导语
虚拟人的第一步,是拥有一个可视化的数字形象。在AIGC时代之前,虚拟人形象需要专业的原画师、建模师花费数周甚至数月完成;而如今,借助扩散模型,我们只需要一行提示词,就能在几分钟内生成高质量的2D/3D虚拟人形象,甚至可以精准控制人物的姿态、表情、动作。
本文就带你从0到1搞懂虚拟人形象生成的核心技术,从生成模型的发展脉络,到扩散模型的核心原理,再到Stable Diffusion、ControlNet等工具的实战应用,一文讲透。
1 生成模型的历史脉络
虚拟人形象生成的核心,是AIGC图像生成技术。从2013年至今,图像生成模型经历了多轮技术迭代,最终扩散模型成为了行业的主流方案,核心发展脉络如下:
- 1. 2013-2014年:VAE(变分自编码器),2013年论文发布,2014年正式发表,首次实现了基于神经网络的可控图像生成;
- 2. 2014-2017年:GAN(生成对抗网络)黄金期,2014年提出,后续衍生出DCGAN、Pix2Pix、CycleGAN、StyleGAN等经典模型,成为当时图像生成的绝对主流;
- 3. 2014-2018年:归一化流(Normalizing Flows),2014年出现RealNVP,2018年推出Glow,提供了另一种生成模型的技术思路;
- 4. 2016-2018年:自回归生成模型,2016年出现PixelCNN,2018年GPT模型诞生,为后续的多模态生成奠定了基础;
- 5. 2020年至今:扩散模型爆发期,2020年DDPM论文发布,扩散模型正式诞生;2021年LDM提出,大幅降低计算量;2022年Stable Diffusion、MidJourney发布,扩散模型彻底走向大众,成为图像生成的行业标准。
2 核心生成模型原理解析
2.1 VAE(变分自编码器)
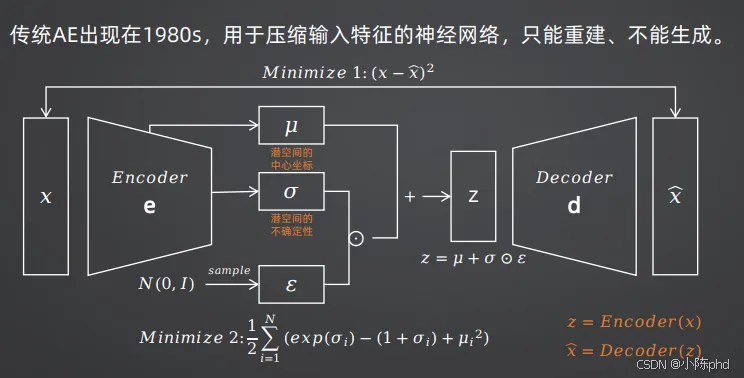 VAE的前身是传统AE(自编码器),传统AE只能实现图像的压缩与重建,无法完成生成任务。而VAE的核心创新,是解决了潜空间的“碎片化”问题,实现了真正的图像生成。
VAE的前身是传统AE(自编码器),传统AE只能实现图像的压缩与重建,无法完成生成任务。而VAE的核心创新,是解决了潜空间的“碎片化”问题,实现了真正的图像生成。

- 1. 编码器(Encoder)将输入图像压缩到潜空间,输出一个正态分布的均值和方差,而不是一个固定的向量;
- 3. 解码器(Decoder)将向量z重建为图像。
- • 核心优化:通过KL散度项,把每个图像的潜空间分布拉回到标准正态分布周围,避免潜空间碎片化,让随机采样的向量也能生成合理的图像。
- • β>1:更强的KL约束,潜空间更规则,但重建图像更模糊;
- • β<1:弱化KL约束,模型更重视重建效果,图像更清晰。
2.2 GAN(生成对抗网络)
GAN的核心是“对抗训练”,通过生成器和判别器的博弈,实现高质量图像生成,是2015-2021年图像生成的绝对主流。
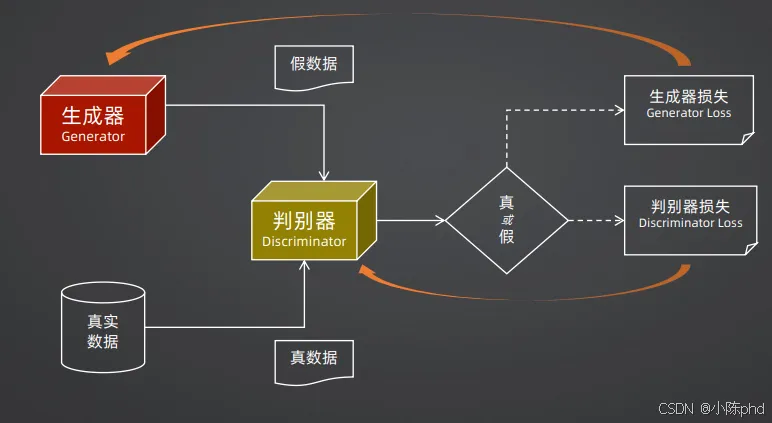
- 1. 生成器(Generator):接收随机噪声,生成“假图像”;
- 2. 判别器(Discriminator):接收真实图像和生成的假图像,判断输入是“真”还是“假”;
- 3. 对抗训练:生成器不断优化,让生成的图像骗过判别器;判别器不断优化,提升真假识别能力,二者博弈最终让生成器能生成以假乱真的图像。
- • 经典衍生模型:
| | |
| | |
| | |
| | |
| | 风格化生成,可生成超真实人脸,至今仍是高质量人像生成的经典方案 |
| | 引入Wasserstein距离,解决GAN训练不稳定、模式崩溃的问题 |
2.3 扩散模型(Diffusion Models)
扩散模型是当前虚拟人形象生成的绝对主流,Stable Diffusion、MidJourney、DALL-E等主流工具,底层均基于扩散模型。
2.3.1 核心原理
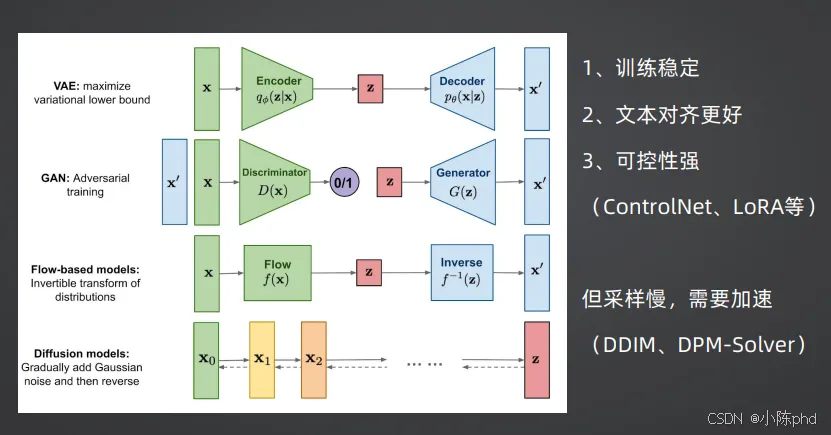
扩散模型的核心逻辑分为两步:前向扩散过程、反向去噪过程。
- 1. 前向扩散:从原始图像(t=0)开始,逐步向图像中添加高斯噪声,经过1000步后,图像变成完全的高斯噪声(t=999);
- 2. 反向去噪:训练一个神经网络,在每一个时间步t,预测图像中添加的噪声,逐步从完全噪声中还原出原始图像,实现图像生成。
- • 核心优势:训练稳定、文本对齐效果好、可控性极强(支持ControlNet、LoRA等扩展方案);
- • 核心短板:原生采样速度慢,需要通过采样器优化实现加速。
2.3.2 扩散模型的技术演进路线
扩散模型从2020年诞生至今,核心演进方向是提升生成速度、优化生成质量、增强可控性,关键里程碑如下:
| | | |
| | | 奠定扩散模型基础,训练稳定,但需要上千步采样,速度极慢 |
| | | DDIM将采样步数从上千步压缩到几十步;LDM在潜空间完成扩散,大幅降低计算量,是Stable Diffusion的原型 |
| | | 进一步优化采样速度,Stable Diffusion正式发布,扩散模型走向大众 |
| | | 工业界首选采样器,在减少步数的同时保持画质,是Euler方案的升级版 |
| | | 无需数值积分,训练模型直接学会跳步,1-4步即可出图,实现极速生成 |
2.3.3 Stable Diffusion核心架构
Stable Diffusion是目前最主流的开源扩散模型,也是生成虚拟人形象的首选工具,核心架构由三部分组成:
- 1. CLIP文本编码器:将用户输入的提示词(Prompt)转换为文本特征向量,实现文本对图像生成的控制;
- 2. LDM潜空间扩散架构:核心生成模块,在潜空间完成扩散与去噪过程,大幅降低计算量;
- 3. DDIM采样器:负责加速采样过程,实现快速出图。
3 虚拟人形象生成的核心可控方案
扩散模型解决了“生成高质量人像”的问题,而以下方案则解决了“精准控制虚拟人形象”的核心需求,是虚拟人形象生成的必备工具。
3.1 固定目标生成:让模型记住特定的虚拟人形象

如果需要生成固定形象的虚拟人,保证不同生成图中的人物外貌一致,就需要用到以下方案,从轻量到重量级排序如下:
- 1. 轻量级方案:Textual Inversion、LoRA(低秩适配),训练成本低,适合个人创作者使用,其中LoRA是目前最主流的方案;
- 2. 中量级方案:Custom Diffusion,效果与训练成本均衡;
- 3. 重量级方案:DreamBooth,能更牢固地绑定特定人物/物体,生成一致性远优于Textual Inversion,适合需要高精度固定形象的虚拟人生成。
3.2 结构约束:ControlNet精准控制虚拟人姿态

在线体验地址ControlNet是虚拟人形象生成的里程碑式工具,它解决了扩散模型“姿态、结构不可控”的痛点,能精准控制虚拟人的人体姿态、面部表情、手部动作、场景构图等。
- • 核心逻辑:通过额外的控制条件(如人体骨骼关键点、线稿、深度图等),引导扩散模型的生成过程,在保留提示词生成效果的同时,严格遵循控制条件的结构约束;
- • 核心应用:生成固定姿态、固定动作的虚拟人形象,比如虚拟主播的口播姿势、虚拟讲师的讲解动作,是虚拟人形象生成的必备工具。
3.3 主流工具对比:Diffusers vs ComfyUI
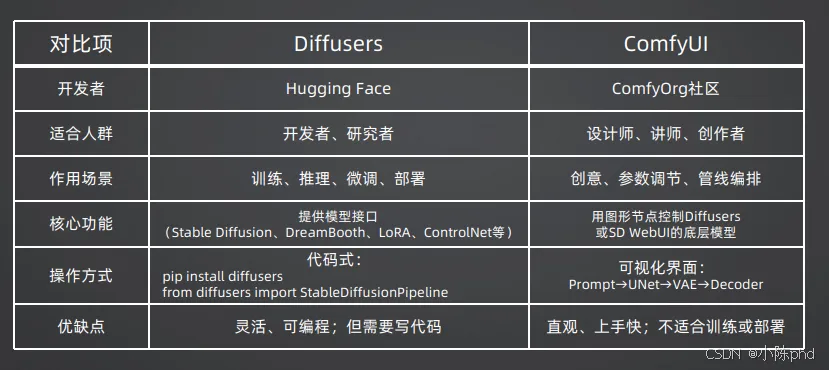
针对不同的使用人群,有两款主流的扩散模型工具,核心差异如下:
| | |
| | |
| | |
| | |
| 提供Stable Diffusion、DreamBooth、LoRA、ControlNet等全系列模型的编程接口 | 用图形化节点控制扩散模型底层逻辑,可视化编排生成流程 |
| | |
| | |
4 扩散模型的领域应用边界
扩散模型不仅能实现虚拟人2D形象生成,还能拓展到更多虚拟人相关的生成任务,核心应用边界如下:
- • 扩散模型核心擅长:Text-to-Image(文生图,虚拟人形象生成)、Text-to-Video(文生视频,虚拟人动态视频生成)、Text-to-3D(文生3D,虚拟人3D模型生成)、Text-to-Music(文生音乐,虚拟人背景音乐生成);
- • 自回归模型核心擅长:Text-to-Speech(文生语音,虚拟人语音合成)、Text-to-Code(文生代码,虚拟人交互系统开发);
- • 二者结合:是当前虚拟人全链路生成的主流方案,实现从形象、语音、视频到交互系统的全流程AI生成。
核心总结
虚拟人形象生成的核心,是扩散模型为代表的AIGC图像生成技术。从VAE、GAN到扩散模型,技术迭代的核心方向,始终是更低的生成门槛、更高的生成质量、更强的可控性。
对于虚拟人创作来说,Stable Diffusion是基础工具,LoRA/DreamBooth能帮你固定虚拟人的专属形象,ControlNet能帮你精准控制虚拟人的姿态和动作,三者结合,就能完成高质量虚拟人形象的全流程生成。
拓展指引
下一篇:《核心技术篇② | 虚拟人的大脑:国内头部大语言模型全解析》,我们会深入拆解虚拟人的“AI大脑”——大语言模型,看看国内头部LLM的技术特点,以及如何为虚拟人打造自主思考、实时交互的能力。