Unidbg学习笔记(十二):Trace 的三个层次
- 2026-04-27 18:22:45
Trace 是 Unidbg 区别于其他方案的核心竞争力。在 Unidbg 里做 Trace,比 Frida 更底层、更完整、也更可控。本篇教你怎么从一团黑盒里“看见”程序在干什么。
上一篇把你留在了哪里
第十一篇我们解决了“函数返回 null”的初始化问题 —— 但解决的姿势其实有点土:
用 Frida 拿标准答案 用 Frida 逐个 Call 找关键 init 用 IDA 静态分析
你可能已经发现了:整套流程里,真正用 Unidbg 的部分,只有最后“按序调用”那一步。
为什么 Unidbg 没在定位过程中起作用?因为我们没用上它最强的能力 —— Trace。
这一篇就是把 Unidbg 的“内视镜”打开。读完之后你会明白:
为什么 Unidbg 的 Trace 比 Frida 完整 三个层次的 Trace 各自适合什么场景 怎么从百万行 Trace 里捞出有用信息
一句话定位:补环境是让 SO 跑起来,Trace 是让 SO 跑给你看。
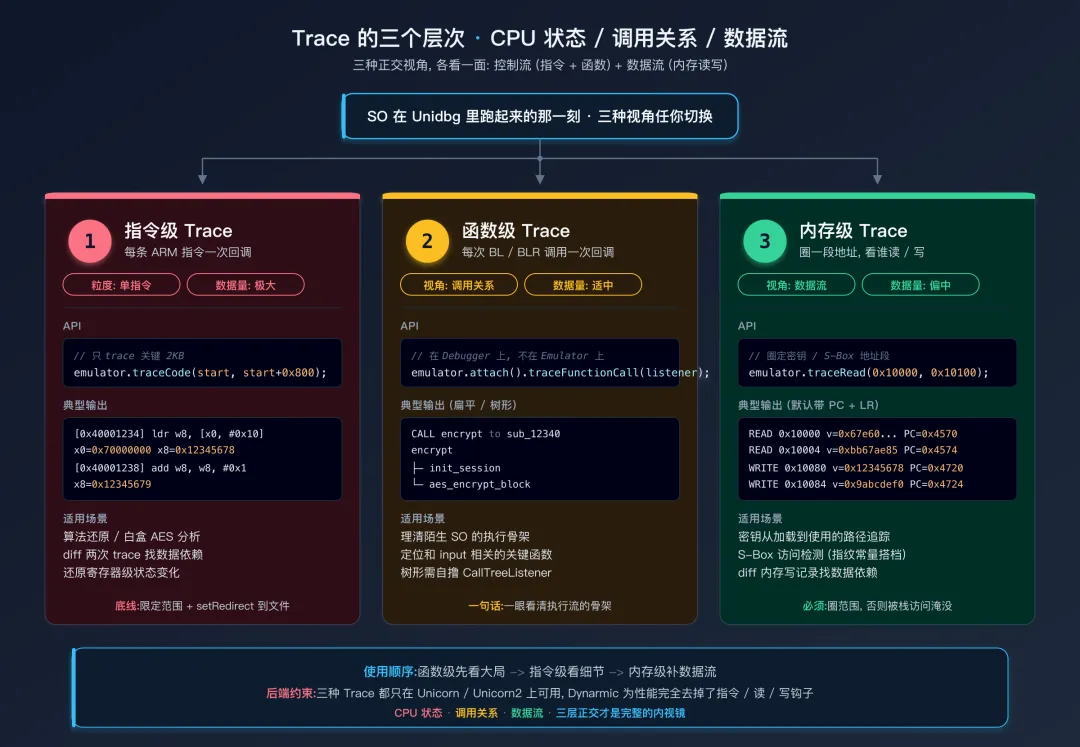
为什么 Unidbg 的 Trace 比 Frida 强
先回答一个常见问题:Frida 也能 Trace 啊,为什么还要用 Unidbg?
简单说:Frida 是“在真机上观察”,Unidbg 是“把样本搬到实验室解剖”。前者快,后者细。

第一层:指令级 Trace
最底层的 Trace。Unidbg 在每条 ARM 指令执行前后,都会回调一次,你能拿到:
当前 PC 地址 指令编码 (4 字节) 反汇编后的助记符 全部寄存器的值
怎么开
// 简单粗暴版: trace 整个 SO
emulator.traceCode();
// 推荐版: 只 trace 一段感兴趣的地址
long base = module.base;
emulator.traceCode(base + 0x1234, base + 0x2000);
典型输出
[14:32:01 256ms][libxxx] [0x40001234][libxxx.so][0x00001234] "ldr w8, [x0, #0x10]" x0=0x70000000 x8=0x12345678
[14:32:01 256ms][libxxx] [0x40001238][libxxx.so][0x00001238] "add w8, w8, #0x1" x8=0x12345679
[14:32:01 256ms][libxxx] [0x4000123c][libxxx.so][0x0000123c] "str w8, [x0, #0x10]" x0=0x70000000 x8=0x12345679
[14:32:01 256ms][libxxx] [0x40001240][libxxx.so][0x00001240] "ldr x9, [x20, #0x28]" x20=0x70100400 x9=0x70110800
[14:32:01 256ms][libxxx] [0x40001244][libxxx.so][0x00001244] "cmp x9, x8" x9=0x70110800 x8=0x12345679
[14:32:01 256ms][libxxx] [0x40001248][libxxx.so][0x00001248] "b.ne 0x40001280" nzcv=0x60000000
一行就是一条指令的“快照”。把每一列拆开看:

[14:32:01 256ms]是 Unidbg 打的时间戳,分析时一般用不上,但如果你在 debug 一个“偶发走错分支”的问题,时间戳能帮你对齐 trace 里的事件顺序[0x40001234]是当前指令的绝对虚拟地址(Unicorn 视角的地址空间),实际取决于 Unidbg 给这个模块分配的基址[libxxx.so][0x00001234]是解析出的模块内偏移——这一列至关重要,它就是你在 IDA 里看到的那个偏移,可以直接双击跳过去对照"ldr w8, [x0, #0x10]"是 Capstone 反汇编出的助记符,基本等同于 IDA 里显示的汇编x0=0x70000000 x8=0x12345678是变化后的寄存器值,Unidbg 只打出“这条指令读/写了哪些寄存器”,没变化的寄存器不打,保持 trace 紧凑
注意第 5 行 cmp x9, x8 指令后面出现了 nzcv=0x60000000——这是 ARM64 的标志寄存器,6 的二进制是 0110,代表 Z=1, C=1, N=0, V=0,即“相等且无借位”。第 6 行的 b.ne 0x40001280 根据这个 nzcv 判断不跳(因为 Z=1 意味着相等,而 b.ne 是“不等才跳”),所以下一行会是 0x4000124c 而不是 0x40001280——这条信息在排查“我以为会跳但实际没跳”的场景里特别有用。
学会读这几列之后,整份 trace 就是一本“程序自述”:什么时候读了哪块内存、比较了什么、分支走了哪一条、返回值填到哪个寄存器,全都写得清清楚楚。
适用场景
算法分析。比如你想知道一个加密函数对输入做了什么 —— 静态看 IDA 反汇编很费劲,因为你不知道哪些分支真的走到了。但指令级 Trace 直接告诉你:这次执行实际经过了哪 1000 条指令,每一步寄存器是什么。
配合 diff 工具,你可以做这种事:
用两份不同的输入跑两次,得到两个 Trace 文件。diff 一下,就能看出 “哪些指令的寄存器值不同” —— 这些就是真正受输入影响的指令,其他都是常量计算。
这在还原白盒 AES 之类的混淆算法时几乎是唯一可行的办法。
数据量警告
指令级 Trace 数据量极大。一个普通的 encrypt 函数可能产生:
5 万到 50 万行 Trace 100 MB 以上的文本 直接卡死 IDE
所以必须缩范围。先用 IDA 看出关键代码段大致在什么偏移,然后只 Trace 那一小段。
// 不要这样
emulator.traceCode(); // 全量, 文件能爆磁盘
// 这样
emulator.traceCode(funcStart, funcStart + 0x800); // 只看关键 2KB
输出重定向
默认 Trace 输出到 stdout,会把控制台刷得无法阅读。务必重定向到文件:
PrintStream redirect = new PrintStream(new FileOutputStream("trace_encrypt.txt"));
emulator.traceCode().setRedirect(redirect);
这样 Trace 进文件,你的 println 还能正常用,两不耽误。
第二层:函数级 Trace
指令级 Trace 太细,有时你只想知道:这个函数被调了几次?谁调的?参数是什么?
这就是函数级 Trace 的用武之地。
怎么开
traceFunctionCall 不在 Emulator 接口上,而在 Debugger 接口上 —— 所以必须先 attach 一个 debugger,再注册 listener:
Debugger debugger = emulator.attach(); // 不传参数 = 拿默认的 SimpleARM*Debugger, 不会真的进交互式断点
debugger.traceFunctionCall(module, new FunctionCallListener() {
@Override
publicvoidonCall(Emulator<?> emulator, long callerAddress, long functionAddress){
System.out.printf("CALL %s -> %s\n",
module.findClosestSymbolByAddress(callerAddress, false),
module.findClosestSymbolByAddress(functionAddress, false));
}
@Override
publicvoidpostCall(Emulator<?> emulator, long callerAddress, long functionAddress, Number[] args){
// 函数返回后回调
}
});
FunctionCallListener 是个 abstract class(不是 interface),所以用匿名子类的姿势 override 两个抽象方法即可。
典型输出
CALL Java_com_xxx_Sec_encrypt -> sub_12340
CALL sub_12340 -> sub_45670
CALL sub_45670 -> AES_encrypt
CALL sub_45670 -> sub_89AB0
CALL sub_12340 -> sub_CDEF0
一眼能看出执行流的“骨架”。
适用场景
理清执行流:面对一个完全陌生的 SO,先跑一遍函数 Trace,看大致经过了哪些函数 定位关键函数:在 1000 个函数里,只有几个跟 input 相关 —— 用不同 input 跑两次,diff 一下函数 Trace 就能找出来 处理混淆样本:OLLVM 控制流平坦化后静态分析几乎没法看,但函数 Trace 仍然能告诉你“实际执行经过了哪些 basic block”
实战技巧:配合 Symbol 解析
光打印地址(sub_12340)没什么用,关键是把它解析回函数名或最近的导出符号。Unidbg 提供的 API 是:
Symbol sym = module.findClosestSymbolByAddress(address, false);
if (sym != null) {
long offset = address - sym.getAddress();
System.out.println(sym.getName() + " + 0x" + Long.toHexString(offset));
}
findClosestSymbolByAddress 会在模块所有导出符号里找地址不大于给定 address 且距离最近的那一个,返回一个 Symbol 对象。即使 SO 大部分函数被 strip,只要有几十个导出符号(典型情况下 JNI 入口、构造函数、几个外部调用的工具函数都是导出的),也足以把 trace 里的数字地址翻译成“某个导出函数 + 偏移”的形式,大大提高可读性。
典型输出对比:
# 不解析的原始 trace
CALL 0x40001234 -> 0x40004570
CALL 0x40004570 -> 0x40008abc
# 解析过的 trace
CALL Java_com_xxx_Sec_encrypt + 0x0 -> sub_4570 + 0x0
CALL sub_4570 + 0x0 -> AES_encrypt + 0x0
前者完全不知道在看什么,后者一眼就能看出调用路径经过了 AES 加密入口。
完整的解析封装通常长这样,带一层缓存避免每次都遍历符号表:
publicclassSymbolResolver{
privatefinal Module module;
privatefinal Map<Long, String> cache = new HashMap<>();
publicSymbolResolver(Module module){
this.module = module;
}
public String resolve(long address){
return cache.computeIfAbsent(address, addr -> {
Symbol sym = module.findClosestSymbolByAddress(addr, false);
if (sym == null) {
return String.format("sub_%x", addr - module.base);
}
long offset = addr - sym.getAddress();
return offset == 0
? sym.getName()
: String.format("%s + 0x%x", sym.getName(), offset);
});
}
}
这套封装扔进 FunctionCallListener 里,trace 的可读性能提高一个量级。注意第二个参数 false 是“不强制返回”——遇到没有符号命中的地址,返回 null 而不是抛异常,由调用者决定怎么 fallback(通常就是回退到 sub_xxxx 格式)。
对于 stripped SO + 没有导出符号的极端情况,还有一条路:用 IDA 在静态分析阶段把识别出的函数名(即使是 IDA 自动生成的 sub_xxxx)导出为一个 symbols.txt,在 Unidbg 里加载这份 txt 做第二层查询。这就是所谓的“外部符号表”,许多逆向工具链里都有类似的做法。
两种展示:扁平 vs 树形
函数级 Trace 默认是“线性”的 —— 每行一个调用。但函数是有嵌套层次的,扁平打印看不出“谁是谁的父亲”。如果想要这样的树形结构:
encrypt
├─ init_session
│ ├─ load_key_table
│ └─ derive_subkey
│ └─ sha256
├─ aes_encrypt_block
│ ├─ aes_round
│ ├─ aes_round
│ └─ aes_round
└─ pad_pkcs7
unidbg 没有内置 call-tree API,得自己写一个 listener,靠在 onCall / postCall 里维护一个 depth 计数器实现缩进:
publicclassCallTreeListenerextendsFunctionCallListener{ // FunctionCallListener 是 abstract class
privateint depth = 0;
privatefinal PrintStream out;
publicCallTreeListener(PrintStream out){ this.out = out; }
@Override
publicvoidonCall(Emulator<?> emulator, long caller, long target){
for (int i = 0; i < depth; i++) out.print("│ ");
out.println("├─ " + resolveName(target));
depth++;
}
@Override
publicvoidpostCall(Emulator<?> emulator, long caller, long target, Number[] args){
depth--;
}
}
depth 计数能跑得通的前提是 onCall / postCall 在 unidbg 的 debugger 内部是配对触发的 —— 你不用自己处理"进函数没出"这种情况。如果 SO 用了非常规跳转(裸 BR、setjmp/longjmp、inline 优化的尾调用等)使配对失效,缩进就会失真。
输出树形时记得重定向到文件(调用树通常上千行,扔 stdout 没法读):
PrintStream out = new PrintStream(new FileOutputStream("call_tree.txt"));
Debugger debugger = emulator.attach();
debugger.traceFunctionCall(module, new CallTreeListener(out));
然后用 less 或编辑器的代码折叠功能阅读。
什么时候用树形 vs 坚持扁平:
树形适合:首次接触大 SO 30 秒看清结构、给逆向报告做可视化 扁平适合:样本带 inline 优化 / 跳转表 / 自定义栈(嵌套层级会失真);只关心"谁调了谁、几次",扁平更好 grep
第三层:内存级 Trace
前两层观察的都是控制流(指令在哪、调到了谁)。但很多分析问题真正关心的是数据流 —— 谁读了哪块内存、谁写了哪块内存、值是什么。Unidbg 在 Emulator 接口上提供了和 traceCode 完全对称的两组 API:
TraceHook traceRead();
TraceHook traceRead(long begin, long end);
TraceHook traceRead(long begin, long end, TraceReadListener listener);
TraceHook traceWrite();
TraceHook traceWrite(long begin, long end);
TraceHook traceWrite(long begin, long end, TraceWriteListener listener);
不带参数 = 全量、传 begin/end = 限定地址段、再传 listener = 自定义处理逻辑 —— 三种重载和 traceCode 一比一对照。
怎么开
最常用的姿势是圈一段感兴趣的内存范围,看哪些指令读/写了它。比如你怀疑某个 BSS 段地址 0x10000-0x10100 是密钥 buffer:
PrintStream traceStream = new PrintStream(new FileOutputStream("mem_trace.txt"));
emulator.traceRead(0x10000L, 0x10100L).setRedirect(traceStream);
emulator.traceWrite(0x10000L, 0x10100L).setRedirect(traceStream);
跑一次目标函数,trace 文件里会列出所有命中这段地址的内存访问 —— 包含访问指令、访问地址、访问字节数、读/写的值。
读这种 trace 比读指令 trace 高效得多 —— 一行一个事件,没有大量"无关计算"指令的噪声。
适用场景
1. 跟踪密钥从加载到使用的路径
很多算法的密钥是先从某个固定地址 / 常量段加载到内存,然后被 round 函数反复读。traceRead 圈定密钥所在地址段,就能看到 round 函数依次访问哪些字节、什么顺序 —— 这往往就是 round 函数的"密钥调度"逻辑。
2. S-Box 访问检测(指纹常量分析的天然搭档)
下面的"在 Trace 中搜索关键常量"小节会讲怎么用 grep 加密指纹常量定位 S-Box 的地址。一旦找到,对那段地址开 traceRead,所有读 S-Box 的指令都会被列出来 —— 这些指令就是算法的"查表层",是逆向 AES / RC4 / DES 时最关键的部分。
3. 数据依赖反推
后面"Diff 两次 Trace"那一招主要靠对比指令级 trace。但内存级 trace 提供了另一个维度:两次执行用不同输入,diff 内存写记录 —— 输出地址相同、写入值不同的位置,就是和输入数据强相关的中间变量。
数据量
内存级 trace 比指令级显著小(数据访问密度低于指令执行密度),但比函数级大。粗估一次 encrypt 跑 100ms 的数据量级:
函数级:~几百行(每次 BL一行)内存级(限定段):~几千到几万行(取决于圈的范围有多大) 指令级(全量):~几十万行(每条指令一行)
具体值会随 SO 复杂度、输入大小、限定地址段宽度浮动很大,上面是数量级而非精确值。所以"圈范围"对内存级 trace 几乎是必须的 —— 全量 traceRead() 会把堆栈上所有局部变量访问也打出来,淹没真正想看的。
实战提示:默认输出格式是
{date} Memory READ/WRITE at 0x{addr}, data size = ..., data value = ..., PC=..., LR=...,每行都带 PC 和 LR,所以你既能知道"哪块内存被访问",也能知道"哪条指令访问的、来自哪个调用"——这是和指令级 trace 不一样的优势。
Backend 限制
和指令级 trace 一样,只有 Unicorn / Unicorn2 backend 支持。Dynarmic 的 JIT 没法暴露每条 load/store 的事件回调。
Trace 数据的分析方法
Trace 数据分析工作流
光有 Trace 不够,要会“读”Trace。下面是几个能省时间的姿势。
1. 与 IDA 的 CFG 交叉对照
IDA 给你的控制流图(CFG)是所有可能的路径,而你真正在乎的是这次执行走的路径。Trace 的作用就是把前者筛成后者。
具体做法:在 IDA 里打开目标函数切到 Graph 视图,把 trace 里所有出现过的地址(通常只看每个 basic block 的入口地址就够)提取出来,写个小脚本或手动用 IDA 的 Python 接口把这些 block 标红:
# IDAPython 代码片段
hit_blocks = set() # 从 trace 解析得到
for addr in hit_blocks:
idc.set_color(addr, idc.CIC_ITEM, 0xFFC0C0) # 淡蓝色 (IDA 用 24-bit BGR, 这是 RGB(192,192,255))
标完之后对比:被染色的是实际执行路径,未染色的是静态存在但本次执行没走的分支。这个差异对 OLLVM 控制流平坦化样本几乎是救命的——OLLVM 会把一个函数的所有 block 塞进一个巨大的 switch(state) 循环,静态看几百个 case 密密麻麻,但实际每次执行只跳 5-10 个 case。标红之后你可以直接把未染色的 case 从分析中略掉,剩下的就是真正的业务逻辑。
这个方法还有个升级版:跑两次不同输入的 trace,染色时用不同颜色,对照能看出“哪些 block 是常量路径(两次都走)、哪些 block 是数据依赖(只在某一次走)”——这正好和第 3 条 diff 思路衔接上。
2. 在 Trace 中搜索关键常量
几乎所有标准加密算法都带有“指纹常量”,即使被混淆过,常量表本身很难改(改了算法就错了)。常见的几种:
63 7C 77 7B F2 6B 6F C5 | ||
6A09E667 BB67AE85 3C6EF372 A54FF53A | ||
67452301 EFCDAB89 | ||
67452301 EFCDAB89 98BADCFE 10325476 | ||
expand 32-byte k | ||
243F6A88 85A308D3 |
在 Trace 文件里直接 grep 这些常量:
# 搜 SHA-256 初始值(注意 Trace 里的 hex 格式)
grep -nE "0x6a09e667|6a 09 e6 67" trace.txt
# 搜 AES S-Box 起点
grep -n "0x637c777b" trace.txt
有两个细节容易踩坑。第一是字节序:ARM64 是小端,内存里存的 0x6a09e667 在 trace 里按内存顺序 dump 时是 67 e6 09 6a,直接搜 6a 09 e6 67 可能搜不到。解决办法是同时搜两种字节序,或者固定搜“立即数”形式(编译器把常量编到 movz/movk 指令里时不考虑字节序,按数值搜)。第二是常量拆分:某些编译器会把 0x6a09e667 拆成两条指令 movz w8, #0xe667 + movk w8, #0x6a09, lsl #16 来加载,grep 整数搜不到,要搜 0xe667 或 0x6a09 这种半字,再人工确认上下文。
搜到命中行之后,看它的指令地址——这往往就是加密算法的入口或者 round 函数的开头。拿这个地址到 IDA 里交叉引用一下,通常能一眼锁定算法函数。
3. Diff 两次 Trace 找数据依赖点
这是 Trace 分析里最强的一招,几乎可以独立解决“白盒混淆算法的结构还原”问题。
流程分四步:
选两份差异最小的输入。比如 input_A = "aaaaaaaaaaaaaaaa"、input_B = "baaaaaaaaaaaaaaa"——只差 1 个字节。差异越小,产生的 trace diff 就越精确;差异太大你得到的 diff 满屏都是受影响的指令,反而不好分析。分别跑一次,生成 trace_A.txt和trace_B.txt。两次执行要确保除输入外其他条件完全一致——这就是第十三篇讲“固定随机”那一套操作的用武之地:如果你没固定随机,两次 trace 会因为 rand() 不一样而产生大量误报 diff。diff -u trace_A.txt trace_B.txt > trace_diff.txt,得到差异文件。分析 diff:每一行不同,都是“这条指令的执行在 A/B 两次间不一样”。具体可分三种情况—— 地址相同、寄存器值不同:这条指令的数据依赖输入,是算法的“计算部分” 地址不同:执行路径本身就走岔了(input 触发了不同分支),是算法的“分支部分” 一侧有、一侧没有:某一路执行了额外的代码(比如 input 的长度不同导致 loop 多跑几次)
把这些 diff 行按地址聚合,你就得到一份“受输入影响的指令清单”——这个清单就是算法的数据依赖图。白盒 AES / 魔改 MD5 这种“看不懂的混淆”,用 diff 法基本能把它降维到一个能分析的规模。
一个可以直接用的 diff 脚本:
# 只保留"地址 + 寄存器变化"两列, 忽略时间戳
import re
defcanonicalize(line):
m = re.search(r'\[0x([0-9a-f]+)\]\[[^\]]+\]\[0x([0-9a-f]+)\]\s+"([^"]+)"\s*(.*)', line)
returnf"{m.group(2)}{m.group(3)}{m.group(4)}"if m else line
跑完规整化再 diff,才能避免时间戳等无关列把 diff 淹了。
4. 关注分支指令的 Taken/Not Taken
CPU 的分支指令(b.eq / cbz / tbz / cbnz ...)在 trace 里长得和普通指令一样,就是一行汇编。但紧随其后的那一行的地址,隐含地告诉你“这次跳转有没有被采纳”——如果下一行地址是“分支目标地址”,就是 taken;如果是“分支指令地址 + 4”(顺序执行的下一条),就是 not taken。
写个脚本扫一遍整份 trace,把所有“分支指令 → 下一条实际地址”的对应关系提取出来,再按分支地址聚合:
# 伪代码
taken_map = {} # {branch_addr: [taken_count, not_taken_count]}
prev = None
for line in trace:
if prev and is_branch(prev):
branch_addr = prev.addr
next_addr = line.addr
taken = (next_addr == prev.branch_target)
taken_map.setdefault(branch_addr, [0, 0])[0if taken else1] += 1
prev = line
聚合结果里你会发现几种有用的模式。单次执行里全部 taken / 全部 not taken 的分支,说明它在本次执行里是“确定分支”——很可能是反检测的 always-true 检查(比如 if (1) 被混淆成了依赖某个常量的 cmp)。taken/not_taken 比例接近 1:1 的分支通常是循环的边界判断(例如 while 里的计数器比较),可以用来估算循环次数。极度不对称(比如 999:1) 的分支是异常处理路径,可以直接忽略。
做了这一步你实际上是从 trace 里重建了一份“运行时控制流图”,比 IDA 的静态 CFG 准确得多——静态 CFG 包含所有可能路径,运行时 CFG 只包含真正走过的路径。两者 diff 一下就能发现哪些分支静态存在但运行时从不触发,那些往往就是反检测预埋的诱饵分支。
Backend 限制:只有 Unicorn 系列支持 Trace
最后一个非常重要的提醒:
Trace 功能只在 Unicorn / Unicorn2 backend 上可用。
Dynarmic 为了性能,完全去掉了指令钩子。如果你之前为了速度切到了 Dynarmic,现在想 Trace,得切回来:
emulator = AndroidEmulatorBuilder.for64Bit()
.setProcessName("com.xxx")
.setRootDir(rootDir)
.addBackendFactory(new Unicorn2Factory(true)) // 必须 Unicorn2 / Unicorn
.build();
这是个性能 vs 可观察性的取舍,也是 Unidbg 全系列里最经典的“两害相权”。想理解为什么非此即彼,得先看两种 backend 的设计哲学:Unicorn2 是解释执行,每条指令都过一次钩子入口,所以它可以把“执行前”“执行后”“内存读写”等事件全部通过回调广播出来;Dynarmic 是动态翻译,会把一段 basic block 编译成 host 机器码然后直接跳过去执行,中途没有统一的入口可以挂钩子,要强行切进 trace 等于让 JIT 作废,性能收益就全没了——这不是工程偷懒,是 JIT 框架的物理上限。
两者的性能差距大致可以用下面这张经验表衡量:
一次 Trace 慢 10 倍是常态,再叠加输出重定向,样本能否跑完就取决于输入规模。经验判据是:输入只改 1 byte、函数体不超过 10 万条指令、能把 Trace 限到 100 字节范围以内,这三条成立时为了 Trace 切到 Unicorn2 完全值得;反之只要有一条不成立,就会发现开一次 Trace 要 10 分钟、打出几百 MB 日志、然后分析一上午才找到关键的那几行——这时候换个思路,先用函数级 Trace 找粗范围,再在 Console Debugger 里人肉单步,反而更划算。
最佳工作流因此分成两段:分析阶段用 Unicorn2 + 全量 Trace,把算法、执行流、关键地址都摸清楚,把对照表做出来;量产阶段切到 Dynarmic,不开 Trace,只保留业务所需的 Hook。这样既能吃到分析期的可观察性,又能在部署时拿到 10 倍的吞吐。第三篇讲后端选型的时候我们就提过这事,这里在 Trace 语境下再强调一遍:可观察性从来不是白嫖,每一条 Trace 日志背后都是真金白银换来的 CPU 周期。
总结
Emulator.traceCode(begin, end) | ||||
Debugger.traceFunctionCall(listener) | ||||
Emulator.traceRead/traceWrite(begin, end) |
用 Trace 的心法:
函数级先看大局:粗看一遍整体调用流,关键函数定位下来(要可视化嵌套就自撸 CallTreeListener)指令级看细节:把范围缩到关键函数几百字节,看寄存器、分支判断 内存级补数据流:圈定算法相关地址段(S-Box / 密钥 buffer),追读写 配合 IDA 反过来标注代码
Trace 三件套始终要做的事:
输出重定向到文件,不刷屏 用 Unicorn / Unicorn2 backend,Dynarmic 没法 Trace 缩范围,不要全量 Trace

