为什么要先讲这个
后面你学 Prompt、Tool Calling、Workflow、Agent Runtime,看起来像是在学不同主题,但背后其实都在回答同一个问题:
什么该交给模型,什么该交给系统?
如果这个判断一开始就错了,后面的设计通常会越来越别扭。很多问题看上去像“模型不够聪明”,其实不是模型太弱,而是把原本应该交给工具、规则、状态系统或人工的事情,硬塞给了模型。
核心观点
LLM 更像一个很强的语义处理器,而不是一个天然可靠的执行器。
这句话足够概括大部分场景。
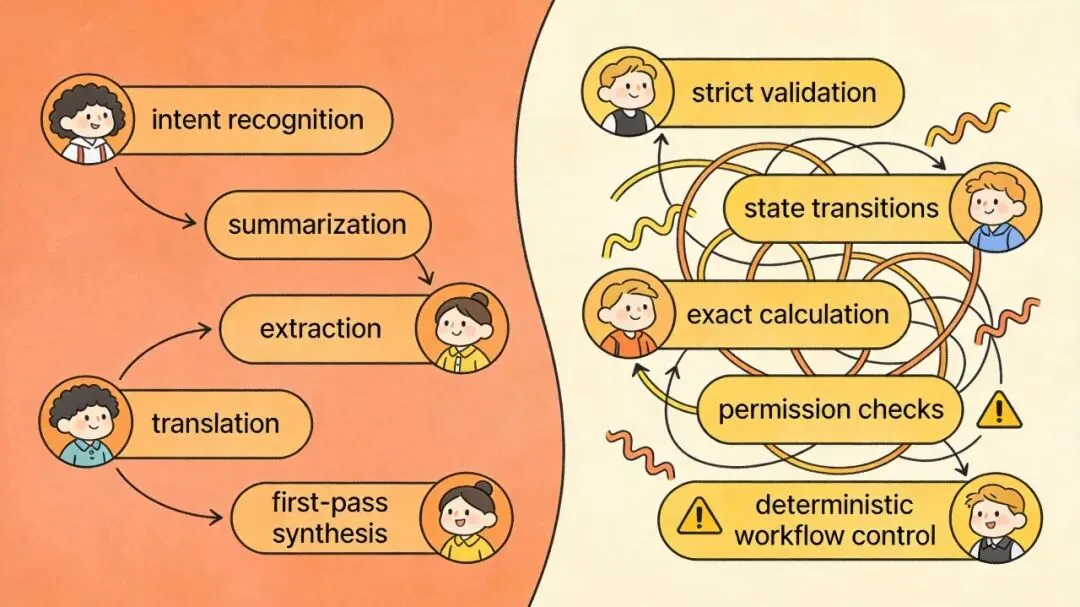
把它当语义处理器,你会想到理解、改写、抽取、归纳和软判断;把它当执行器,你就会期待它稳定记忆、精确执行、自动纠错、直接接触真实世界,而这些恰好是它的短板。
LLM 真正擅长什么
LLM 最强的地方,不是“会回答”,而是“会处理语言”。
它很擅长从口语化、表达混乱、格式不统一的文本里抓住真正的意思,所以很适合意图识别、内容分类、语义去重、检索前的相关性判断。这类任务往往很难写死规则,但人又能大致判断,正是模型最有价值的位置。
它也很适合做语言转换类工作,比如总结、改写、翻译、解释和起草。很多时候你并不需要一份绝对完美的最终稿,而是需要一份可以继续加工的初稿。模型最值钱的地方,常常就是先把混乱信息压缩成可讨论、可处理的形式。
再往前走一步,模型还擅长从低结构材料里抽取高结构信息。现实世界里的输入常常是邮件、网页、聊天记录、访谈纪要,而不是整齐表格。模型可以从这些材料里提取出时间、人物、事件、结论、争议点和下一步动作,为后面的检索、存储、路由和评估打基础。
当资料来自多个来源时,模型也很适合先做第一轮归并。它能把重复信息合并,把不同说法并排对照,再形成一版初步结论。这里的关键词是“初步”。它不是最终裁判,但很适合做第一层整理器。
LLM 不擅长什么
首先,它不是天然稳定的执行器。同样的输入,在不同上下文、不同提示词甚至不同时间下,模型都可能给出不完全一样的结果。也就是说,它天然带有波动性。因此,凡是要求完全一致、可复现、可审计的环节,都不该只靠模型承担。权限判断、金额计算、严格格式校验、流程状态流转,更适合交给确定性代码。
其次,它没有你以为的长期记忆。聊天体验会让人误以为模型“记住了你”,但模型本身不是可靠的长期存储系统。只要任务跨步骤、跨会话、跨天,记忆就必须显式外置到 state、数据库、文档或检索系统里,而不是指望模型自己别忘记。
再次,它不能直接接触真实世界。没有工具调用时,它并不能自己读网页、查数据库、看本地文件、调用系统命令;有工具调用时,真正完成访问的是工具和运行时,不是模型本体。模型擅长的是决定该查什么、看完后怎么理解、最后怎么组织成回答。
最后,只要一个问题已经能被清楚写成规则,通常就不该优先交给模型。模型擅长的是“说不清但能判断”的事,不擅长“规则已经很清楚,只要严格照做”的事。一个很实用的判断方法是:如果你能把标准稳定地写成测试用例,这件事大概率更适合让代码执行。
放到 Agent 里怎么理解
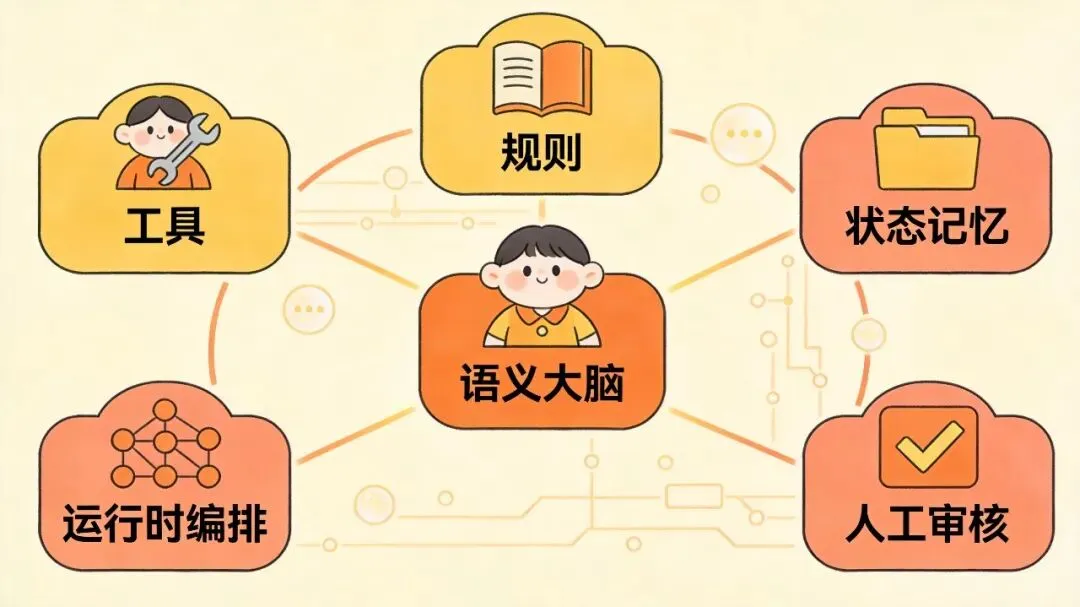
做 Agent 不是让模型一个人包打天下,而是把它放到最值钱的位置上。
模型负责理解、判断、归纳和生成;工具负责搜索、读取、调用和执行;规则负责边界和约束;状态系统负责记忆和恢复;运行时负责流程控制、重试和观测;高风险结论则保留人工复核。一个成熟的 Agent System,价值不在于“模型参与得越多越高级”,而在于分工是不是合理。
Research Agent 就很典型。模型适合决定搜什么、判断资料是否相关、从长文里抽重点、把多来源内容总结成一版结论;工具负责搜索网页、抓正文、存状态;规则负责去重、限轮和结构校验。这样分工之后,系统才会从“会聊天的流程”变成“能工作的系统”。
设计时先问自己
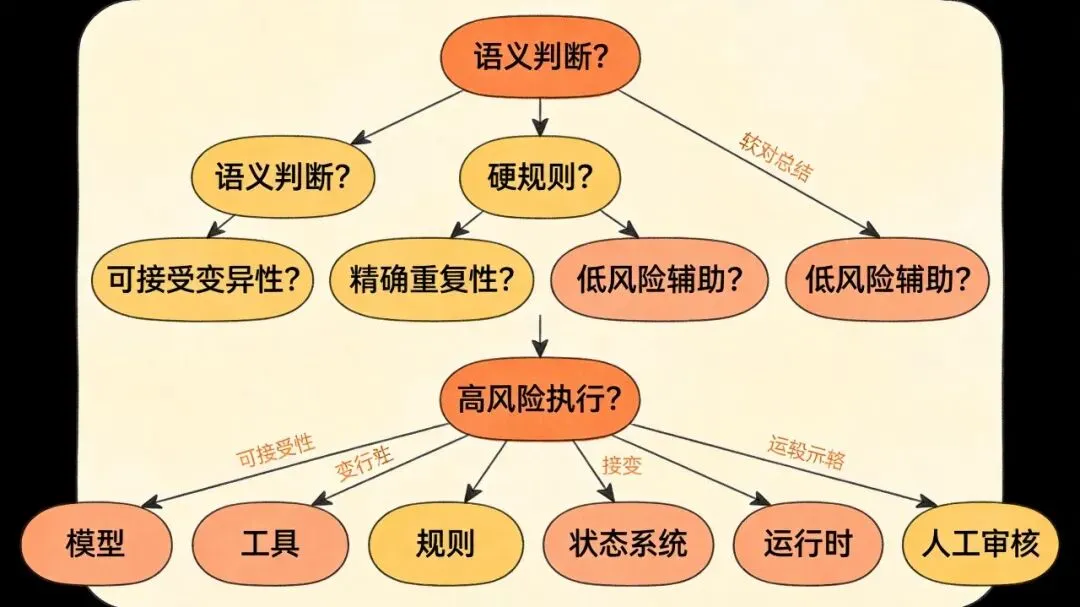
每次准备把一个任务交给模型时,先停一下,问自己四件事:这是语义问题,还是规则问题?它需要理解和归纳,还是需要稳定和精确执行?如果这里出错,系统能不能接受波动?这个环节是不是其实更该交给工具、规则、状态系统或人工?
很多架构问题,不是实现得不够复杂,而是一开始就把任务分给了不合适的执行者。
最后
LLM 最厉害的地方,是把模糊的人类语言变成可处理的信息;Agent System 的价值,是让这种能力出现在该出现的地方,而不是替代整个系统。