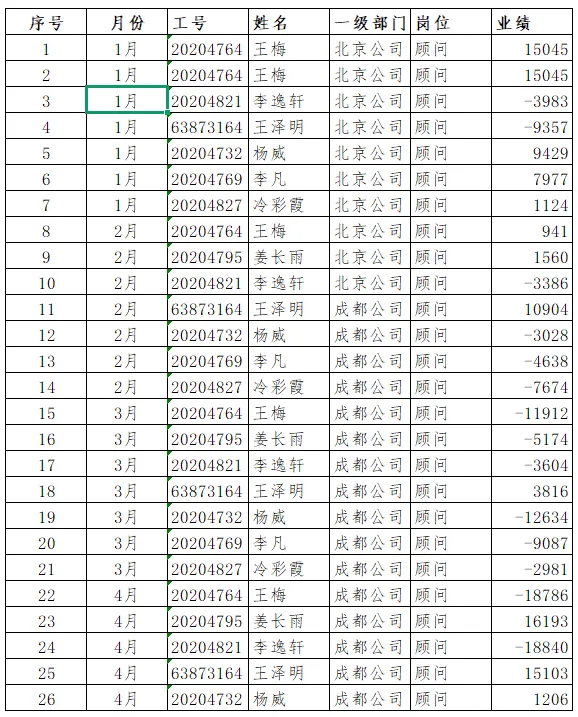
我首先想到使用xlookup函数,使用实在很方便,只说一下匹配模式和搜索模式- 匹配模式:可选,0=精确匹配(default),1=近似匹配,-1=反向近似匹配。
- 搜索模式:可选,1=从前往后(default),-1=从后往前,2=二进制搜索。
- []中括号圈起来的这几个参数不要示是必须的,也只可以不写,如果不写就没有对应的功能与要求了。
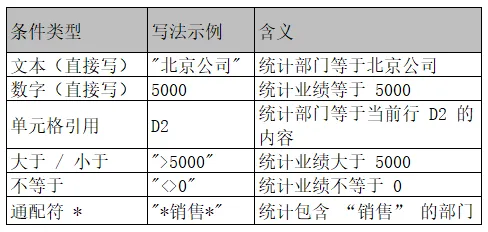
- 它还有一种模糊查找的方式,就是在查找值中加入通配符(*表示多个字符,? 表示一个字符),然后还是选择【0=精确匹配】
这里要解释一下,匹配模式中的【1=近似匹配,-1=反向近似匹配】。注意它们不是用来 找名字、工号这种精确内容的,那样的话直接用(0=精确匹配)就可以,进行档位判断、区间匹配时使用。【1=近似匹配】要求查找列必须升序排列,它找不到完全一样的,就找不超过目标值且最接近目标的那个值。举例,查找列1000,3000,5000,我要查找2500,查找逻辑,1000<2500,继续,3000>2500,停止,返回1000对应的值。而【-1=反向近似匹配】要求查找列必须降序,查找则是相反的逻辑。对于搜索模式中的【2=二进制搜索】,它要求数据是升序排列的,而-2要示数据是降序排列的,因为它使用的是二分查找的方法。还有一个长相近似的函数,vlookup,其实与hlookup可以视为亲兄弟。- 数据表即为选择要查找的区域,查找列应在第一列,而且所选区域不要包含表头。区域选择完毕后,应该通过F4将其转成绝对引用。
- 匹配条件中,0或FALSE=精确匹配,1或TRUE=近似匹配,与vlookup用法及要求相同
- 同vlookup函数一样,也有一种模糊查找的方式,就是在查找值中加入通配符(*表示多个字符,? 表示一个字符),然后还是选择【0=精确匹配】
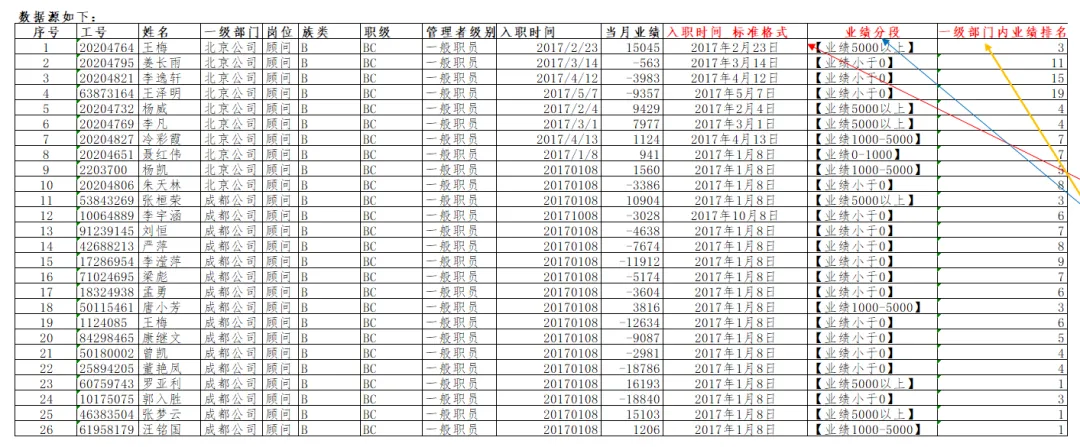
题目1.1 现在我再在此题目上申引一下,举一反三,如果我们需要通过多条件筛选才能得到想要的值:比如只通过工号不能唯一确定王梅当月业绩,还要结合姓名与部门来确定?XLOOKUP(条件1&条件2&条件3, 数据源条件列1&数据源条件列2&数据源条件列3, 要返回的列)
其实这可以视作为用字符串拼接的形式组成的查看值,查找也是去对比字符串拼接后的值。算作是字符串拼接版的xlookup查询吧。也可以用index与match的组合,我们下面来拆解它是如何发挥作用的=INDEX(要返回的列, MATCH(1, (条件列1=条件1)*(条件列2=条件2)*(条件列3=条件3), 0))
index的语法是INDEX(数据区域, 行号, [列号]),就是根据后面的索引信息(行号, [列号])返回数据区域中的具体定位值。当数据区域是一列(维)的,就看只有一个行号信息,如果是二维的面域,就根据行和列两个信息确定。match的语法是MATCH(查找值, 查找区域, 匹配类型),查找区域是一维的区域,要么是行要行是列,匹配类型可以是【0=精确匹配;1=模糊匹配(default),要求区域升序,找小于查找值的最大值;-1=模糊匹配,要求区域降序,找大于查找值的最小值】=INDEX($J:$J, MATCH(1, ($C:$C="王梅")*($D:$D="北京公司"), 0))
其中的($C:$C="王梅")*($D:$D="北京公司")返回的是一整列由 1 和 0 组成的数字,只有「同时是王梅 + 北京公司」的那一行是 1,其他所有行都是 0。这样就不难理解题目1.2,如果按照题目1.1 的条件查询找到多条记录,要求解它们的和=SUMIFS(求和区域, 条件列1, 条件1, 条件列2, 条件2, ...)
对满足条件具体来讲,现在求出北京公司,业绩分段在5000以上的总业绩和,如下=SUMIFS($J:$J, $D:$D, "北京公司", $L:$L, "业绩5000以上")
求成都公司 2017 年 1 月 1 日后入职的员工总业绩(K 列 = 标准入职时间=SUMIFS($J:$J,$D:$D,"成都公司",$K:$K,">="&DATE(2017,1,1))
// 新版Excel支持数组=SUMIFS($J:$J, $C:$C={"王梅","杨威"})// 老版Excel写法=SUM(SUMIFS($J:$J, $C:$C={"王梅","杨威"}))
题目2,请将【入职时间】字段内容按标准日期格式整理,并填入K列【入职时间标准格式】字段中,标准格式为:年/月/日=IF(ISNUMBER(--H5), IF(LEN(H5)=8, DATE(LEFT(H5,4),MID(H5,5,2),RIGHT(H5,2)),H5), DATEVALUE(H5))
-- 叫双重负号,作用是:把 “长得像数字的文本” 强行转成真正的数字- if(判断条件,满足条件执行1,不满足条件执行2)
- 将8位数字提取成日期格式,连同原本已经是日期的数据一齐转化为真日期,即日期序列号。
题目3,请将当月绩效分段展示,并在L列【业绩分段】字段中展示。区间分别为:业绩小于0为【业绩小于0】;业绩大于0并且小于等于1000归为【业绩0-1000】;业绩大于1000并且小于等于5000归为【业绩1000-5000】;业绩大于5000归为【业绩5000以上】=IF(K13<0, "【业绩小于0】", IF(K13<1000, "【业绩0-1000】", IF(K13<5000,"【业绩1000-5000】","【业绩5000以上】")))
题目4,请给出每位员工在各自的一级部门内的业绩排名,并填入【一级部门内业绩排名】字段RANK(number, ref, [order])
ref(排名的参照区域),应该是一个数字区域,并且使用绝对引用,否则会根据下拉动作,变化引用区域,区域里的文本、空白单元格会被自动忽略order指定排名是「降序(default)」还是「升序」,order 只要不是 0,不管写1还是-1,效果都是升序
=COUNTIFS(条件区域1, 条件1, 条件区域2, 条件2, 条件区域3, 条件3, ...)
# 会有并排名次出现,并且下一名会=COUNTIFS($D$2:$D$26, D2, $J$2:$J$26, ">"&J2) + 1# 下面方法改进了一下,不会出现=COUNTIFS($D$2:$D$26, D2, $J$2:$J$26, ">"&J2) + COUNTIFS($D$2:$D2, D2, $J$2:$J2, J2) # 上方重复计数的人
- COUNTIFS会数出满足当前条件的数据个数,这里是数出同部门比目标数据高的数目,最后加上1就是当前排名。
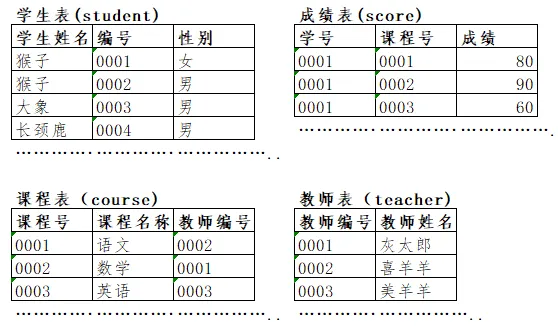
题目1,查询至少选修了2门课程的学生姓名、学生编号、选修的课程名称、带课教师的姓名及成绩
SELECT 学生姓名, 学生编号, 课程名称, 教师姓名, 成绩FROM ( SELECT s.学生姓名, s.编号 AS 学生编号, c.课程名称, t.教师姓名, sc.成绩, -- 窗口函数:按学生分组,统计每个学生的总选课数 COUNT(sc.课程号) OVER (PARTITION BY s.编号) AS 选课总数 FROM student s JOIN score sc ON s.编号 = sc.学号 JOIN course c ON sc.课程号 = c.课程号 JOIN teacher t ON c.教师编号 = t.教师编号) AS temp-- 外层筛选:只保留选课数≥2的学生记录WHERE 选课总数 >= 2;
我们对于上面出现了一个窗口函数OVER(),这里的通用语句是
聚合函数(字段) OVER ( PARTITION BY 分组字段 -- 窗口按什么划圈子 ORDER BY 排序字段 -- 可选:窗口内按什么排序) AS 别名
在上面的语句中的具体呈现为
COUNT(要数的列) OVER (PARTITION BY 按什么分组) AS 新列名# 对应上面的代码COUNT(sc.课程号) OVER (PARTITION BY s.编号) AS 选课总数
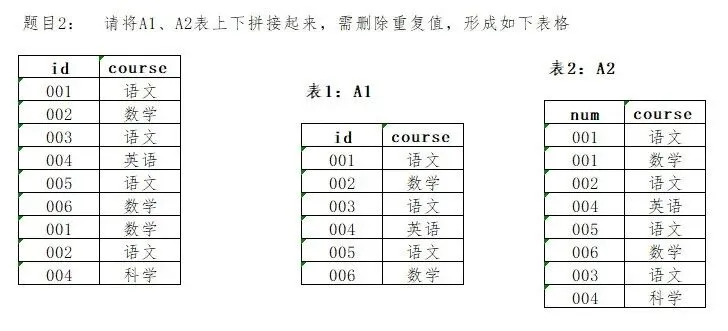
题目2,请将A1、A2表上下拼接起来,需删除重复值,形成如下表格
SELECT id, course FROM A1UNIONSELECT num AS id, course FROM A2;
题目1,假设左方的是表名为data的excel文件或者数据库表,请用python脚本读取全部数据。说明:数据库连接/文件地址可虚构题目2,数据中有重复的数据,请剔除重复项。说明:重复数据的特征是月份、工号、姓名、一级部门、岗位、业绩均一致
场景一:将文件作为 Excel 表格文件读取。我们使用最通用的 pandas 库读取,它能一键解析 Excel 并返回结构化数据,同时支持后续所有数据处理操作。import pandas as pd# ---------------------- 1. 配置文件路径(可虚构) ----------------------# 这里的文件地址是示例虚构值,实际使用时替换为你的文件真实路径file_path = "./sales_data.xlsx" # 假设Excel文件名为sales_data.xlsx,存放在当前目录sheet_name = "Sheet1" # 数据所在的工作表名,默认是Sheet1,可根据实际修改# ---------------------- 2. 读取全部数据 ----------------------# 使用pandas读取Excel文件,会自动将表格转为DataFrame(类似表格的结构化数据)df = pd.read_excel( io=file_path, sheet_name=sheet_name, header=0 # 第0行作为表头(你的表格第一行是列名,所以用header=0))# ---------------------- 3. 验证读取结果(可选) ----------------------print("数据读取成功,数据前5行:")print(df.head()) # 打印前5行数据,验证读取是否正确print("\n数据基本信息:")print(df.info()) # 查看数据类型、非空值等信息print("\n数据总行数:", len(df)) # 查看数据总行数
import pandas as pd# 1. 读取Excel数据(沿用上方代码)file_path = "./sales_data.xlsx"df = pd.read_excel(file_path, sheet_name="Sheet1", header=0)print("===== 去重前数据量 =====")print(f"总行数:{len(df)}")# ===================== 核心:剔除重复项 =====================# 只有【月份、工号、姓名、一级部门、岗位、业绩】全部相同,才判定为重复df_no_duplicate = df.drop_duplicates( subset=["月份", "工号", "姓名", "一级部门", "岗位", "业绩"], keep="first", # 保留第一条重复数据 ignore_index=True # 重置行索引)# ===================== 结果验证 =====================print("\n===== 去重后数据量 =====")print(f"总行数:{len(df_no_duplicate)}")print("\n去重后前5行数据:")print(df_no_duplicate.head())# 可选:将去重后的数据保存为新Exceldf_no_duplicate.to_excel("./去重后数据.xlsx", index=False)
场景二:将表作为数据库表读取。假设你的数据存放在 MySQL 数据库中,表名为data,我们用pymysql建立连接,配合pandas读取数据。
import pandas as pdimport pymysql# ---------------------- 1. 配置数据库连接参数(可虚构) ----------------------# 以下参数为示例虚构值,实际使用时替换为你的数据库真实信息db_config = { "host": "localhost", # 数据库地址,本地为localhost,远程则填IP "user": "root", # 数据库用户名 "password": "123456", # 数据库密码 "database": "company_db", # 数据库名,假设你的表在company_db这个库中 "port": 3306, # MySQL默认端口3306 "charset": "utf8mb4" # 字符集,避免中文乱码}# ---------------------- 2. 建立数据库连接 ----------------------# 使用上下文管理器with,自动管理连接的关闭,避免资源泄漏with pymysql.connect(**db_config) as conn: # 定义SQL语句,读取data表的全部数据 sql_query = "SELECT * FROM data;" # 读取表中所有行和列 # 使用pandas的read_sql函数,直接读取SQL查询结果为DataFrame df = pd.read_sql(sql=sql_query, con=conn)# ---------------------- 3. 验证读取结果(可选) ----------------------print("数据库表读取成功,数据前5行:")print(df.head())print("\n数据基本信息:")print(df.info())print("\n数据总行数:", len(df))
import pandas as pdimport pymysql# 1. 连接数据库并读取data表(沿用上方代码)db_config = { "host": "localhost", "user": "root", "password": "123456", "database": "company_db", "port": 3306, "charset": "utf8mb4"}with pymysql.connect(**db_config) as conn: df = pd.read_sql("SELECT * FROM data;", con=conn)print("===== 去重前数据量 =====")print(f"总行数:{len(df)}")# ===================== 核心:剔除重复项 =====================df_no_duplicate = df.drop_duplicates( subset=["月份", "工号", "姓名", "一级部门", "岗位", "业绩"], keep="first", ignore_index=True)# ===================== 结果验证 =====================print("\n===== 去重后数据量 =====")print(f"总行数:{len(df_no_duplicate)}")
题目3,按工号展示出每个工号1-4月的业绩之和,并按照业绩从高到低排序,数据结果如下,要求写出python脚本
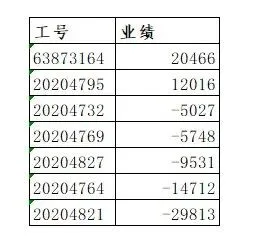
import pandas as pd# ===================== 1. 读取数据(二选一即可) =====================# --- 场景A:读取Excel文件 ---file_path = "./sales_data.xlsx"df = pd.read_excel(file_path, sheet_name="Sheet1", header=0)# --- 场景B:读取数据库表(MySQL示例) ---# import pymysql# db_config = {"host": "localhost", "user": "root", "password": "123456", "database": "company_db", "port": 3306}# with pymysql.connect(**db_config) as conn:# df = pd.read_sql("SELECT * FROM data;", con=conn)# ===================== 2. 剔除重复数据(按指定列去重) =====================df_no_duplicate = df.drop_duplicates( subset=["月份", "工号", "姓名", "一级部门", "岗位", "业绩"], keep="first", ignore_index=True)# ===================== 3. 核心:按工号分组汇总业绩 =====================# 按工号分组,汇总1-4月业绩之和grouped_result = df_no_duplicate.groupby( by="工号", # 分组依据:按工号 as_index=False # 不让工号变成索引,保留为普通列)["业绩"].sum() # 对业绩列求和# ===================== 4. 按业绩从高到低排序 =====================grouped_result_sorted = grouped_result.sort_values( by="业绩", # 按业绩列排序 ascending=False, # 降序(从高到低) ignore_index=True # 重置排序后的索引)# ===================== 5. 输出结果(和题目格式完全一致) =====================print("按工号汇总业绩(从高到低):")print(grouped_result_sorted)# 可选:将结果保存为新的Excel文件grouped_result_sorted.to_excel("./工号业绩汇总.xlsx", index=False)
# 高级封装版(1行拿数据)with pymysql.connect(**db_config) as conn: df = pd.read_sql("SELECT * FROM data;", con=conn)
其实我们通过原生游标 cursor.execute () 手写,实现完全相同的结果import pandas as pdimport pymysqldb_config = { "host": "localhost", "user": "root", "password": "123456", "database": "company_db", "port": 3306, "charset": "utf8mb4"}# 1. 建立连接with pymysql.connect(**db_config) as conn: # 2. 创建游标(底层操作必须用游标) cursor = conn.cursor() # 3. 手动执行SQL语句 cursor.execute("SELECT * FROM data;") # 4. 获取所有查询结果 data = cursor.fetchall() # 5. 获取列名(表头) columns = [col[0] for col in cursor.description] # 6. 手动转成DataFrame(和read_sql结果完全一样) df = pd.DataFrame(data, columns=columns)
关于其它方面,上面的操作如果不太懂,可以补充一下,Pandas 表格处理相关的知识。