大语言模型(LLM)本质上是一个"闭门造车的学者"——它拥有海量知识,却存在三个致命局限:
•第一,知识有截止日期。 当你问"今天北京天气如何",模型无法回答,因为它的训练数据止于某个时间点。•第二,无法影响现实世界。 它可以告诉你"应该给张三发邮件",但无法真的帮你点击发送按钮。•第三,计算和记忆受限。 让它计算复杂公式或查询大型数据库,往往力不从心且容易出错。
工具调用(Tool Use) 正是为了解决这些问题而生。它让AI从"只会说话"进化为"能动手做事"——查询实时天气、操作GitHub仓库、发送邮件、控制浏览器、访问数据库,这些能力的本质都是让AI学会使用外部工具。
二、Function Calling机制与实现
Function Calling(函数调用)是OpenAI在2023年6月推出的技术,它定义了一套LLM与外部世界交互的标准协议。核心思想很简单:不是让LLM直接生成答案,而是让它生成"调用指令"。
首先LLM模型会收到一份关于工具的定义信息,这个定义是一段格式化的json,它定义了可用的工具列表,包括每个工具的名称、使用场景、调用参数等;
{ "type": "function", "function": { "name": "get_weather", "description": "获取指定城市的天气", "parameters": { "type": "object", "properties": { "city": { "type": "string", // 强制字符串类型 "description": "城市名称" }, "unit": { "type": "string", "enum": ["celsius", "fahrenheit"] // 强制枚举值 } }, "required": ["city"] // 强制必填字段 } }}
其次,当用户向LLM模型提问/交流时,模型判断需要调用某个工具,就会输出这个工具的调用要求。例如,当用户问"北京今天天气如何",LLM不会直接回答普通的文本,而是输出结构化JSON指令:
{ "tool_calls": [{ "function": { "name": "get_weather", "arguments": "{\"city\": \"北京\"}" } }]}
具体的工具调用由外部程序完成(LLM本身作为一个神经网络模型,不具备调用能力),外部程序接收到这个结构化指令后,执行实际的天气查询函数,再将结果返回给LLM,LLM最后基于真实数据生成自然语言回复。
这里的问题是,当用户输入与某个工具描述匹配时,如何保证LLM模型自发地生成tool_calls标准响应,而非普通文本语言。早期尝试过使用纯提示词方案(例如"如果需要调用外部工具,请输出JSON格式..."),但提示词方案取决于模型的指令遵循能力,可靠性不足,模型可能忘记格式、添加markdown标记、幻觉字段等等,导致下游程序调用失败。目前采用的主要方案是微调+约束解码:
•第一层:微调训练赋予决策能力
模型通过专门微调学会何时调用工具。训练数据包含大量"用户提问→工具调用→结果返回"的完整对话。模型内化了"工具描述与用户意图的语义匹配"能力——当看到"天气"相关的用户输入,且存在get_weather工具时,自动触发调用模式。这不是靠提示词"教"出来的,而是权重层面的能力内化,类似于模型学会翻译或算术。
•第二层:约束解码保障格式
仅靠训练还不够,模型可能生成格式错误的JSON。Function Calling的可靠性来自于约束解码(Constrained Decoding)技术。约束解码在Token生成的每一个步骤实时干预,确保输出100%符合JSON Schema,零语法错误。其与常规解码的对比示意图如下:
标准解码:
用户输入 → 模型计算 → 输出Logits(概率分布)→ Softmax → 采样 → 生成Token ↑ 完全自由采样
约束解码:
用户输入 → 模型计算 → 输出Logits → [约束处理器] → 屏蔽非法Token → Softmax → 采样 ↑ ↑ 原始概率分布 物理强制 │ (非法Token概率=-∞) ↓ 只允许合法Token
Function Calling实现了三个关键突破:
•标准化交互:无论底层工具是Python函数、REST API还是数据库查询,都统一为JSON格式的调用指令,AI只需学会一种"语言"。•确定性输出:通过约束解码,从概率生成转变为结构化输出,下游程序可以可靠解析执行,无需担心格式错乱。•能力解耦:AI负责"决策"(判断是否调用、调用哪个),外部程序负责"执行"(实际操作API),两者通过标准协议协作。
这为AI Agent的"动手能力"奠定了技术基础。但Function Calling也有局限:每个AI平台(OpenAI、Anthropic、Google)的实现细节不同,工具定义无法跨平台复用,就像USB-C出现前的充电接口乱象。其次工具开发与应用开发是紧耦合的,开发者需要完成工具定义、工具调用全流程,工具换了或者LLM模型换了,都可能需要重新在开发一遍。
三、MCP协议与工具生态
随着AI Agent复杂度的提升,Function Calling的"紧耦合"问题日益凸显:
•重复造轮子:每个应用开发者都要为同一工具(如查天气)重新编写函数实现•碎片化:OpenAI、Anthropic、Google的工具定义格式互不兼容•维护困难:工具更新需要修改所有使用该工具的应用代码
2024年11月,Anthropic推出Model Context Protocol(MCP),试图终结这种分裂局面。
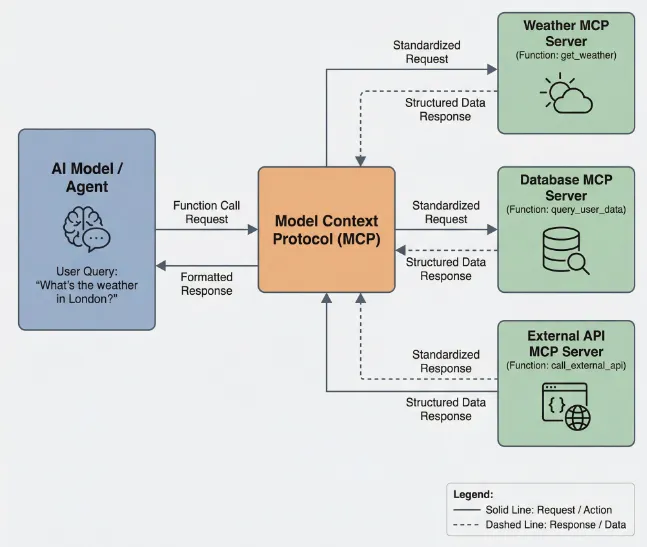
MCP不是替代Function Calling,而是对function call的封装,将其标准化、架构化、生态化。
核心架构:
•MCP Server:托管实际工具的服务,暴露标准化接口(支持stdio本地进程或HTTP远程连接)•MCP Client:内置于AI Agent,负责协议通信,自动完成工具发现和工具调用•通信协议:采用JSON-RPC 2.0,确保跨语言兼容
关键创新:
•解耦:工具开发者只需按MCP标准实现一次,专注完成MCP server的开发,任何支持MCP的AI应用都能即插即用;应用开发者,只需要专注应用逻辑的开发,工具集成通过MCP client完成,需要使用某个工具,只需配置对应的MCP server地址即可。•远程访问:通过SSE或Streamable HTTP传输,应用开发者无需下载代码,像访问网页一样连接云端工具•动态发现:连接Server后自动获取所有工具列表及其JSON Schema
举例来说:
•在传统function call机制下,如果需要使用GitHub工具,需要:复制粘贴JSON定义→本地实现函数→处理认证→维护更新。•现在使用MCP,开发者只需配置https://github.com/mcp,AI会自动发现create_issue、merge_pr等所有工具,即刻可用。
MCP带来的价值:
| | |
| | |
| | |
| | |
| | |
| | Server端统一控制,Client通过OAuth授权 |
| OpenAI/Anthropic/Google格式不一 | |
总结:MCP把工具调用从"编程任务"变成了"配置任务"——应用开发者只需指定Server地址,MCP Client自动完成发现、路由、调用、返回的全流程,无需编写任何工具逻辑代码。这种解耦催生了AI工具的"应用商店"模式,开发者通过一些平台很容易找到需要的工具。
•官方MCP Registry:Anthropic推出的元数据目录,聚合数千个MCP Server•托管平台:Pylee、TrueFoundry等提供一键部署和私有Registry•开源生态:社区涌现覆盖GitHub、Slack、浏览器、数据库的MCP Server
四、skill的兴起
在MCP生态快速发展的同时,另一个概念"Skill"(技能)也在兴起,尤其在Claude等平台上,Skill的本质是预配置的MCP Server组合+专用指令模板的封装。 他可以将提示词模板、工具配置、执行逻辑、资源等等打包起来行程一个专业的技能包,AI加载某个Skill后,就自动具备了这个领域的能力。下一篇我们将对skill这个概念,进行专门的介绍。

