ChatTTS:新一代中文语音合成工具原理与实战解析
在AI语音合成领域,针对中文场景优化的工具一直是开发者的刚需。ChatTTS凭借其高自然度、口语化、灵活的音色与韵律控制,成为中文TTS(Text-to-Speech)领域的热门选择。本文将从技术原理到代码实战,全面解析ChatTTS的核心逻辑,帮你吃透这款工具的底层设计与使用方法。
一、ChatTTS核心定位
ChatTTS是一款专为中文优化的端到端语音合成模型,主打口语化、高自然度、支持情感/韵律定制,相比传统TTS(如Tacotron 2、VITS早期版本),它简化了端到端的生成流程,且对中文的韵律、语气、口语习惯适配更优。其核心依赖Transformer架构(代码中固定transformers==4.53.2),无需复杂的预处理/后处理流程,即可直接从文本生成高质量的24kHz语音波形。
二、ChatTTS核心技术原理
ChatTTS的本质是基于Transformer的端到端语音合成模型,整合了文本精炼、说话人表征、可控采样推理、端到端波形生成四大核心模块,以下拆解每个模块的原理:
1. 文本精炼(Refine Text)模块:让语音更"像人说话"
传统TTS直接将纯文本转为语音,容易出现"机械感"——比如缺少停顿、口语化表达不足。ChatTTS的文本精炼模块解决了这个问题:
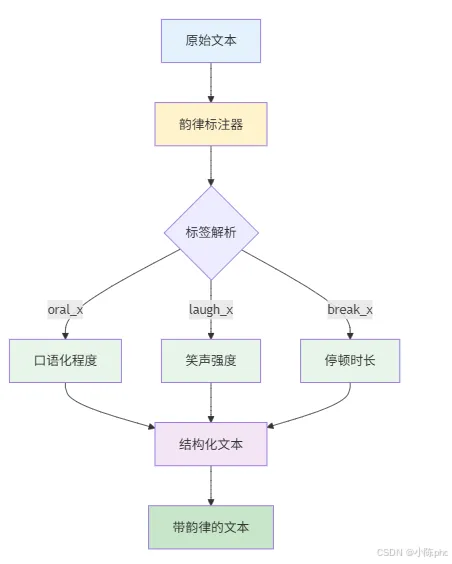
- • 核心逻辑:对输入文本进行韵律标注预处理,通过自定义标签(如
[oral_2]「口语化程度」、[laugh_0]「笑声强度」、[break_4]「停顿时长」)将纯文本转化为带"说话风格"的结构化文本。 - • 作用:模拟人类说话的韵律习惯(比如句间停顿、口语化语气),是ChatTTS语音自然度的核心保障。
- • 代码体现:
params_refine_text = chat.RefineTextParams(prompt='[oral_2][laugh_0][break_4]'),通过prompt传入韵律标签,控制文本的精炼规则。
韵律标签对照表:
| | | |
[oral_x] | | | |
[laugh_x] | | | |
[break_x] | | | |
2. 说话人嵌入(Speaker Embedding):定制专属音色
ChatTTS支持灵活的音色定制,核心是“说话人嵌入向量(spk_emb)”:
- • 核心逻辑:每个说话人的音色(声线、音调、语速)可以被编码为一个高维向量(说话人嵌入),模型通过这个向量控制生成语音的音色特征。
- • 实现方式:
chat.sample_random_speaker()会从预训练的说话人空间中采样一个随机向量,固定随机种子(如代码中SEED=42)可复现同一音色;也可通过自定义嵌入向量实现“指定音色”生成。 - • 优势:无需录制大量语音训练专属模型,仅通过向量采样/微调即可实现音色定制。
3. 可控推理模块:平衡生成稳定性与多样性
ChatTTS的推理过程基于"可控采样策略",核心是通过参数控制生成语音的随机性:
- •
temperature(温度):控制采样的随机性,值越低(如代码中0.3)生成越稳定,值越高则语音变化越多(但可能出现失真); - •
top_P(核采样):仅保留累计概率≥0.7的候选音素,减少低概率错误采样; - •
top_K:仅从概率前20的候选音素中采样,进一步限制随机性;
- • 原理:基于Transformer解码器的自回归生成,结合"温度+Top-P+Top-K"的混合采样策略,在"稳定"和"自然"之间找到平衡。
参数调优建议:
4. 端到端波形生成:直接输出可播放的语音
ChatTTS内置高效声码器(Vocoder),无需额外模块即可从文本直接生成24kHz的语音波形:
- • 逻辑:模型输出的是原始语音波形数据(而非梅尔频谱),直接转为numpy数组后即可保存为WAV文件;
- • 优势:省去“文本→梅尔频谱→波形”的两步流程,降低延迟,简化部署。
三、核心代码实战解析
结合示例代码,逐行理解ChatTTS的使用逻辑(代码已简化关键注释):
1. 环境依赖与基础配置
# 固定transformers版本(核心依赖,保证模型兼容性)
import numpy as np
import torch
import ChatTTS
import soundfile as sf
# 配置项:输入文本、输出文件、随机种子、是否跳过文本精炼
TEXT = "大家好,我是赵帅。现在演示 ChatTTS 生成语音的效果,祝大家课程顺利。"
OUT_WAV = "chattts_demo.wav"
SEED = 42
SKIP_REFINE = False# 关闭则启用文本精炼,提升自然度
关键:transformers==4.53.2是官方验证的兼容版本,避免因版本差异导致模型加载失败。
环境安装命令:
pip install transformers==4.53.2
pip install ChatTTS
pip install soundfile
pip install torch
2. 模型加载:首次自动下载权重
defmain():
print("transformers 版本:", __import__("transformers").__version__)
# 加载模型(compile=False:不编译模型,节省显存/算力)
print("正在加载 ChatTTS 模型(首次运行自动下载)...")
chat = ChatTTS.Chat()
chat.load(compile=False)
- •
chat.load(compile=False):首次运行会从HuggingFace下载预训练权重(需网络通畅);compile=False适合轻量设备(如CPU/低配GPU),开启compile=True可加速推理但需更高算力。
3. 说话人音色采样
# 固定随机种子,保证音色可复现
torch.manual_seed(SEED)
rand_spk = chat.sample_random_speaker()
- •
sample_random_speaker():从预训练的说话人嵌入空间中采样,固定SEED后,每次运行都会生成相同的音色,便于调试。
4. 推理参数配置
# 文本精炼参数:口语化+轻微停顿
params_refine_text = chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_4]'
)
# 推理参数:音色嵌入+采样策略
params_infer_code = chat.InferCodeParams(
spk_emb=rand_spk,
temperature=0.3, # 低温度保证稳定
top_P=0.7,
top_K=20
)
- • 若设置
SKIP_REFINE=True,则params_refine_text=None,跳过文本精炼,推理速度更快但自然度下降。
5. 语音生成与保存
# 核心推理:文本→语音波形
wavs = chat.infer(
[TEXT],
params_refine_text=Noneif SKIP_REFINE else params_refine_text,
params_infer_code=params_infer_code,
skip_refine_text=SKIP_REFINE,
refine_text_only=False,
stream=False# 非流式生成(流式适合实时场景)
)
# 格式转换+保存(24kHz采样率,PCM_16编码)
wav = wavs[0]
ifisinstance(wav, torch.Tensor):
wav = wav.detach().cpu().numpy().astype(np.float32)
sf.write(OUT_WAV, wav, 24000, subtype="PCM_16")
print(f"已生成: {OUT_WAV}")
- •
chat.infer():核心生成函数,stream=False表示一次性生成完整语音(流式生成适合实时语音交互场景); - • 保存时需注意:ChatTTS生成的语音采样率固定为24kHz,需匹配保存参数,否则会出现语速异常。
流式 vs 非流式对比:
流式生成代码示例:
# 流式生成适合实时语音交互
wav_iter = chat.infer([TEXT], stream=True)
for chunk in wav_iter:
# 实时播放或传输
audio_chunk = chunk[0].detach().cpu().numpy()
play_audio(audio_chunk) # 边合成边播放
四、关键调优技巧
1. 音色定制与保存
# 保存音色
import numpy as np
torch.manual_seed(42)
spk = chat.sample_random_speaker()
np.save("my_speaker.npy", spk)
# 加载音色
spk_loaded = np.load("my_speaker.npy")
params_infer_code = chat.InferCodeParams(spk_emb=spk_loaded, ...)
2. 不同场景的韵律配置
# 场景1:新闻播报(正式、清晰)
params_refine_text = chat.RefineTextParams(prompt='[oral_1][laugh_0][break_2]')
params_infer_code = chat.InferCodeParams(temperature=0.2, top_P=0.8, top_K=10)
# 场景2:日常对话(自然、口语化)
params_refine_text = chat.RefineTextParams(prompt='[oral_3][laugh_1][break_4]')
params_infer_code = chat.InferCodeParams(temperature=0.3, top_P=0.7, top_K=20)
# 场景3:讲故事(生动、有情感)
params_refine_text = chat.RefineTextParams(prompt='[oral_4][laugh_2][break_6]')
params_infer_code = chat.InferCodeParams(temperature=0.4, top_P=0.6, top_K=30)
3. 推理速度优化
| | |
| | chat.load(compile=True) |
| | skip_refine_text=True |
| | |
| | torch.cuda |
4. 常见问题排查
- • 破音/杂音:降低
temperature至0.2,提高top_P至0.8 - • 音色不一致:固定随机种子
torch.manual_seed(SEED)
五、应用场景
| | |
| 智能客服 | | oral_1 |
| 虚拟人 | | oral_3-4 |
| 内容创作 | | |
| 语音助手 | | |
- • 智能客服:生成自然的中文客服语音,支持多音色、多语气;
- • 虚拟人:为数字人定制专属音色,匹配口型生成语音;
- • 语音助手:适配智能家居、车载场景的口语化语音交互。
六、总结
ChatTTS的核心优势在于中文优化、端到端易用性、灵活的可控性:通过文本精炼模块解决自然度问题,通过说话人嵌入实现音色定制,通过可控采样平衡稳定性与多样性。从代码实战来看,其API设计简洁,仅需几行代码即可实现高质量语音生成,是中文TTS场景的优质选择。
未来,ChatTTS还可结合微调(如定制专属音色、行业术语适配)进一步提升场景适配能力,相信会成为中文语音合成领域的主流工具之一。

