一、python深度学习中的epoch和batch是什么意思Epoch(训练轮次)是模型完整遍历一次训练数据集的完整周期。一个Epoch包含多次权重更新(每个Batch更新一次),多个Epoch让模型反复学习数据特征,逐渐从初步认知到精细调优,最终达到稳定收敛。代码中设置NUM_EPOCHS=5意味着模型将把整个训练集完整学习5遍,每个Epoch后都会进行验证和保存检查点。Batch(批次)是将训练数据分成的小组,模型一次处理一个Batch而非单个样本。在深度学习中,Batch是内存效率、计算并行化和稳定优化的平衡点——大Batch加快训练但需要更多显存,小Batch噪声多但泛化可能更好。代码设置BATCH_SIZE=1(在线学习)适合CPU训练,每个Batch包含一张图像及其标注,每个Epoch中会有“总样本数/Batch大小”次权重更新。
二、torch.save() 函数是怎么用的
torch.save() 是 PyTorch 中保存模型、张量或任意Python对象到磁盘的核心函数。
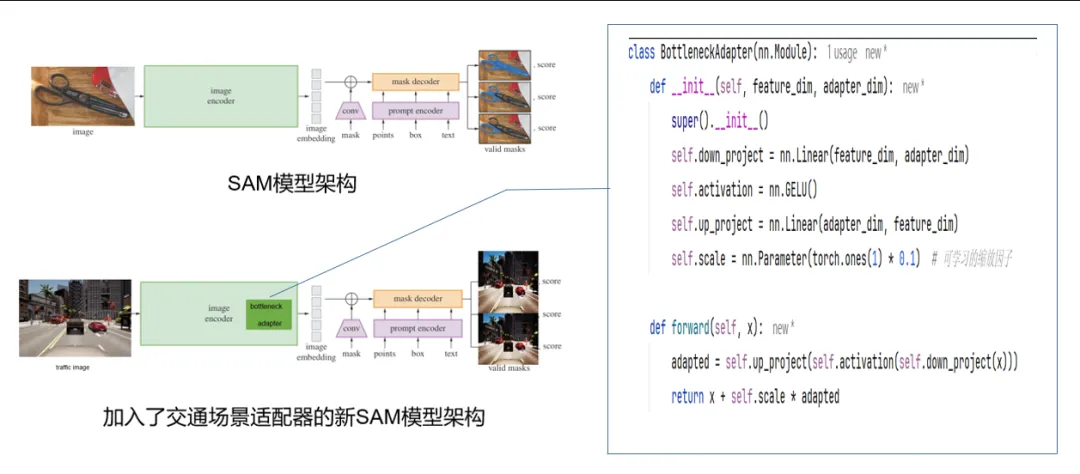
SAM模型由两部分组成:架构代码定义模型结构(如ViT编码器、提示编码器、掩码解码器),而.pth文件是保存训练后参数值的权重文件。.pth本质是一个Python序列化的字典,存储了模型每一层的权重张量,比如卷积核参数、归一化层参数等。使用时先用代码构建模型骨架,再将.pth文件中的权重加载到对应层中,两者结合才形成完整的可执行模型。
三、在SAM模型里加入的交通适配器是什么
torch.nn 是 PyTorch 的神经网络标准库,它提供了一套完整的工具集用于构建和训练深度学习模型,就像一个专业木工的工具箱。在这个工具箱中,各种网络层如同基础工具:卷积层(Conv2d)好比锯子,擅长提取图像的局部特征,能将输入数据“切割”成有意义的局部模式;全连接层(Linear)如同锤子,通过加权求和将特征“敲打”组合成更高层次的表示;归一化层(BatchNorm)则像砂纸,平滑优化过程,加速训练收敛;而 Dropout 层相当于安全开关,随机断开连接以防止模型过拟合。
损失函数(如 CrossEntropyLoss、MSELoss)充当了尺子的角色,精准衡量模型预测与真实值之间的“误差距离”,为优化提供明确方向。所有模型的基类 nn.Module 则如同一个多功能工作台,所有组件都在此基础上搭建,它提供了参数管理、设备迁移、状态保存等核心功能。容器(Sequential、ModuleList 等)好比组装架,帮助工程师将各种层模块化地组织成完整的网络架构。
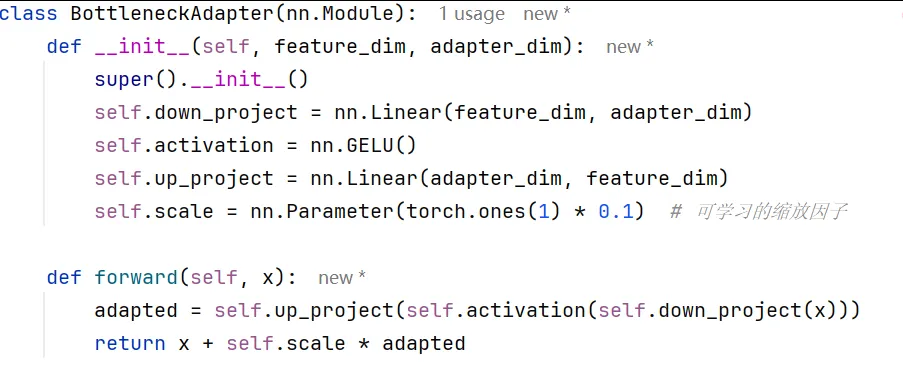
交通适配器采用了经典的瓶颈(Bottleneck)结构,其核心是由降维层、激活函数和升维层构成的轻量化模块。降维层(down_project)将SAM提取的高维交通场景特征(如1280维)压缩至低维空间(如160维),这大幅减少了可训练参数量,既能有效防止在有限交通数据上的过拟合,又降低了计算开销。随后通过GELU激活函数引入非线性变换,该函数相比ReLU更为平滑,更适合Transformer架构的特性。升维层(up_project)则将处理后的特征恢复至原始维度,与原始特征通过可学习的缩放因子进行残差连接,这种设计确保了适配器在注入交通场景知识的同时,不会破坏SAM预训练获得的通用视觉表示能力。
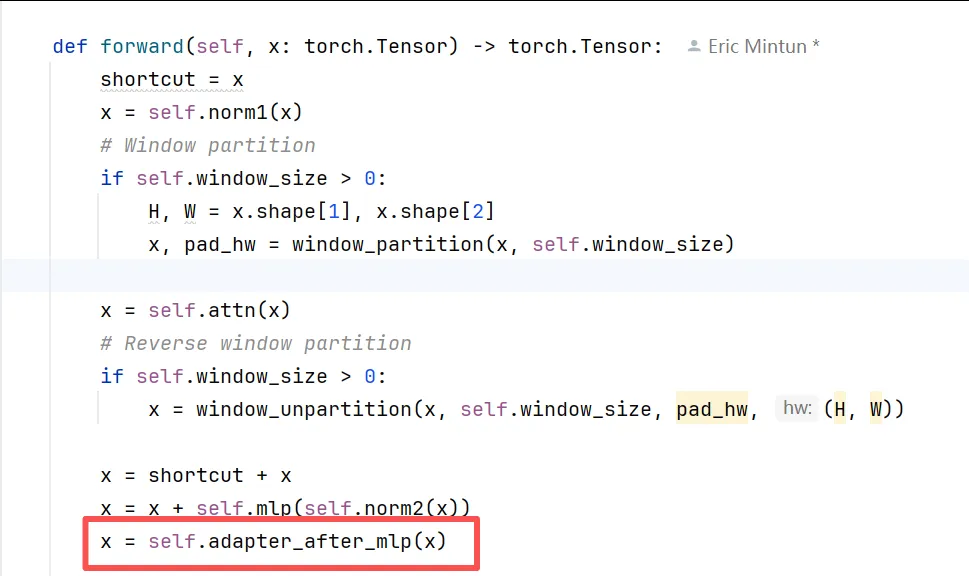
适配器被插入在每个Transformer Block的MLP层之后,这是因为视觉特征在MLP处理后已经过充分融合,此时加入领域适配能最有效地将通用特征向交通场景调优。整个结构通过严格的参数冻结机制实现——仅新加的适配器层可训练,原始SAM主干完全冻结,这保证了模型既保留在11亿张图像上学到的强大泛化能力,又能专注学习交通场景特有的语义模式。这种组件组合体现了参数高效微调的核心思想:以最小的新增参数量,实现特定领域的性能提升。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
