学习笔记:临床回顾性实用指南(五)数据的收集、录入及整理
- 2026-04-16 21:59:08
基线资料 baseline characteristics
总体生存情况 overall survival
无进展生存期 progression free survival, PFS
时间-事件资料 time-to-event data
统计产品与服务解决方案 statisitical product and service solutions, SPSS
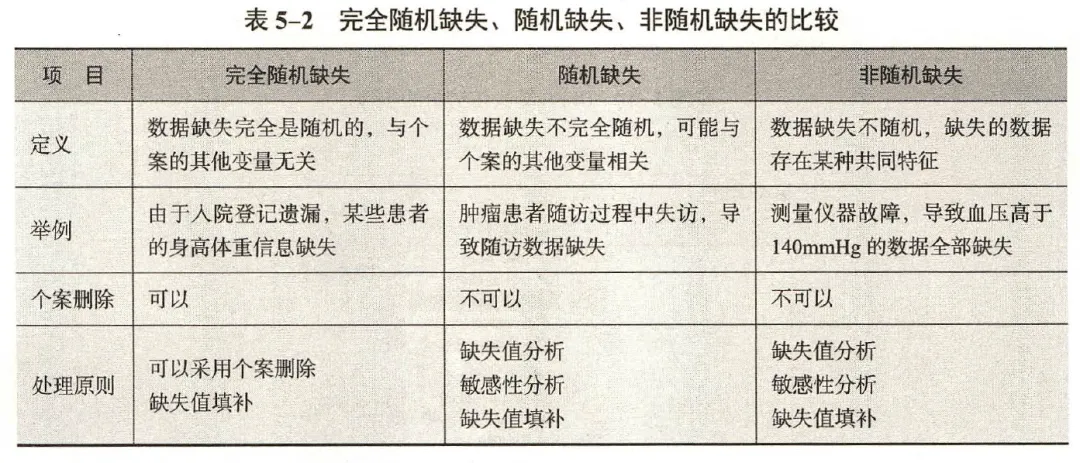
完全随机缺失 missing completely at random, MCAR
随机缺失 missing at random, MAR
非随机缺失 missing not at random, MNAR
 |
 |
NHANES is the only national health survey that includes health exams, laboratory tests, and dietary interviews for participants of all ages.NHANES是美国唯一一项针对所有年龄段参与者开展健康检查、实验室检测以及饮食调查的全国性健康调查项目。  数据库首页 数据库首页 |
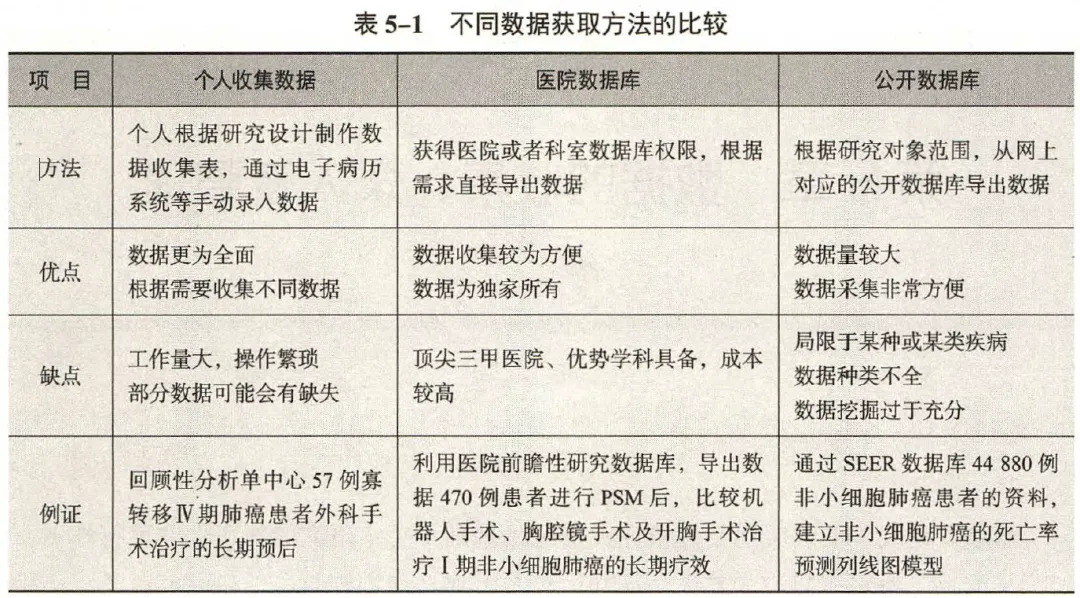
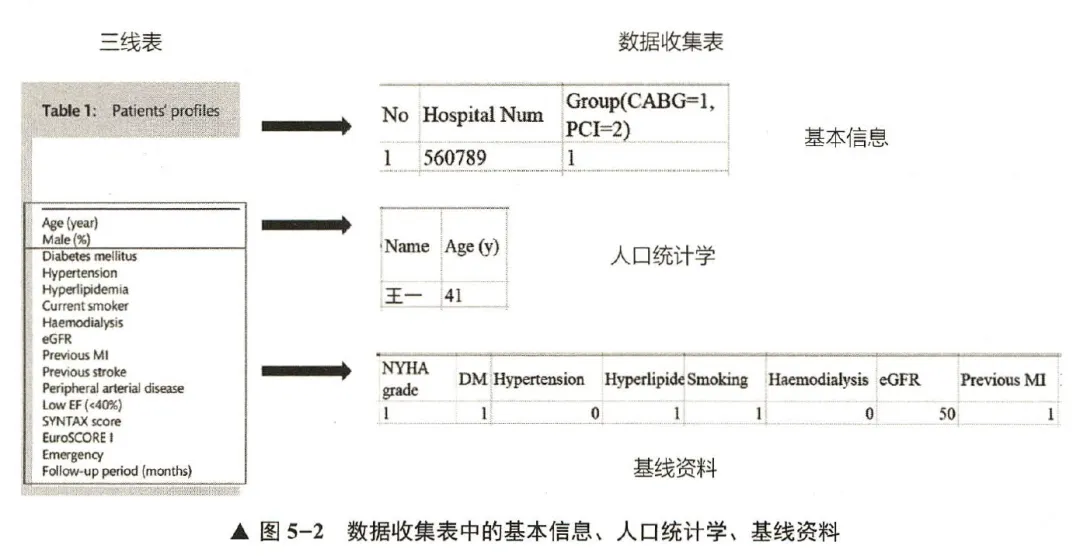
个人收集--通过数据收集表收集数据
数据收集表行内容通常可以分为序号、ID (住院号、识别号、姓名)等基本信息,性别、年龄、民族、身高、体重等基本的人口统计学信息,诊断、并发症、病理学结果、实验室检查、影像学检查等基线资料,干预措施、干预时间等治疗资料,以及短期疗效、并发症发生率等疗效资料,还有长期随访结果的随访资料。
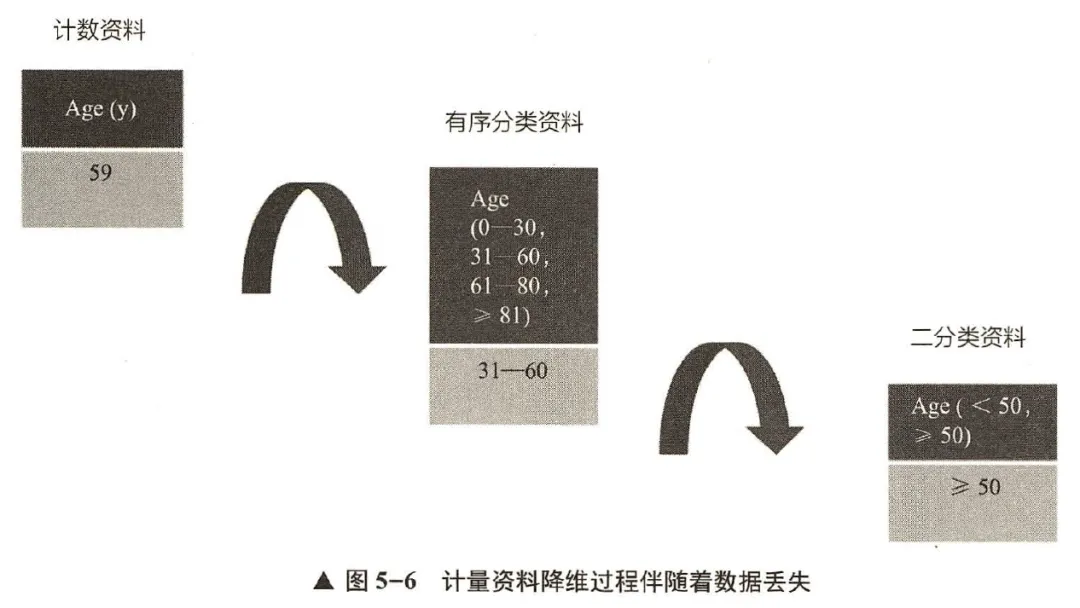
(1)计量资料:计量资料是指监测每个研究个体的某项指标的大小而获得的资料,表现为数值大小,一般都度量衡单位。常见的年龄、白细胞计数、BMI指数都是计量资料,表现为数值大小,可以用平均数±标准差或者中位数、四分位数表示。在用数据收集表记录计量资料时,应当直接录入原始数据,并尽可能保留原始数据的小数位数。
(2)计数资料:计数资料是将全体观察单位按照某种性质或特征分组,然后再分别清点各组观察单位的个数获得的资料,因而又称定性资料或分类资料。根据种类数及是否有序,计数资料又可以分为二分类资料、无序分类资料和有序分类资料。
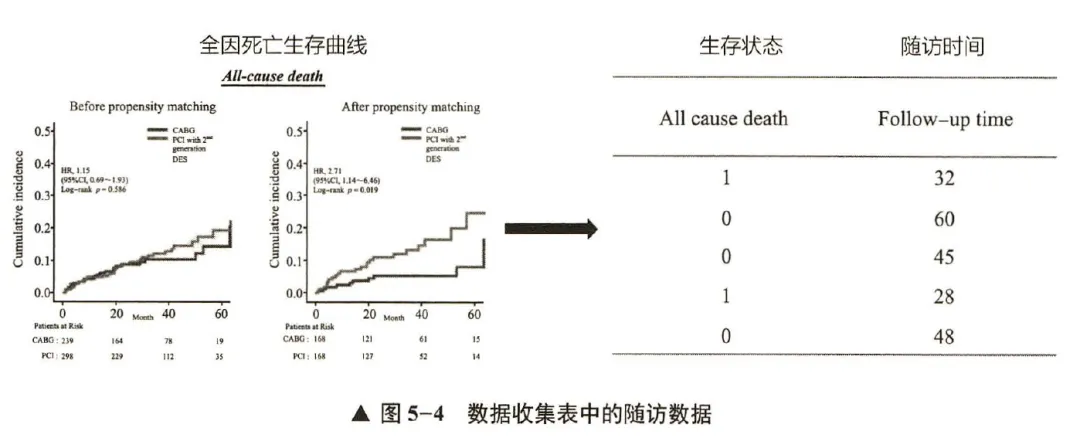
(3)生存资料:生存资料是一种特殊类型的资料,包含有生存状态和随访时间两个要素。

数据收集中的注意事项:①尽量记录原始数据;②确保数据的真实准确性
数据的清洗和整理是指把原始数据整理成可以进行统计学分析的数据格式。
数据清洗:确定变量-统一格式-处理缺失
SPSS软件
统计学分析运算、数据挖掘、预测分析、决策支持
支持导人和导出Excel数据,进行统计分析后可以输出统计分析结果和图表
SPSS设定的变量类型有三种,即名义、有序和标度,分别对应无序分类资料、有序分类资料和计量资料。
数据缺失分析
数据缺失过多(一般认为大于10%)可能会导致统计偏倚,影响统计结果
SPSS→分析→缺失值分析
缺失数据的处理:
简单删除-缺失值不多(<10%),并且缺失数据为完全随机缺失或随机缺失数据,删除后对整体数据影响不多
缺失插补-临近点平均值法、序列平均值法、回归估计值法、期望最大化法、多重插补法
多重插补法源自贝叶斯估计,认为插补值是随机的,且源自已观测到的值
SPSS→分析→多重插补→插补缺失值数据

