_t _thread; // 定时器 pthread};
七个字段,各司其职:
_buckets:桶数组,调度请求按线程 ID 哈希分散到不同桶中,减少锁竞争:桶数组,调度请求按线程 ID 哈希分散到不同桶中,减少锁竞争_nearest_run_time+ _mutex:全局最近执行时间,由 _mutex 保护。新任务更早时更新并唤醒 timer 线程_nsignals:futex 变量,用于唤醒 timer 线程。不能直接用 _nearest_run_time——它是 64 位,futex 只支持 32 位
2.2 Bucket
classBAIDU_CACHELINE_ALIGNMENTTimerThread::Bucket{ FastPthreadMutex _mutex; // 保护本桶 int64_t _nearest_run_time; // 本桶最近执行时间 Task* _task_head; // 任务链表头};
缓存行对齐(BAIDU_CACHELINE_ALIGNMENT),避免不同桶之间的伪共享。每个桶有独立的互斥锁——多线程调度时只竞争自己的桶,不竞争全局锁。
2.3 Task
struct BAIDU_CACHELINE_ALIGNMENT TimerThread::Task { Task* next; // 链表指针 int64_t run_time; // 绝对执行时间(微秒) void (*fn)(void*); // 回调函数 void* arg; // 回调参数 TaskId task_id; // 任务 ID butil::atomic<uint32_t> version; // 版本号(状态机)};
Task 从 ResourcePool 分配(参见本系列第三篇),通过 task_id 索引。version 字段是理解任务生命周期的关键——下面会详细分析。
2.4 TaskId 的编码
typedef uint64_t TaskId;// 高 32 位:version// 低 32 位:ResourcePool slot
inline TaskId make_task_id(ResourceId<Task> slot, uint32_t version){ return (uint64_t)version << 32 | slot.value;}inline ResourceId<Task> slot_of_task_id(TaskId id){ return { id & 0xFFFFFFFF };}inlineuint32_tversion_of_task_id(TaskId id){ return (uint32_t)(id >> 32);}
这种编码使得通过 TaskId 可以 O(1) 定位 Task 对象(通过 ResourcePool 的 address_resource),同时通过 version 判断任务是否已被取消或执行完毕。
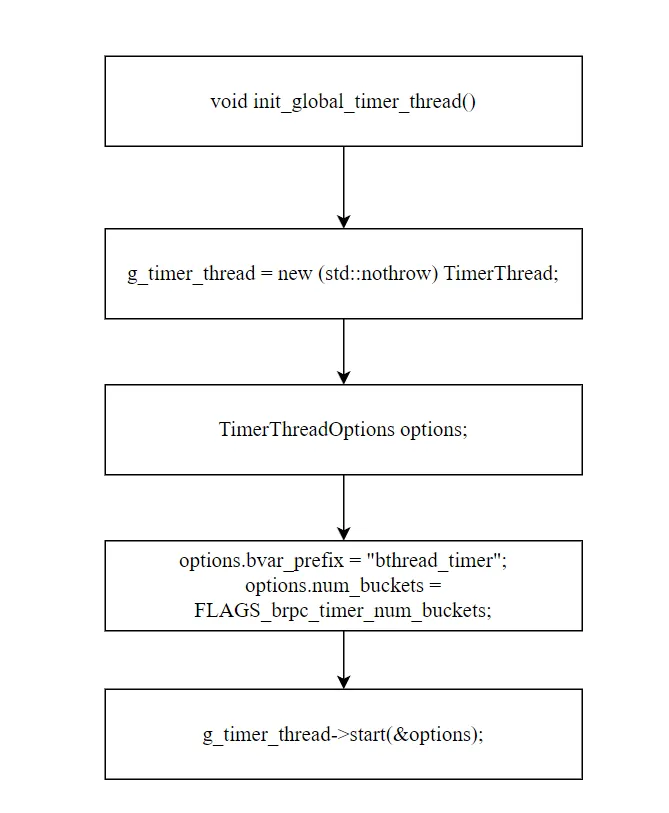
三、全局单例的创建
static pthread_once_t g_timer_thread_once = PTHREAD_ONCE_INIT;static TimerThread* g_timer_thread = NULL;TimerThread* get_or_create_global_timer_thread(){ pthread_once(&g_timer_thread_once, init_global_timer_thread); return g_timer_thread;}
通过 pthread_once 保证全局只初始化一次。init_global_timer_thread 的流程:
- 构建 TimerThreadOptions,桶数量来自 GFlags(默认 13),bvar 前缀为
"bthread_timer"
进程生命周期内永不退出。
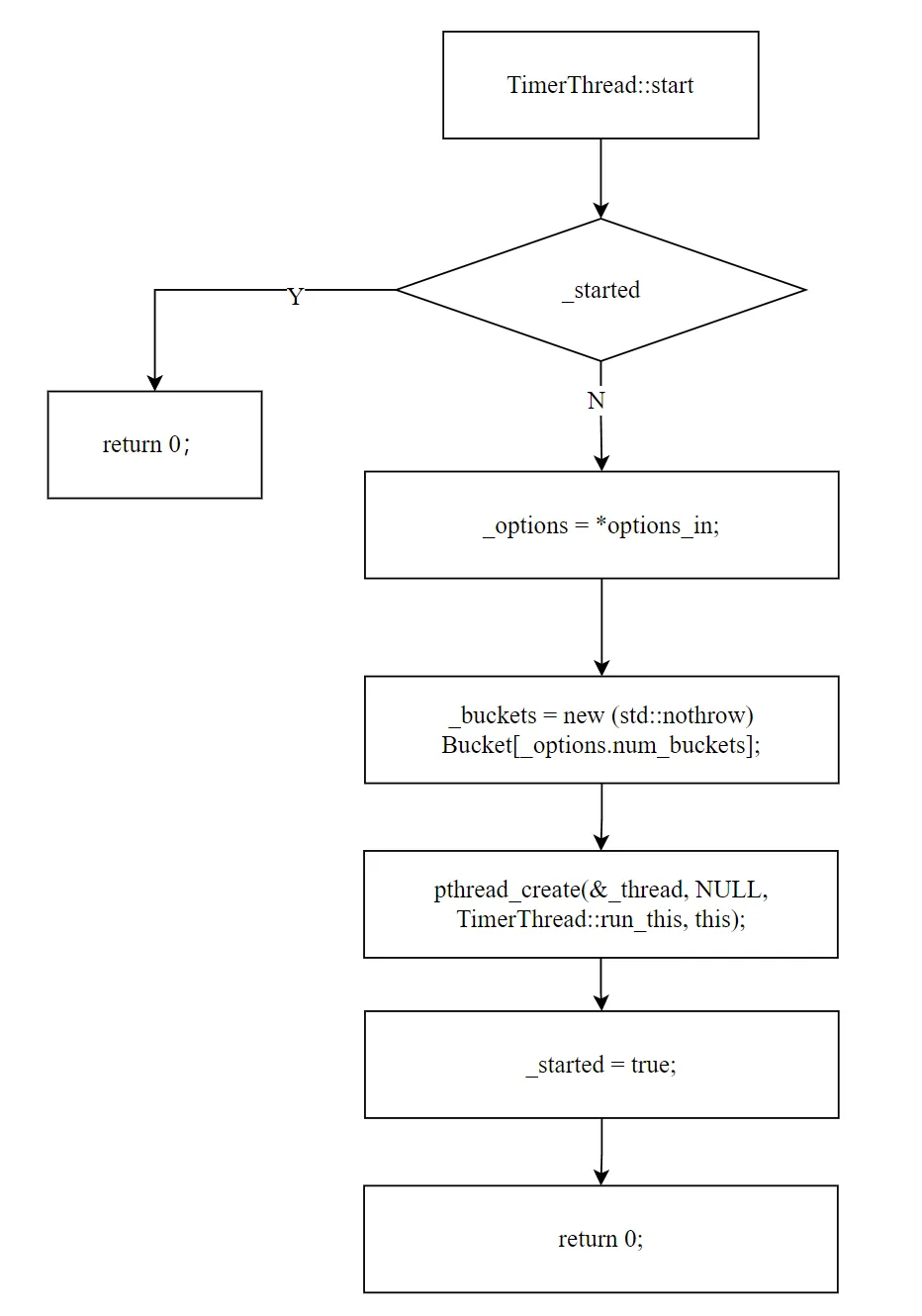
四、start:启动定时器线程
intTimerThread::start(const TimerThreadOptions* options_in){ if (_started) return 0; // 已启动 _options = *options_in; if (_options.num_buckets == 0 || _options.num_buckets > 1024) { // 校验桶数量 return EINVAL; } _buckets = new Bucket[_options.num_buckets]; // 创建桶数组 pthread_create(&_thread, NULL, run_this, this); // 创建 pthread _started = true; return 0;}
启动过程简洁:创建桶数组 → 创建 pthread → 设置已启动标志。pthread 入口函数 run_this 设置线程名为 "brpc_timer"(便于调试),然后调用 run() 进入主循环。
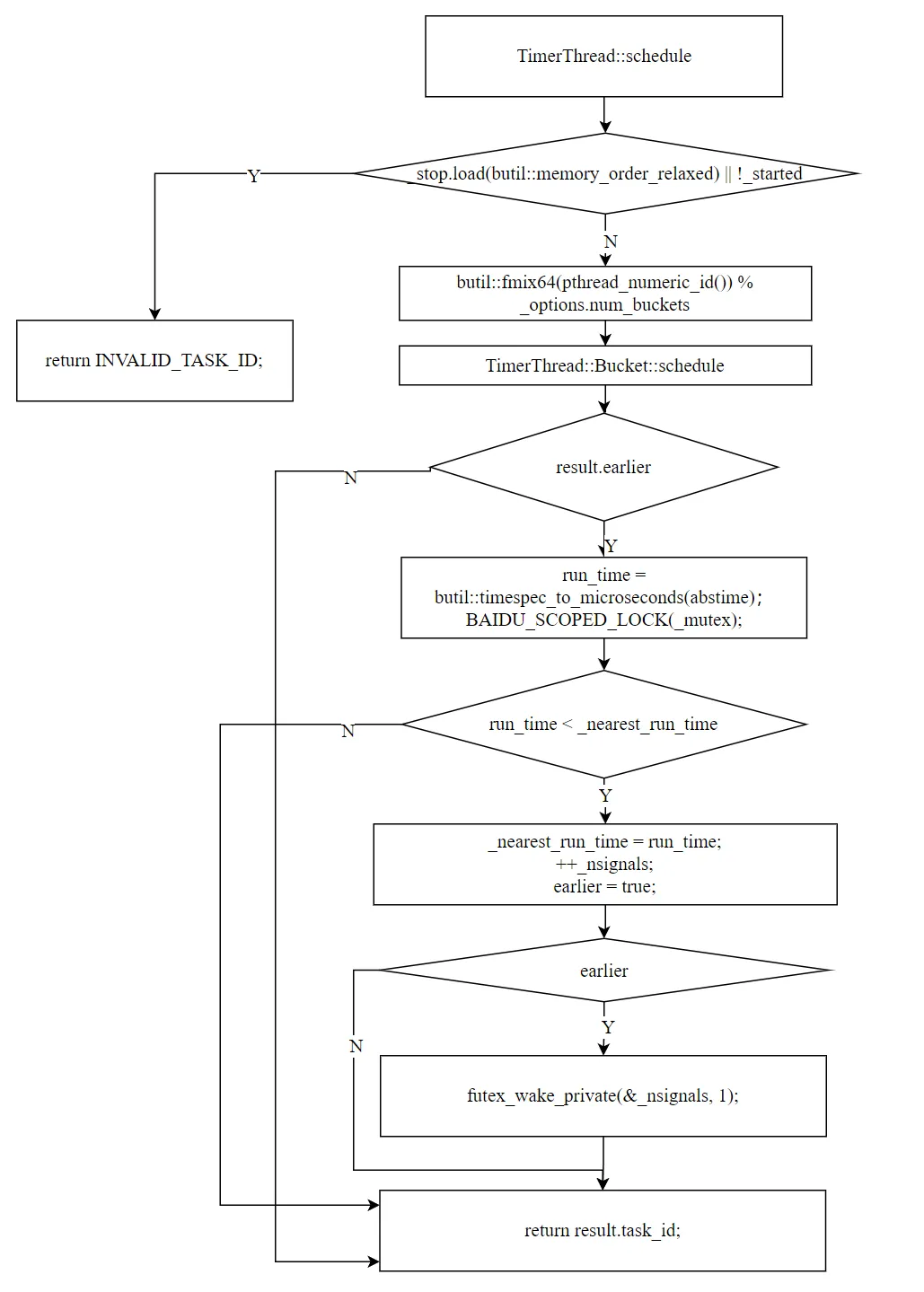
五、schedule:调度定时任务
调度分两层:先调度到桶(Bucket::schedule),再由 TimerThread 决定是否唤醒。
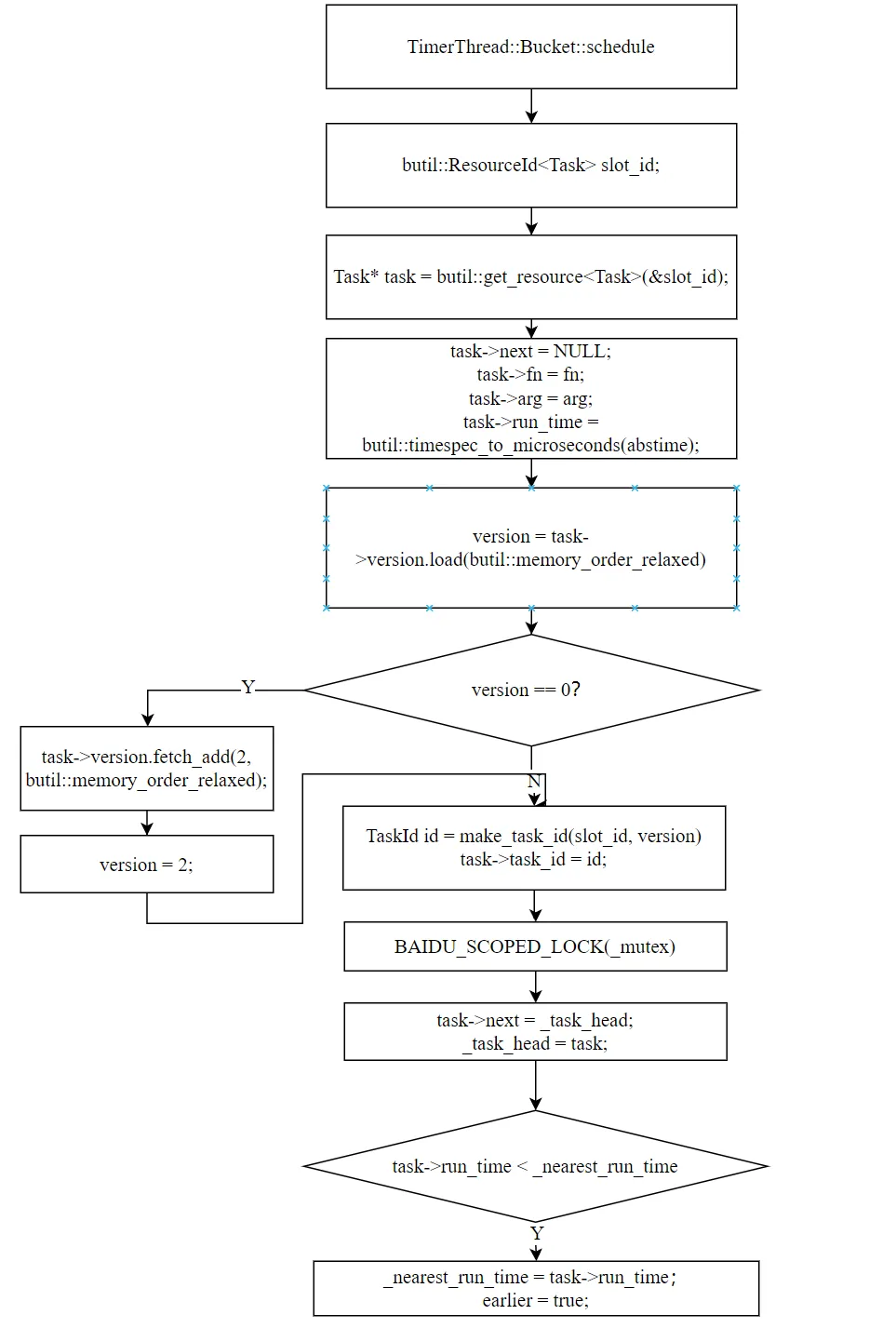
5.1 Bucket::schedule:调度到桶
Bucket::ScheduleResult Bucket::schedule( void(*fn)(void*), void* arg, const timespec& abstime) { // 1. 从 ResourcePool 分配 Task butil::ResourceId<Task> slot_id; Task* task = butil::get_resource<Task>(&slot_id); // 2. 设置 Task 字段 task->fn = fn; task->arg = arg; task->run_time = butil::timespec_to_microseconds(abstime); // 3. 处理 version(跳过 0) uint32_t version = task->version.load(memory_order_relaxed); if(version == 0) { task->version.fetch_add(2, memory_order_relaxed); version = 2; } const TaskId id = make_task_id(slot_id, version); task->task_id = id; // 4. 插入桶的链表头部 bool earlier = false; { BAIDU_SCOPED_LOCK(_mutex); task->next = _task_head; _task_head = task; if(task->run_time < _nearest_run_time) { _nearest_run_time = task->run_time; earlier = true; // 这个任务是本桶最早的 } } return { id, earlier };}
四个步骤:
- 分配 Task:从 ResourcePool 获取(参见本系列第三篇),O(1) 操作
- 设置字段:回调函数、参数、执行时间
- 处理 version:
version 初始值为 2(跳过 0,因为 0 用于 ResourcePool 的"未使用"标记)。如果是复用的 Task,version 可能已经是 id_version + 2(上一个任务的结束版本号),直接使用即可 - 插入链表:头插法,O(1)。如果这个任务是本桶最早的,标记
earlier = true
5.2 TimerThread::schedule:外部接口
TaskId TimerThread::schedule( void (*fn)(void*), void* arg, const timespec& abstime) { if (_stop || !_started) return INVALID_TASK_ID; // 1. 按线程 ID 哈希选择桶 const Bucket::ScheduleResult result = _buckets[fmix64(pthread_numeric_id()) % num_buckets] .schedule(fn, arg, abstime); // 2. 如果是本桶最早的任务,检查是否需要唤醒 timer 线程 if (result.earlier) { int64_t run_time = butil::timespec_to_microseconds(abstime); bool earlier = false; { BAIDU_SCOPED_LOCK(_mutex); if (run_time < _nearest_run_time) { _nearest_run_time = run_time; ++_nsignals; earlier = true; } } if (earlier) { futex_wake_private(&_nsignals, 1); } } return result.task_id;}
两步判断:
- 按线程哈希选桶:
fmix64(pthread_numeric_id()) % num_buckets。同一 pthread 的任务进入同一桶,利用缓存局部性 - 条件唤醒:只有当新任务是本桶最早(
result.earlier)且比全局最早(_nearest_run_time)更早时,才唤醒 timer 线程
这个设计很巧妙:大多数 RPC 场景中,任务的 run_time 递增(超时时间越来越晚),所以大多数任务不是"最早的",不会触发全局锁竞争。
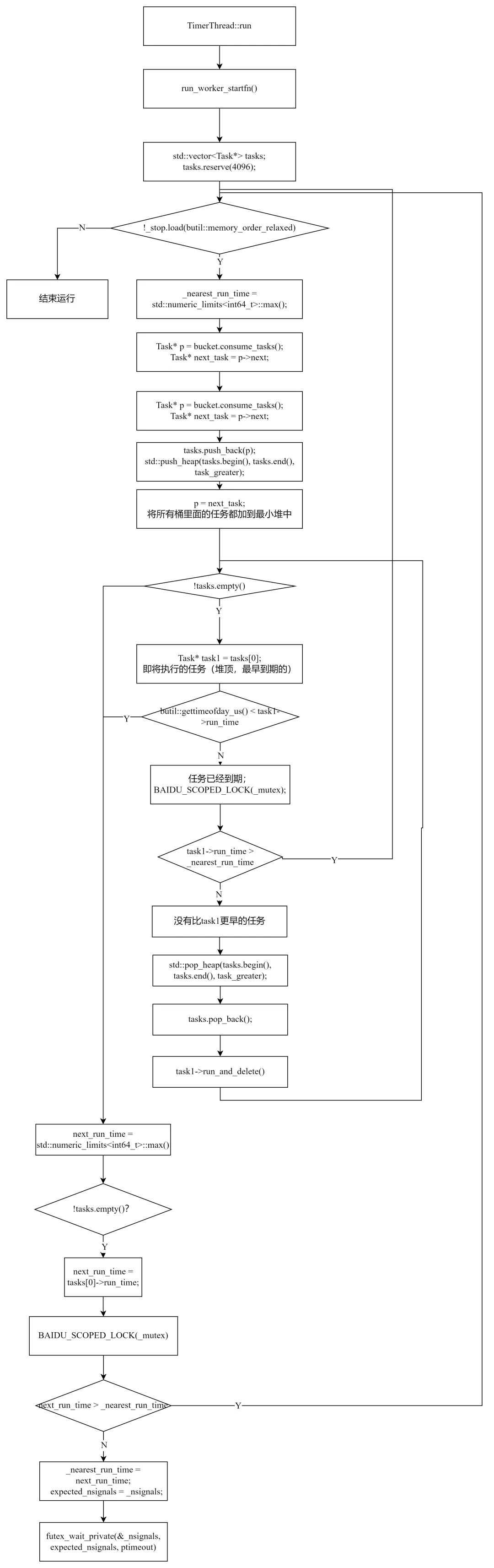
六、run:主循环(核心)
TimerThread::run() 是定时器线程的主循环,也是最复杂的部分。
6.1 整体结构
voidTimerThread::run(){ std::vector<Task*> tasks; tasks.reserve(4096); // 预分配,避免频繁扩容 while (!_stop) { // 1. 清空全局最近时间 // 2. 从桶中拉取任务到最小堆 // 3. 执行到期任务 // 4. 计算等待时间并 futex 睡眠 }}
6.2 第一步:清空全局最近时间
{ BAIDU_SCOPED_LOCK(_mutex); if (_stop) break; _nearest_run_time = INT64_MAX;}
在拉取桶中任务之前,将 _nearest_run_time 设为无穷大。这样,在拉取过程中如果有新任务到来(更早),schedule 会更新 _nearest_run_time,我们就能感知到。
6.3 第二步:从桶中拉取任务
for (size_t i = 0; i < num_buckets; ++i) { for (Task* p = bucket.consume_tasks(); p != nullptr; ...) { Task* next_task = p->next; if (!p->try_delete()) { // 跳过已取消的任务 tasks.push_back(p); std::push_heap(tasks.begin(), tasks.end(), task_greater); } p = next_task; }}
consume_tasks() 原子地摘取桶的整个链表(加锁 → 摘链表 → 清空桶)。对每个任务:
try_delete()检查是否已被 unschedule 取消。如果已取消,归还 ResourcePool- 未取消的任务加入最小堆(按
run_time 排序,堆顶是最早的任务)
6.4 第三步:执行到期任务
bool pull_again = false;while (!tasks.empty()) { Task* task1 = tasks[0]; // 堆顶 = 最早的任务 if (gettimeofday_us() < task1->run_time) break; // 未到期,跳出 // 检查是否有更早的任务被调度 { BAIDU_SCOPED_LOCK(_mutex); if (task1->run_time > _nearest_run_time) { pull_again = true; // 有更早的任务,重新拉取 break; } } std::pop_heap(tasks.begin(), tasks.end(), task_greater); tasks.pop_back(); task1->run_and_delete(); // 执行并删除}if (pull_again) continue; // 重新拉取桶
执行到期任务前,再次检查 _nearest_run_time:如果在我们拉取桶的过程中有更早的任务到来(task1->run_time > _nearest_run_time),需要重新拉取。这是一个乐观检查——大多数情况下不需要重新拉取。
为什么会出现 task1->run_time > _nearest_run_time?因为 consume_tasks 和 schedule 是并发的。timer 线程在拉取桶 A 时,线程 X 可能正好向桶 A 调度了一个更早的任务——此时 _nearest_run_time 被更新,但 timer 线程已经拉过了桶 A。所以需要在执行前再次检查。
6.5 第四步:计算等待时间并睡眠
int64_t next_run_time = INT64_MAX;if (!tasks.empty()) { next_run_time = tasks[0]->run_time; // 堆顶 = 下次执行时间}int expected_nsignals;{ BAIDU_SCOPED_LOCK(_mutex); if (next_run_time > _nearest_run_time) { continue; // 有更早的任务,重新拉取 } _nearest_run_time = next_run_time; expected_nsignals = _nsignals;}// 计算超时时间timespec* ptimeout = NULL;if (next_run_time != INT64_MAX) { ptimeout = microseconds_to_timespec(next_run_time - gettimeofday_us());}futex_wait_private(&_nsignals, expected_nsignals, ptimeout);
睡眠前有三次检查确保不漏任务:
- 如果堆顶任务的
run_time 比 _nearest_run_time 大,说明有更早的任务到了,重新拉取 - 记录
_nsignals 到 expected_nsignals——这是关键的防丢失机制 futex_wait_private比较当前 _nsignals 与 expected_nsignals。如果在拉取桶和睡眠之间有新任务到来,schedule 已经 ++_nsignals,值不匹配,futex_wait_private 立即返回
_nsignals 解决了一个问题:不能用 _nearest_run_time 做 futex(它是 64 位),所以用单独的 32 位计数器。每次有更早任务时递增,timer 线程睡眠前记录期望值,醒来后检查是否一致。
6.6 完整流程图
run() 主循环┌────────────────────────────────────────────────────────┐│ while (!_stop) { ││ 1. _nearest_run_time = INT64_MAX ││ 2. 遍历所有桶 → consume_tasks → 最小堆 ││ 3. while (堆顶任务到期) { ││ 检查 _nearest_run_time → 有更早? pull_again ││ pop_heap → run_and_delete ││ } ││ 4. next_run_time = 堆顶.run_time / INT64_MAX ││ 检查 _nearest_run_time → 有更早? continue ││ expected_nsignals = _nsignals ││ futex_wait(_nsignals, expected, timeout) ││ } │└────────────────────────────────────────────────────────┘
七、Task 的 version 状态机
Task 的 version 字段管理任务的三种状态:
schedule() run_and_delete()id_version ──────────> id_version+1 ──────────> id_version+2 (未运行) (运行中) (已移除) │ ▲ │ unschedule() │ └──────────────────────────────────────────────┘ (取消)
三个操作通过原子操作改变 version:
run_and_delete(执行任务):
boolTask::run_and_delete(){ const uint32_t id_version = version_of_task_id(task_id); uint32_t expected = id_version; // CAS: id_version → id_version+1(执行中) if (version.compare_exchange_strong(expected, id_version + 1, memory_order_relaxed)) { fn(arg); // 执行回调 version.store(id_version + 2, memory_order_release); // 标记完成 return_resource(slot_of_task_id(task_id)); // 归还 ResourcePool return true; } else if (expected == id_version + 2) { // 已被 unschedule 取消 return_resource(slot_of_task_id(task_id)); return false; }}
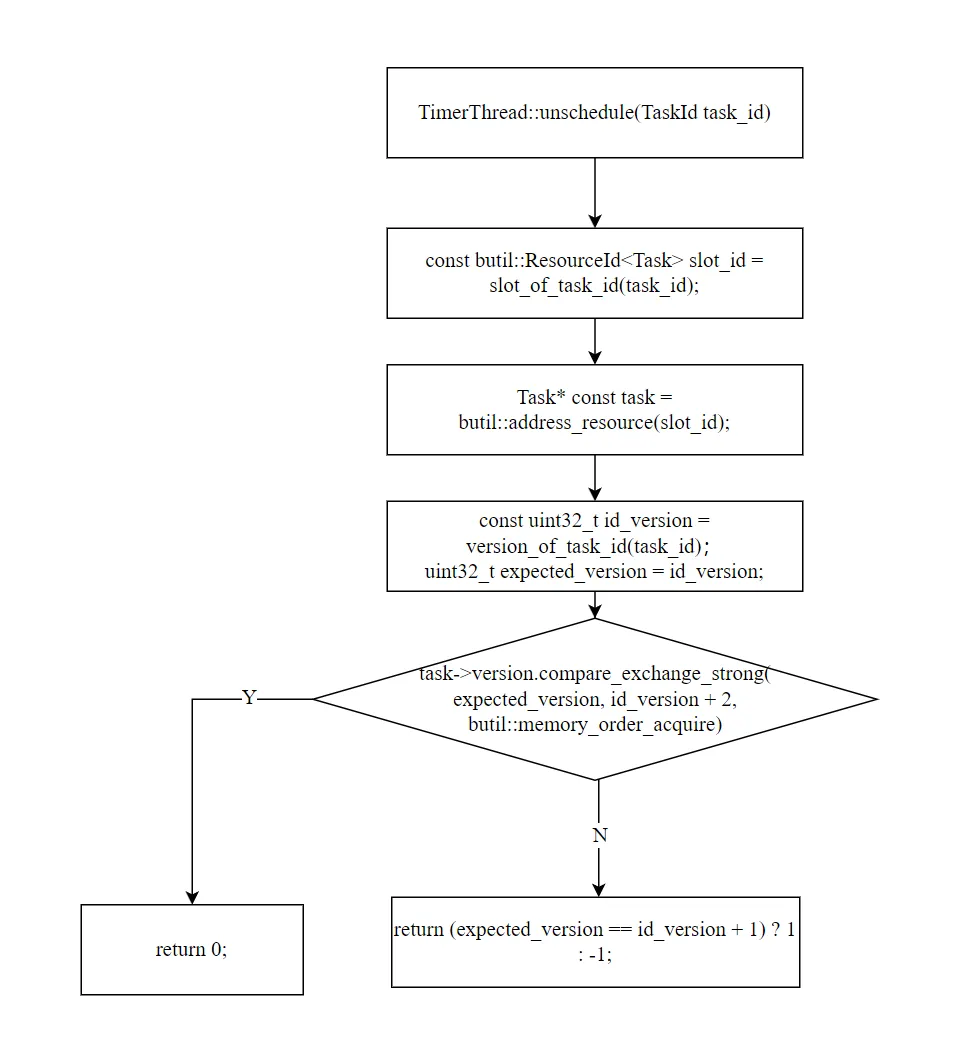
intTimerThread::unschedule(TaskId task_id){ const uint32_t id_version = version_of_task_id(task_id); uint32_t expected = id_version; // CAS: id_version → id_version+2(取消) if (version.compare_exchange_strong(expected, id_version + 2, memory_order_acquire)) { return 0; // 取消成功 } return (expected == id_version + 1) ? 1 : -1; // 返回 1: 正在运行中 // 返回 -1: 不存在或已完成}
boolTask::try_delete(){ const uint32_t id_version = version_of_task_id(task_id); if (version.load(memory_order_relaxed) != id_version) { // version != id_version → 已取消或已完成 CHECK_EQ(version.load(), id_version + 2); return_resource(slot_of_task_id(task_id)); return true; } return false; // 仍然有效,不删除}
关键观察:TaskId 中的 version(高 32 位)在创建后不变,真正表示实时状态的是 Task.version 字段。 判断任务状态时,必须同时比较两者——TaskId 中的 version 是"期望值",Task.version 是"实际值"。
version 初始值为 2(跳过 0),每次复用时上一次的结束版本号(id_version + 2)成为下一次的初始版本号。这种设计使得 version 在 Task 的整个生命周期中严格递增,不会回绕。
八、unschedule:取消任务
取消操作的核心就是上一节分析的 version CAS,但有几个细节值得注意:
不需要获取任何锁——纯 CAS 操作。这也是为什么 Task 要用 ResourcePool(而非 ObjectPool):ResourcePool 通过 slot_id 可以 O(1) 定位对象,不需要加锁(参见本系列第三篇的 address_resource)。
不回收 Task 结构体——由 TimerThread::run 在 try_delete 或 run_and_delete 中统一回收。源码注释解释了原因:
在 timer 线程唤醒之前可能积累大量已取消的任务,但 ResourcePool 的 TLS 缓存(每线程 128K)足以容纳。当 timeout / latency < 2730(128K / sizeof(Task))时,已取消的任务不占用额外内存。2730 是一个很大的超时/延迟比,在大多数 RPC 场景中都能满足。
返回值的三种情况:
0:取消成功(任务尚未运行)1:任务正在运行中(回调正在执行)-1:任务不存在或已完成
调用者可以根据返回值决定后续行为——例如返回 1 时可能需要等待回调执行完毕。
九、stop_and_join:停止定时器
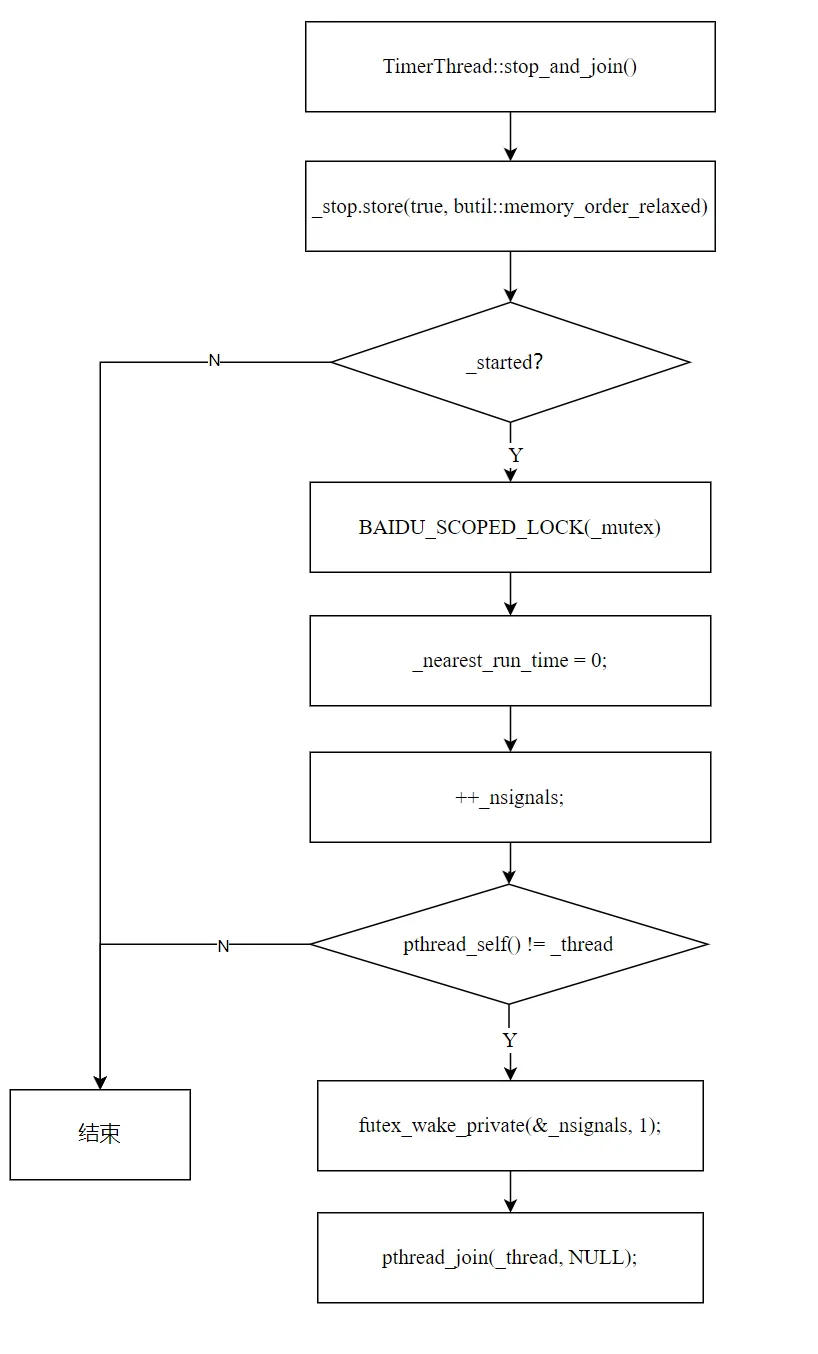
void TimerThread::stop_and_join() { _stop.store(true, memory_order_relaxed); if (_started) { { BAIDU_SCOPED_LOCK(_mutex); _nearest_run_time = 0; // 触发重新拉取 ++_nsignals; // 唤醒 timer 线程 } if (pthread_self() != _thread) { futex_wake_private(&_nsignals, 1); pthread_join(_thread, NULL); } }}
停止流程:
- 设置停止标志:
_stop = true - 触发唤醒:将
_nearest_run_time 设为 0(比任何任务都早),递增 _nsignals,确保 timer 线程能被唤醒 - 条件等待:
pthread_self() != _thread 检查调用者是否是 timer 线程自身
为什么需要这个检查?如果 stop_and_join 被 timer 线程自身的回调调用(回调中调用了 stop_and_join),不能 pthread_join 自己——会死锁。此时只设置 _stop = true 和 _nearest_run_time = 0 即可:回调返回后,主循环会检测到 _stop 并退出。
十、总结
TimerThread 的设计可以归纳为一句话:分桶减少调度竞争,最小堆管理执行顺序,version 状态机管理任务生命周期,futex 驱动等待与唤醒。
四个关键设计:
1. 分桶(Bucket)减少锁竞争。 调度请求按线程 ID 哈希分散到不同桶中。每个桶有独立的互斥锁,多线程调度时互不干扰。桶数量默认 13(经验值),不宜过大——更大的桶数量使每个桶更稀疏,反而更容易竞争全局互斥锁。
2. 两级"最近时间"优化。 每个桶维护自己的 _nearest_run_time,全局维护一个 _nearest_run_time。只有当新任务是本桶最早且比全局更早时,才需要获取全局锁并唤醒 timer 线程。在 RPC 场景中(超时时间递增),大多数任务不会触发全局锁。
3. version 三态状态机。 Task 通过 version 字段管理"未运行 → 运行中 → 已移除"三种状态。schedule 设置初始 version,run_and_delete 递增 version(id_version → id_version+1 → id_version+2),unschedule 通过 CAS 跳到"已移除"。所有状态转换都是原子操作,不需要锁。
4. futex + expected_nsignals 防丢失。_nsignals 作为 futex 变量,每次有更早任务时递增。timer 线程睡眠前记录 expected_nsignals,如果睡眠期间有新任务改变了 _nsignals,futex_wait_private 因值不匹配立即返回。这确保了不会漏掉任何更早的任务。
本文基于 Apache brpc 源码(src/bthread/timer_thread.h、src/bthread/timer_thread.cpp)撰写。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
