—— MoE、Speculative Decoding、RAG 与推理并行/显存瓶颈
在前文大模型“表示-架构-训练-推理-对齐”技术路线基础上,本文介绍现代大模型系统里最关键的四个工程问题。分别回答四个现实问题:
参数怎么继续变大而不让每个 token 的计算同步爆炸?—— MoE(混合专家模型)
推理怎么更快?—— Speculative Decoding(推测解码)
模型不知道企业私有知识时怎么办?—— RAG(Retrieval-augmented Generation,检索增强生成)
部署时常常不是算力先满,而是显存先爆?—— 推理并行与显存管理
如果说 Transformer 概念介绍解释了“模型为什么能理解上下文”,那么这四块解释的是“现代大模型为什么能在工程上跑得起来、跑得更快、接上真实知识,并扩展到更大规模”。它们是系统能力真正落地时的硬约束。以实现“成本、速度、知识、部署”四个工程目标。主题 | 核心问题 | 一句话理解 |
MoE | 参数规模继续扩大时,如何不让每个 token 的计算量同比例上升 | 让每个 token 只激活少数专家,做到“总参数大,单次计算稀疏” |
Speculative Decoding | 目标模型太慢时,如何减少每个 token 的等待 | 先让小模型猜,多 token 一次性由大模型验证 |
RAG | 模型参数里没有的最新/私有知识怎么接进来 | 先检索,再把外部片段塞进提示词,由模型基于上下文作答 |
推理并行与显存 | 为什么部署时常常不是 GPU浮点运算能力不够,而是显存不够 | 因为权重、KV Cache、批处理和通信开销共同构成了推理瓶颈 |
一、MoE:参数变大,但每个 token 的计算不必同比例变大
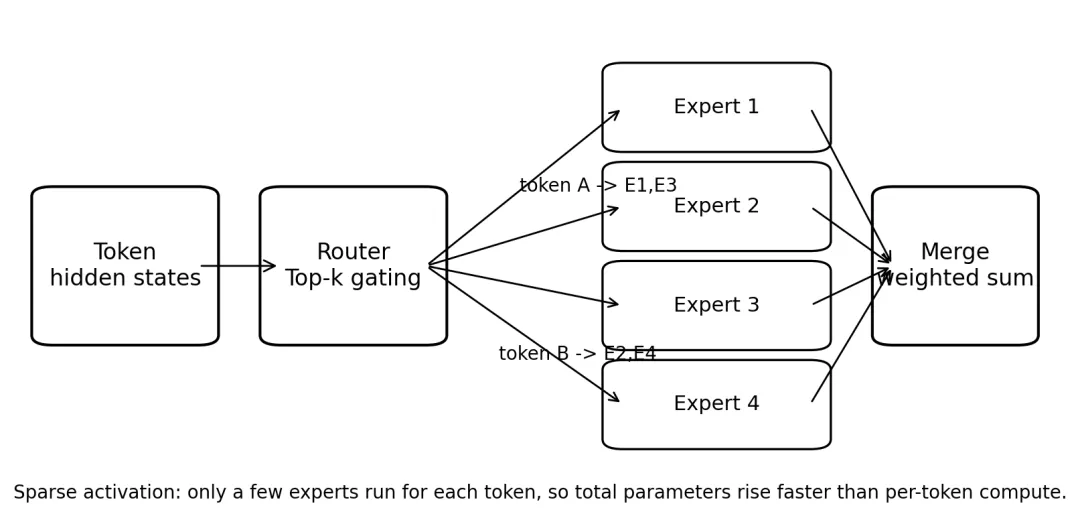
在传统稠密 Transformer 里,每一层前馈神经网络(FFN)的参数都对每个 token 生效。也就是说,只要你把参数规模扩大,几乎意味着每个 token 的前向计算量也随之上升。MoE 的思路不是把所有参数都算一遍,而是把一部分 FFN 替换成多个“专家网络”,再用一个路由器决定当前 token 应该送去哪些专家。于是,模型的“总参数量”可以很大,但对单个 token 来说,只会真的经过其中少数几个专家。这个结构的关键不在“专家”三个字,而在“稀疏激活”。从计算图角度看,MoE 不是让一层更复杂,而是让一层变成一个条件计算系统:不同 token 走不同路径。图 1MoE 的直观结构:Router 决定 token 进入哪些专家,最后再合并输出1. MoE 的最小计算逻辑
假设一层里有 N 个专家,每个专家本质上都可以看成一个独立的 FFN。输入 token 的隐藏状态 h 先经过 router,得到一个对各专家的打分向量 g。接着只保留 Top-k 个得分最高的专家,例如 k=2。于是,这个 token 只会被送到 2 个专家,而不是全部 N 个专家。如果记被选中的专家集合为 S,那么该层输出可以写成:y = Σ_{i∈S} α_i · Expert_i(h)。这里 α_i 是 router 给出的归一化权重。这个公式背后的意思非常直接:不是所有专家都被平均调用,而是“谁更适合处理当前 token,谁来算”。2. MoE 真正解决的不是“更聪明”,而是“更划算”
如果把稠密模型比作一家所有员工都要参与每个项目的公司,那么 MoE 更像一个总人数很大、但每个项目只调少数专业小组的组织。这样做的收益是:总参数量上去后,模型容量变大;但单 token 的实际计算量接近“少数专家 + 路由器”的成本,而不是全部专家总和。
这也是为什么很多 MoE论文会同时强调两件事:第一,总参数量大幅增加;第二,activeparameters per token 相对可控。前者决定模型容量,后者决定推理成本。读文章时这两个量必须分开看。
3. MoE 的难点:路由会不会失衡
如果 router 总把大多数 token 派给少数几个专家,就会出现“热门专家过载、冷门专家闲置”的问题。这样一来,一方面训练不稳定,另一方面并行效率很差,因为少数设备成为瓶颈。于是,MoE 通常要额外加负载均衡损失,鼓励不同专家都被用到。另一个常见问题是容量限制。每个专家在一个 batch 内通常会设一个容量上限;超过上限的 token 可能被丢弃、回退或重路由。这说明 MoE 不是纯粹的模型结构问题,它同时是批处理调度问题。4. 读技术文章时要盯住的几个关键词
关键词 | 它真正意味着什么 |
Top-1 / Top-2 routing | 每个 token 激活几个专家,决定稀疏程度与计算成本 |
Load balancing loss | 防止 router 把 token 挤到少数专家 |
Shared expert | 保留一部分“公共专家”,降低完全稀疏路由的训练不稳定 |
Expert parallel | 专家分散在不同设备上,需要通信把 token 送到对应设备 |
Active params | 总参数里当前 token 真的用到多少 |
二、Speculative Decoding:为什么可以一次确认多个 token
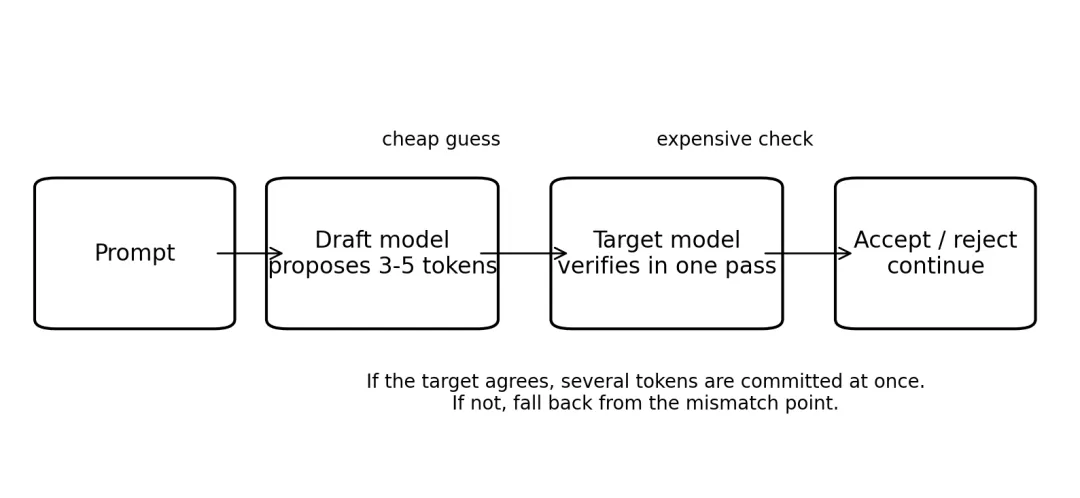
自回归推理最慢的地方在于“串行”。目标模型每次只吐出一个 token,而下一个 token 必须等待上一个 token 确认后才能开始。即便 GPU 很强,这个串行依赖仍然限制了端到端时延。Speculative Decoding 的核心想法是:让一个更便宜的小模型先往前猜几步,再由大模型一次性验证这些候选。这里的关键不是让小模型代替大模型,而是把“小模型的便宜”和“大模型的准确”叠起来。只要小模型猜得足够接近,大模型就可以在一次前向里确认多个 token,相当于把原本逐 token 的等待压缩。图 2Speculative Decoding:先猜,再批量验证1. 快在哪里
假设草稿模型(小模型)先给出 4 个候选 token。目标模型随后基于同一上下文做一次更大的前向计算,并检查这 4 个位置是否与自身分布兼容。如果兼容,就相当于一次确认了多个 token;如果在第 3 个 token 开始不兼容,那么前 2 个仍可以被接受,后面从分歧点重新开始。因此,速度提升来自“目标模型调用次数减少”,而不只是运算次数下降。它优化的是大小模型串行步数,而不是简单减少每一步的算量。对延迟敏感的在线场景,这种差别尤其重要。2. 什么时候收益高,什么时候收益低
如果草稿模型和目标模型分布接近,接受率就高,收益明显;如果草稿模型太弱,候选常常被拒绝,反而平添一次额外草稿计算。于是,Speculative Decoding 的工程本质是一个匹配问题:草稿模型要足够便宜,但又不能和目标模型差太远。它对代码补全、格式化强、语言模式稳定的任务往往更友好;对开放式创作、极强推理、分布突变大的任务,接受率可能下降。读评测时要同时看 token/s 和 acceptance rate,而不是只看其中一个。3. 它与 KV Cache 的关系
Speculative Decoding 不是替代 KV Cache。KV Cache 解决的是“已经算过的前文别再算一遍”,而 speculative 解决的是“能不能减少必须等待的大模型步数”。前者减少重复计算,后者减少串行轮数。它们在高性能推理系统里往往是叠加使用。三、RAG:模型不知道的知识,不一定要塞回参数里
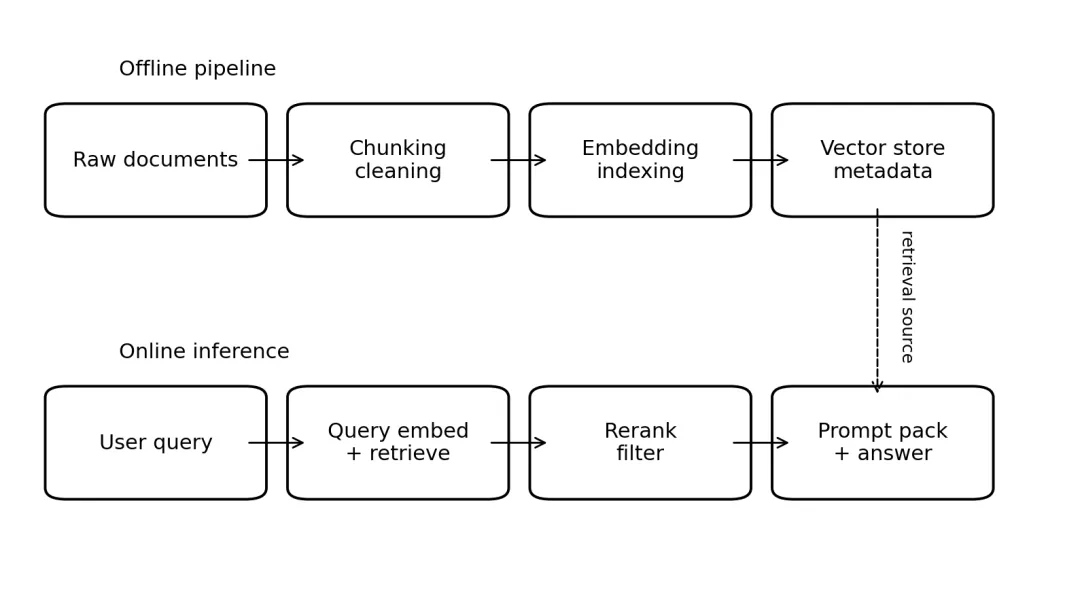
很多人第一次接触 RAG,会把它理解成“把数据库接到模型上”。这不算错,但太粗。更准确地说,RAG 是把“知识获取”拆成两个阶段:先在外部知识库中检索相关片段,再把检索结果作为上下文喂给生成模型。它不是让模型参数本身记住更多,而是让模型在回答前先拿到一份临时参考材料。所以 RAG 不是主干模型训练技术,而是系统编排技术。它非常适合解决三类问题:知识更新频繁、知识属于私域、回答必须可追溯。企业知识库问答、文档助手、代码库助手,大多落在这个范围里。图 3RAG 的典型架构:离线建库 + 在线检索/重排 + 生成1. 离线阶段:真正决定上限的是“怎么切”,不是“有没有库”
离线阶段通常包括清洗文档、切 chunk、为 chunk 生成 embedding、写入向量库,并保存标题、时间、权限、来源等元数据。这里最关键的常常不是 embedding 模型本身,而是 chunk 设计。切得过大,召回时夹杂太多噪声;切得过小,语义断裂,模型拿到的片段拼不出完整结论。因此,很多高质量 RAG 系统都会把 chunking 当成知识工程来做,例如按标题层级切、按段落语义切、保留重叠窗口、为表格和图注单独建索引,甚至为 FAQ 和流程文档采用不同切分策略。2. 在线阶段:检索不是终点,重排才更接近答案
在线阶段一般是:把用户 query 向量化,先做粗召回,再做 rerank。粗召回要解决“别漏掉”,重排要解决“别把噪声放到前面”。如果只有向量相似度而没有 rerank,系统很容易拿回“主题接近但并不回答问题”的段落。高质量 RAG 还会在 prompt 组装时做很多限制,例如去重、按来源排序、限制总 token 数、保留出处、区分背景资料和强证据。换言之,RAG 不是把 10 段文本一股脑塞进去,而是要像编辑一样,先筛选,再排版。3. RAG 与微调不是替代关系
维度 | RAG | 微调 / Continued pretraining |
改变了什么 | 外部上下文 | 模型参数 |
适合什么 | 知识更新频繁、需引用来源 | 风格、格式、任务模式稳定 |
更新成本 | 重建索引即可 | 需要再训练 |
可追溯性 | 较强,可附引用 | 较弱,知识写进参数后难追踪 |
局限 | 检索错误会直接污染回答 | 训练成本高,更新慢 |
4. RAG 最常见的失败,不是模型幻觉,而是系统前面就取错了料
很多所谓“模型幻觉”,实际发生在检索阶段:没召回、召回错、重排错、权限错、文档过旧、chunk 被截断。等上下文进到模型时,模型往往只是尽力在已有材料上进行语言组织。于是,排查 RAG 质量时不能只看最终回答,而要沿着 query -> recall -> rerank -> prompt pack -> answer 的链路逐层看。工程上常用的指标包括 Recall@k、MRR、上下文命中率、引用正确率、答案可归因率。只看人工主观“答得像不像”是不够的。四、推理并行与显存瓶颈:常常不是算力先满,而是显存先爆
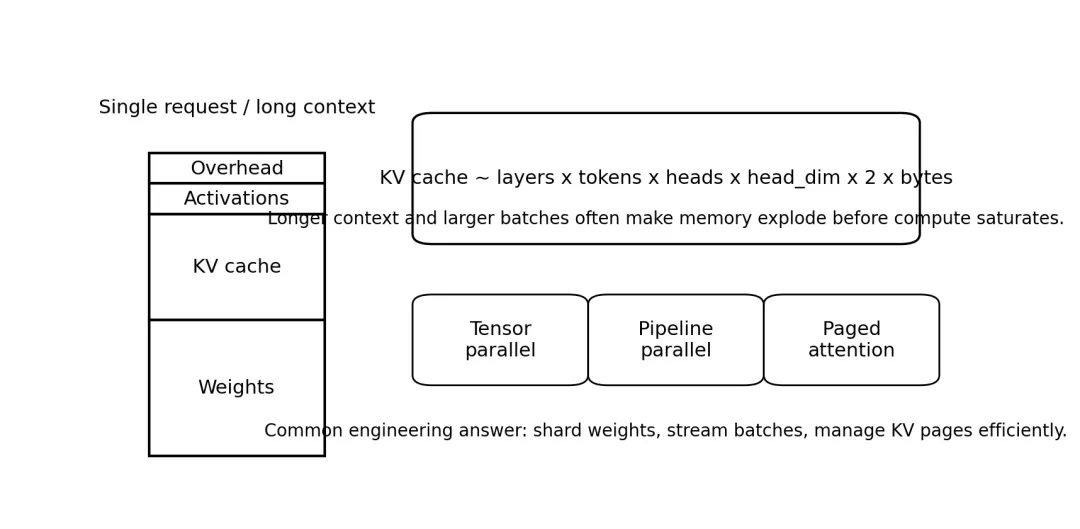
训练阶段大家习惯讨论浮点运算次数、吞吐、优化器状态;到了推理阶段,真正把系统卡住的常常是显存和通信。原因很简单:在线服务不是单条请求顺序执行,而是很多不同长度、不同上下文、不同生成步数的请求同时涌进来。此时,GPU 不只是装模型参数,还要装 KV Cache、批处理队列、临时激活以及各种运行时缓冲。对长上下文模型尤其如此。随着上下文长度增加,权重大小并不会变化,但 KV Cache 会随 token 数线性增长。于是,很多场景下瓶颈从“模型有多大”转移到“上下文有多长、并发有多高”。图 4推理显存并不只由权重决定,KV Cache 往往成为主导项1. 为什么 KV Cache 会越来越大
在自回归生成里,前文 token 的 Key 和 Value 会被缓存下来,后续生成时直接复用,而不必重复计算。假设有 L 层、T 个已缓存 token、每层有 H 个注意力头、每头维度为 d,那么 KV Cache 的量级大致与 L × T × H × d × 2 成正比,最后再乘上数据类型字节数。这个公式不需要死记,但要记住它表达的趋势:层数越多、上下文越长、并发越高,KV Cache 就越重。于是,16k、32k、128k 上下文窗口不只是“模型能看更长文本”,同时也意味着推理内存和调度复杂度显著上升。2. 常见并行方式,切分对象的差异
方式 | 切分对象 | 主要代价 |
Tensor Parallel | 同一层内部的矩阵计算 | 层内通信频繁,适合单层太大装不下 |
Pipeline Parallel | 不同层分到不同设备 | 流水线气泡和跨层传递时延 |
Data Parallel | 复制整模型,分摊不同请求/样本 | 显存占用高,不解决单卡装不下 |
Expert Parallel(MoE) | 不同专家分布到不同设备 | token 路由导致 all-to-all 通信 |
Sequence / Context Parallel | 序列维度切分 | 注意力相关通信与实现更复杂 |
3. 真正高性能的在线推理,还要处理“碎片化请求”
现实中的请求不是整齐划一的。有些只输入几十 token,有些上万;有些很快结束,有些会持续生成很长。于是,服务端通常要做 continuous batching:新请求不断插入正在运行的 batch 中,而不是等整个 batch 一起结束再开下一轮。这带来另一个问题:KV Cache 会变得像一堆长短不一的内存页。如果分配不当,就会出现显存碎片和搬运开销。因此,像 PagedAttention 这样的思路,本质上是在把 KV Cache 视作分页管理对象,而不是一块连续大内存。4. 推理系统常见的三个权衡
第一是吞吐和延迟的权衡。大 batch 往往提高吞吐,但单请求等待变长。第二是量化与精度的权衡。更低比特有助于塞下更大模型或更多并发,但可能影响质量和稳定性。第三是长上下文和可服务并发的权衡。把窗口做得很长,并不意味着线上一定划算。因此,部署一个模型从来不是“把 checkpoint 放到 GPU 上”这么简单,而是在成本、延迟、吞吐、质量、并发之间找一个业务可接受点。五、总结
如果把这四块重新放回整张技术地图,可以得到一个更完整的理解:Transformer 主干解释能力从哪里来;MoE 解释模型容量如何继续放大;Speculative Decoding 解释延迟如何下降;RAG 解释外部知识如何接进来;推理并行与显存管理解释模型为什么在部署时会受到硬件与系统结构强约束。后续再读到大模型文章时,建议先判断它在回答哪个问题:是在谈“模型更会想”,还是在谈“模型更省钱、更快、更能接真实世界知识、更容易服务化”。很多看似都叫“大模型技术”,其实讨论的是完全不同层次的问题。模块 | 主目标 | 看文章时该盯什么 | 常见误解 |
MoE | 扩大模型容量而不线性放大每 token 计算 | 总参数 vs active parameters、路由方式、负载均衡 | “参数更大 = 每次推理更贵” |
Speculative | 减少目标模型串行步数 | 接受率、token/s、草稿模型成本 | “只是再加一个小模型所以必然更慢” |
RAG | 把外部知识临时接入上下文 | chunking、recall、rerank、引用质量 | “有向量库就等于做好了 RAG” |
推理系统 | 在硬件约束下把服务跑稳跑快 | KV Cache、batching、并行方式、通信 | “部署问题只是工程细节,不影响模型能力” |
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
