Image credit: Tom's Hardware
最近在补 NVIDIA Kyber 架构这部分内容。Kyber 最早在 GTC 2025 亮相,当时还是原型和概念;今年 GTC 2026 又带来了更多细节更新。下面的内容是把两届的信息综合整理的。 学的过程问题不少,零零散散的理解放着容易忘,于是整理成笔记。
1. 先补一个前情提要
直接讲 Kyber 会有点悬空,还是先把它放回演进线里看比较好。
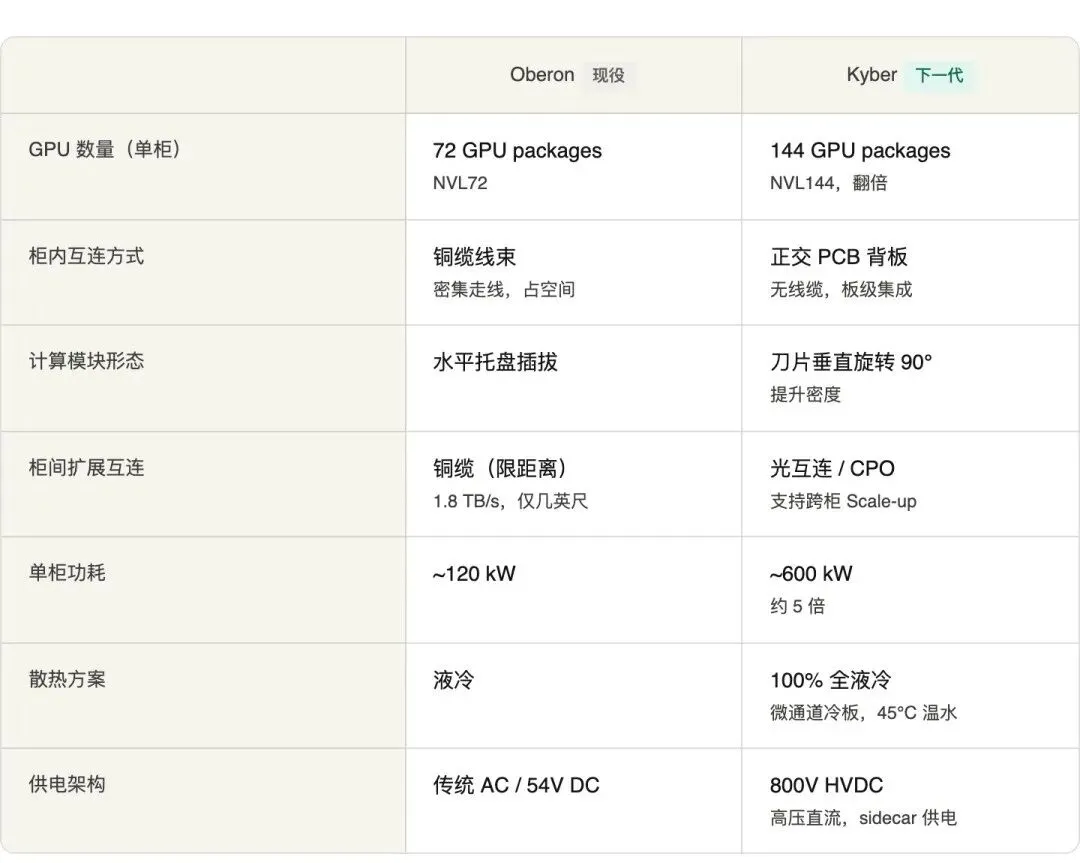
Kyber 之前,主流的 NVIDIA 机柜形态叫 Oberon,也就是大家熟悉的 NVL72——单柜大约 72 颗 GPU,柜内主要靠铜缆完成 GPU 和交换芯片之间的连接。
Kyber 这一代,是在 Oberon 的基础上继续往前推。目前在 GTC 上亮相的形态是:
它不是突然冒出来的"新机柜",而是在 Oberon 基础上,把单机架 NVLink 域从 72 颗 GPU 翻倍到 144 颗,同时重构整套机柜形态的一次系统级升级。
Image credit: Claude AI
2. 柜内先变:旧问题出在线缆上
把 Oberon 理解成"72 颗 GPU + 大量铜缆互连"的机柜,Kyber 接下来的变化就比较好理解了。
铜缆的问题,表面上是"连接方式"的问题,但会带来一连串更现实的麻烦:线太多、占空间、挡散热、装配复杂、后期维护排障也更难。机柜背部被密集线束占满之后,散热、组装和维护都会变成工程瓶颈。
所以 Kyber 在柜内做的第一步,不是"往里多塞 GPU",而是先把连接方式改掉。
具体变化是:计算刀片被旋转 90 度插入机柜,GPU 和 NVSwitch 之间的连接,从铜缆换成了正交背板(PCB 背板)。 所谓"正交",是指计算模块和交换模块从两个垂直方向插入同一块背板,天然实现互连,不需要额外走线——这也是为什么旋转 90 度这个动作本身很关键。
复杂度并没有消失,而是从线缆、连接器和装配空间,转移到了板级集成。这也是高端 PCB 和 CCL(覆铜板)在这个节点被更多关注的原因——电路板不再只是配套部件,而是在承接原来由线缆完成的系统功能。
3. 柜间再变:铜在更大的域里不够用了
柜内问题解决之后,接下来是机柜和机柜之间怎么扩。
这里要先区分两个词:
Scale-up:GPU 之间高带宽、低延迟的紧密协同,核心是 NVLink
Scale-out:更多节点之间的数据分发和同步,常见是以太网或 InfiniBand
Kyber 接下来真正要扩的,是 Scale-up 这一层。而铜缆有传输距离和信号衰减的限制——NVL72 的 NVSwitch 全部集中在机柜中间,正是因为铜缆在 1.8 TB/s 的速率下只能跑几英尺。一旦 NVLink 域要跨机柜扩展,铜就不够用了。
所以从 Rubin Ultra 的 NVL576(8 个 Oberon 机柜组合)开始,机柜间的 Scale-up 连接开始引入光互连。而到了 Feynman 一代的 NVL1152,CPO(共封装光学)会进一步成为核心方案。
这里有一个背景值得说一下:光互连本身不是新东西,插拔式光模块(pluggable)早就存在。但在 GB200 的 NVL576 原型里,用 pluggable 来做 Scale-up 互连,导致 BOM 成本过高,系统从 TCO 角度很难成立。CPO 把光学器件和交换芯片封装在一起,大幅缩短光电转换路径,解决的正是这个成本和功耗的问题。
值得单独记的一点:光互连不是进入外围网络,而是进入了 GPU 之间最核心的计算域。柜内靠背板,柜间靠光。
几个词:
NVLink:英伟达 GPU 之间的高速互连
CPO:共封装光学,把光学器件和交换芯片做得非常近,减少电到光转换的损耗
OE(Optical Engine):光引擎,CPO 里核心的光电转换部分
4. 热的问题:散热开始从配套变成前提
有一个数字很能说明问题:
Blackwell NVL72:单柜约 120 kWKyber NVL144(Rubin Ultra):单柜约 600 kW,大约是前者的 5 倍从 120 kW 到 600 kW,散热就不再是"可以优化的项",而是"系统能不能跑起来的前提"。
这也是为什么 Kyber 会是 100% 全液冷。液冷里还有一个技术细节值得多看一眼:微通道冷板——在冷板内部做出非常细密的液体流道,让冷却液更靠近热点,通道间距可以到 100 微米级。
功耗密度上去之后,液冷不是"选项",而是"前提"。
5. 电的问题:最后几厘米也成了难题
供电的问题,要从"为什么是 800V"说起。
在当前这类 AI 机柜架构里, 54V DC 仍是常见的供电方式。到了 Kyber 接近兆瓦级的量级,如果还用 54V,光是把电送进机柜所需的铜排就要重达 200kg——一个吉瓦级数据中心里,铜排用量会超过 200 吨。这条路走不通。
电压越高,同样功率下电流越小,铜的用量和线路损耗都会大幅下降。所以 Kyber 转向 800V HVDC(高压直流),逻辑是:高压远送,逐级降压。 更准确地说,是先把交流转换成 800V 高压直流,再通过sidecar把高压直流分配到计算机柜,并在更靠近计算节点、甚至更靠近 GPU 的位置继续完成后级降压。
sidecar值得单独解释一下。如果把供电模块塞进 Kyber 计算柜里,光是电源模块就要占掉约 64U 的机柜空间,计算刀片根本放不下。所以 NVIDIA 的方案是把供电模块独立出来,放在计算柜旁边单独的 sidecar 里——计算柜的空间全部留给计算。
但电进了机柜,不代表问题结束。当单芯片功耗继续上升,最后这几厘米的供电路径本身也会变成损耗来源。更靠近芯片脚边的供电模块、更短的路径,会变得越来越重要。
供电的难点不只是"送进来",还包括"最后几厘米怎么送得更高效"。
几个词:HVDC(高压直流)、PSU(电源模块)、DC/DC(板上降压转换模块)、Sidecar(暂理解为与计算机柜配套的独立供电柜)。

Image credit: Tom's Hardware
6. 把这些连起来
如果把前面这几部分连起来,可能聚焦于某几个具体参数的意义不大,而是一个更整体的感觉:
Kyber 带来的,不只是某一个器件需求的增加,而是系统复杂度开始重新分配。
柜内的问题推向了背板和高端 PCB;柜间扩展把压力推向了光互连;功耗继续上升,液冷和供电也被推到系统前台。
顺着这条复杂度转移的逻辑往下想,产业价值的分布也会跟着变。产业价值未必会平均落在每个环节,而更可能流向那些承接了新复杂度、并逐渐变成系统前提的地方。
7. 往后看
它不是简单把 GPU 塞得更多,而是把 AI 系统真正难的问题——连接、散热、供电——一层层往外推了出来。
谁承接了这些新复杂度,谁就更值得继续看。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
