摘要:线性回归只关心预测准不准,不关心权重本身合不合理。Ridge和Lasso在损失函数里加了约束,Ridge让权重均匀变小,Lasso把不重要的直接清零。这篇把房价数据79维特征做到224维,对比三种模型的差异,也说清楚什么时候该用哪个。
上篇用线性回归把房价预测做到了 R² 0.84。收尾时留了一句话:"还有提升空间"。说的是还有类别特征没处理。
这次把全部79列处理完了。数值型用中位数填充缺失,序数型(如ExterQual的质量评级)映射为1-5数字,名义型(如Neighborhood等无顺序类别)做独热编码展开为 0/1 哑变量。一套下来特征数从14跳到224维,数据预处理方法具体实现见 notebook。线性回归直接跑到了R² 0.92,但今天的主角不是线性回归。是它的两个升级版,Ridge 和 Lasso。
一、线性回归有什么不够好?
先明确一点:线性回归、Ridge、Lasso 三个模型的形式完全一样,都是
ŷ = w₁x₁ + w₂x₂ + ... + b
区别不在形式上,在怎么求解w。线性回归求w只看一件事:预测准不准。数学上就是让MSE最小。这个问题在于特征之间有关系时,可能有多组 w 都能让预测误差差不多小。举个例子:面积和房间数高度相关。你可以给面积赋100、房间数赋-99,也可以给面积赋1、房间数赋0。预测结果几乎一样,R² 一样高。
但前一组权重明显不合理,某个变量稍微变一点,预测值就剧烈抖动。换一套数据可能就失效。这就是线性回归的隐患:它只关心结果准不准,不关心权重本身合不合理。
Ridge和 Lasso做的是同一件事:不仅要预测准,权重还得合理。两者区别在于怎么求解w。
二、Ridge:L2 惩罚,让权重变小
Ridge 的损失函数:
多出来的就是 L2 正则项。α 控制惩罚力度:α=0 等价于普通线性回归,α 越大权重被压得越小。一般按数量级试(0.01、0.1、1、10、100),看测试集效果选。看参数更新这一步就知道它怎么起作用的:
self.w -= self.lr * dw # 线性回归
self.w -= self.lr * (dw + self.alpha * self.w) # Ridge
Ridge多了self.alpha * self.w,表明每一轮更新,w 不仅往误差减小的方向走,还被衰减一部分。α·w 的拽力和 w 本身成正比,w=2 时衰减量是 w=0.1 的 20 倍。跑完2000轮,所有权重都比原来小,但都不为0。大大的衰减多,小的衰减少,结果是均匀压缩。在深度学习里,称为 weight decay(权重衰减),每一轮更新都让权重缩一点,和 Ridge 的 α·w 是同一个操作。Ridge 没有主动选择哪些变量重要,只是把所有权重均匀压小一圈。
三、Lasso:L1 惩罚,让权重变零
Lasso 的损失函数:
就是把 Ridge 的 w² 换成了 |w|。别小看这个变化。看梯度:
self.w -= self.lr * (dw + self.alpha * sign(self.w))
sign(w) 在 w > 0 时是 +1,w < 0 时是 -1。它跟 w 的大小无关。 w=10 和 w=0.01 受到的惩罚力度是一样的。
结果就是:Lasso 对每个权重加的是一个固定力度的惩罚,不管 w 多大,惩罚量都一样。对于不重要的特征(跟预测目标关联弱),数据本身的梯度信号很弱,压不过这个固定惩罚,权重被推到 0 就再也出不来了。对于重要的特征(跟目标关联强),数据梯度信号强,能克服惩罚,权重才得以保留非零。
重要的特征保留,不重要的变成 0。 这就叫稀疏解。(实际跑的时候可能不会精确等于 0——梯度下降很难钉在 0 上,只会"接近 0"。sklearn 的 Lasso 用坐标下降才能稳定归零。)
四、两者核心区别
Ridge 让权重变小,Lasso 让权重变少。
五、房价数据的预测应用
House Prices 全量特征工程后的数据长这样:
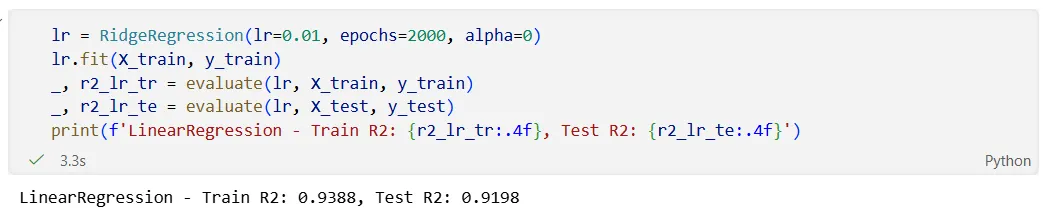
先用 Ridge(α=0) 跑一遍,等价于普通线性回归:
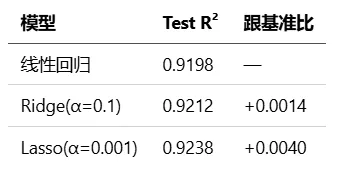
训练集和测试集只差 0.019。224 维对应 1168 个样本(约 1:5),模型没有严重过拟合。
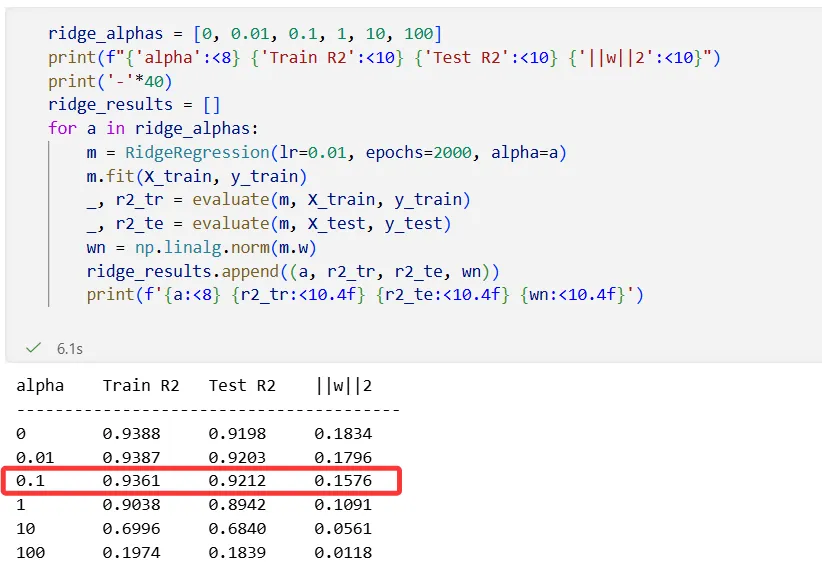
α=0.1 时最好。权重范数从 0.183 降到 0.158——所有权重均匀缩小了一圈。
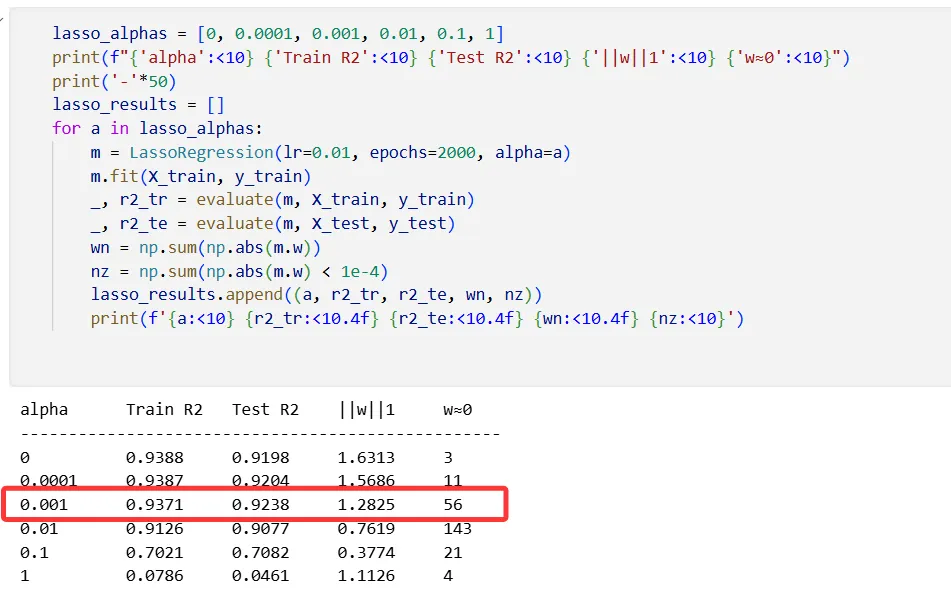
α=0.001 时最好,56 个特征被压到接近 0。Lasso 的 α 只有 Ridge 的百分之一,L1 的恒定惩罚比 L2 的线性惩罚强。
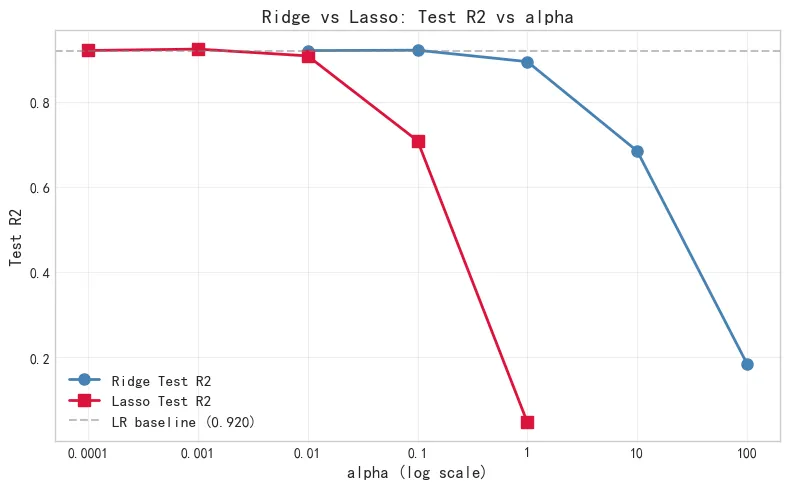
Ridge vs Lasso 的 Test R² 随 α 变化曲线。Ridge 蓝色,Lasso 红色,灰色虚线是线性回归基线。 两条线都是用 α=0(即普通线性回归)起步,随着 α 增大,正则化效果先变好再变差,呈现明显的倒 U 型。Ridge 在 α=0.1 左右达到最佳,Lasso 在 α=0.001 左右达到最佳,说明合适的正则化强度能小幅提升泛化效果,但压过头反而更差。
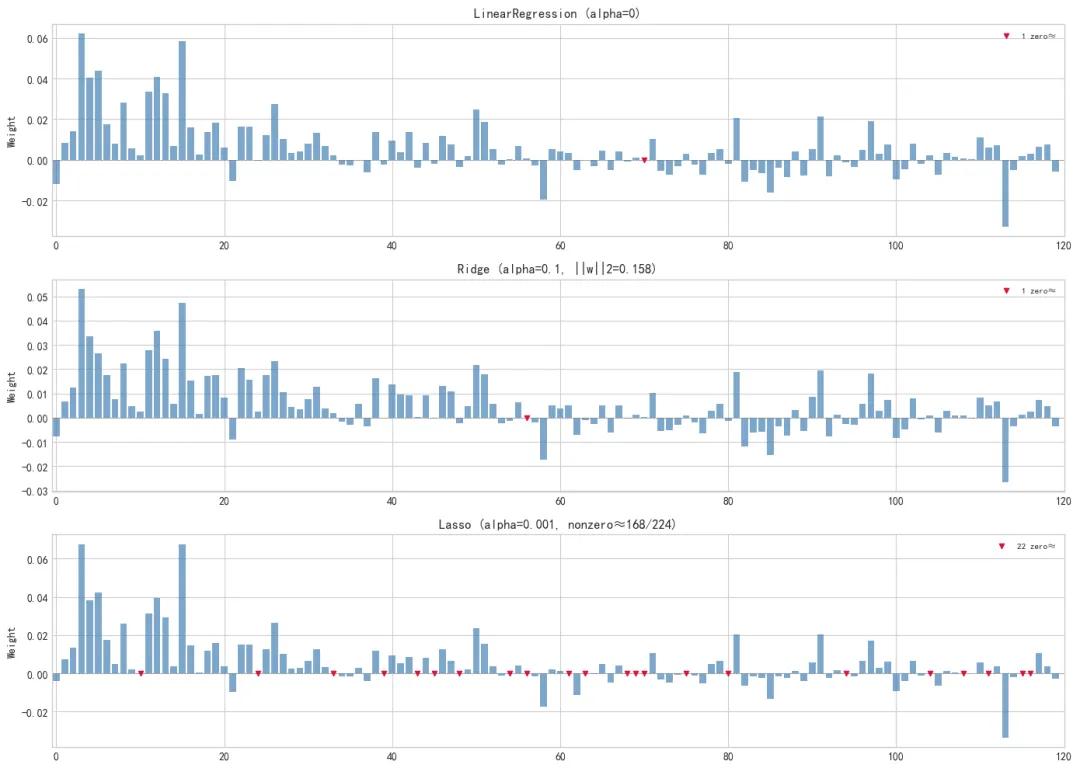
选前 120 个特征看三个模型的权重分布(前 58 个是数值+序数型,后面是独热编码产生的哑变量):
- Ridge:形状跟 LR 几乎一样,只是整体矮了一截
- Lasso:部分权重被压到几乎看不见(红色标记),形成稀疏解
三张权重条形图并排:LR → Ridge → Lasso,红色柱表示接近 0 的权重。从上到下对比看:LR 的权重分布最散,高低不平;Ridge 整体矮了一截但形状没变,正是均匀压缩的效果;Lasso 在右边多个位置出现红色标记(权重归零),正是稀疏解的表现。
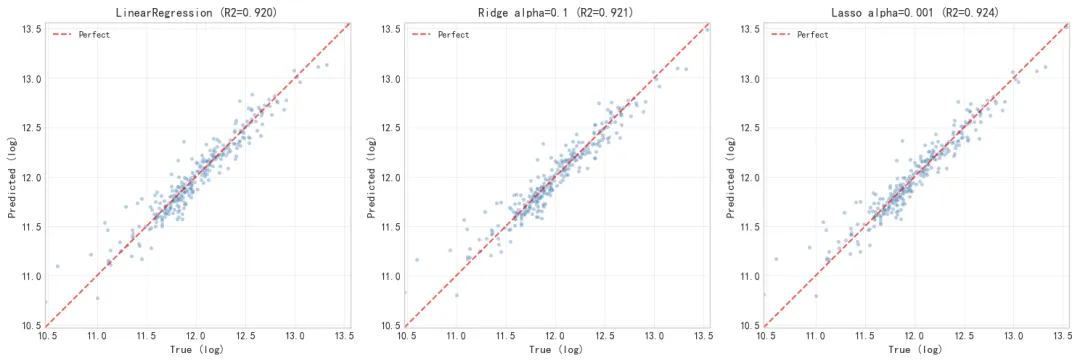
三个模型的真实值 vs 预测值散点图。数据点越贴近对角线越好。三张图差别不大,说明三个模型的预测效果很接近,也解释了 R² 只有 0.004 的提升,模型本来就没过拟合,正则化帮不上太多忙。
Ridge和Lasso的提升不大。原因就是特征/样本比才 1:5,模型本来就没过拟合。如果特征数和样本数差不多(比如 500 特征 × 500 数据),Ridge 和 Lasso 的作用会明显得多。Kaggle 上有个专门的竞赛就叫 Don't Overfit! II——300 个连续型特征、训练集只有 250 条,随便一个线性回归都能把训练集 R²/准确率撑到接近 1.0,但测试集一塌糊涂。这种场景下 Lasso 的效果远好于普通线性回归。
六、怎么选择线性回归模型?
- 不知道特征重不重要,想保下限:Ridge。L2 均匀压缩所有权重但不归零,不会丢掉可能有用的信息。大部分场景下 Ridge 比线性回归稳定,又不需要调太狠的参数,是最省心的起点。
- 特征特别多、大部分可能是噪音:Lasso。L1 自动把不重要特征的权重打成 0,相当于在做特征选择。你只管把所有能想到的特征塞进去,Lasso 自己会挑。但如果相关特征之间高度共线,Lasso 的随机性比较大。
- 想看模型认为哪些特征有用:Lasso。训练完后看哪些特征的权重是 0,哪些就是模型认为没用的。Ridge 也有权重大小可以做参考,但它没有精确归零的能力,分界线模糊。
- 特征之间高度相关(比如面积和房间数):Ridge。Lasso 在高度相关的特征组合里倾向于随机选一个保留、其余清零,结果不稳定;Ridge 则给每组相关特征分配相近的权重,更稳健。
- 既要特征选择又要分组稳定性:ElasticNet(L1+L2 混合)。把 Ridge 和 Lasso 的损失项加在一起,L1 负责稀疏化、L2 负责稳定相关特征的权重分配,实际项目中经常用。感兴趣可以搜"ElasticNet 回归"了解细节,这里不展开了。
七、代码和实现
实现代码:models/ridge_regression.py, models/lasso_regression.py
实现 notebook:notebooks/day2_ridge_lasso.ipynb
在GitHub上可以下载,https://github.com/HuangWuwutelling/ml-learning
下一篇讲逻辑回归(Logistic Regression)。虽然名字带回归,但实际做的是分类,用 Sigmoid 函数把线性回归的输出压缩到 0~1 之间,变成概率。