摘要:上一篇文章梳理了 bthread 的类型体系,看到 bthread_mutex_t 内部持有一个 butex 指针。本文深入这个指针背后的实现:一个 unsigned 如何被拆成 locked + contended 两个字节,trylock 如何用单字节 exchange 实现无竞争路径的最快加锁,竞争路径如何通过 butex_wait 让出 CPU 而非阻塞线程,以及解锁时如何根据状态决定是否唤醒。此外,brpc 还通过符号拦截(symbol interposition)让 pthread_mutex 也享受竞争分析能力。在前一篇文章中,我们看到 bthread_mutex_t 的定义:typedef struct bthread_mutex_t { unsigned* butex; // 核心:指向 butex bthread_contention_site_t csite; // 竞争统计 bool enable_csite; // 是否启用统计 mutex_owner_t owner; // 持有者(仅调试)} bthread_mutex_t;
一个 unsigned* 指针就能实现一把完整的互斥锁?是的。本文深入拆解这个 butex 指针背后的精妙实现。
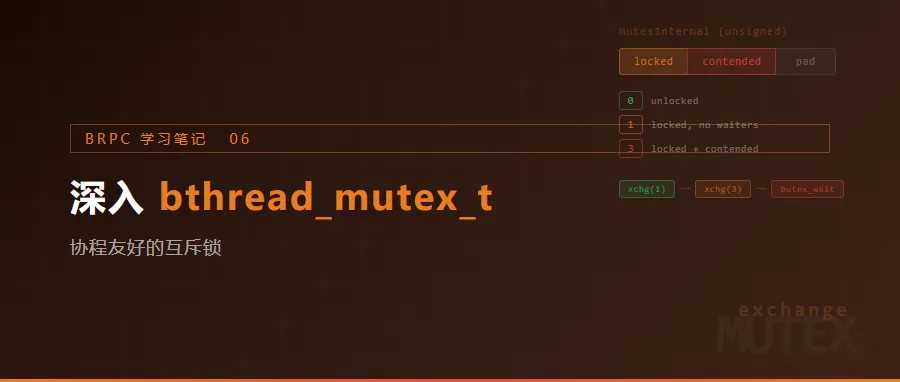
一、MutexInternal:一个 unsigned 的位拆分
bthread_mutex_t 的核心在于 *butex 这个 unsigned 值。它被 reinterpret_cast 为 MutexInternal 结构体,拆成三个字段:
struct MutexInternal { butil::static_atomic<unsigned char> locked; // 字节 0:锁定标志 butil::static_atomic<unsigned char> contended; // 字节 1:竞争标志 unsigned short padding; // 字节 2-3:未使用};
| byte 0 | byte 1 | byte 2-3 || locked | contended | padding |
作为整体 unsigned 解释时,只有三个有效状态值:
为什么要把 locked 和 contended 分成独立的字节,而不是用一个整数的两个位?这是精心设计的:
trylock 只需修改 locked 字节(单字节 exchange),不需要读-改-写 contended。 在 x86 上,单字节 exchange 只需一条 XCHG 指令,比 CAS(compare-and-swap)更简洁。这是无竞争路径——也是最常见的路径——能做到最快的关键。
竞争路径的 exchange 操作整个 unsigned,原子地同时设置两个标志。 这保证了 locked 和 contended 的状态转换是原子的,不存在中间状态。
const MutexInternal MUTEX_CONTENDED_RAW = {{1},{1},0}; // locked=1, contended=1 → 值为 3const MutexInternal MUTEX_LOCKED_RAW = {{1},{0},0}; // locked=1, contended=0 → 值为 1#define BTHREAD_MUTEX_CONTENDED (*(const unsigned*)&MUTEX_CONTENDED_RAW) // 3#define BTHREAD_MUTEX_LOCKED (*(const unsigned*)&MUTEX_LOCKED_RAW) // 1
二、初始化与销毁
2.1 bthread_mutex_init
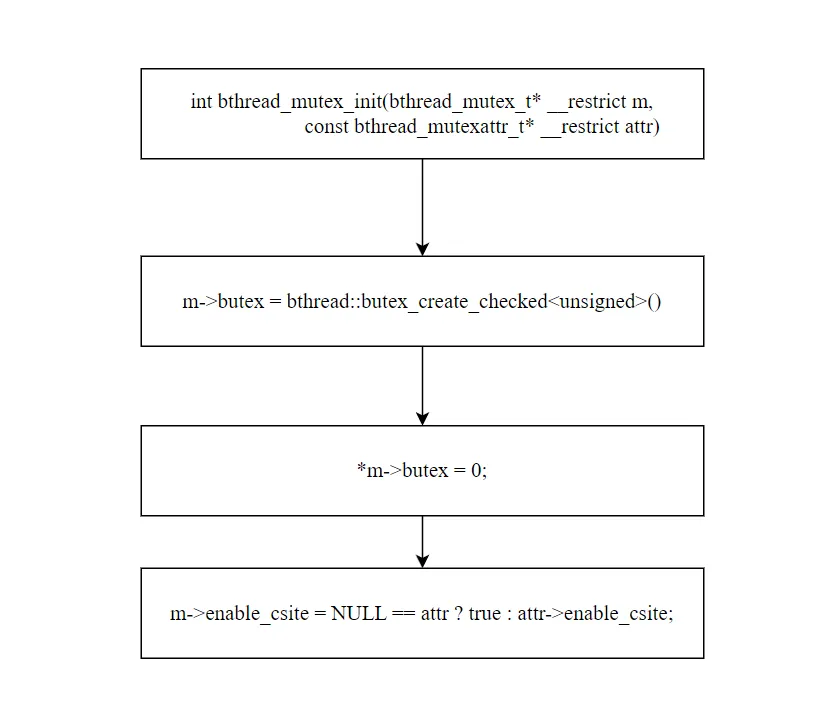
intbthread_mutex_init(bthread_mutex_t* m, constbthread_mutexattr_t* attr){ m->butex = bthread::butex_create_checked<unsigned>(); // 从 ObjectPool 分配 butex *m->butex = 0; // 初始状态:未锁定 m->enable_csite = (attr == NULL) ? true : attr->enable_csite; return 0;}
butex 从 ObjectPool 分配(参见本系列第二篇),初始值为 0(未锁定)。默认启用竞争统计。2.2 bthread_mutex_destroy
intbthread_mutex_destroy(bthread_mutex_t* m){ bthread::butex_destroy(m->butex); // 归还到 ObjectPool return 0;}
归还到 ObjectPool 后内存不释放——这是有意为之。上一篇文章(butex)分析过,butex_wake 和 butex_destroy 之间存在竞态,ObjectPool 的"永不释放"特性保证了安全。
三、trylock:无竞争的最快路径
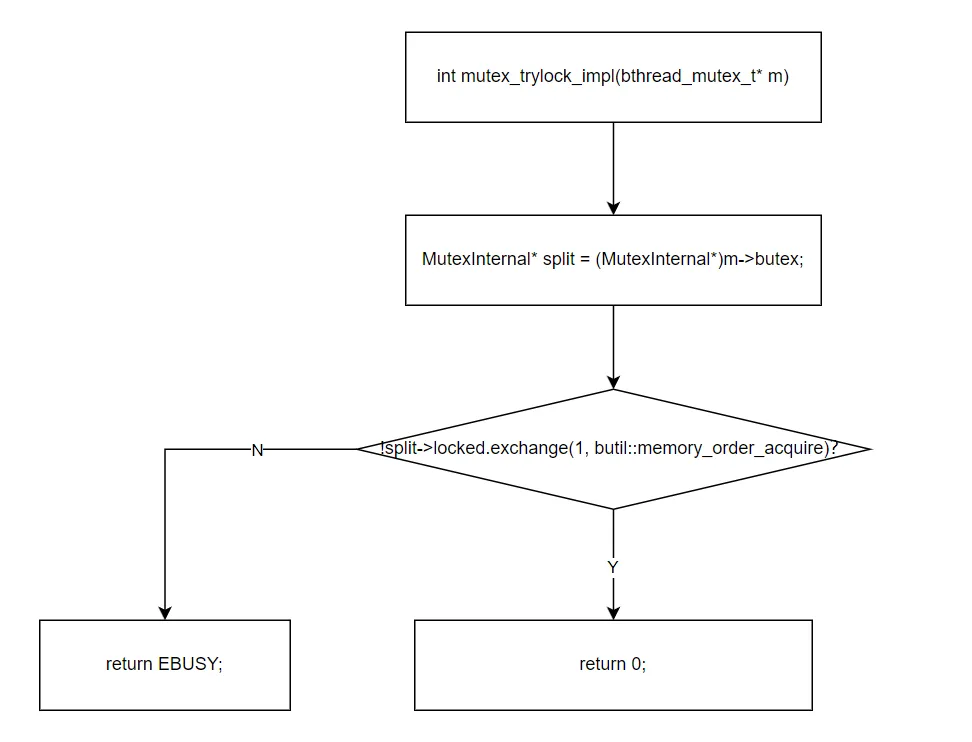
inlineintmutex_trylock_impl(bthread_mutex_t* m){ MutexInternal* split = (MutexInternal*)m->butex; if (!split->locked.exchange(1, butil::memory_order_acquire)) { return 0; // 旧值为 0,加锁成功 } return EBUSY; // 旧值为 1,锁已被占用}
整个过程只需一次操作:单字节 exchange(1)。
为什么用 exchange 而不是 CAS?对于 trylock,exchange(1) 返回 0 即表示成功,等价于 CAS(0→1),但代码更简洁。在 x86 上两者都编译为 XCHG 指令,性能相同。
注意:trylock 只操作 locked 字节,不触碰 contended。trylock 不等待,不会成为等待者,也不影响现有的等待者队列。
四、lock:从快到慢的两级策略
加锁分两步:先 trylock(无竞争快速路径),失败后进入竞争路径。4.1 第一步:trylock
staticintbthread_mutex_lock_impl(bthread_mutex_t* m, const timespec* abstime){ if (0 == mutex_trylock_impl(m)) { return 0; // 无竞争,直接拿到锁 } // 竞争路径...}
如果 trylock 成功,直接返回——这是最理想的情况,无任何等待。4.2 第二步:竞争路径 mutex_lock_contended_impl
trylock 失败后进入竞争路径。这里有三个精巧的设计:
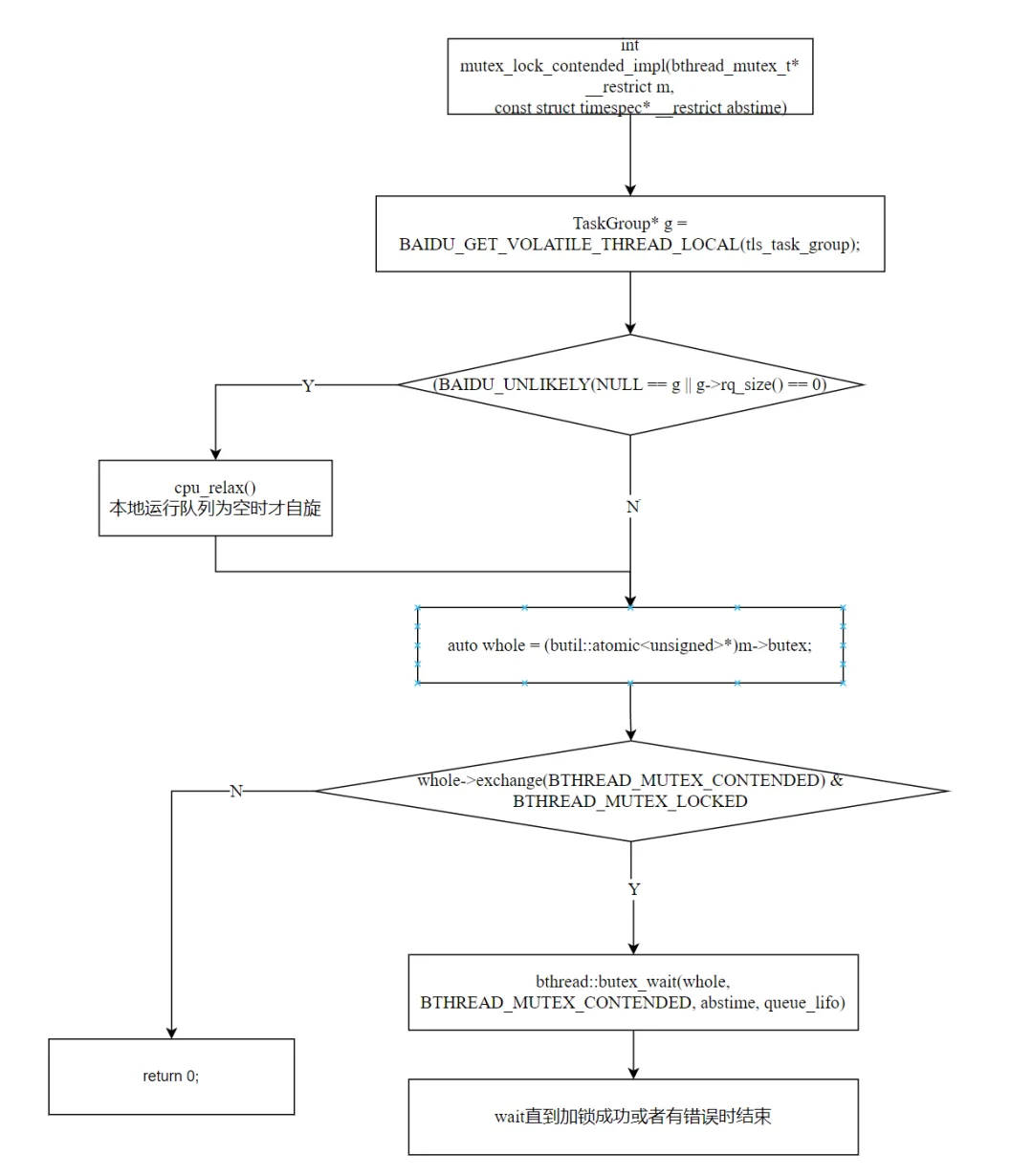
设计一:有限自旋
TaskGroup* g = BAIDU_GET_VOLATILE_THREAD_LOCAL(tls_task_group);if (BAIDU_UNLIKELY(NULL == g || g->rq_size() == 0)) { for (int i = 0; i < MAX_SPIN_ITER; ++i) { // MAX_SPIN_ITER = 4 cpu_relax(); }}
在进入阻塞前,如果本地 TaskGroup 的运行队列为空,先自旋 4 次。这是合理的——锁可能马上就被释放,自旋几次就能拿到,比 butex_wait 的开销小得多。但只自旋 4 次,避免浪费 CPU。
设计二:exchange 整个 unsigned 设置 CONTENDED 状态
auto whole = (butil::atomic<unsigned>*)m->butex;while (whole->exchange(BTHREAD_MUTEX_CONTENDED) & BTHREAD_MUTEX_LOCKED) { // 锁仍被占用,等待 bthread::butex_wait(whole, BTHREAD_MUTEX_CONTENDED, abstime, queue_lifo);}// 成功拿到锁
exchange(BTHREAD_MUTEX_CONTENDED) 原子地写入 3(locked=1, contended=1),并返回旧值:
- 旧值 &
LOCKED != 0 → 锁仍被占用,需要 butex_wait - 旧值 &
LOCKED == 0 → 锁恰好被释放,成功拿到锁
设置 contended=1 的目的:告诉未来的解锁者"有人在等,请唤醒我"。
设计三:FIFO → LIFO 的等待策略
bool queue_lifo = false;bool first_wait = true;while (whole->exchange(BTHREAD_MUTEX_CONTENDED) & BTHREAD_MUTEX_LOCKED) { butex_wait(whole, BTHREAD_MUTEX_CONTENDED, abstime, queue_lifo); if (first_wait && errno == 0) { first_wait = false; } if (!first_wait) { queue_lifo = true; // 被唤醒后下次插队 }}
- 第一次等待:FIFO(排到队尾)——公平地与其他等待者竞争
- 被唤醒后再次等待:LIFO(插到队头)——被唤醒的 bthread 需要与新到达的 bthread 竞争锁,而新到达者已经在 CPU 上运行,有巨大优势。LIFO 插队给被唤醒者更高的优先级,避免被反复"抢跑"导致饥饿
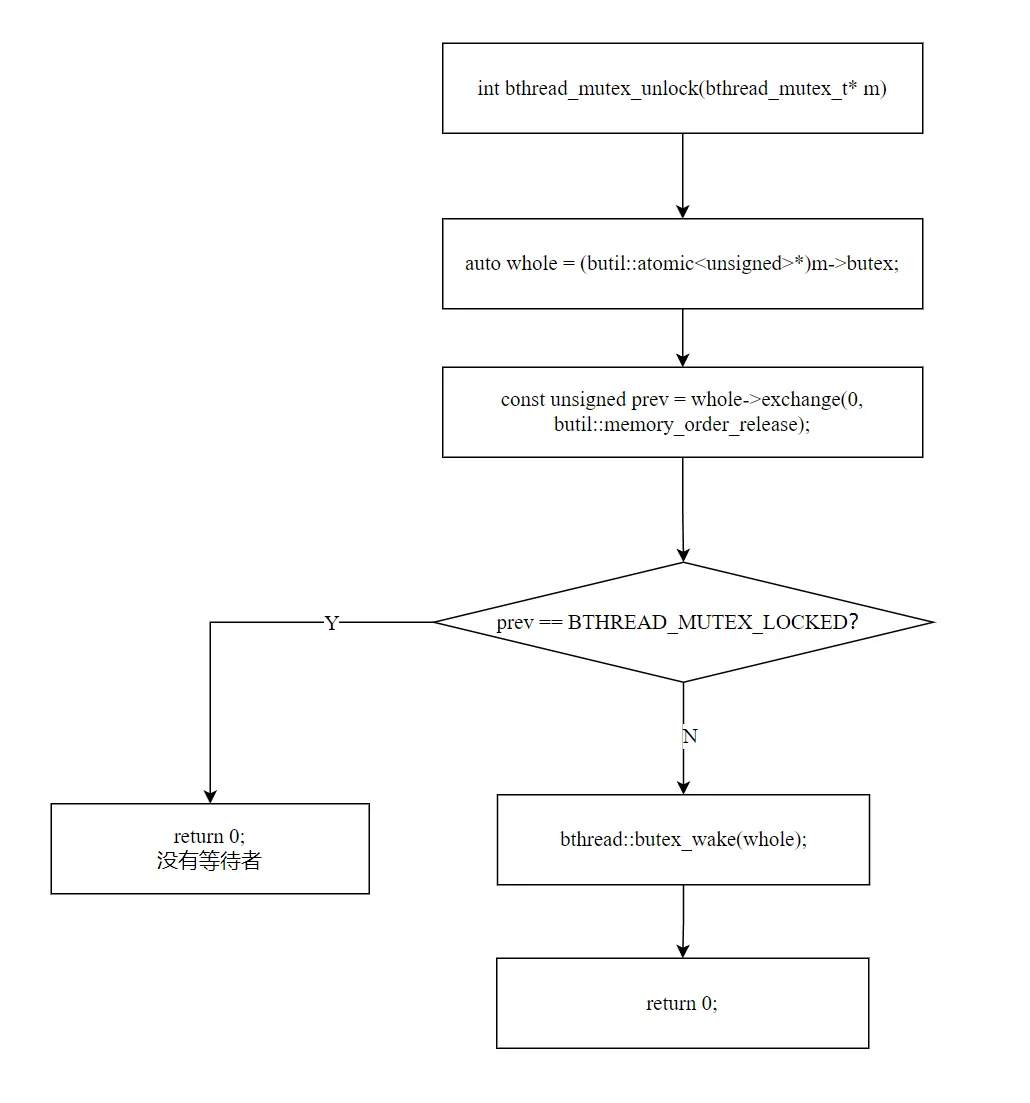
五、unlock:根据状态决定是否唤醒
intbthread_mutex_unlock(bthread_mutex_t* m){ auto whole = (butil::atomic<unsigned>*)m->butex; const unsigned prev = whole->exchange(0, butil::memory_order_release); if (prev == BTHREAD_MUTEX_LOCKED) { return 0; // 只有 locked,无等待者,不需要唤醒 } // prev == BTHREAD_MUTEX_CONTENDED (3):有等待者,唤醒一个 bthread::butex_wake(whole); return 0;}
解锁只需一次 exchange(0),原子地清零整个 unsigned,然后根据旧值决定后续动作:
这个设计的精妙之处:解锁者在 exchange(0) 的瞬间就释放了锁,不需要等待唤醒者响应。 被唤醒者在 butex_wait 返回后,会在 while 循环的下一次 exchange(BTHREAD_MUTEX_CONTENDED) 中竞争锁——可能与新到达的 trylock 竞争,但这是公平的,因为 unlock 已经释放了锁。
六、加解锁的完整状态机
把三个操作串联起来,形成完整的状态机:
trylock() ┌─────────────────┐ │ split->locked │ │ .exchange(1) │ └────────┬────────┘ │ 旧值=0? ├──── Yes ──→ 成功拿到锁(状态=LOCKED) │ No(锁被占用) │ ▼ mutex_lock_contended_impl() ┌─────────────────────────┐ │ whole->exchange(3) │ ← 原子设 CONTENDED,告知"有人等" │ 旧值 & LOCKED? │ │ Yes → butex_wait() │ ← 让出 CPU,不阻塞线程 │ No → 拿到锁 │ └────────┬────────────────┘ │ ▼ unlock() ┌─────────────────────────┐ │ whole->exchange(0) │ ← 原子清零,释放锁 │ 旧值=LOCKED? │ │ Yes → 直接返回 │ ← 无等待者,无需唤醒 │ No → butex_wake() │ ← 有等待者,唤醒一个 └─────────────────────────┘
关键观察:三个操作各只需一次原子操作——trylock 是 exchange(1)(单字节),lock 是 exchange(3)(整个 unsigned),unlock 是 exchange(0)(整个 unsigned)。无竞争路径不涉及任何系统调用或 butex 操作。
七、C++ 封装层
7.1 bthread::Mutex
class Mutex {public: voidlock() { bthread_mutex_lock(&_mutex); } voidunlock() { bthread_mutex_unlock(&_mutex); } booltry_lock() { return 0 == bthread_mutex_trylock(&_mutex); }private: bthread_mutex_t _mutex;};
RAII 风格的 C++ 封装,构造时调用 bthread_mutex_init,析构时调用 bthread_mutex_destroy。
7.2 std::lock_guard<bthread_mutex_t>
template <> class lock_guard<bthread_mutex_t> {public: explicitlock_guard(bthread_mutex_t& mutex) : _pmutex(&mutex) { bthread_mutex_lock(_pmutex); // 构造时加锁 } ~lock_guard() { bthread_mutex_unlock(_pmutex); // 析构时解锁 }};
7.3 std::unique_lock<bthread_mutex_t>
支持四种构造模式:
| |
|---|
unique_lock(m) | |
unique_lock(m, defer_lock) | |
unique_lock(m, try_to_lock) | |
unique_lock(m, adopt_lock) | |
unique_lock 还支持 swap、release、owns_lock 等操作,用于与条件变量配合使用。
八、竞争分析(Contention Profiling)
brpc 的互斥锁内置了竞争分析能力,这是相比 pthread_mutex 的一个重要增强。
8.1 工作原理
当竞争分析器启动时(通过 ContentionProfilerStart),加锁操作会额外记录:
1. trylock 失败 → 记录等待开始时间2. 进入竞争路径 → 记录等待结束时间3. 解锁时 → 记录持锁时间4. 提交采样 → 记录调用栈
采样后的数据包含:等待时间、调用栈、采样频率。最终输出为 pprof 兼容格式,可以用 pprof 工具可视化锁竞争热点。8.2 pthread_mutex 的符号拦截
最令人惊叹的设计是:brpc 通过符号拦截(symbol interposition)让 pthread_mutex_lock/unlock 也享受竞争分析能力。
// brpc 定义了自己的 pthread_mutex_lock,覆盖 glibc 的版本intpthread_mutex_lock(pthread_mutex_t* mutex){ return bthread::pthread_mutex_lock_impl(mutex);}
原理:Linux 的动态链接器在解析符号时,优先使用可执行文件和共享库中先出现的符号。brpc 把自己的 pthread_mutex_lock 放在共享库中,覆盖了 glibc 的实现。这样所有代码(包括第三方库)调用 pthread_mutex_lock 时,实际上走的是 brpc 的版本。
brpc 的版本在内部调用真正的 glibc 实现(通过 dlsym(RTLD_NEXT, "pthread_mutex_lock") 获取),但在调用前后插入竞争分析逻辑。
这意味着不需要修改任何已有代码,就能对整个进程的 pthread_mutex 进行锁竞争分析。
九、FastPthreadMutex:基于 futex 的高性能 pthread 锁
除了 bthread_mutex,brpc 还提供了 FastPthreadMutex——一个直接基于 Linux futex 系统调用的 pthread 互斥锁实现,绕过 glibc 的 pthread_mutex_t。
启用条件:编译时定义 BTHREAD_USE_FAST_PTHREAD_MUTEX。
// 启用时的实现class FastPthreadMutex { unsigned _futex; // 直接使用 futex 变量 // lock: 自旋 + futex_wait_private // unlock: exchange(0) + futex_wake_private};// 未启用时退化为 butil::Mutex(基于 pthread_mutex_t)typedef butil::Mutex FastPthreadMutex;
十、总结
bthread_mutex_t 的设计可以归纳为一句话:用最少的原子操作实现完整的互斥锁语义,通过 butex 实现协程友好的等待。
四个关键设计:
1. MutexInternal 的字节拆分。 一个 unsigned 拆成 locked + contended 两个独立字节。trylock 只操作 locked(单字节 exchange,最快路径),竞争路径操作整个 unsigned(原子设置两个标志)。三种操作(trylock/lock/unlock)各只需一次原子操作。
2. 三态状态机。 0(未锁)→ 1(已锁无等待者)→ 3(已锁有等待者)。unlock 根据 exchange(0) 的返回值判断是否有等待者,无需额外数据结构。
3. FIFO→LIFO 的公平策略。 第一次等待排到队尾(公平),被唤醒后插到队头(避免被新到达者饿死)。在公平性和性能之间取得平衡。
4. 竞争分析 + 符号拦截。 内置竞争分析能力,通过符号拦截让 pthread_mutex_lock 也受益,无需修改已有代码即可对全进程的锁竞争进行 profiling。
本文基于 Apache brpc 源码(src/bthread/mutex.h、src/bthread/mutex.cpp)撰写。