RNN、LSTM、GRU 学习笔记:从循环结构到门控记忆
最近在看强化学习里的 recurrent policy。
很多策略网络会引入 RNN、LSTM 或 GRU,用来处理带历史信息的状态。
如果只看代码,很容易卡在几个问题上:
- LSTM 和 GRU 的图里为什么经常看不到最终输出 ?
这篇文章不追求把所有细节讲完,只先把主线理清楚。
先说结论
RNN 系列模型的核心,是把序列历史压缩到一个状态里,再传给下一个时间步。
vanilla RNN 只有一个隐藏状态 。
它结构简单,但长序列中容易出现梯度消失或梯度爆炸。
LSTM 在隐藏状态之外,额外引入记忆元 。
可以理解为:
负责长期保存信息, 负责当前对外表达。
GRU 则进一步简化。
它没有单独的记忆元,而是把历史信息和当前表达都合并在隐藏状态 中。
为什么还要看 RNN?
现在很多场景会优先想到 Transformer。
但在一些工程任务里,RNN 仍然有价值。
比如:
在强化学习、机器人控制、时间序列预测等任务里,RNN、LSTM、GRU 仍然经常出现。
它们不是最时髦的结构,但很适合用来理解“历史状态如何参与当前决策”。
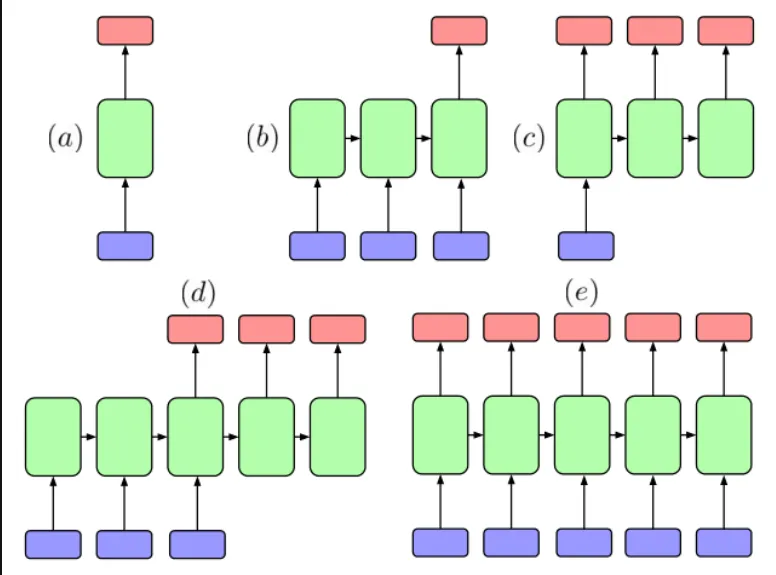
输入和输出的几种结构
RNN 处理的是序列问题。
序列问题不只是“多个输入对应多个输出”,还可以有很多形式。
这几种结构在实际任务中,大概可以这样对应:
这里需要注意:
one-to-one 严格来说不一定需要 RNN,它只是放在这里作为对比。
RNN 真正有价值的地方,是后面这些带有序列输入或序列输出的任务。
RNN 输入输出结构图片引用:A Critical Review of Recurrent Neural Networks for Sequence Learning
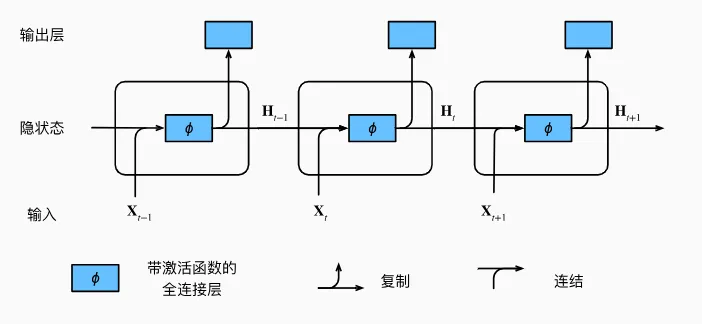
vanilla RNN:当前输入加历史状态
先看最经典的 vanilla RNN。
它的核心是一个循环传递的隐藏状态。
vanilla RNN 结构图片引用:https://zh.d2l.ai/chapter_recurrent-neural-networks/rnn.html
每一个时间步都会接收两个输入:
然后模型计算当前时刻的隐藏状态 ,继续传给下一个时间步。
这里最重要的一点是:
RNN 在不同时间步使用的是同一组参数。
序列长度变长时,模型不是新增一套网络,而是把同一个循环层反复展开。
vanilla RNN 的数学表达
先定义几个量:
隐藏状态更新公式是:
输出层公式是:
如果是分类任务,通常还会接一个 :
这里有几个关键点:
所以 vanilla RNN 的核心就是:
当前状态 = 当前输入 + 历史状态。
vanilla RNN 的问题
vanilla RNN 的结构很直观,但它有一个典型问题:
长序列训练时,历史信息很容易传不远。
原因在于 RNN 需要沿着时间反向传播,也就是常说的 BPTT。
当序列很长时,梯度会经过很多次连续相乘,容易出现两个极端:
所以 vanilla RNN 更适合处理短期依赖。
如果任务需要记住更长时间之前的信息,就需要引入门控机制。
这也是 LSTM 和 GRU 出现的主要原因。
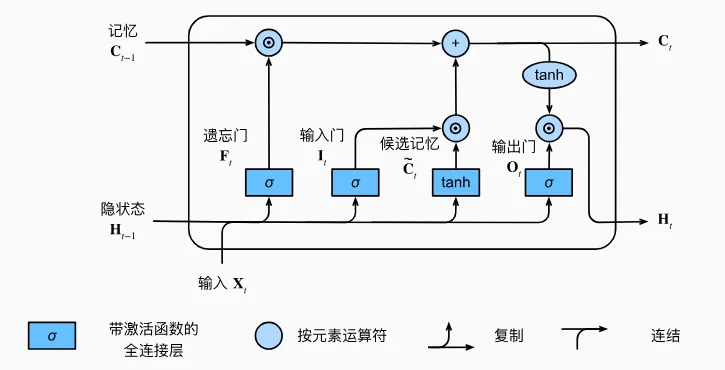
LSTM:把长期记忆单独拎出来
LSTM 的目标,是缓解 vanilla RNN 在长序列中记不住远期信息的问题。
它额外维护了一个记忆元 ,再通过门控机制控制信息的遗忘、写入和输出。
可以简单概括为:
三道门:
一个记忆元:
LSTM 结构图片引用:https://zh.d2l.ai/chapter_recurrent-modern/lstm.html
LSTM 的数学表达
先定义几个量:
LSTM 的计算链路可以理解成这样:
遗忘门:
输入门:
候选记忆元:
更新记忆元:
输出门:
当前隐藏状态:
这里最关键的是三道门和一个记忆元:
- 是当前隐藏状态,通常会传给下一时刻,也可以用于当前时刻的任务输出。
- 表示 sigmoid 函数,输出范围在 0 到 1 之间。
所以 LSTM 的核心思想是:
用记忆元保存长期信息,再用遗忘门、输入门、输出门控制信息的保留、写入和输出。
LSTM 的代价
LSTM 通过记忆元和门控机制缓解了长期依赖问题,但它也不是没有代价。
主要问题有三个:
- 结构更复杂,参数量比 vanilla RNN 更大;
- 每个时间步要计算三个门和一个候选记忆元,训练和推理成本更高;
- 在序列特别长、数据规模很大时,仍然不如 Transformer 这类结构容易并行。
所以 LSTM 适合需要保留长期信息、但又不希望模型过于庞大的场景。
在强化学习策略网络里,如果状态历史对当前动作有影响,LSTM 是一个常见选择。
但如果只是短窗口信息,或者对实时性要求很高,就需要重新权衡它的计算成本。
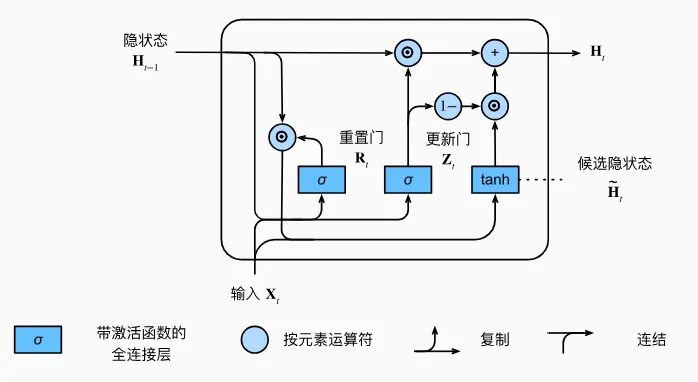
GRU:把记忆和隐藏状态合并
GRU 可以理解成 LSTM 的简化版本。
它不再单独维护记忆元,而是把长期信息和当前隐藏状态合并到 里。
可以简单概括为:
两道门:
一个候选状态:
GRU 结构图片引用:https://zh.d2l.ai/chapter_recurrent-modern/gru.html
GRU 的数学表达
先定义两个量:
GRU 的计算链路可以理解成这样:
重置门:
更新门:
候选隐藏状态:
当前隐藏状态:
这里最关键的是两个门:
- 是重置门,决定在计算候选隐藏状态时,要不要参考一部分历史信息;
- 是更新门,决定最终状态里,保留多少旧状态、写入多少新状态;
- 是候选隐藏状态,可以理解成当前时刻准备写入的新记忆;
- 表示 sigmoid 函数,输出范围在 0 到 1 之间。
所以 GRU 的核心思想是:
用更新门控制“记住多少过去”,用重置门控制“如何生成新的候选记忆”。
GRU 的取舍
GRU 把 LSTM 里的记忆元和隐藏状态合并了,同时减少了门的数量。
这样做的好处是:
但代价是控制能力也相对弱一些。
GRU 没有单独的记忆元 Ct,也没有单独的输出门。
因此,在某些特别依赖长期精细记忆的任务里,LSTM 可能会更稳。
不过在很多工程任务中,GRU 的效果和 LSTM 接近,同时计算成本更低,所以它经常是一个更实用的折中选择。
LSTM 和 GRU 的历史存取方式
两者最核心的区别,是历史信息存在哪里。
LSTM 是“记忆”和“输出”分开管理。
GRU 是把“记忆”和“输出”合并管理。
一句话总结:
LSTM 更像是单独维护一条长期记忆通道;GRU 则是把长期信息压缩在隐藏状态里。
几个容易混淆的问题
1. LSTM 和 GRU 没有最终输出吗?
不是没有输出。
很多结构图只画了循环单元内部,把任务输出层省略了。
更完整的链路应该是:
vanilla RNN:
LSTM:
GRU:
最终任务输出通常还是由隐藏状态 接一个输出层得到:
这里容易混淆的是:
LSTM 公式里的 是输出门,不是最终任务输出 。
2. 为什么要一直传递隐藏状态?
因为当前时刻的输入 只包含当前信息。
很多序列任务需要历史上下文。
隐藏状态 的作用就是:
把过去的信息压缩成一个状态,传给下一个时间步。
可以这样理解:
所以模型看到 时,不只是看到当前输入 ,还通过 间接获得了前面 、 的信息。
3. 隐藏状态已经包含历史信息,为什么 LSTM 还需要记忆元?
vanilla RNN 只有一个 。
它既要记住过去,又要参与当前输出,还要继续传给下一个时刻。
LSTM 把这件事拆开了:
所以可以简单理解为:
记忆元 负责存,隐藏状态 负责用。
不是所有保存在 里的信息都会立刻暴露到 。
只有被输出门 选择出来的部分,才会变成当前时刻对外可见的隐藏状态。
4. GRU 的重置门到底起什么作用?
GRU 里更新门 的作用比较直观:
它决定最终状态里,旧状态和新候选状态各占多少。
重置门 的作用更容易被忽略。
它主要作用在生成候选隐藏状态这一步:
关键是这一项:
如果 接近 0,说明生成候选状态时基本不看过去,更多依赖当前输入 。
如果 接近 1,说明生成候选状态时会充分参考过去的隐藏状态。
所以重置门可以理解成:
控制“生成新候选状态时,还认不认旧历史”。
而更新门控制的是:
最终状态里,旧历史到底留多少。
阅读建议
读 RNN、LSTM、GRU 时,不要一开始就陷入公式细节。
更好的顺序是:
记住这几句话就够了:
最后总结
RNN 系列模型的主线,其实就是一句话:
如何让当前时刻的决策带上过去的信息。
vanilla RNN 用隐藏状态直接传递历史。
LSTM 引入记忆元和三道门,让长期信息更稳定。
GRU 则把结构简化,用两个门完成历史保留和候选状态生成。
理解这条主线之后,再去看 recurrent policy 或时间序列模型,代码里的 hidden_state、cell_state、reset mask 等概念会清楚很多。
文献引用
- Lipton, Z. C., Berkowitz, J., & Elkan, C. (2015). A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv:1506.00019. https://arxiv.org/abs/1506.00019
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. Dive into Deep Learning. RNN 章节:https://zh.d2l.ai/chapter_recurrent-neural-networks/rnn.html
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. Dive into Deep Learning. LSTM 章节:https://zh.d2l.ai/chapter_recurrent-modern/lstm.html
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. Dive into Deep Learning. GRU 章节:https://zh.d2l.ai/chapter_recurrent-modern/gru.html