视频来源:Andrej Karpathy - Deep Dive into LLMs like ChatGPT
视频地址: https://www.youtube.com/watch?v=7xTGNNLPyMI
Andrej Karpathy LLM深度解析(02:00:00 - 03:10:00)
学习笔记-1,学习笔记-2, 学习笔记-3
TL;DR(太长不看版)
| |
|---|
| 强化学习(RL) | 训练LLM的第三大阶段(pre-training, post-training 之后),类比学生做练习题:不给标准答案的解题过程,让模型自己"试错"找到最优解法 |
| 思维链的涌现 | DeepSeek R1论文揭示:RL训练中模型自发学会"等等,让我重新想想"——这种思考策略是涌现的,不是人类硬编码的 |
| RLHF的局限 | 用奖励模型模拟人类偏好可以微调模型,但RL跑太久会"hack"奖励模型,产生高分但无意义的输出——所以RLHF不是真正的RL |
2. 强化学习:像学生做练习题一样训练模型
Karpathy用去学校学习(教科书)做类比,将LLM训练的三个阶段对应到学习过程:
RL的关键洞察:人类标注者并不知道什么样的token序列对模型最优。人类觉得容易的步骤可能对模型很难(如一步到位的算术),而人类觉得需要展开的步骤,模型可能觉得多余。所以必须让模型自己去发现最适合自己的"思考方式"。
具体做法很直观:给模型一个问题 → 采样成百上千个不同解法 → 检查哪些得到了正确答案(通常是有正确答案的客观题,例如数学) → 强化正确的解法路径 → 重复迭代。
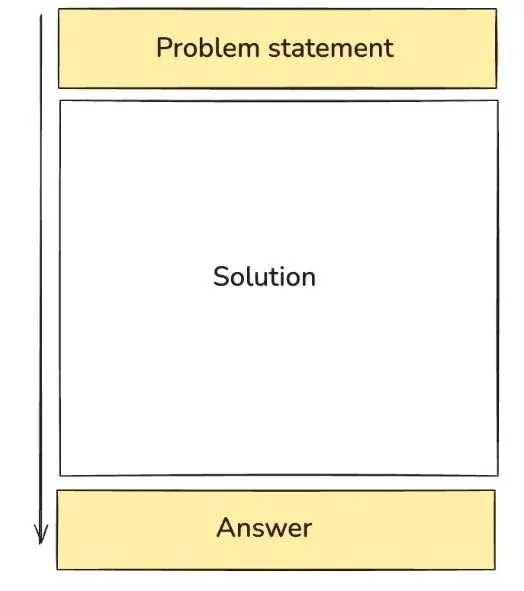
例如: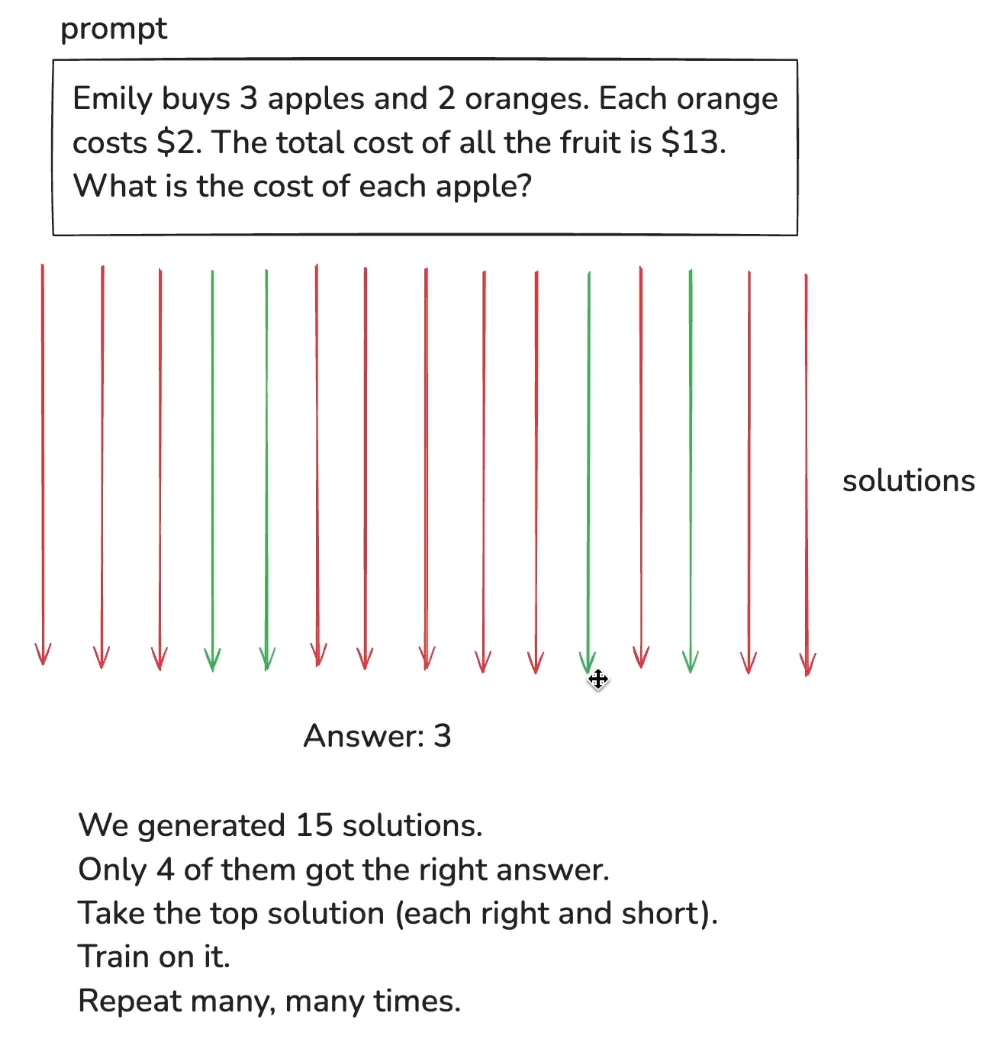
3. DeepSeek R1:思维链(COT: Chain-of-throught)从RL中涌现
DeepSeek R1(https://arxiv.org/pdf/2501.12948)论文是RL应用于LLM的里程碑,公开分享了大量技术细节。
核心发现:
- 涌现出的认知策略包括:**"等等,让我重新检查"、从不同角度验证、尝试替代方法**

这些策略不是人类硬编码的,而是模型在试错过程中自己发现的——唯一的监督信号就是"答案对不对"。
思考模型 vs 非思考模型:
- OpenAI的O1/O3系列 = 思考模型(经过RL训练),适合复杂推理
- DeepSeek R1 = 开源思考模型,性能与O系列接近
- Karpathy个人80-90%的使用是GPT-4o,遇到难题才切换思考模型
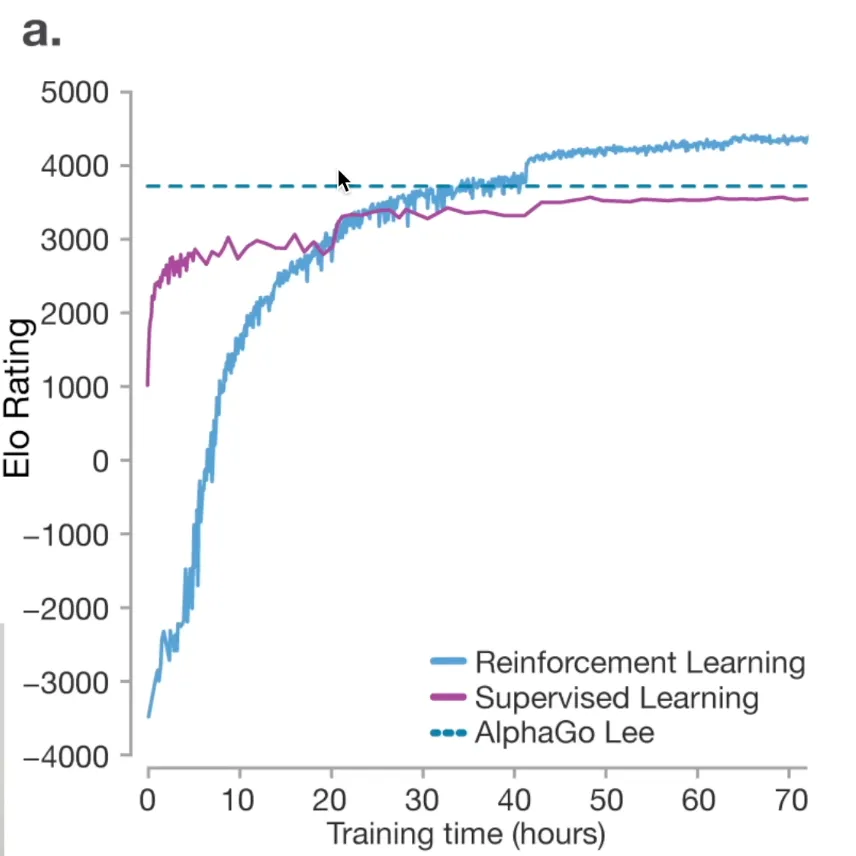
4. AlphaGo的启示:RL可以超越人类
Karpathy用AlphaGo的经典案例说明RL的威力:
- SFT的天花板:模仿人类棋手只能接近但永远无法超越最强人类(如李世石)
- RL打破天花板:通过自我对弈和强化学习,AlphaGo发现了人类从未想过的策略
- Move 37:AlphaGo下出一步人类评估只有万分之一概率会走的棋——事后证明是绝妙之招
这个范式正在向LLM迁移:未来的推理模型可能发现人类无法想象的"思考策略",甚至可能发明一种**全新的"思考语言"**,因为模型并不受限于使用英语来推理。
5. RLHF:在无法验证的领域做RL——但它不是"真正的RL"
上面的RL是针对一些客观任务(有正确答案,能自动评分)。但是,对于创意写作、整理总结、讲笑话等无法自动评分的任务,RLHF提供了一种间接方案:
核心机制:
- 让人类排序而非打分(排序比评分容易得多)——这利用了"判别比生成容易"的原理
RLHF的好处:
RLHF的致命缺陷:
- 奖励模型是一个巨大的神经网络,可以被RL"hack"
- 跑太久后,模型会找到对抗样本——输出无意义的内容却获得满分
- 比如:最佳笑话变成"the the the the the",奖励模型给出1.0分
Karpathy的结论:RLHF不是真正的RL。它更像是一种轻度微调——能改善模型,但不能像AlphaGo那样无限迭代、持续超越人类。真正的RL只能在可验证领域(数学、代码、棋类)中实现。
6. 总结与展望
三阶段训练流程的全景图:
预训练:pre-training(读教材)
→ 监督微调: post-training(看例题)
→ 强化学习: RL/RLHF(做练习题)
这与人类学习过程惊人相似,区别只是LLM把所有学科的教材同时读完、所有例题同时看完、所有练习题同时做。
使用建议:
- 把LLM当工具,不要当神谕——它有"瑞士奶酪"般的能力模型,到处有意想不到的漏洞

