文件访问是仅次于 JNI 的第二高频补环境场景,但它也是**最容易被"补漏"**的通道。因为 Android 真机上文件访问失败本来就很常见,你会下意识地觉得"失败没关系" —— 而恰恰是这种默认的沉默,让反检测代码在你眼皮底下通过。
上一篇把你留在了哪里
第七篇讲完 JNI 通道之后,你已经掌握了全部补环境工作量的 90%。这一篇开始的三篇(文件 / 系统调用 / 库函数)占剩下的 10%,但它们每一个都有独特的陷阱和高价值场景。
文件系统这一篇特别值得慢慢读 —— 不是因为它技术上复杂,而是因为它在反检测对抗里占有压倒性的权重。你会看到,很多 App 抓你 Unidbg 就是靠一个 /proc/self/maps 的读取成败判断。
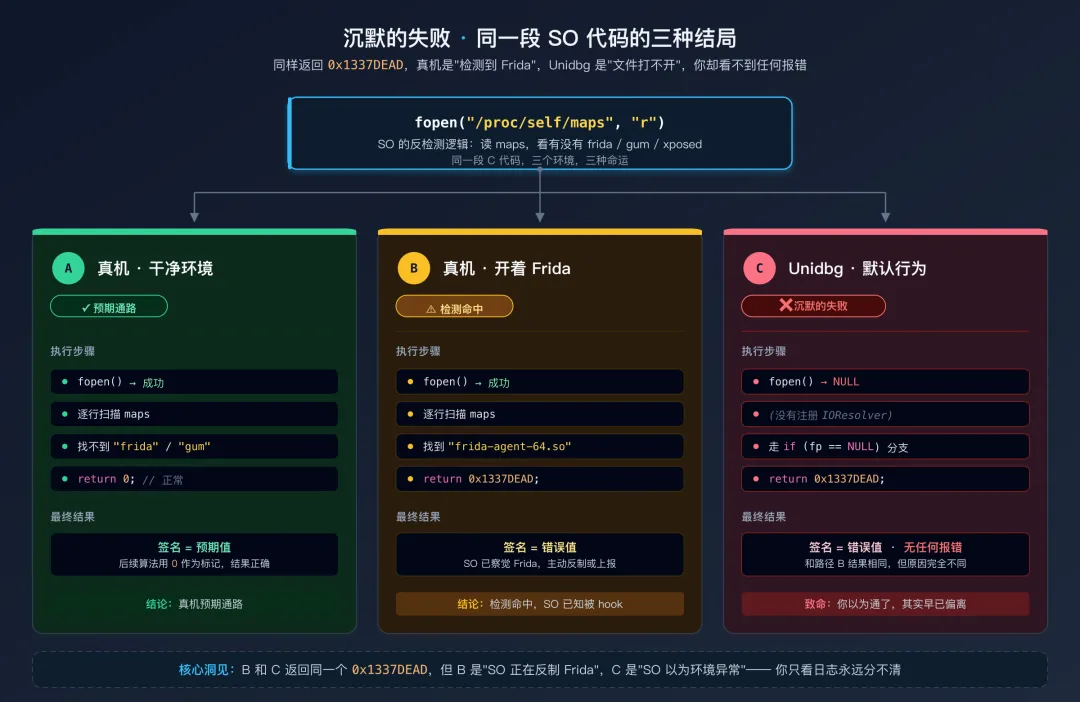
一个让你警惕的现象:沉默的失败
先看一段几乎每个新手都写过的代码:
// 新手写法: 只 override 了 AbstractJni, 完全没碰文件系统
publicclassMyAppextendsAbstractJni{
publicstaticvoidmain(String[] args){
Emulator<AndroidFileIO> emulator = AndroidEmulatorBuilder
.for64Bit()
.build();
// ... 加载 SO, 调 native 方法
// 跑完了, 没报错, 以为通了
}
}
跑起来,没有 IllegalStateException: resolve failed,没有 UnsatisfiedLinkError,最终 native 方法也返回了一个结果 —— 看起来完全通了。
但你把这个结果拿到真机上对照 Frida 抓的"标准答案",发现不一致。于是你开始怀疑是不是 JNI 值写错了、是不是哪个参数对不上。查了半天全是对的。
真相往往是这样一段代码藏在 SO 里:
// SO 内部的反检测逻辑
intcheck_frida(){
FILE *fp = fopen("/proc/self/maps", "r");
if (fp == NULL) {
// 文件打不开, 无法判断 -> 认为环境异常, 返回错误标记
return0x1337DEAD;
}
char line[256];
while (fgets(line, sizeof(line), fp)) {
if (strstr(line, "frida") || strstr(line, "gum")) {
fclose(fp);
return0x1337DEAD; // 发现 Frida, 返回错误标记
}
}
fclose(fp);
return0; // 正常
}
在真机上开 Frida,这段代码会读到含 frida 的行 → 返回错误标记;不开 Frida,读不到 → 返回 0 正常。
在 Unidbg 里呢?
- Unidbg 默认找不到
/proc/self/maps,fopen 返回 NULL
整个过程没有任何报错。Unidbg 认认真真跑完了每一行 SO 代码,你也认认真真看着它跑完 —— 但你们都不知道,有一个检测分支在你眼皮底下被触发了。
沉默的失败:同一段 SO 代码在三种环境下的三种结局这就是文件系统层补环境的核心挑战:失败是沉默的,沉默是致命的。
为什么文件访问容易被补漏
三个原因叠加,让这个通道成为盲区:
原因 1:Android 本身就很混乱
Android 的碎片化让文件访问本来就是个"测不准问题"。同一个 /sys/class/power_supply/battery/voltage_now,在不同机型、不同 Android 版本、不同 SELinux 状态下,可能存在、可能不存在、可能能读、可能 permission denied。SO 开发者也知道这一点,他们会写大量的 if (fp == NULL) return default_value 来处理不确定性。
原因 2:SO 往往会"兜底"
因为原因 1 的存在,SO 代码几乎总会给文件读取一个降级分支。Unidbg 里文件打不开时,SO 不会崩溃,它会安静地走降级。新手看到"没报错"就以为通了。
原因 3:开发者下意识觉得文件访问"无所谓"
打开文件失败,在真机上也经常发生 —— 这种直觉让你不会下意识地去盯着 fopen、access、fread。你会觉得 "noisy logging,忽略就行"。但反检测代码恰恰利用了这种轻视。
三个原因叠加的结果:你没注意到一个失败,SO 走了错分支,最终结果错了。
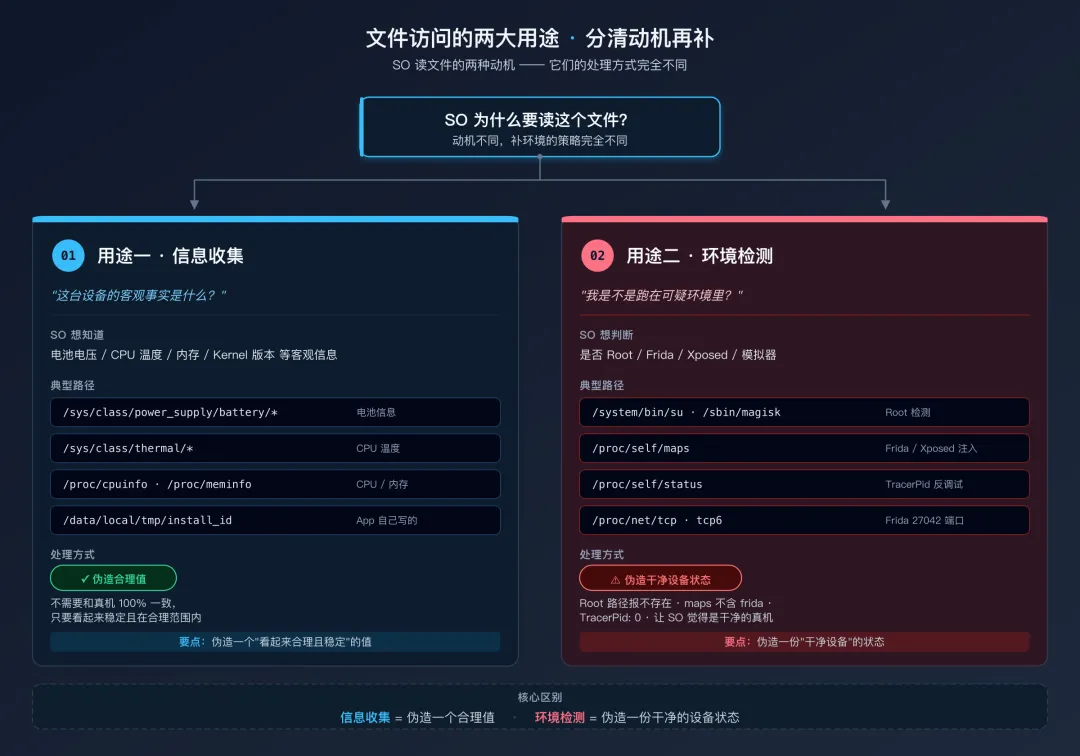
文件访问的两大用途:分清动机
要有意识地补对这个通道,第一步是分清 SO 读文件的两种动机。这两种动机的处理方式完全不同。
文件访问的两大用途用途一:信息收集
SO 想知道一个客观事实:电池电压、CPU 温度、屏幕密度、Kernel 版本 ……这些信息在 Android API 里不一定有现成的获取方式,或者获取成本较高,直接读文件更方便。
典型路径:
/sys/class/power_supply/battery/* 设备电池信息
/sys/class/thermal/* CPU 温度传感器
/proc/cpuinfo CPU 型号 / 核心数
/proc/meminfo 内存信息
/sys/block/*/size 存储容量
/data/local/tmp/install_id App 自己写的文件
处理原则:尽量伪造看起来合理且稳定的值。不用和真机 100% 一致(因为真机每次读出来也不完全一样),但必须在合理范围内。
用途二:环境检测
SO 想判断自己是不是跑在可疑环境里:有没有 Root?有没有 Frida?有没有 Xposed?是不是在模拟器里?这时候它就会去读特定的路径,看这些路径是否存在、内容是什么。
典型路径:
/system/bin/su 判断 Root (经典)
/system/xbin/su 判断 Root (备用位置)
/proc/self/maps 内存映射, 检测 Frida / Xposed 注入
/proc/self/status TracerPid 反调试
/data/data/de.robv.android.xposed/ Xposed 安装路径
/system/lib/libxposed_art.so Xposed native 库
/proc/net/tcp / tcp6 检测 Frida 的 27042 端口
/sys/devices/system/cpu/kernel_max 某些厂商检测用
/sbin/magisk 判断 Magisk
处理原则:必须让 SO 觉得"这是一个干净的真实设备"。关键是:
/proc/self/maps 必须返回一份不含 frida / xposed / riru 的内容/proc/self/status 里 TracerPid 必须是 0
核心区别一句话:
信息收集 = 伪造一个合理值;环境检测 = 伪造一份干净的设备状态
把这两种用途分清楚,你就知道自己在"补什么"了。下面进入具体的实现机制。
IOResolver:Unidbg 的文件系统钩子
Unidbg 给文件系统设计的钩子叫 IOResolver。它的定位和 AbstractJni 非常对称:
| | | |
|---|
| vm.setJni(jni) | Jni | |
| emulator.getSyscallHandler().addIOResolver(resolver) | IOResolver | |
当 SO 调 open("/proc/self/maps", O_RDONLY) 时,Unidbg 的 SyscallHandler 不会直接去读文件,而是先遍历所有注册的 IOResolver,挨个问:"你能处理这个路径吗?" 第一个给出有效回答的 resolver 赢得这次调用。
这个设计非常经典:责任链模式。你可以注册多个 IOResolver,每个负责不同的路径:
// 注册顺序决定优先级, 先注册的先被问
emulator.getSyscallHandler().addIOResolver(new ProcSelfResolver()); // 专门处理 /proc/self/*
emulator.getSyscallHandler().addIOResolver(new AntiDetectResolver()); // 专门处理反检测路径
emulator.getSyscallHandler().addIOResolver(new DeviceInfoResolver()); // 专门处理设备信息
这种分层让代码可维护,也让你可以把"反检测"和"信息伪造"分成不同模块。
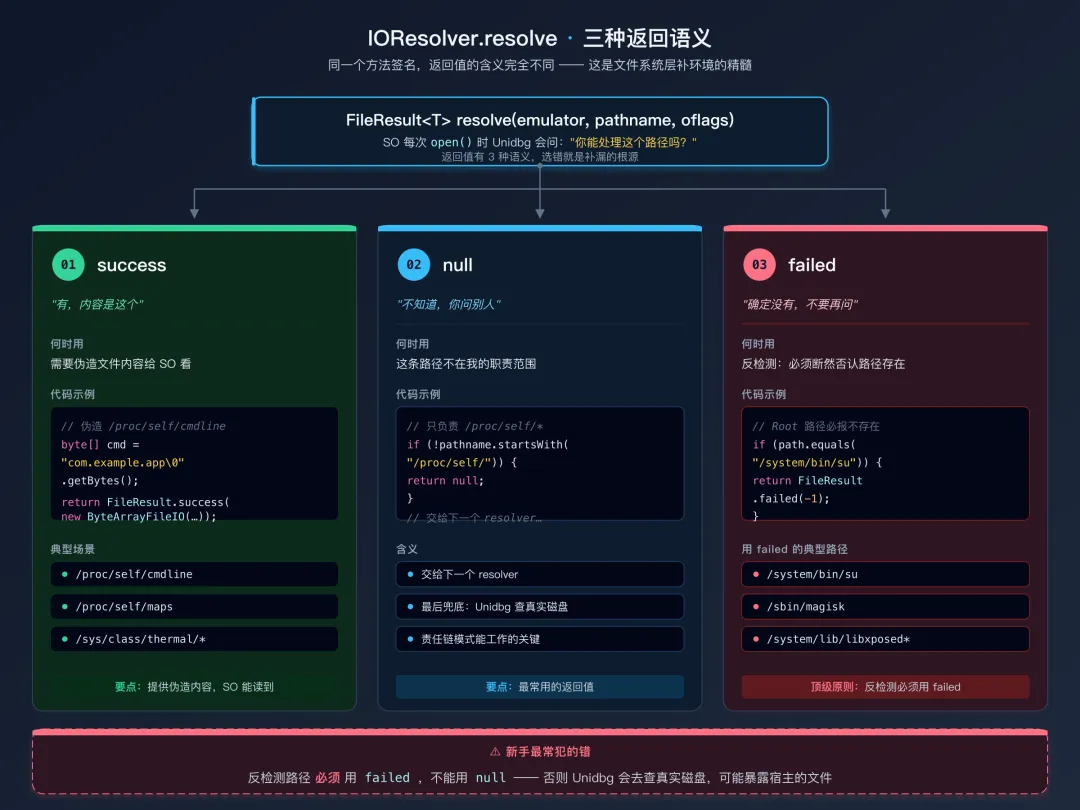
resolve 方法的三种返回语义
IOResolver 只有一个核心方法 resolve,但它的返回值有三种语义,这是整个文件系统层补环境的精髓:
IOResolver.resolve 的三种返回语义publicinterfaceIOResolver<TextendsNewFileIO> {
FileResult<T> resolve(Emulator<T> emulator, String pathname, int oflags);
}
返回值 1:一个有效的 FileResult
表示"这个路径我来处理,这是伪造的内容"。
@Override
public FileResult<AndroidFileIO> resolve(Emulator<AndroidFileIO> emulator,
String pathname, int oflags){
if ("/proc/self/cmdline".equals(pathname)) {
// 伪造进程名: 返回 App 真实的包名
byte[] cmdline = "com.example.app\0".getBytes();
return FileResult.success(new ByteArrayFileIO(oflags, pathname, cmdline));
}
returnnull; // 其它路径交给下一个 resolver 或 Unidbg 默认
}
返回值 2:null
表示"我不管这个路径,交给下一个 resolver 或 Unidbg 默认去处理"。这是最常用的返回值,也是责任链模式能工作的关键。
public FileResult<AndroidFileIO> resolve(...){
if (!pathname.startsWith("/proc/self/")) {
returnnull; // 不是我负责的范围
}
// ... 处理 /proc/self/* 路径
}
返回值 3:FileResult.failed()
最容易被忽略但最重要的一种返回。含义是:"这个路径确定不存在,不要再交给后续任何 resolver,也不要让 Unidbg 去查真实文件系统。直接告诉 SO 这里没有。"
public FileResult<AndroidFileIO> resolve(...){
// 反检测: Root 相关路径必须报不存在
if (pathname.equals("/system/bin/su")
|| pathname.equals("/system/xbin/su")
|| pathname.equals("/sbin/magisk")) {
// FileResult.failed 告诉 SO "这里没有这个文件"
// 返回 null 会让 Unidbg 去查真实磁盘, 你可能不小心把主机的 /sbin 暴露出去
return FileResult.failed(-1);
}
returnnull;
}
为什么不能用 null 代替 FileResult.failed?
因为 null 的语义是"我不管,你去问别人"。如果后面没有其他 resolver,Unidbg 会尝试去读真实磁盘。万一你的开发机恰好有 /sbin/magisk(别笑,Mac 上还真有一些 /sbin 下的东西),或者 Unidbg 内置的某些兜底把这个路径当存在,你的"反检测"就失效了。
记住这个三元关系:
| | |
|---|
FileResult.success(fileIO) | | |
null | | |
FileResult.failed(-1) | | |
补环境的一个顶级原则:**反检测路径必须用 failed,不能用 null**。这是新手最常犯的错,也是检测代码最容易利用的缝隙。
SimpleFileIO vs ByteArrayFileIO:选哪个?
IOResolver 返回的 FileResult 需要包装一个 NewFileIO 的实现。Unidbg 给了两个常用选择:
SimpleFileIO —— 从磁盘真实文件读
// 从项目资源目录下加载一个事先准备好的 cpuinfo 文件
File cpuinfoFile = new File("target/resources/device/cpuinfo");
return FileResult.success(
new SimpleFileIO(oflags, cpuinfoFile, pathname));
适用场景:
- 文件内容体积大(几 KB 到几 MB),不想塞在代码里
- 你已经从真机
adb pull 了一份真实文件,放在项目资源下
ByteArrayFileIO —— 从内存字节数组读
// 直接构造字节内容, 无磁盘 IO
byte[] cmdline = "com.example.app\0".getBytes();
return FileResult.success(
new ByteArrayFileIO(oflags, pathname, cmdline));
适用场景:
- 内容需要动态生成(比如每次根据当前 PID 计算)
选择原则:
内容 > 1KB 且固定 → SimpleFileIO (文件准备一次, 永久复用)
内容 < 1KB 或需要动态生成 → ByteArrayFileIO (代码中直接构造)
大多数反检测场景用 ByteArrayFileIO,因为反检测相关的文件通常很小;大多数设备信息伪造用 SimpleFileIO,因为 /proc/cpuinfo、/proc/meminfo 之类的文件内容较长。
proc 伪文件系统深入:最关键的一片战场
/proc 值得单独拉一章出来讲,因为它不是普通文件系统。
它的特殊之处:内核动态生成
/proc 是 Linux 内核提供的一个伪文件系统。里面的文件不在磁盘上,它们是内核根据当前进程状态动态生成的。每次你 cat /proc/self/status,内核都重新跑一段代码,把当前进程的信息格式化成文本丢给你。
这意味着两件事:
- 你不能一字不改地把真机
adb pull /proc/self/status 的内容直接塞给 Unidbg —— 因为 self 指向真机当时的某个进程,里面的 Pid / Tgid 和你 Unidbg 里的不一样,直接复用会穿帮。正确做法是把它当模板,保留大部分原始字段,只按 Unidbg 当前运行时动态替换 Pid / Tgid / TracerPid 等几个关键行(见下文 /proc/self/status 的"进阶技巧") - Unidbg 必须手动模拟每个关键 proc 文件的输出
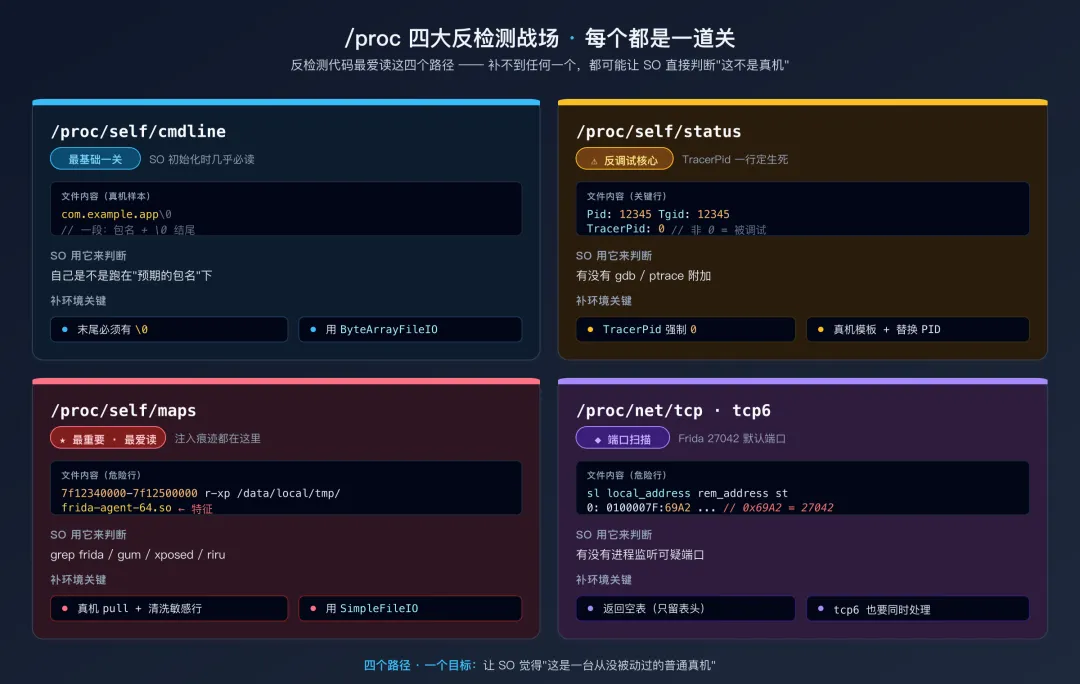
下面是反检测代码最关心的四个 proc 路径。逐一拆。
/proc 四大反检测战场:cmdline / status / maps / net/tcp 的全景导航/proc/self/cmdline — 进程名
这是反检测里最基础的一道关。很多 SO 在初始化时会读这个文件,确认自己跑在"预期的包名"下。如果读出来的进程名不对,SO 会怀疑是被注入到其他进程。
if (pathname.equals("/proc/self/cmdline")) {
// 注意: cmdline 的格式是 argv 各段用 \0 分隔, 末尾也要有一个 \0
// 对大多数 App 来说只有一段: 包名\0
String packageName = "com.example.app";
byte[] cmdline = (packageName + "\0").getBytes(StandardCharsets.UTF_8);
return FileResult.success(new ByteArrayFileIO(oflags, pathname, cmdline));
}
新手陷阱:很多人写成 packageName.getBytes(),忘记末尾的 \0。大部分 SO 用 read 读到 EOF 就停,可能没事;但用 strlen 找结束符的 SO 会读到后续的随机内存,行为未定义,下次跑不同的结果。末尾的 \0 不是可选的。
/proc/self/status — TracerPid 反调试
/proc/self/status 里有一行关键字段:TracerPid: 0。这个值不为 0 就表示有调试器(比如 gdb、ptrace 附加)正在跟踪这个进程。反调试代码会读这一行,看到非 0 就终止。
真机上的 status 文件内容大约 50 行,包含名称、状态、PID、内存占用等信息。Unidbg 里你必须构造一份包含正确 TracerPid: 0 的内容:
if (pathname.equals("/proc/self/status")) {
// 构造一份完整的 status, 关键是 TracerPid 必须是 0
StringBuilder sb = new StringBuilder();
sb.append("Name:\tcom.example.app\n");
sb.append("State:\tS (sleeping)\n");
sb.append("Tgid:\t12345\n");
sb.append("Pid:\t12345\n");
sb.append("PPid:\t1\n");
sb.append("TracerPid:\t0\n"); // !!! 这一行是重点 !!!
sb.append("Uid:\t10101\t10101\t10101\t10101\n");
sb.append("Gid:\t10101\t10101\t10101\t10101\n");
// ... 其它字段, 可以从真机 pull 一份作为模板
byte[] content = sb.toString().getBytes(StandardCharsets.UTF_8);
return FileResult.success(new ByteArrayFileIO(oflags, pathname, content));
}
进阶技巧:正确姿势不是从零手写,而是用真机做模板、按运行时打补丁:
- 在真机上
adb pull /proc/self/status 拿到一份真实样本 - 在 Unidbg 里用
emulator.getPid() 拿到当前运行时 PID - 只替换
Pid / Tgid 两行为当前 PID,TracerPid 强制写 0,其他字段原样保留 - 这样既保持了"和真机完全一致的字段集",又避免了 PID 不一致被穿帮
这是"模板 + 补丁"的思路:整体抄真机(保真),关键字段动态生成(避免穿帮)。下面 /proc/self/maps 用的也是同一个套路。
/proc/self/maps — 内存映射(最重要)
这是反检测代码最爱读的一个文件。原因是 /proc/self/maps 列出了进程加载的所有共享库和内存段,如果有人注入了 Frida / Xposed / 某个 rootkit,一定会在这里留下痕迹。
# 真机上一个干净进程的 maps 片段
70a1234000-70a1500000 r-xp 00000000 103:03 12345 /data/app/.../libapp.so
70a1500000-70a1600000 r--p 002cc000 103:03 12345 /data/app/.../libapp.so
...
# 被 Frida 注入后的 maps
7f12340000-7f12500000 r-xp 00000000 00:00 0 /data/local/tmp/re.frida.server/frida-agent-64.so
7f12500000-7f12600000 r--p 001cc000 00:00 0 /data/local/tmp/re.frida.server/frida-agent-64.so
...
反检测代码只需要 grep -i "frida\|gum\|xposed\|riru",就能识破所有常见的注入。
在 Unidbg 里伪造 maps 的关键:
- 必须看起来像真实设备(有
/system/lib64/libc.so、linker64 等基础库) - 必须包含你自己的 libapp.so(SO 会在里面找自己)
- 必须不含 frida / xposed / substrate / riru 等敏感字眼
- 地址范围要合理(ARM64 用户空间大致在
0x12c00000 到 0x8000000000 范围)
实战中一般从真机 adb pull /proc/self/maps(针对一个目标 App 进程),然后:
- 替换 libapp.so 的路径为 Unidbg 下的路径(或保留原路径,反正 SO 只看基址)
- 保存为资源文件,用
SimpleFileIO 返回
if (pathname.equals("/proc/self/maps")) {
// 预先从真机 pull 并清洗过的 maps 文件
File mapsFile = new File("src/main/resources/device/clean_maps.txt");
return FileResult.success(new SimpleFileIO(oflags, mapsFile, pathname));
}
警告:直接用 Unidbg 默认返回的 maps 往往不够干净。Unidbg 会把自己加载的 ELF 段列在里面,但不会主动加入 /system/lib64/libc.so 等基础库,这种"缺胳膊少腿"的 maps 本身就是特征。真实的检测代码可能不是检测"有没有 frida",而是检测"有没有 libc.so" —— 没有就说明不是正常 Android 进程。
/proc/net/tcp 和 tcp6 — 端口检测
Frida 默认监听 27042 端口(如果你用 frida-server)或者某个随机端口(如果用 gadget)。反检测代码会读 /proc/net/tcp 看有没有进程监听这些可疑端口。
# /proc/net/tcp 的格式
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt ...
0: 0100007F:69A2 00000000:0000 0A ...
^^^^
0x69A2 = 27042, 这就是 Frida 的默认端口
反检测策略:伪造一份只包含正常端口的 tcp 内容,或者直接返回文件不存在(有些系统这个文件本来就难读)。
if (pathname.equals("/proc/net/tcp") || pathname.equals("/proc/net/tcp6")) {
// 只返回一个空表头, 表示没有任何监听的 socket
String empty = " sl local_address rem_address st tx_queue rx_queue tr"
+ " tm->when retrnsmt uid timeout inode\n";
return FileResult.success(new ByteArrayFileIO(oflags, pathname,
empty.getBytes()));
}
PID 一致性问题:一个隐蔽的坑
接着上面 /proc/self/status 的话题讲一个特别容易踩的坑。
Unidbg 的 PID 来自哪里
Unidbg 没有"进程"的概念。它是一个 Java 库,跑在宿主 JVM 里。但 SO 代码可能会调 getpid() 或 getppid()。Unidbg 怎么办?
它返回宿主 JVM 的 PID。
// Unidbg 内部: UnixSyscallHandler.getpid
@Override
publicintgetpid(Emulator<?> emulator){
// 直接返回 JVM 进程 PID, 每次运行都不一样
return android.os.Process.myPid(); // 实际是 ProcessHandle.current().pid()
}
这导致两个直接后果:
后果 1:每次运行 PID 都不同
你今天跑 Unidbg 拿到 PID=12345,明天拿到 PID=67890。所以任何涉及 PID 的逻辑都不能硬编码。
后果 2:不能从真机复制 /proc/12345/ 下的任何内容
新手常干的事:从真机 adb pull /proc/self/ 一堆文件,然后在 IOResolver 里做路径匹配:
// 错误写法!
if (pathname.equals("/proc/12345/status")) { // 真机当时的 PID
return FileResult.success(...);
}
这段代码永远不会被触发,因为 Unidbg 里 /proc/self/ 被解析成 /proc/{当前 JVM PID}/,而你写死的是真机 PID。
正确的做法:动态匹配
@Override
public FileResult<AndroidFileIO> resolve(Emulator<AndroidFileIO> emulator,
String pathname, int oflags){
// 拿到当前 Unidbg 里 SO 看到的 PID
int pid = emulator.getPid();
String selfPrefix = "/proc/" + pid + "/";
// 三种形式都要拦: /proc/self/xxx, /proc/{pid}/xxx, 以及简写
if (pathname.startsWith("/proc/self/") || pathname.startsWith(selfPrefix)) {
// 提取最后一段文件名, 比如 "status" / "maps" / "cmdline"
String filename = pathname.substring(pathname.lastIndexOf('/') + 1);
return handleProcSelf(filename, pathname, oflags);
}
returnnull;
}
private FileResult<AndroidFileIO> handleProcSelf(String filename,
String pathname, int oflags){
switch (filename) {
case"status": return buildStatus(pathname, oflags);
case"maps": return buildMaps(pathname, oflags);
case"cmdline": return buildCmdline(pathname, oflags);
// ...
}
returnnull;
}
关键点:
- 用
emulator.getPid() 拿到运行时 PID - 同时拦截
/proc/self/ 和 /proc/{pid}/ 两种前缀(SO 两种写法都可能用)
反检测实战:一份最小 IOResolver 模板
把前面所有东西串起来,这是一个覆盖大多数反检测场景的最小 IOResolver 模板。你可以直接拿去用:
publicclassAntiDetectIOResolverimplementsIOResolver<AndroidFileIO> {
// Root 相关路径, 必须报不存在
privatestaticfinal Set<String> ROOT_PATHS = new HashSet<>(Arrays.asList(
"/system/bin/su",
"/system/xbin/su",
"/sbin/su",
"/system/sd/xbin/su",
"/system/bin/failsafe/su",
"/data/local/su",
"/data/local/xbin/su",
"/data/local/bin/su",
"/sbin/magisk",
"/sbin/.magisk",
"/cache/.disable_magisk",
"/dev/.magisk.unblock"
));
// Xposed 相关路径, 必须报不存在
privatestaticfinal Set<String> XPOSED_PATHS = new HashSet<>(Arrays.asList(
"/system/lib/libxposed_art.so",
"/system/lib64/libxposed_art.so",
"/system/framework/XposedBridge.jar",
"/data/data/de.robv.android.xposed.installer/"
));
@Override
public FileResult<AndroidFileIO> resolve(Emulator<AndroidFileIO> emulator,
String pathname, int oflags){
// 1. 反检测: 确定性报"不存在"
if (ROOT_PATHS.contains(pathname) || XPOSED_PATHS.contains(pathname)) {
// !!! 用 failed 而不是 null, 防止 Unidbg 默认去查真实磁盘 !!!
return FileResult.failed(-1);
}
// 2. /proc/self/* 系列, 动态构造
int pid = emulator.getPid();
if (pathname.startsWith("/proc/self/")
|| pathname.startsWith("/proc/" + pid + "/")) {
return handleProcSelf(pathname, oflags);
}
// 3. /proc/net/tcp 系列, 空表返回
if (pathname.equals("/proc/net/tcp") || pathname.equals("/proc/net/tcp6")) {
String empty = " sl local_address rem_address st tx_queue\n";
return FileResult.success(
new ByteArrayFileIO(oflags, pathname, empty.getBytes()));
}
// 4. 其它路径交给下一个 resolver 或 Unidbg 默认
returnnull;
}
private FileResult<AndroidFileIO> handleProcSelf(String pathname, int oflags){
String filename = pathname.substring(pathname.lastIndexOf('/') + 1);
switch (filename) {
case"cmdline":
byte[] cmdline = "com.example.app\0".getBytes();
return FileResult.success(
new ByteArrayFileIO(oflags, pathname, cmdline));
case"status":
// 实际工程中这里应该加载一份预先清洗过的真机 status
return FileResult.success(
new SimpleFileIO(oflags,
new File("src/main/resources/device/status.txt"),
pathname));
case"maps":
// 清洗过的 maps, 已去除 frida/xposed
return FileResult.success(
new SimpleFileIO(oflags,
new File("src/main/resources/device/maps.txt"),
pathname));
default:
returnnull;
}
}
}
使用方式:
// 在创建 emulator 之后, 加载 SO 之前注册
emulator.getSyscallHandler().addIOResolver(new AntiDetectIOResolver());
验证闭环:怎么知道自己补对了
和前两篇一样,"跑通"不等于"跑对"。文件系统层的验证方式有自己的特点:
方法 1:Frida trace fopen / open / access
在真机上用 Frida hook 这三个函数,记录 SO 实际访问过的所有路径。对照 Unidbg 里的日志,看路径覆盖是否一致。
// Frida 脚本: 抓 SO 调用的所有文件访问
var openPtr = Module.findExportByName('libc.so', 'open');
Interceptor.attach(openPtr, {
onEnter: function(args) {
this.path = args[0].readCString();
},
onLeave: function(retval) {
console.log('[open] ' + this.path + ' => fd=' + retval);
}
});
// 类似地 hook fopen 和 access
方法 2:在 IOResolver 里加 log
@Override
public FileResult<AndroidFileIO> resolve(...){
System.out.println("[IOResolver] " + pathname + " flags=" + oflags);
// ...
}
方法 3:开 SyscallHandler 的 verbose 日志
// 让 Unidbg 打印所有 open 系统调用, 包括默认处理的
emulator.getSyscallHandler().setVerbose(true);
真正的检验:对照 Frida 抓到的路径列表和 Unidbg 实际处理的路径列表,两者必须完全一致。如果 Frida 里 SO 读了 /proc/self/maps 而 Unidbg 日志里没有,说明 Unidbg 把它兜底处理了,你没看到;或者 SO 没读到你的 resolver,说明它走了另一条路径。
总结:文件系统层的五条铁律
- resolve 三返回:success / null / failed —— 反检测必须用 failed
- ByteArray 放小的,SimpleFileIO 放大的:选错了要么性能差要么难维护
- PID 永远不硬编码:用
emulator.getPid(),同时拦截 /proc/self/ 和 /proc/{pid}/ - 沉默是魔鬼:文件访问失败不报错,必须主动 log + 对照 Frida 验证
文件系统层补不好,SO 会在你看不见的地方走错分支。一旦你建立起"每条文件访问都要明确处理"的本能,大部分反检测就不再神秘。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
