VLLM学习笔记
核心问题:内存碎片化与浪费
笔记整理自视频教程:https://www.youtube.com/watch?v=6uPnLkCiy5g
碎片化问题场景
示例:内存无法分配
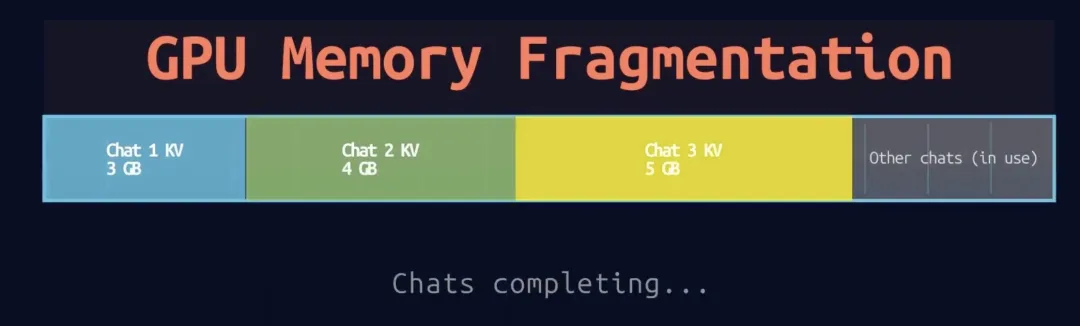
假设在一台40GB显存的A100 GPU上处理多个请求:
初始状态:
内存布局(40GB总量):
├─ 请求A: 3GB [████ ]
├─ 请求B: 4GB [█████ ]
└─ 请求C: 5GB [██████ ]
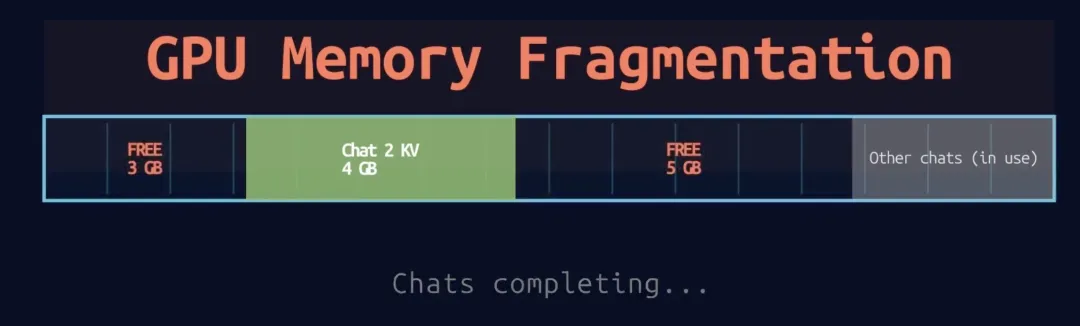
请求A和B完成后:
内存布局:
├─ 空闲1: 3GB [... ] ← 碎片
├─ 空闲2: 5GB [..... ] ← 碎片
└─ 请求C: 5GB [██████ ]
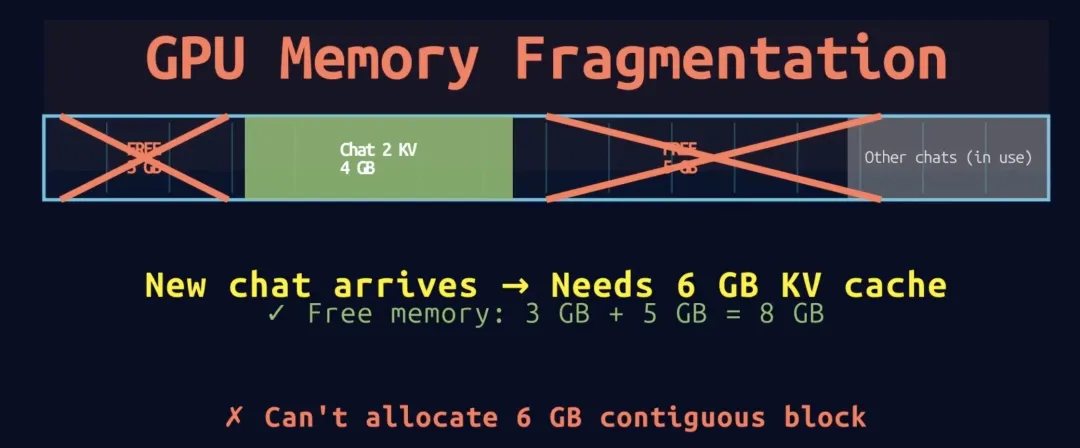
新请求需要6GB:
问题:总空闲内存 = 8GB(3GB + 5GB)
但没有连续的6GB空间
结果:请求被拒绝 ❌
结论:这就是内存碎片化(Memory Fragmentation)——虽然总内存足够,但无法分配给新请求。
传统方法的巨大内存浪费
批处理策略的问题
传统服务方式:为每个请求预留固定最大序列长度的连续内存块
具体示例:
请求配置:
- 最大序列长度:预留30GB空间
- 实际使用:约12GB空间
- 浪费:18GB
浪费率 = 18GB / 30GB = 60%
普遍统计数据
浪费的原因:
- 2. 平均长度低:大多数请求的序列长度远小于最大值
- 3. 碎片化累积:预留的空隙导致碎片,无法有效复用
- 4. 分配器限制:即使是碎片化的空闲空间,分配器也无法合并使用
问题影响分析
对服务质量的影响
现象:GPU显存表面上看起来很充足
实际:新请求被拒绝,即使有大量空闲空间
用户视角:
✗ "系统显示有20GB空闲,为什么我的请求被拒绝?"
✗ "明明资源足够,为什么响应这么慢?"
对资源利用率的影响
传统方式资源利用:
显存使用总量:40GB
实际有效使用:12GB
浪费空间:28GB(70%浪费)
技术一:PagedAttention
核心原理
借鉴操作系统的虚拟内存技术
操作系统的解决方案:
问题:程序需要不确定大小的内存
解决:
1. 将RAM分成固定大小的"页"(Page),典型大小4KB
2. 只在需要时分配页
3. 使用"页表"(Page Table)映射逻辑地址到物理地址
4. 程序看到的是连续逻辑空间,OS可以分散存储到物理内存任意位置
关键洞察:
物理内存无需连续,页可以散布在任何位置,这消除了外部碎片化
应用到KV Cache
VLLM将OS的这个成熟思想应用到大语言模型的KV Cache管理:
- • 每个token的attention计算需要查询历史所有token的Keys和Values
- • PagedAttention将其分解为固定大小的块
块分配机制
基本概念
Blocks(块):
为什么是16个token?
- • 太大(如256个token):灵活性差,浪费多
序列到块的映射
示例:64个token的序列
序列长度:64 tokens
块大小:16 tokens/block
需要的块数:⌈64/16⌉ = 4 blocks
映射关系:
块0: token 1-16 [███████████████]
块1: token 17-32 [███████████████]
块2: token 33-48 [███████████████]
块3: token 49-64 [███████████████]
块表映射机制
逻辑块到物理块的映射
块表(Block Table)的作用:
具体示例:
逻辑块序列(按生成顺序):
B0, B1, B2, B3, B4, B5, B6, B7
对应的物理块位置:
5, 2, 7, 0, 12, 3, 9, 15
块表记录:
逻辑块0 → 物理块5
逻辑块1 → 物理块2
逻辑块2 → 物理块7
逻辑块3 → 物理块0
逻辑块4 → 物理块12
逻辑块5 → 物理块3
逻辑块6 → 物理块9
逻辑块7 → 物理块15
内存视图对比
传统方式(连续分配):
物理内存(逻辑块 = 物理块):
[ B0 | B1 | B2 | B3 | B4 | B5 | B6 | B7 ]
↑ ↑
起点 终点
要求:必须有一整块连续空间
**PagedAttention(非连续分配):```
物理内存(碎片化但可用):
[ B3 | B1 | XX | B0 | XX | XX | B2 | XX | XX | B6 | XX | XX | XX | B4 | B5 | B7 ]
↑ ↑ ↑ ↑ ↑ ↑ ↑
位置0 位置1 位置3 位置5 位置9 位置12 位置15
XX表示其他请求占用的块
块的顺序不重要,块表会翻译逻辑位置
PagedAttention工作流程
单请求处理流程
与传统方式对比
技术二:前缀共享(Prefix Sharing)
应用场景
典型使用案例
示例1:系统提示词共享
3个用户同时查询,都用相同的系统提示词:
用户A + 系统提示词:"你是一个乐于助人的AI助手,请用简单术语..."
└─→ 具体问题:"解释量子计算"
用户B + 系统提示词:"你是一个乐于助人的AI助手,请用简单术语..."
└─→ 具体问题:"解释相对论"
用户C + 系统提示词:"你是一个乐于助人的AI助手,请用简单术语..."
└─→ 具体问题:"解释机器学习"
示例2:多参数变体
相同prompt,不同参数:
请求1: "解释量子计算,用简单术语"
请求2: "解释量子计算,用技术术语"
请求3: "解释量子计算,用一句话"
共享机制
内存布局对比
传统方式(无共享):
内存占用 = 3份完整请求
请求1: [系统提示词][量子计算简单术语......]
请求2: [系统提示词][量子计算技术术语......]
请求3: [系统提示词][量子计算一句话........]
重复存储系统提示词 3次 ❌
PagedAttention前缀共享:
共享前缀(存储1次):
[系统提示词][量子计算 ]
各请求只存储 divergent 部分:
请求1: 指针 → [共享前缀][,用简单术语......]
请求2: 指针 → [共享前缀][,用技术术语......]
请求3: 指针 → [共享前缀][,用一句话........]
系统提示词只存储1次 ✓
前缀共享流程
共享时的引用计数
引用计数机制
原理:
示例:
共享前缀Block0-2:
- 引用计数 = 3 (Request1, Request2, Request3)
Request1完成后:
- 独有Block3,4 引用计数 = 0 → → 释放
- 共享Block0-2 引用计数 = 2 (Request2, Request3) → 保留
Request2完成后:
- 独有Block5,6 引用计数 = 0 → → 释放
- 共享Block0-2 引用计数 = 1 (Request3) → 保留
Request3完成后:
- 独有Block7 引用计数 = 0 → → 释放
- 共享Block0-2 引用计数 = 0 → → 释放
技术三:连续批处理(Continuous Batching)
传统静态批处理的问题
工作机制
静态批处理规则:
问题分析:
时间轴:
t=0s: 开始4个请求
t=3s: 请求1完成 → → GPU空闲(等待其他请求)
t=4s: 请求2完成 → → GPU继续空闲
t=5s: 请求3完成 → → GPU继续空闲
t=10s: 请求4完成 → → 可以开始新批次
GPU空闲时间:5秒(占总时间的50%)
浪费的计算资源:50%
问题根源
原因:
举个例子:
就像一辆公交车:
- 必须等到所有乘客都下车才能接新客
- 即使有些乘客很快下车,车也要等最后一个慢乘客
- 其他想上车的人只能在一旁等待
连续批处理工作原理
核心机制
连续批处理规则:
处理流程
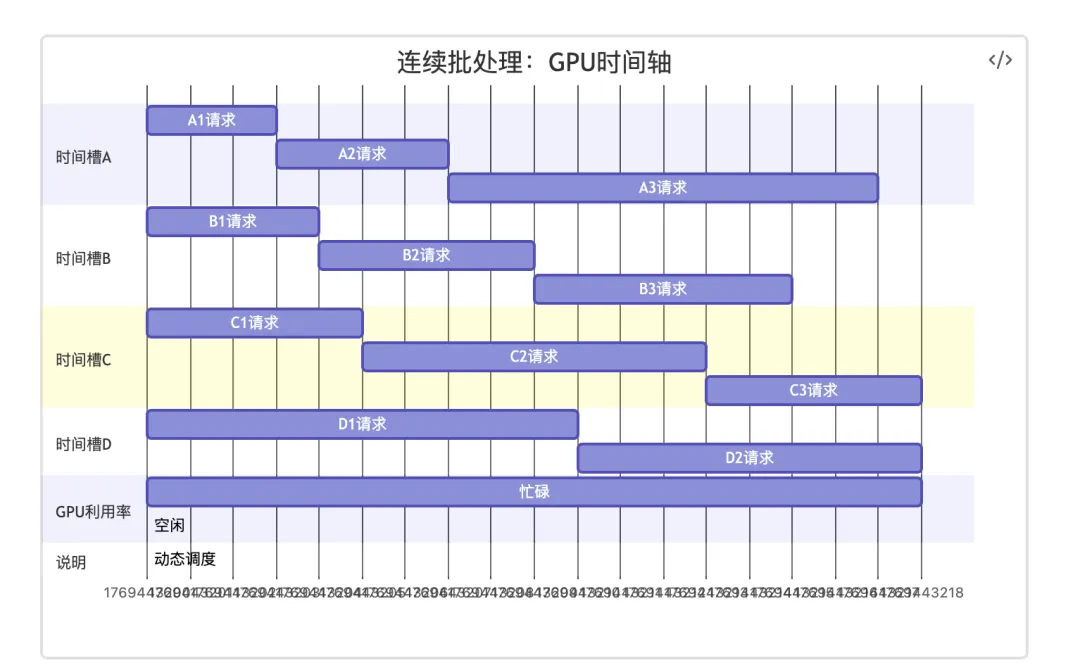
时间轴分析:
t=0s: 请求A1, B1, C1, D1 开始(占满4个位置)
t=3s: A1完成 → 立即换入 A2(不等待B1, C1, D1)
t=4s: B1完成 → 立即换入 B2
t=5s: C1完成 → 立即换入 C2
t=7s: A2完成 → 立即换入 A3
t=9s: B2完成 → 立即换入 B3
t=10s: D1完成 → 立即换入 D2
t=13s: C2完成 → 立即换入 C3
t=15s: B3完成 → 完成(假设没有更多请求)
t=17s: A3完成 → 完成
t=18s: C3完成 → 完成
t=18s: D2完成 → 完成
结果:
- GPU全程忙碌(18秒)
- 处理了12个请求(A1-A3, B1-B3, C1-C3, D1-D2)
- 空闲时间:0秒
动态调度优势
关键特性
与PagedAttention的协同效应
为什么连续批处理需要PagedAttention?
连续批处理要求:
- 请求可以随时添加
- 内存需要动态分配和释放
传统连续内存的问题:
- 如果每个请求都需要大块连续内存
- 无法动态分配(因为会产生碎片)
- 无法实现连续批处理
PagedAttention的优势:
- 块级内存管理
- 可以分配任意数量的块
- 可以随时释放
- 完美支持连续批处理
协同工作:
请求完成 → 释放块 → 块返回空闲池 → 立即分配给新请求
连续批处理依赖PagedAttention的动态内存管理能力
关键概念
| | |
|---|
| KV Cache | | |
| PagedAttention | | |
| Block(块) | | |
| 块表 | | |
| 前缀共享 | | |
| 连续批处理 | | |
| 引用计数 | | |
| 碎片化 | | |
| 静态批处理 | | |
| 内存浪费 | | |






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
