使用 Unidbg 的过程,本质上是在和一个不完整的操作系统做协商。理解它"缺了什么"比知道它"有什么"更重要。
从一次报错开始
假设你第一次用 Unidbg 跑一个签名函数,代码大概长这样:
publicclassSignDemoextendsAbstractJni{
privatefinal AndroidEmulator emulator;
privatefinal VM vm;
privatefinal Module module;
publicSignDemo(){
// 创建 ARM 64 位模拟器,进程名伪装为目标 App
// 进程名很重要:SO 可能通过 /proc/self/cmdline 检查进程名
emulator = AndroidEmulatorBuilder.for64Bit()
.setProcessName("com.example.app")
.build();
// 创建 Android 虚拟机实例,加载 APK 以获取资源和类信息
// APK 文件用于解析 AndroidManifest.xml 中的包名、签名等
vm = emulator.createDalvikVM(new File("example.apk"));
// 注册 JNI 回调处理器
// 当 SO 发起 JNI 调用时,Unidbg 会回调到你的 AbstractJni 子类
vm.setJni(this);
// 开启详细日志,能看到每一次 JNI 调用和系统调用
// 调试阶段建议开启,生产环境关闭以提升性能
vm.setVerbose(true);
// 加载目标 SO 文件
// callInit=true 表示自动执行 .init 段、.init_array 和 JNI_OnLoad
DalvikModule dm = vm.loadLibrary(new File("libexample.so"), true);
module = dm.getModule();
}
public String callSign(String input){
// 调用 SO 中的签名函数
// 参数说明:
// vm.getJNIEnv() — JNIEnv 指针,所有 JNI 函数的第一个参数
// 0 — jobject this(静态方法传 jclass,这里简化为 0)
// vm.addLocalObject — 将 Java 对象注册到 Unidbg 的本地引用表中
DvmObject<?> result = module.callFunction(
emulator, "sign",
vm.getJNIEnv(),
0,
vm.addLocalObject(new StringObject(vm, input))
);
return result.getValue().toString();
}
}
你满怀期待地运行,然后控制台输出了这样的报错:
JNI callStaticObjectMethod not implemented
class: android/provider/Settings$Secure
method: getString(Landroid/content/ContentResolver;Ljava/lang/String;)Ljava/lang/String;
这条报错信息蕴含了关于 Unidbg 本质的一切。 让我们逐行解读:
callStaticObjectMethod not implemented — SO 代码通过 JNI 调用了一个 Java 静态方法,但 Unidbg 不知道怎么响应class: android/provider/Settings$Secure — 被调用的是 Android 系统的 Settings.Secure 类method: getString(...) — 方法是 getString,它在读取 Android 系统设置(比如 android_id、bluetooth_address 等)Ljava/lang/String; — 方法签名显示返回值是 String 类型
这段报错翻译成人话就是:SO 代码问了一个问题("这台设备的 android_id 是什么?"),Unidbg 答不上来,因为它没有真正的 Android Settings 数据库。
你要做的,就是告诉 Unidbg:"当 SO 问这个问题时,请这样回答。"
这就是 Unidbg 的世界观:它是一个残缺但可用的 Android 系统,它能自动处理大部分底层事务,但总会遇到它处理不了的问题,需要你来接手。
理解这个世界观,需要回答两个核心问题:
Unidbg 模拟了 Android 的哪些层
一个 Android SO 文件的运行,依赖一个从硬件到应用层的完整软件栈。Unidbg 从这个栈中选择性地实现了五个层次:
Unidbg 模拟的五个层次第一层:CPU 指令执行(Backend 层)
这是 Unidbg 最坚实的一层,由上一篇介绍的五种后端引擎提供:
- ARM32(ARMv7)和 ARM64(AArch64)指令集的完整模拟
- 浮点运算(VFP,Vector Floating Point)和 SIMD 指令(NEON,ARM 的向量运算扩展)
这一层几乎不需要你操心。 SO 代码中的纯计算逻辑 — 加密算法、哈希函数、数据转换 — 都可以在这一层正确执行。只要是不涉及外部交互的指令序列,Backend 都能忠实地模拟。
**为什么说"几乎"**:极少数情况下,Unicorn 的浮点精度或特殊指令(如某些 NEON 乘法指令的溢出行为)可能与真实 ARM CPU 有细微差异。这类差异在普通 SO 分析中几乎不会碰到,但在对抗场景下可能被用作 Unicorn 引擎指纹检测。
第二层:Linux 系统调用(SyscallHandler)
真实 Android 运行在 Linux 内核之上,SO 代码通过 SVC(Supervisor Call)指令发起系统调用(syscall)来请求内核服务。Unidbg 实现了一个 SyscallHandler,拦截这些系统调用并模拟内核的响应。
已实现的系统调用(约 30%)包括:
| | |
|---|
| openat, read, write, close, fstat | |
| mmap | |
| getpid | |
| clock_gettime | |
| sigaction | |
| futex | |
| ioctl | |
关键认知:Unidbg 对这些系统调用的实现是语义近似而非完全一致。
以 clock_gettime 为例,它返回的是宿主机(你的 Mac/PC)的系统时间,不是模拟出的 Android 设备时间。对大部分场景这无所谓,但如果 SO 通过对比两次 clock_gettime 的差值来检测执行速度,模拟器的慢速执行(Unicorn 解释执行比真机慢几十倍)就会暴露。
"语义近似"的含义:真实 Linux 内核的 mmap 返回的地址受 ASLR(Address Space Layout Randomization,地址空间布局随机化)影响,每次运行都不同。Unidbg 的 mmap 返回的地址是确定性的。大部分 SO 不关心 mmap 返回的具体地址值,但防护类 SDK 可能会检查内存布局是否符合真机特征。
第三层:C 运行时库(虚拟 libc)
Android 使用 Bionic libc(Google 专为 Android 开发的 C 标准库,不同于 Linux 桌面发行版使用的 glibc),SO 代码中大量调用 malloc、free、strlen、memcpy、printf 等 C 标准库函数。Unidbg 的处理策略是混合式的:
- 一部分函数由 Unidbg 在 Java 层内置实现:比如内存管理(
malloc/free/calloc)、字符串操作(strlen/strcmp/memcpy)。这些实现运行在 JVM 中而非模拟器中,性能更好 - 一部分函数通过加载真实的 libc.so 提供:Unidbg 会加载一个从 Android 系统中提取的 libc.so(位于
src/main/resources/android/sdk23/lib/ 目录),让其中的函数在模拟器中直接以 ARM 代码执行 - 少数函数需要你手动 Hook:比如
__system_property_get(读取 Android 系统属性)在模拟环境中没有属性数据库可查,需要你通过 Hook 提供返回值
这一层的设计思路是"能用真实的就用真实的"。libc 中的纯计算函数(字符串操作、数学函数、格式化输出)可以直接在模拟器中执行其 ARM 代码,只有涉及操作系统交互的函数才需要特殊处理。
第四层:JNI 桥接(DalvikVM)
这是使用 Unidbg 时交互最频繁的一层,也是"补环境"工作量最大的一层。
JNI(Java Native Interface)是 Java 代码和 Native 代码之间的桥梁。在真实 Android 中,当 SO 代码调用 FindClass("android/os/Build") 时,ART(Android Runtime)虚拟机会在已加载的类中查找 android.os.Build 类并返回一个引用。在 Unidbg 中,这个工作由 DalvikVM(Unidbg 内置的轻量级 JNI 模拟层)完成。
Unidbg 实现了约 150 个核心 JNI 函数,覆盖了以下几类操作:
| | |
|---|
| FindClass | |
| CallObjectMethod | |
| GetFieldID | |
| NewStringUTF | |
| NewByteArray | |
| NewGlobalRef | |
| ExceptionCheck | |
关键区分:JNI 函数分为"Unidbg 自动处理"和"需要你手动实现"两类。
自动处理的是那些与 Java 对象管理相关的通用操作:创建字符串、管理数组、引用计数等。这些操作的语义是确定的,不依赖于具体的 App 业务逻辑。
需要你实现的是那些涉及具体 Java 类和方法的调用:CallObjectMethod、CallStaticObjectMethod、GetStaticObjectField 等。当 SO 代码调用一个 Java 方法时,Unidbg 只知道被调用的类名、方法名和签名,但不知道这个方法应该返回什么 — 因为它没有 ART 虚拟机,无法执行 Java 代码。所以它把这个问题转交给你。
**这就是为什么你的类要继承 AbstractJni**:Unidbg 通过 callObjectMethod、callStaticObjectMethod、getStaticObjectField 等回调方法把"Java 方法调用"传递给你。你在这些回调中根据类名和方法名判断应该返回什么值。这个机制在后续的第七篇会详细讲解。
第五层:文件系统(IOResolver)
SO 代码经常需要读取文件,Unidbg 通过 IOResolver 接口提供了一个按需响应的虚拟文件系统。
当 SO 代码调用 open("/proc/self/status") 时:
- 首先检查你是否在
IOResolver 中注册了对这个路径的处理 - 如果你注册了 → 使用你提供的文件内容(通过
FileResult 返回) - 如果你没注册 → 使用 Unidbg 的默认处理(对部分常见路径如
/proc/self/cmdline 有内置响应) - 如果都没有 → 返回文件不存在(
errno = ENOENT)
这不是一个真正的文件系统 — 没有目录结构、没有 inode、没有文件权限管理。它更像一个"问答机":SO 问"这个文件的内容是什么?",你来回答。
IOResolver 的三种返回值语义:
- 返回
FileResult 对象 → "这个文件存在,内容是这些" - 返回
-1 → "明确告诉 SO 这个文件不存在" - 返回
null → "我不处理这个路径,交给 Unidbg 默认逻辑"
Unidbg 没有模拟什么
理解 Unidbg 的缺失比理解它的能力更重要 — 因为缺失的部分决定了你要做多少"补环境"工作,也决定了哪些样本 Unidbg 根本无法处理。
Unidbg 没有模拟的五大缺失缺失一:没有进程调度(单进程模型)
真实 Android 系统可以同时运行成百上千个进程,内核通过 CFS(Completely Fair Scheduler,完全公平调度器)在它们之间分配 CPU 时间片。
Unidbg 没有进程的概念。它就是一个进程 — 你的 JVM 进程。SO 代码在这个进程内的模拟器中执行。不存在"其他进程"。
影响:
- 如果 SO 代码通过
kill() 发送信号给另一个进程 → 没有目标进程可以接收 - 如果 SO 代码通过
/proc/ 目录遍历其他进程信息(反调试检测常见手段)→ 不存在其他进程 - 如果 SO 代码
fork() 创建子进程 → Unidbg 不支持
在实际逆向中,大部分签名/加密类 SO 不涉及多进程操作,所以这个缺失影响有限。
缺失二:没有真正的线程(协作式伪多线程)
这是 Unidbg 最容易让人困惑的缺失之一。
真实 Android 的线程是由内核调度的 — 多个线程可以真正地并行执行在不同的 CPU 核心上。线程之间通过 futex(Fast Userspace Mutex)、pthread_mutex、pthread_cond 等原语进行同步。
Unidbg(使用 Unicorn2 及以上的后端时)实现了一种协作式伪多线程:
- 线程不是真正并行执行的 — 同一时刻只有一个线程在模拟器中运行
- 线程切换由 Unidbg 在特定时机主动发起(比如系统调用返回时、
futex 等待时) - 没有真正的时间片轮转(time-slice round robin)
影响:
- 依赖真正并行执行的代码(比如生产者-消费者模型)可能行为异常
JNI_OnLoad 中如果启动了后台线程并等待其完成(这在真机上很常见),可能导致死锁
实际案例:许多 App 的 SO 在 JNI_OnLoad 中创建一个初始化线程,主线程通过 pthread_join 或条件变量等待初始化完成。在真机上这没问题(两个线程并行执行),但在 Unidbg 中主线程会阻塞在等待上,而初始化线程永远无法被调度执行 — 经典死锁。
处理办法:Hook 掉 pthread_create,把初始化逻辑改为在主线程中同步执行。或者使用 emulator.getThreadDispatcher() 手动触发线程切换。
缺失三:没有网络协议栈
Unidbg 没有实现 TCP/IP 协议栈。没有 socket 系统调用(socket、connect、bind、send、recv),没有 DNS 解析(getaddrinfo),没有 HTTP 客户端。
影响:
- 如果 SO 代码尝试发起网络请求(上报日志、与服务端握手、获取远程配置)→ 全部失败
- 如果 SO 代码通过网络请求获取加密密钥或初始化参数 → 你需要手动提供这些数据
这个缺失在"签名计算"场景下通常不是大问题 — 签名函数的核心逻辑是纯计算,不需要网络。但在某些安全 SDK 中,初始化阶段可能需要与服务端交换密钥(如 SSL Pinning 验证),这时就需要通过 Hook 绕过网络依赖或手动提供密钥数据。
缺失四:没有 Binder 通信
Binder 是 Android 独有的进程间通信(IPC,Inter-Process Communication)机制,是 Android Framework 的基石。几乎所有的系统服务(ActivityManager、PackageManager、WindowManager、TelephonyManager)都通过 Binder 暴露接口。
Unidbg 完全没有实现 Binder。
影响:
- 任何间接通过 JNI → Java → SystemService 的调用链都需要你在 JNI 层截断并手动提供返回值
为什么 Binder 的缺失不是致命的:SO 代码通常不直接使用 Binder(直接使用意味着要手动构造 Binder 事务,这在 NDK 开发中极为罕见)。它们通过 JNI 调用 Java 层的方法,Java 层的方法再通过 Binder 调用系统服务。由于 Unidbg 在 JNI 层就截断了这个调用链(你通过 callObjectMethod 等回调直接返回值),所以 Binder 的缺失被 JNI 层的手动实现"遮盖"了。
缺失五:没有 ART 虚拟机(不能执行 DEX 代码)
这是 Unidbg 最根本的限制。
真实 Android 中,ART(Android Runtime)虚拟机执行 DEX 字节码。App 的 Java/Kotlin 代码编译为 DEX 格式,由 ART 加载并执行(通过 AOT 预编译或 JIT 即时编译为机器码)。当 SO 代码通过 JNI 调用一个 Java 方法时,ART 负责执行那个 Java 方法并返回结果。
Unidbg 没有 ART 虚拟机。它完全不能执行 Java/Kotlin 代码。
影响 — 所有 JNI 回调都需要你来处理:
当 SO 代码调用 CallObjectMethod 执行一个 Java 方法时,在真机上 ART 会执行那个方法的 Java 代码。在 Unidbg 中,没有 ART 来执行,所以这个调用被转发到你的 AbstractJni 子类 — 你需要根据方法签名判断应该返回什么。
- 简单情况:返回一个固定值(比如设备型号
"Pixel 6"、屏幕高度 1920) - 中等情况:JDK 内置类(如
StringBuilder、HashMap)的方法调用,可以直接用 Java 实现 - 复杂情况:App 自定义 Java 类的方法调用,你需要从 JADX 反编译结果中复制并重写那段 Java 逻辑
这也解释了为什么有些样本在 Unidbg 中极难处理:如果 SO 函数频繁回调 Java 层、Java 层的逻辑又很复杂(比如涉及 SharedPreferences 读写、ContentProvider 查询、多层方法调用),你等于要手动重写一大部分 App 的 Java 代码。这时候可能 Frida + 真机才是更好的选择。
依赖树模型:理解"补环境"的本质
到现在为止,我们已经知道了 Unidbg 实现了什么、缺失了什么。但这些知识还是零散的。需要一个统一的模型来理解"补环境"到底是怎么回事。
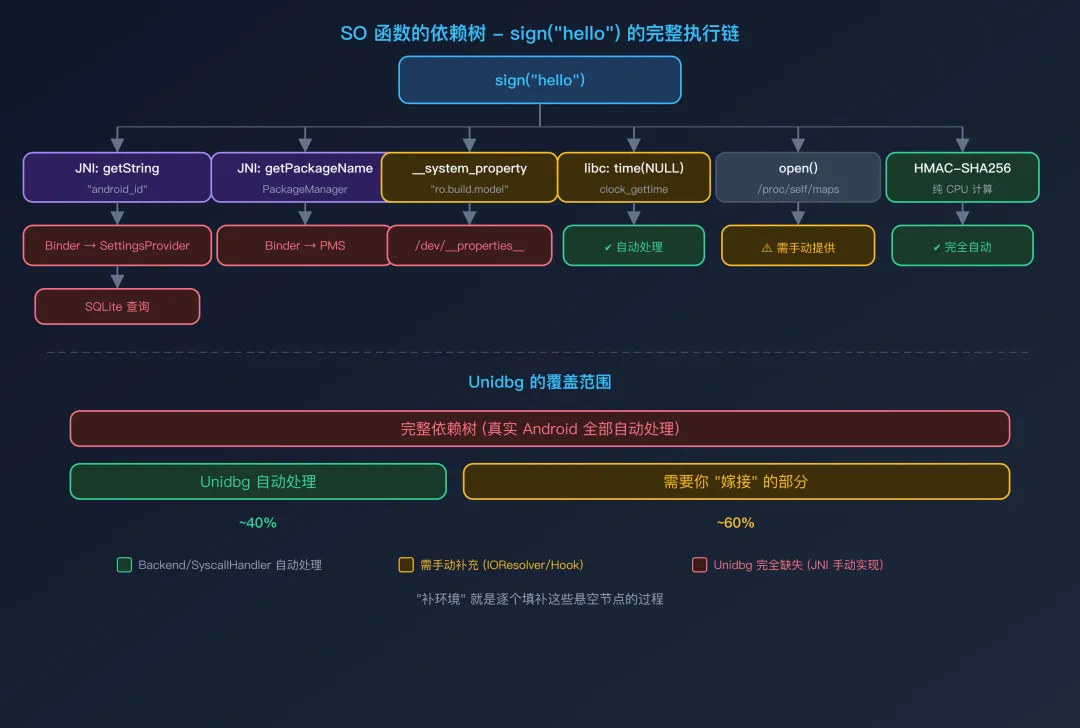
SO 函数的依赖树
一个 SO 函数在真机上的执行,依赖一棵庞大的"服务树"。以一个签名函数 sign("hello") 为例:
SO 函数的依赖树在真机上,这棵树的每一个节点都有对应的服务提供者 — Android 系统自动处理一切。
在 Unidbg 中,这棵树只有部分节点能被自动处理:
- 纯计算分支(HMAC-SHA256)→ 完全由 Backend 层自动处理
- libc 函数(
time、strlen)→ 大部分由虚拟 libc 自动处理 - 简单系统调用(
clock_gettime、getpid)→ 由 SyscallHandler 自动处理 - JNI 通用操作(
NewStringUTF、GetArrayLength)→ 由 DalvikVM 自动处理
剩下的节点 — 那些涉及具体 Android 服务、具体 Java 类、具体文件内容的 — 都悬空着,等待你来"嫁接"。
"补环境",就是逐个填补这些悬空节点的过程。
四层交互模型
SO 代码与外部世界的交互可以归纳为四层,每层对应一种补环境方式:
四层交互模型**处理的优先级永远是"先让 Unidbg 自己跑"**:启动模拟器 → 加载 SO → 调用目标函数 → 看它哪里倒下 → 读报错信息 → 判断属于哪一层 → 补上 → 再跑。循环往复。
不要试图在运行前预判所有缺失。每个 SO 的依赖不同,只有让它跑起来,它才会告诉你缺了什么。
一个完整的"残缺世界"巡礼
为了让这些抽象的层次变得具体,让我们走一遍一个 SO 函数从加载到执行的完整过程,标注每一步 Unidbg 的处理方式。
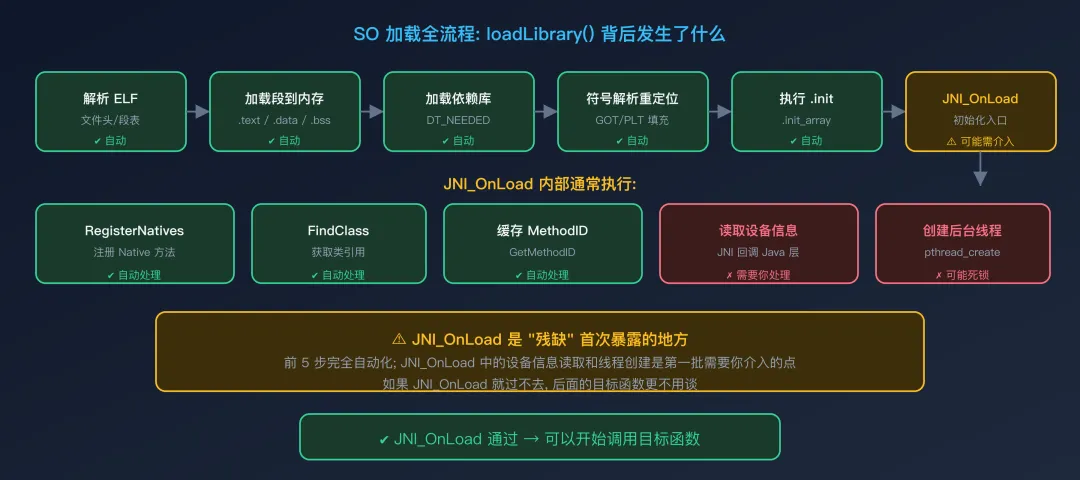
阶段一:SO 加载
// 这一行背后,Unidbg 自动完成了 6 个步骤
DalvikModule dm = vm.loadLibrary(new File("libexample.so"), true);
SO 加载全流程前五步完全自动化,你不需要任何干预。**JNI_OnLoad 是第一个可能出问题的地方** — 因为 JNI_OnLoad 函数通常会注册 Native 方法、初始化全局状态,过程中可能触发 JNI 回调或系统调用。
阶段二:JNI_OnLoad 执行
JNI_OnLoad 是 SO 的初始化入口,它通常做以下事情:
| | | |
|---|
| RegisterNatives | | |
| FindClass | | |
| GetMethodID | | |
| | | |
| pthread_create | | |
第 4 步和第 5 步就是 Unidbg 的"残缺"开始暴露的地方。如果 JNI_OnLoad 就过不去,后面的目标函数更不用谈。
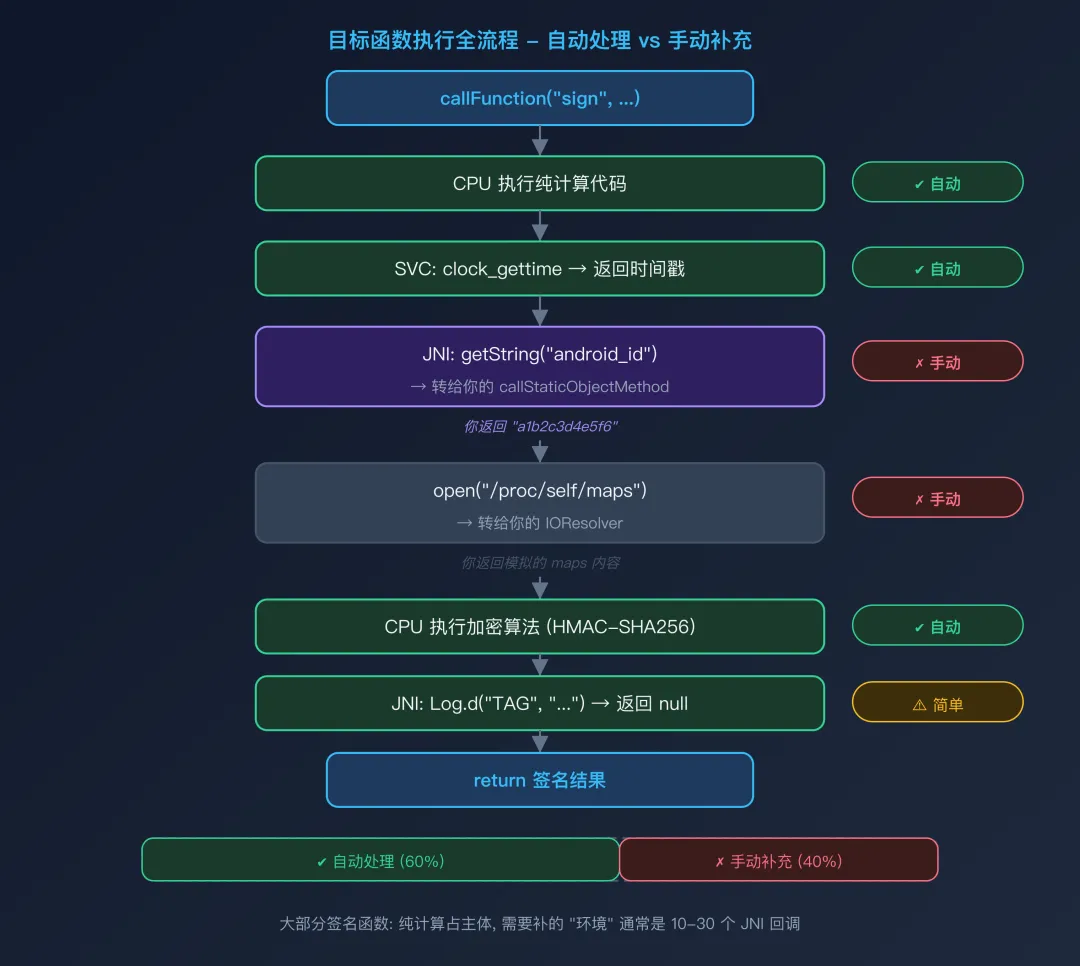
阶段三:目标函数执行
当你调用签名函数时,SO 代码的执行会在四层交互模型中跳跃:
目标函数执行全流程每个红色标记(✗ 手动)的地方,就是你需要"补环境"的点。每个绿色标记(✓ 自动)的地方,是 Unidbg 自动处理的部分。
好消息是:对大多数签名/加密类 SO,纯计算部分占了代码的绝大部分。需要你补的"环境"通常是 10-30 个 JNI 回调和少量文件访问。
坏消息是:有些安全 SDK 的检测逻辑会密集地与 Android 系统交互(读取几十个系统属性、遍历已安装应用列表、检查多个文件是否存在、获取各种设备标识符),补环境的工作量可能很大。
一张地图:哪些由 Unidbg 处理,哪些由你处理
最后,让我们用一张清晰的对照表来总结这个"残缺但可用"的世界:
| | | |
|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | Hook __system_property_get |
| | | |
| | | 手动实现每个回调 |
| | | |
| | | |
| | | |
| | | |
| | | |
建立正确的心智模型
使用 Unidbg,你需要同时扮演两个角色:
- 操作系统 — 回答 SO 代码提出的每一个 Unidbg 无法回答的问题
第二个角色才是 Unidbg 使用的核心。你不是在"配置"一个工具,你是在扮演一个操作系统:
- SO 代码问你"屏幕多高?" → 你回答
1920 - SO 代码问你"
android_id 是什么?" → 你回答一个 16 位十六进制字符串 - SO 代码要读
/proc/self/maps → 你提供一份精心构造的内存映射表 - SO 代码调用
System.currentTimeMillis() → 你返回一个合理的时间戳 - SO 代码调用
Log.d("TAG", "debug") → 你返回 null(日志不影响计算结果)
理解这个角色,是从"Unidbg 初学者"到"Unidbg 使用者"的分界线。
初学者遇到报错会想:"这个工具怎么又报错了?" 使用者遇到报错会想:"SO 又问了一个我还没回答的问题,让我看看它在问什么。"
心态的转变,比任何 API 知识都重要。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
