从一个问题开始
想象你正在和一个 AI 助手完成一个复杂的多轮任务——比如让它帮你分析一份数据报告,你们已经讨论了 20 轮。
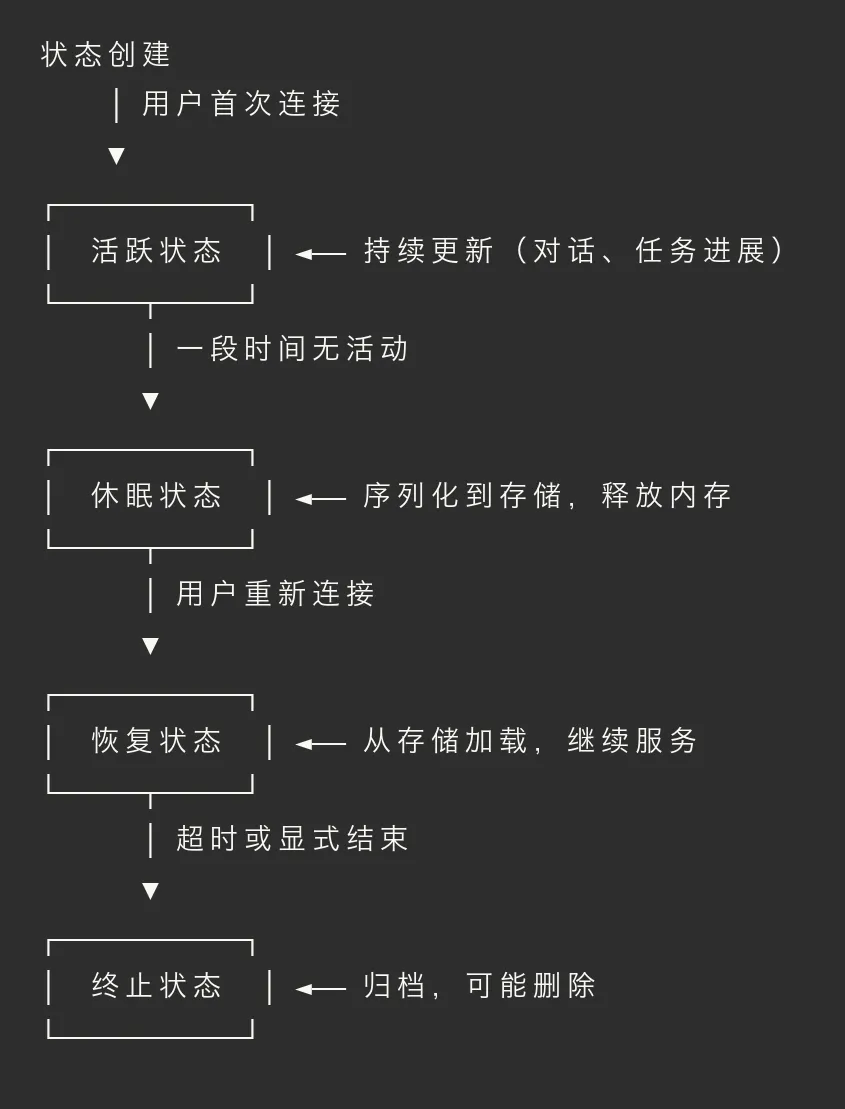
场景 A: 突然服务重启了,你回来发现 Agent 完全不记得之前的对话:"你好,请问有什么可以帮你?"
场景 B: 你说"我明天继续",第二天重新连接,Agent 对之前的进展一无所知...
场景 C(进阶): 你的 Agent 服务部署在多个实例上(比如 Kubernetes),用户的请求被负载均衡到不同实例,每个实例看到的「对话历史」都不一样...
这些问题都指向一个核心:Agent 状态管理。
先建立直觉:状态是什么?
无状态(Stateless):
每次请求都是独立的,不依赖之前的状态。 就像自动售货机:投币 → 出货,每次交易独立。
有状态(Stateful):
请求之间有依赖,需要维护上下文。 就像银行账户:取款要看余额,余额就是状态。
Agent 天然是有状态的:
Agent 状态的组成
class AgentState:
def __init__(self):
# 1. 会话级状态(Session State)
self.session_id = generate_id()
self.conversation_history = []
self.current_intent = None
# 2. 任务级状态(Task State)
self.active_tasks = {}
self.pending_actions = []
# 3. 用户级状态(User State)
self.user_id = None
self.user_preferences = {}
# 4. 运行时状态(Runtime State)
self.plan = None
self.memory_context = []
self.tool_results = []
# 5. 元数据
self.created_at = now()
self.last_activity = now()
self.version = 1
状态生命周期
状态持久化方案
方案一:内存存储(开发/测试)
class InMemoryStateStore:
def __init__(self):
self.states = {} # session_id -> state
def save(self, session_id, state):
self.states[session_id] = state
def load(self, session_id):
return self.states.get(session_id)
def delete(self, session_id):
del self.states[session_id]
优点: 简单、快速缺点: 服务重启丢失、不支持分布式
方案二:Redis(生产推荐)
import redis
import json
class RedisStateStore:
def __init__(self, redis_url):
self.redis = redis.from_url(redis_url)
self.ttl = 3600 * 24 # 24 小时过期
def save(self, session_id, state):
"""保存状态"""
key = f"agent:session:{session_id}"
serialized = json.dumps(state, default=str)
self.redis.setex(key, self.ttl, serialized)
def load(self, session_id):
"""加载状态"""
key = f"agent:session:{session_id}"
data = self.redis.get(key)
if data:
return json.loads(data)
return None
def update(self, session_id, updates):
"""部分更新"""
state = self.load(session_id)
if state:
state.update(updates)
self.save(session_id, state)
def extend_ttl(self, session_id):
"""延长过期时间"""
key = f"agent:session:{session_id}"
self.redis.expire(key, self.ttl)
优点: 快速、支持过期、分布式可用缺点: 容量受限、不适合大状态
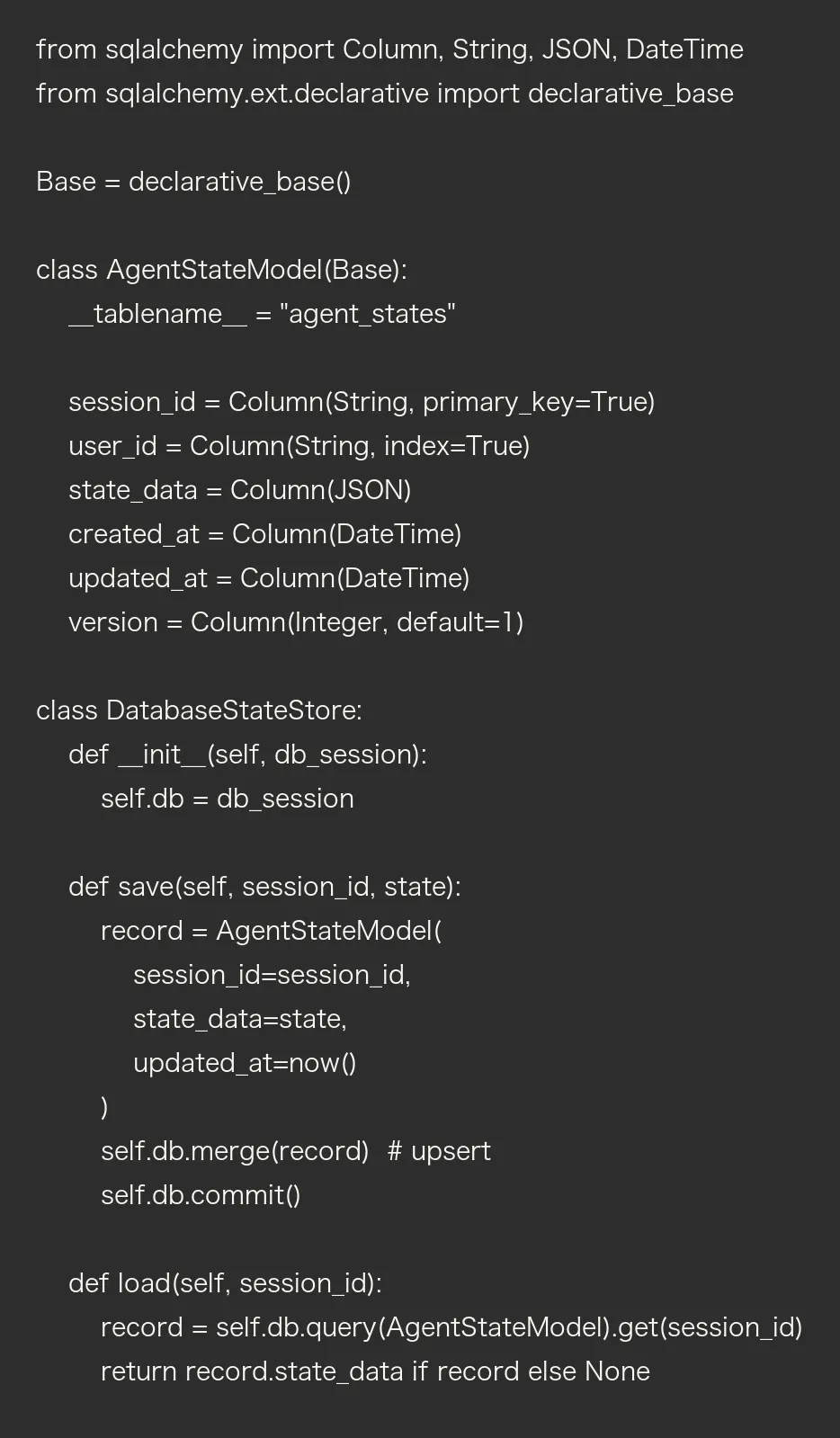
方案三:数据库存储
优点: 持久化、可查询、容量大缺点: 延迟较高、需要序列化
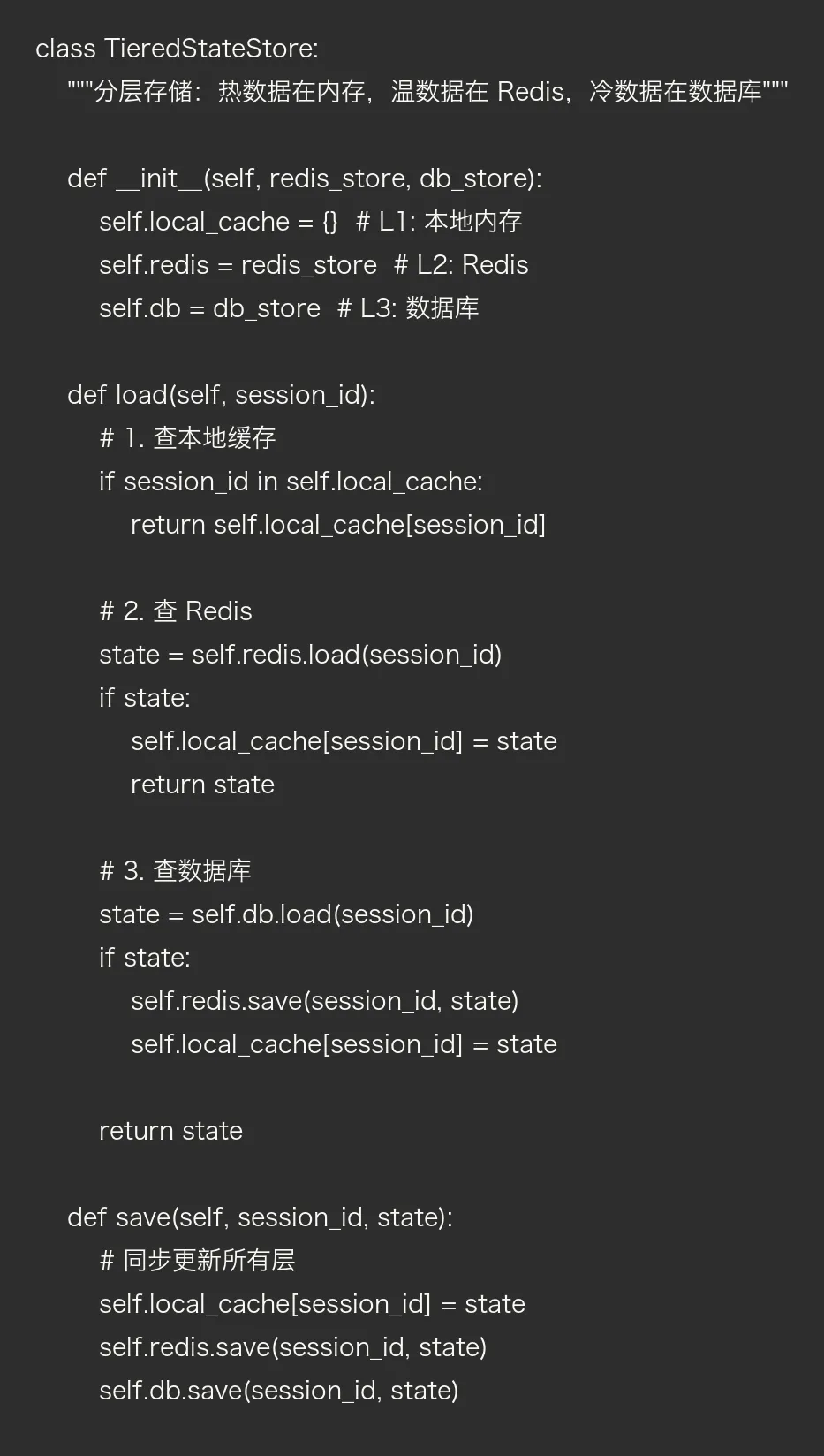
方案四:分层存储(最佳实践)
分布式场景下的状态管理
问题:多个实例如何共享状态?
用户请求 1 ──► Instance A ──► 创建状态 S1
│
用户请求 2 ──► Instance B ──► 找不到 S1!
解决方案
方案 1:粘性会话(Sticky Session)
Load Balancer 配置:
same session_id → same instance
优点: 简单,本地状态即可缺点: 实例故障时状态丢失、负载不均衡
方案 2:集中式状态存储(推荐)
优点: 任意实例可处理任意请求、容错性好缺点: 需要序列化/反序列化开销
方案 3:事件溯源(Event Sourcing)
优点: 完整历史、可审计、可回滚缺点: 复杂、重建状态耗时
状态恢复机制
恢复流程
会话管理最佳实践
会话生命周期管理
超时与清理
常见误区
总结与延伸
一句话总结:
状态管理是生产级 Agent 的基础设施,需要设计合理的存储方案、恢复机制和会话生命周期管理。
面试常考点:
有状态和无状态的区别?Agent 为什么需要状态?
- Agent 需要状态:对话历史、任务进度、用户偏好都是状态
状态存储有哪些方案?各有什么优缺点?
- 分层存储:热数据内存、温数据 Redis、冷数据数据库
分布式场景下如何处理状态共享?
- 粘性会话:同一会话路由到同一实例(简单但有单点故障)
- 集中式存储:状态存 Redis/DB,任意实例可恢复(推荐)
事件溯源是什么?有什么优缺点?
如何设计状态恢复机制?
- 恢复流程:加载状态 → 重建组件 → 恢复运行时对象
延伸阅读:
- Designing Data-Intensive Applications(DDIA)
- Kubernetes StatefulSet 文档
- Temporal / Cadence 等工作流引擎的状态管理
- LangGraph Checkpointing:LangGraph 内置了 checkpointer 机制,可以自动将 Agent 的图状态持久化到 SQLite/PostgreSQL,支持中断恢复和时间旅行(回溯到任意历史状态),是目前最流行的 Agent 状态管理方案之一
以上就是这篇笔记,希望能帮到你。有不对的地方欢迎评论区留言指正,欢迎转发给有需要的朋友,会持续更新更多AI Agent相关内容~





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
