PyTorch学习笔记|动态计算图与梯度下降入门
- 2026-05-15 12:26:18

autograd回溯机制
新版PyTorch中的张量已经不仅仅是一个纯计算的载体,张量本身也可支持微分运算。这种可微分性其实不仅体现在我们可以使用grad函数对其进行求导,更重要的是这种可微分性会体现在可微分张量参与的所有运算中。
我们看下代码,张量y具有了一个grad_fn属性,并且取值为
import torch
x = torch.tensor(1.,requires_grad=True)
y = x ** 2 #构造函数关系
print(y)
#result
tensor(1., grad_fn=<PowBackward0>)
我们继续构建一个新的z,z也同时存储了张量计算数值、z是可微的,并且z还存储了和y的计算关系(add)。据此我们可以知道,在PyTorch的张量计算过程中,如果我们设置初始张量是可微的,则在计算过程中,每一个由原张量计算得出的新张量都是可微的,并且还会保存此前一步的函数关系,这也就是所谓的回溯机制。而根据这个回溯机制,我们就能非常清楚掌握张量的每一步计算,并据此绘制张量计算图。
z = y + 1
print(z.requires_grad, z)
# True tensor(2., grad_fn=<AddBackward0>)
动态计算图
借助回溯机制,我们就能将张量的复杂计算过程抽象为一张图(Graph),例如此前我们定义的x、y、z三个张量,三者的计算关系就可以由下图进行表示。
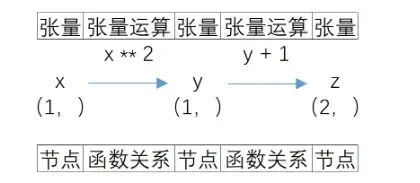
计算图的定义:上图就是用于记录可微分张量计算关系的张量计算图,图由节点和有向边构成,其中节点表示张量,边表示函数计算关系,方向则表示实际运算方向,张量计算图本质是有向无环图。 在张量计算图中,虽然每个节点都表示可微分张量,但节点和节点之间却略有不同。就像在前例中,y和z保存了函数计算关系,但x没有,而在实际计算关系中,我们不难发现z是所有计算的终点,因此,虽然x、y、z都是节点,但每个节点却并不一样。此处我们可以将节点分为三类,分别是: a):叶节点,也就是初始输入的可微分张量,前例中x就是叶节点; b):输出节点,也就是最后计算得出的张量,前例中z就是输出节点; c):中间节点,在一张计算图中,除了叶节点和输出节点,其他都是中间节点,前例中y就是中间节点。 当然,在一张计算图中,可以有多个叶节点和中间节点,但大多数情况下,只有一个输出节点,若存在多个输出结果,我们也往往会将其保存在一个张量中。
值得一提的是,PyTorch的计算图是动态计算图,会根据可微分张量的计算过程自动生成,并且伴随着新张量或运算的加入不断更新,这使得PyTorch的计算图更加灵活高效,并且更加易于构建,相比于先构件图后执行计算的部分框架(如老版本的TensorFlow),动态图也更加适用于面向对象编程。
反向传播与梯度计算
我们曾使用autograd.grad进行函数某一点的导数值得计算,其实,除了使用函数以外,我们还有另一种方法,也能进行导数运算:反向传播。当然,此时导数运算结果我们也可以有另一种解读:计算梯度结果。
首先,对于某一个可微分张量的导数值(梯度值),存储在grad属性中。在最初,x.grad属性是空值,不会返回任何结果,我们虽然已经构建了x、y、z三者之间的函数关系,x也有具体取值,但要计算x点导数,还需要进行具体的求导运算,也就是执行所谓的反向传播。所谓反向传播,我们可以简单理解为,在此前记录的函数关系基础上,反向传播函数关系,进而求得叶节点的导数值。在必要时求导,这也是节省计算资源和存储空间的必要规定。
反向传播结束后,即可查看叶节点的导数值。无论何时,我们只能计算叶节点的导数值。
x = torch.tensor(1.,requires_grad=True)
y = x ** 2 #构造函数关系
z = y + 1 #继续构造函数
z.backward()#执行反向传播
print(x.grad)
#tensor(2.)
默认情况下,在反向传播过程中,中间节点并不会保存梯度,若想保存中间节点的梯度,我们可以使用retain_grad()方法。
x = torch.tensor(1.,requires_grad=True)
y = x ** 2
y.retain_grad()
z = y ** 2
z.backward()
print(x.grad,y.grad)
#tensor(4.) tensor(2.)
梯度下降基本思想
之前我们用最小二乘法求解简单线性回归的目标函数,并顺利的求得了全域最优解。在所有的优化算法中最小二乘法虽然高效并且结果精确,但也有不完美的地方,核心就在于最小二乘法的使用条件较为苛刻,要求特征张量的交叉乘积结果必须是满秩矩阵,才能进行求解。而在实际情况中,很多数据的特征张量并不能满足条件,此时就无法使用最小二乘法进行求解。
梯度下降的基本思想其实并不复杂,其核心就是希望能够通过数学意义上的迭代运算,从一个随机点出发,一步步逼近最优解。数学意义上的迭代运算,指的是上一次计算的结果作为下一次运算的初始条件带入运算。
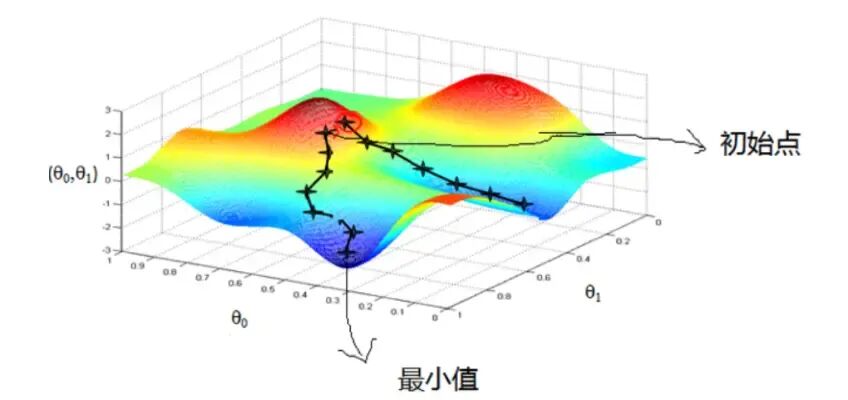
梯度下降的方向和步长
当然,梯度下降的基本思想好理解,但实现起来却并不容易(这也是大多数机器学习算法的常态)。在实际沿着目标函数下降的过程中,我们核心需要解决两个问题,其一是往哪个方向走,其二是每一步走多远。以上述简单线性回归的目标函数为例,在三维空间中,目标函数上的每个点理论上都有无数个移动的方向,每次移动多远的物理距离也没有明显的约束,而这些就是梯度下降算法核心需要解决的问题,也就是所谓的方向和步长。
关于方向的讨论,其实梯度下降是采用了一种局部最优推导全域最优的思路,我们首先是希望能够找到让目标函数变化最快的方向作为移动的方向,而这个方向,就是梯度。简单的说梯度是一个向量,每个分量是函数对对应变量的偏导数。步长也叫学习率,而学习率乘以梯度,则是原点移动的“长度”。
梯度下降的数学表示
梯度下降损失函数为:

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 《太玄经》学习笔记(12)附《太玄经与心理疗愈》
- 观世的AI学习笔记㉑:别让它猜,让它审——我的AI协作心法
- 【学习资料】保安服务管理条例
- 【档案学习】档案扫描及图像处理需要注意的问题(实操落地版)
- 双碳学习笔记(九):内部碳定价——企业如何用“碳价”驱动减排
- 【考公】2026年国省考学习备考资料免费分享+26年事业单位考前常识+26事业编三支公基常识最后40题+26年事业单位D类模拟卷&押题卷
- 学习笔记丨与良师益友同行,于一园之中见天地本心
- 学习假努力之一:听讲和做笔记
- 读书笔记|主动脉内球囊反搏联合药物治疗对ST段抬高型心肌梗死合并心力衰竭患者心脏泵血功能及短期临床结局的影响
- 读书班学习笔记 | 巴州区卫健局党组书记、局长王映民:深化健康引领性工程、构建全生命周期体系 奋力谱写“十五五”卫健事业新篇章
