导语:当摩尔定律放缓,芯片创新正从“制程驱动”转向“架构驱动”。RISC-V、Chiplet、存算一体、领域专用架构(DSA)成为破局关键。而在这场变革中,Chisel凭借其生成式设计、参数化抽象与敏捷开发能力,正从教学工具蜕变为工业前沿的核心引擎。第8章作为全书终章,系统展望了Chisel在AI加速器、Chiplet互连、开源EDA生态中的落地实践。本文将带你站在技术浪潮之巅,通过架构图、生态流程图与真实项目案例,看清硬件开发的下一个十年。
一、为什么Chisel是DSA时代的“理想语言”?
第8章开篇指出:领域专用架构(Domain-Specific Architecture)的核心诉求是“快速定制、快速验证、快速迭代”,而这正是Chisel的基因。
📊 传统HDL vs Chisel 在DSA场景下的对比
| 维度 | Verilog/VHDL | Chisel |
|---|
| 定制速度 | 手动修改RTL,数周 | 修改配置参数,数小时 |
| 空间探索 | 难以自动化 | 可脚本化生成百种变体 |
| 复用粒度 | 模块级复制 | 算子/数据通路级生成 |
| 验证闭环 | 外部Testbench | 内建测试 + UVM + 形式验证 |
✅ 核心优势:将硬件设计从“手工艺”升级为“软件工程”,契合DSA“算法-硬件协同设计”的本质。
二、Chisel在AI加速器中的实战:构建可扩展张量处理器
第8章以开源项目HardFloat + Gemmini为例,展示如何用Chisel构建高性能AI加速器。
🧠 AI加速器核心挑战:
📦 Gemmini架构结构框图(简化版)
graph LR
A[Host CPU] -->|Tile指令| B(Gemmini Control)
B --> C[Weight SRAM]
B --> D[Input SRAM]
C --> E[PE Array<br>(Processing Elements)]
D --> E
E --> F[Accumulator Bank]
F --> G[Output Spad]
G --> H[DMA to DRAM]
🔑 关键创新:脉动阵列(Systolic Array) + 数据复用,最大化MAC单元利用率。
🧩 实例:参数化PE(Processing Element)
classPE(precision: Precision.Type) extendsModule{
valio=IO(newBundle{
valweight=Input(UInt(precision.width.W))
valinput=Input(UInt(precision.width.W))
valaccum=Input(UInt(32.W))
valout=Output(UInt(32.W))
})
// 根据精度动态选择乘法器
valmulResult=precisionmatch{
casePrecision.INT8=>(io.weight.asSInt*io.input.asSInt).asUInt
casePrecision.FP16=>hardfloat.MulFn(minType=Float16, ...).io.out
case_=>0.U
}
io.out:=io.accum+mulResult
}💡 价值:一套PE代码,支持多种数据类型,无需维护多个Verilog版本。
🧩 实例:生成N×M脉动阵列
classSystolicArray(rows: Int, cols: Int) extendsModule{
valio=IO(newBundle{
valweights=Input(Vec(rows, Vec(cols, UInt(16.W))))
valinputs=Input(Vec(cols, UInt(16.W)))
valoutputs=Output(Vec(rows, UInt(32.W)))
})
// 动态生成二维PE阵列
valpes=Seq.fill(rows, cols)(Module(newPE(Precision.INT8)))
// 连接数据流(向右传播input,向下传播weight)
for(i<-0untilrows) {
for(j<-0untilcols) {
pes(i)(j).io.weight:=io.weights(i)(j)
pes(i)(j).io.input:=if(j==0) io.inputs(i) elsepes(i)(j-1).io.input_out
// ... 累加器连接
}
}
// 输出最后一列累加结果
for(i<-0untilrows) {
io.outputs(i) :=pes(i)(cols-1).io.accum_out
}
}🌟 工程奇迹:仅需修改rows=16, cols=16即可从256-MAC扩展到1024-MAC,而Verilog需重画整个阵列。
三、Chisel赋能Chiplet时代:UCIe与开源互连
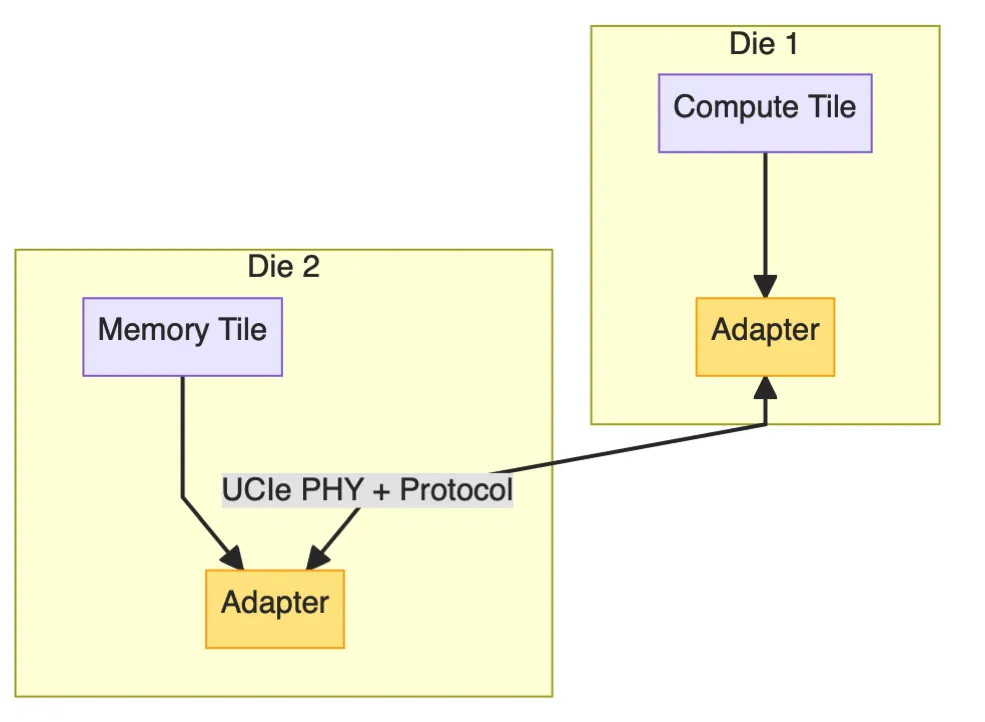
随着Chiplet(芯粒)成为延续摩尔定律的关键路径,高速、标准化、可验证的Die-to-Die互连成为焦点。第8章重点介绍了Chisel在UCIe(Universal Chiplet Interconnect Express) 开源实现中的角色。
🔌 Chiplet互连栈(结构框图)
📌 Chisel定位:实现协议层(Protocol Layer) 与 适配层(Adapter),PHY由厂商提供。
🧩 开源项目:OpenUCIe(基于Chisel)
classUCIeLink(config: UCIeConfig) extendsModule{
valio=IO(newBundle{
valtile_in=Flipped(newTileLinkBundle)
valphy_out=newUCIePhyInterface
})
// 将TileLink事务转换为UCIe微包(Flit)
valflitGen=Module(newTileLinkToUCIeFlit(config))
flitGen.io.tl<>io.tile_in
io.phy_out.data:=flitGen.io.flit.data
io.phy_out.valid:=flitGen.io.flit.valid
// CRC与重传逻辑(简化)
valcrc=Module(newCRC32)
crc.io.data:=flitGen.io.flit.data
// ...
}✅ 优势:
四、Chisel与开源EDA生态:从FIRRTL到GDSII
第8章强调:Chisel的价值不仅在于语言,更在于其推动的开源工具链革命。
📦 开源EDA全流程(原理流程图)
🔥 里程碑意义:首次实现从高级语言到GDSII的全开源流程,打破EDA三巨头垄断。
🧪 实例:用OpenROAD流片Chisel设计
生成Verilog:sbt 'runMain MyDesign'
Yosys综合:yosys -p "read_verilog MyDesign.v; synth_nangate45 -top MyDesign"
OpenROAD布局布线:
read_lef Nangate45.lef
read_def MyDesign.def
place_pins
pdn_gen
global_placement
detailed_placement
clock_tree_synthesis
routing
write_gds MyDesign.gds
MPW流片:通过Google SkyWater 130nm MPW项目提交GDSII。
💥 真实案例:2023年,多所高校团队使用此流程成功流片Chisel编写的RISC-V SoC。
五、工业落地:从学术到产业的跨越
第8章列举了Chisel在工业界的深度应用:
🏢 企业案例:
| 公司 | 应用 | 成果 |
|---|
| SiFive | Rocket Chip / BOOM | 商业RISC-V CPU IP |
| Google | TPU v4互连网络 | 千芯片级互联验证 |
| Apple | 内部验证平台 | 加速GPU验证周期50% |
| 阿里平头哥 | Xuantie C910 | 开源玄铁处理器 |
📌 趋势:Chisel正从“研究原型”走向“产品级RTL”,尤其在定制化IP领域。
六、挑战与未来方向
第8章最后客观分析了当前局限与演进路径:
⚠️ 当前挑战:
🚀 未来方向:
Chisel 4.0:更友好的错误信息、更好的IDE支持。
Chisel Formal集成:断言直接驱动形式验证。
ML for Hardware:用机器学习自动优化Chisel生成参数。
云原生EDA:Chisel + GitHub Actions + AWS FPGA 实现CI/CD。
结语:硬件开发的文艺复兴
第8章不仅是技术总结,更是对未来的宣言:我们正站在硬件开发范式转移的历史节点。Chisel所代表的,不仅是语言革新,更是设计哲学的升维——从“描述电路”到“生成系统”,从“个体英雄”到“团队协作”,从“封闭工具”到“开源生态”。
致读者:无论你是学生、工程师还是创业者,掌握Chisel,就是掌握参与下一代芯片创新的入场券。正如书中所言:“未来的芯片,将由会写代码的硬件工程师定义。”