AI推理批处理技术学习笔记:静态、动态与连续批处理
- 2026-05-19 14:33:19
AI推理批处理技术学习笔记:静态、动态与连续批处理
AI推理批处理技术学习笔记:静态、动态与连续批处理
笔记整理自技术博客:https://www.baseten.co/blog/continuous-vs-dynamic-batching-for-ai-inference/#naive-implementation-for-basic-testing
批处理(Batching)是在生产环境中服务LLM和其他生成模型的关键技术。通过同时处理多个请求来GPU模型,可以充分利用GPU资源,大幅提高模型部署的吞吐量。
四种批处理方式
1. 无批处理:一次处理一个请求 2. 静态批处理:请求放入批次,批次满时运行 3. 动态批处理:按收到的请求放入批次,批次满或等待时间到时运行 4. 连续批处理:token级别处理,旧请求完成且释放GPU空间时处理新请求
一、无批处理 - 基本测试的朴素实现
原理
最简单的模型服务器实现没有批处理。每个请求按接收顺序单独处理。
特点
• 如果使用FastAPI和PyTorch启动快速服务,默认不会获得批处理功能 • 适合基本开发和测试 • 在生产环境中浪费宝贵的GPU资源
资源浪费示例
想象一条充满汽车的道路,每辆车只有司机,没有乘客。大多数车至少能坐四个人,所以大量容量被浪费。这正是您的GPU上发生的情况。结论
无批处理会导致:
• ✗ GPU容量大部分处于空闲状态 • ✗ 资源利用率极低 • ✓ 仅适合开发测试环境
二、静态批处理 - 计划负载的简单方法
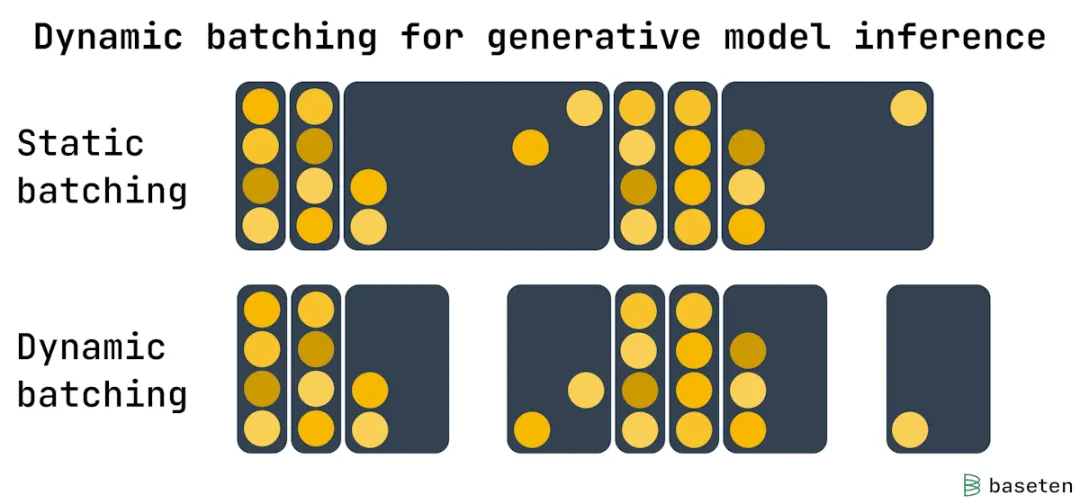
工作原理
内存带宽瓶颈
运行LLM或许多其他ML模型时的瓶颈是用于加载模型权重的内存带宽。
关键概念:
• 模型权重远大于激活(activations,即请求处理中间状态的"状态") • 将模型权重的一层加载到GPU缓存时,希望在处理多个独立激活集合时分摊这个成本 • 这样比逐层加载权重并逐个计算激活获得更好的吞吐量
静态批处理机制
• 等待接收到设定数量的请求 • 运行单个批次同时处理这些请求
类比:公交车
如果公交车运营静态批处理:司机等待公交车完全坐满,然后开车出发去目的地这确保公交车每次经过路线时都是满载的适用场景
静态批处理最适用于:
• ✅ 延迟不是问题的情况 • ✅ 每日处理大型文档语料库的定时任务 • ✅ 后台处理任务
优势:
• ✅ 实现简单 • ✅ 能够确保高吞吐量(每次批次都是满的)
劣势:
• ✗ 可能显著增加延迟 • ✗ 需要在系统其他部分构建请求编排 • ✗ 需要良好管理的请求队列
使用要求
• 需要良好管理的请求队列来馈送模型 • 需要一种以大块接受模型输出的方法
三、动态批处理 - 生产环境的AI推理
问题:静态批处理的延迟问题
静态批处理适用于日常任务或后台处理,但对于对延迟敏感的生产部署(如响应用户输入生成图像),静态批处理无法满足要求。
类比:第一个上公交车的人
想象在一个流量稀缺的日子,你是第一个上公交车的人。如果必须等待整个公交车坐满才能离开,你将等待很长时间。改进方案
如果司机在第一个乘客上车时启动一个定时器,并在公交车满员或定时器到期(先发生的)时发车,这样保证最多等待几分钟。
动态批处理机制
配置参数
设置动态批处理需要配置:
1. 预设的最大批次大小:希望在每次运行前达到的目标 2. 等待窗口:接收第一个请求后等待的时间
工作流程
示例配置:- 批次大小:16个请求- 等待窗口:100毫秒当服务器接收到第一个请求时,会发生以下情况之一:1. 在100毫秒内接收到15个以上的请求 → 立即运行完整的批次2. 接收到少于15个请求 → 100毫秒后运行部分批次效果
动态批处理在流量较少时导致更短的等待时间,同时在流量高峰期保持吞吐量。
适用场景
动态批处理非常适合以下模型的实时流量:
• ✅ Stable Diffusion XL(图像生成) • ✅ 每个推理请求耗时几乎相同的模型
配置灵活性
具体部署的正确设置取决于:
• 流量模式 • 延迟要求
动态批处理在广泛选项范围内提供了灵活性。
四、连续批处理 - LLM生产环境推理
问题:动态批处理在LLM上的局限性
虽然动态批处理适合图像生成等模态(每个输出耗时基本相同),但对于LLM,我们可以使用连续批处理做得更好。
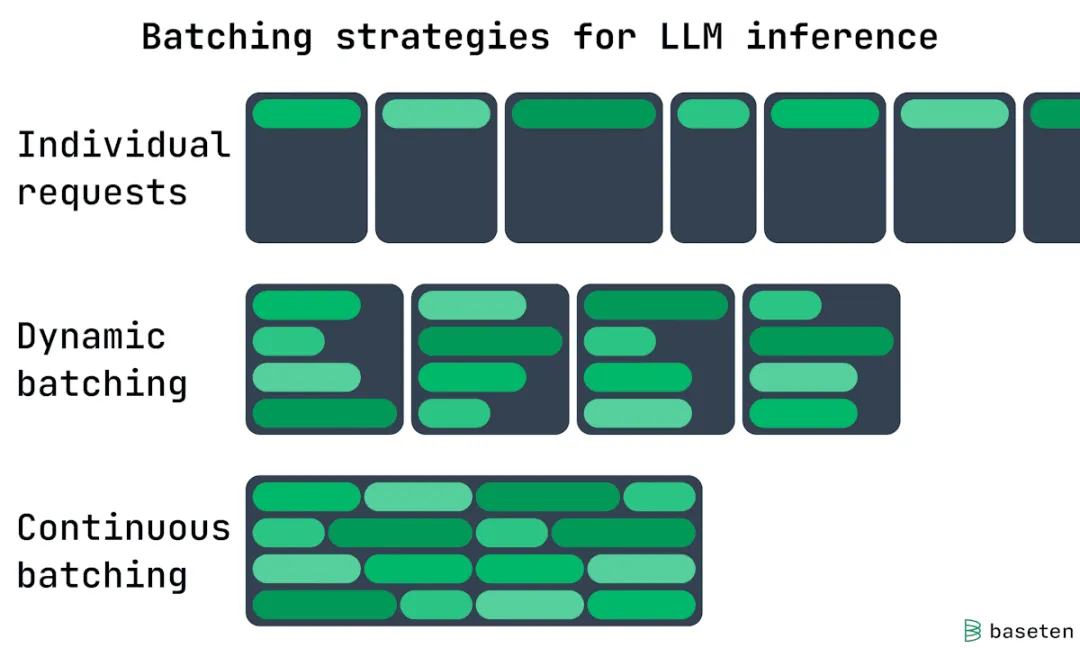
LLM的变长输出特点
LLM创建token序列作为输出:
• 输出序列长度会变化 • 模型可能回答简单问题(短输出) • 也可能执行带逐步推理的详细分析(长输出)
动态批处理的问题
如果使用动态批处理方法:
• 每批次请求都需要等待最长输出完成 • 然后下一批才能开始 • 这导致GPU资源空闲
连续批处理机制
Token级别处理
连续批处理在token级别而非请求级别工作。
核心原理
AI推理的瓶颈是加载模型权重。
连续批处理操作:
• 模型服务器逐层加载模型 • 将其应用于每个请求的下一个token • 同样的模型权重可用于: • 一个响应的第5个token • 另一个响应的第85个token
类比:真实世界的公交车路线
连续批处理类似于真实世界中的公交车路线运行方式:- 司机经过路线时,乘客乘坐公交车的时间不同- 当一个乘客到达目的地时,就会给新乘客腾出一个座位五、批处理方法对比总结
特性对比表
| 无批处理 | |||||
| 静态批处理 | |||||
| 动态批处理 | |||||
| 连续批处理 |
6、关键概念
| 批处理 | ||
| 激活(Activations) | ||
| 内存带宽瓶颈 | ||
| 吞吐量 | ||
| 延迟 | ||
| Token级别处理 | ||
| Prefill | ||
| Next Token Prediction |
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- S4 HANA物料管理集成学习笔记-财务会计与控制组织架构之业务范围和功能范围
- RE学习资料《逐句详解》内容试读及购买方法
- 「0839-文学概论」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+知识总结+高清PDF可打印+免费分享!
- 2025-2026事业单位学习资料合集总汇(含百度网盘(各省份+公基+职测+综应ABCDE类
- 2026春小学学习资料(百度网盘)免费下载
- 小学学习资料|小学数学45道母题万能答题模板(高清下载打印)
- 新型电力系统学习笔记030:构网型技术与跟网型技术核心对比
- 「0832-数据结构」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
- 「0840-文物学概论」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+知识总结+高清PDF可打印+免费分享!
- 俄语学习笔记【单词词组造句篇】日常1056
