接着MLC相关知识,我们最后简要学习下TLC,QLC和1.5Bits/cell的NAND存储方式。更多级的存储从本质上说并没有不同。关键技术都是如何收窄Vt的分布宽度,使得各级Vt状态之间有足够的裕量,能够被区分开来。
TLC 3Bits/cell
每个TLC的Cell存储三个Bits信息,分别归到3页Page,lower page 1st/middle page 2nd/ upper page 3rd。这些page有独立的地址,所以在用户看来与普通Page相同。
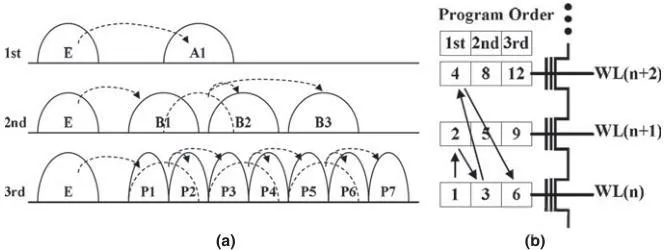
传统的TLC写入方法直接继承自MLC。擦除状态E,在1st page被写入到A1态,接着2nd page从A1态写入到B2/B3态。最后3rd page,从B1/B2/B3态写入到P2~P7态。每级Page写入都要用到前面级的信息,来确定需要写入的态。其中A1/B1~B3都是中间态,减轻一次性写入被后续干扰导致的Vt展宽。WL的写入次序也类似MLC,可以看图(b)中数字标注,2nd和3rd page的写入操作,都延迟到相邻WL的1st和2nd page之后,尽量降低WL之间Vt偏移量。从图上还能看到,由于TLC与MLC的物理结构相同,7个Vt态要放进相同的Vt窗口内,这就对Vt的分布宽度要求更严格,特别是3rd page的写入Vpgm增量步长必须很小,导致写入速度很慢。
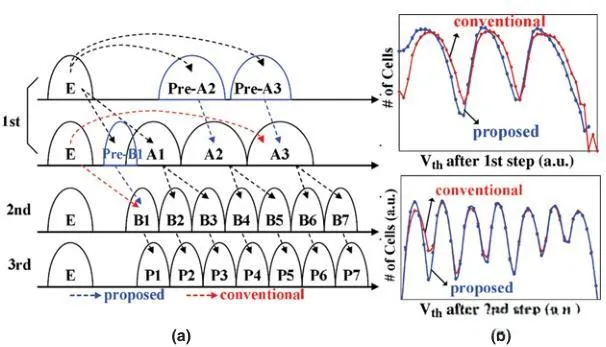
在21nm结点还提出了预写入的方法。具体来说,1st page会拆出两步,前一步将E态预写入到Pre-A2/Pre-A3,后一步从E分出Pre-B1和A1,这样分出5个态。2nd page从前面5个态E/Pre-B1/A1/A2/A3,写入到E/B1~B7八个态。3rd Page微调到最终态P1~P7。这么做的好处是减小了每次写入的Cell Vt移动量,降低写入干扰。从图中对比看,引入Pre-A2/Pre-A3,减轻BL-BL串扰,使得A1~A3的分布宽度收窄15%。引入Pre-B1,将WL-WL串扰减轻10%。
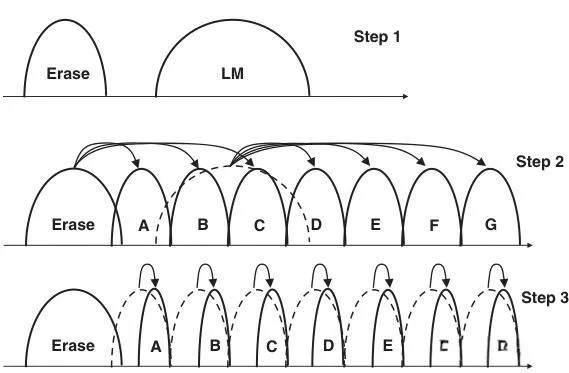
随着Cell微缩,FG耦合增强,叠加小FG更易感,干扰越来越严重,影响写入性能。在19nm结点引入了空气间隙 air gap (AG),来减小WL之间的耦合。还发展出了三步写入Three-Step Program(TSP)技术,来增强写入效率。第一步写入到临时状态LM,第二步从E/LM直接写入到8个状态A~G,第三步将所有Vt态的分布收紧。因为跳过了之前2nd page的步骤,写入时间变短。AG和TSP结合,使得19nm NAND TLC的写入速度能达到18MB/s。
需要提醒的是,尽管发展出了不同的写入技巧,但随着Cell微缩,Vt窗口还是不可避免的变窄,裕量越来越少。
QLC 4Bits/cell
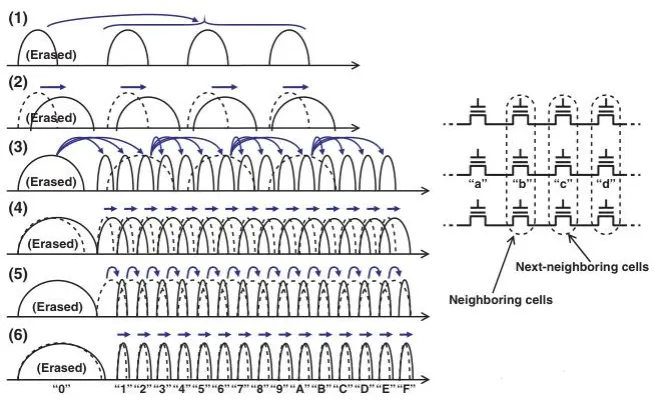
QLC要在单个Cell内存储16个Vt状态,对Vt分布的宽度要求更加严格。这里增加了更精细的写入技巧。首先,用TSP将Cells被写入到16个较低态(lower verify voltages),比目标态(target verify voltages)略低。当所有相邻Cell都写入后,Cell Vt展宽。此时,再做一遍写入,收紧Vt分布。待相邻Cell收紧后,Vt还是会有轻微展宽,但因为收紧Vt的移动量很小,所以最后的展宽不大,可以得到非常窄的Vt分布。
QLC增加了写入步骤,还要求更窄的Vt分布,必然牺牲写入效率,总的写入时间增加到11.75ms。就算采用双Page同时写入技术two-page mode,写入速度也比TLC慢,约5.6MB/s。
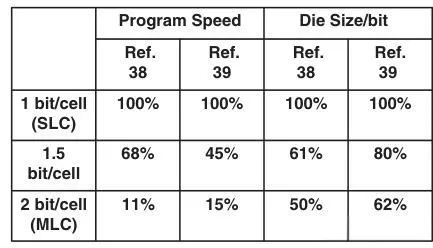
三级(Three-level 1.5bits/cell)NAND FLASH
特殊的1.5bit/cell技术是平衡性能和成本的产物。即有接近SLC的性能,高于MLC的可靠性,又比SLC更便宜。三级Cell有“0”,“1”,“2”三个Vt态,比MLC的4个态的读取裕量大1倍。从写入速度上来说能达到SLC的68%,面积为61%接近MLC。
移动读取算法 Moving read algorithm
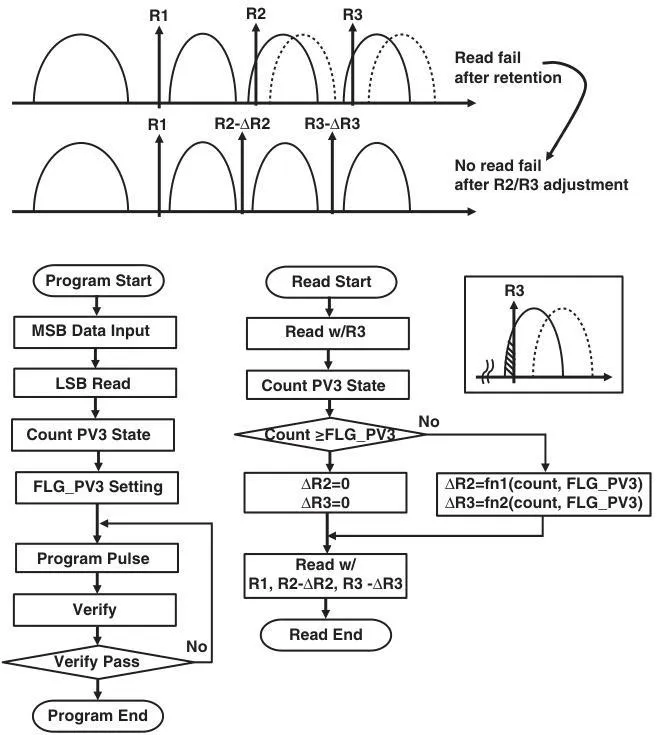
前面主要是关于MLC NAND写入的方法,最后补充一点增强读取操作的算法技术。我们知道数据保持能力Data retention是NAND的重要指标,但随着Cell微缩,Vt随P/E循环次数的漂移越来越严重。为了补偿这种漂移,引入移动读取算法,可以根据Vt漂移的多少来微调CG上的读取电压大小。
举个例子,我们增加一组Cell,记录每页Page中PV3态的数目,记为FLG_PV3。因为PV3是最容易受到影响,数据保持最差。在读取操作时,数出读取的PV3态的Cell数目与写入时的FLG_PV3比较。如果数目不符,说明Vt漂移影响到了读取操作。这种情况将相应降低读取电压。采用这一方法,可以将读取错误率降低30%。
前面例子只是针对数据保持能力导致的Vt漂移,针对FG干扰、写入电子扩散、RTN、写干扰、读干扰等等,都可以设计相应的优化方案来提高读取的可靠性。