近年来,自然语言处理(NLP)在质量和可用性方面取得了快速增长,这推动了企业对人工智能(AI)解决方案的采用研究人员开始将更新的深度学习方法应用于自然语言处理,数据科学家开始从传统方法转向使用基于大文本语料库预训练的语言模型的先进深度神经网络算法文本分类是一个重要的任务,比如情感分析、数字图书馆中的文档索引、仇恨言论检测,以及医疗、学术、法律等多个领域的通用分类,这一类项目主要包括AzureML上的文本分类BERT,使用多变换器模型对多NL句子进行文本分类,使用Transformer模型进行多语言数据集文本分类
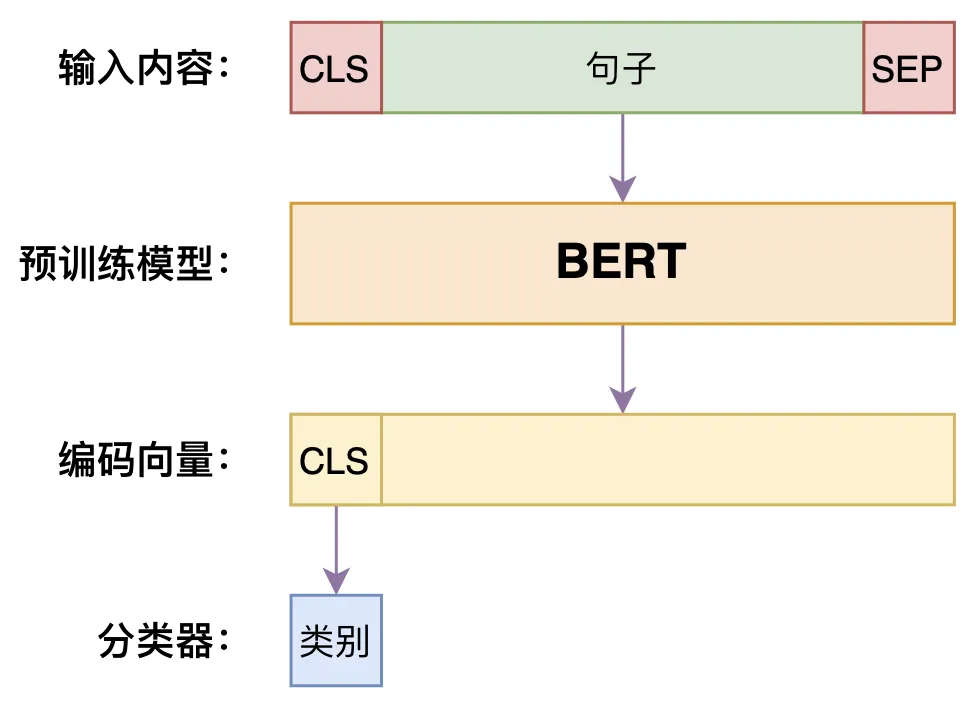
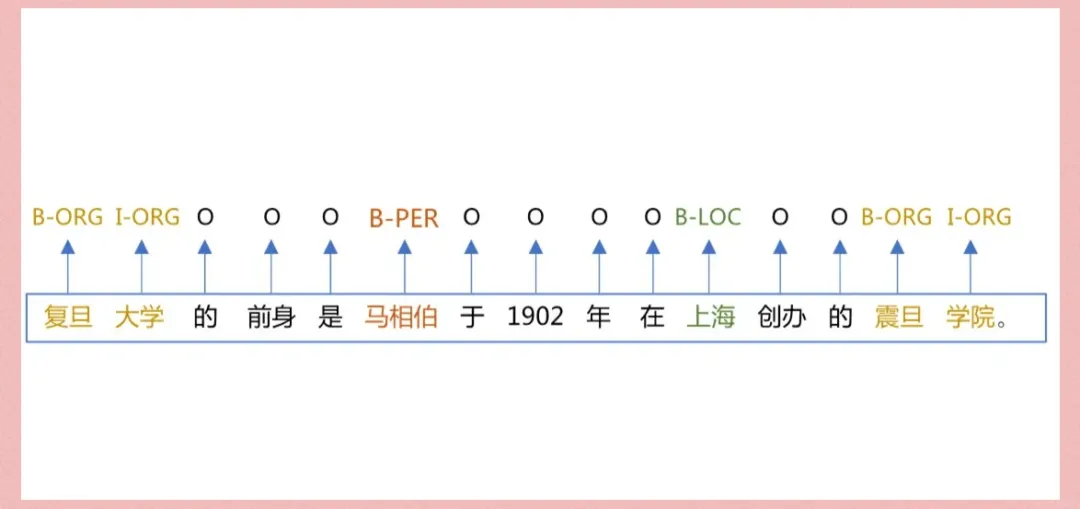
命名实体识别(NER)是检测和分类上述现实世界物体的任务 在正文中。常见的命名实体包括个人姓名、地点、组织等。最先进的NER方法包括将长短期记忆神经网络与条件随机场(LSTM-CRF)结合, 像BERT这样的预训练语言模型
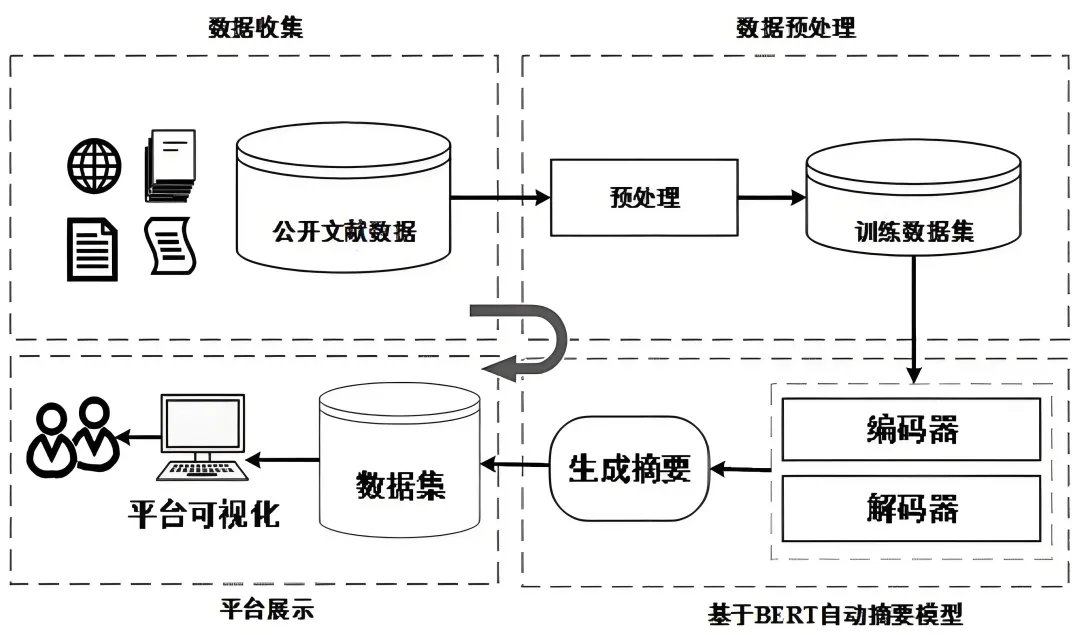
文本摘要(Text Summarization)是自然语言处理(NLP)中的核心任务之一,其目标是将一篇长文档(如新闻、论文、报告)自动压缩成一段简短、连贯且保留关键信息的文本,主要分为抽取式和生成式
Entailment在 NLP 中通常指 自然语言推理 (Natural Language Inference, NLI) 任务,有时也被称为文本蕴含,这个任务是衡量机器语言理解能力的试金石
问答任务 (Question Answering, QA) 是自然语言处理 (NLP) 中最具挑战性且应用最广泛的任务之一。它的目标是让计算机能够理解人类提出的自然语言问题,并从给定的上下文或内部知识库中找出准确的答案
句子相似性 (Sentence Similarity) 是自然语言处理 (NLP) 中的一项基础且关键的任务。它的核心目标是量化两个句子在语义上的接近程度,通常输出一个分数(如 0 到 1 之间)或一个分类标签(相似/不相似)
Embeddings 是现代自然语言处理 (NLP) 乃至整个深度学习领域的基石技术,Embedding 是一种将离散对象(如单词、句子、图片、用户ID)转换为连续向量(一串数字)的技术。这种转换使得计算机能够理解这些对象的语义含义和相互关系,而不仅仅是把它们当作冰冷的符号
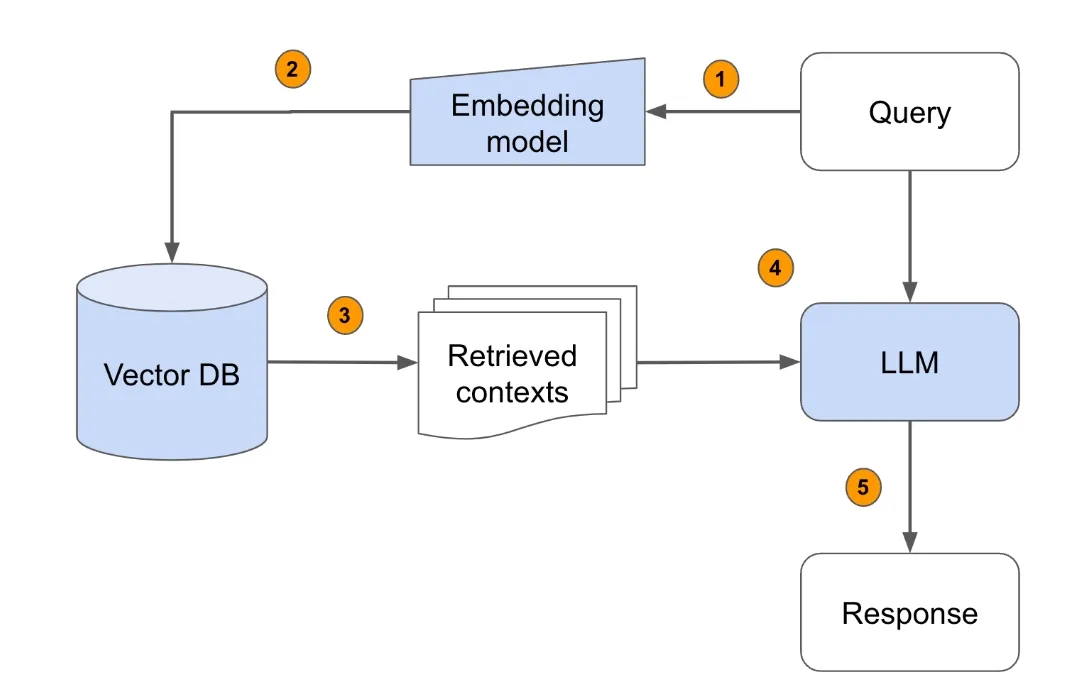
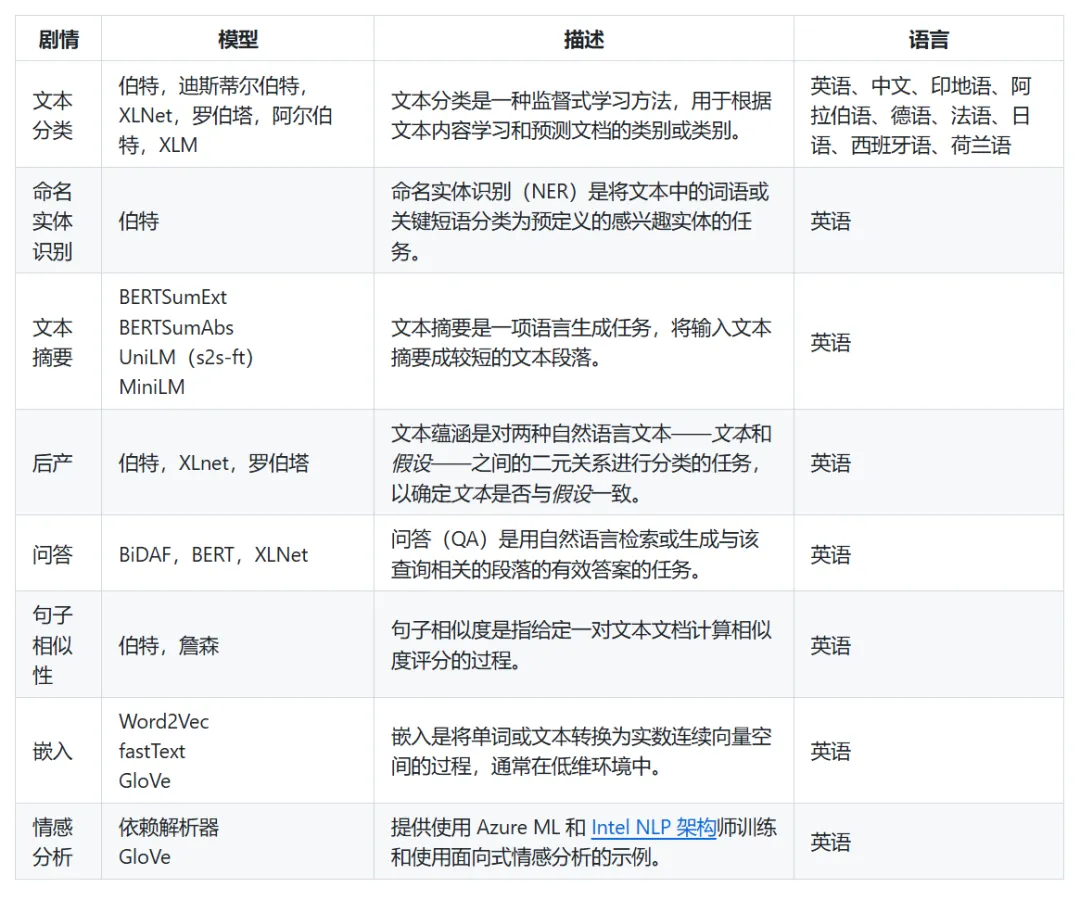
此外还有标注和模型解释性的内容,这些任务都是比较经典的,非常适合NLP入门学习2. 发送口令“NLP项目”领取(人工回复可能有时差,都会发给大家的,不用着急
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
