学习笔记:LLMs for Chemical Engineering
- 2026-05-25 12:16:29

Schweidtmann 教授(代尔夫特理工大学,TU Delft)在讲座中介绍了大型语言模型(LLM)在化学工程领域的潜力,讨论了将这些模型整合到工程领域所面临的挑战,以及对更易获取、更可用的工业数据的需求。他还介绍了一种名为数字化伴侣(Digitization Companion,DigiCo)的工具,用于处理工业数据,并讨论了基于规则的系统这一概念及其在安全关键领域中的应用。对话最后探讨了人工智能在化学工程行业中的未来、不同模型相结合的潜力,以及为化学工程领域构建基础模型的重要性。
可供其他流程工业领域参考。
🚀 1、从代码到化工:AI 的“副驾驶”进化论
在进入硬核的化工世界之前,先看看 AI 在其他领域已经做到了什么。
💻 程序员的福音:GitHub Copilot如果你是一个程序员,你可能已经离不开它了。只需写下一句注释:“我要写一个求 1 到 10 之和的函数”,AI 就能自动补全剩下的代码。它不仅降低了开发成本,更改变了软件开发的方式。
🌍 语言的桥梁:DeepL 与 Google Translate把一本中文书翻译成日文?过去可能需要专业翻译耗时数月,现在 AI 几分钟就能搞定,而且准确度惊人。
✍️ 写作的导师:Grammarly它不仅是拼写检查,更是你的私人编辑,帮你润色文章,减少错误。
总结一个规律:
只要任务可以被看成“对符号/序列的预测与生成”(代码、句子、翻译),LLM 就有巨大潜力。
那么问题来了: 如果程序员有 Copilot,作家有 Grammarly,化学工程师的“Copilot/Grammarly ”在哪里? 🤔
🧪 2、化学工程不只是“文本”:模态差异带来的鸿沟
在软件、语言、写作领域,我们面对的是文本 / 代码;
而在化学工程中,我们日常处理的是:
PFD(Process Flow Diagram,工艺流程图)
P&ID(Piping and Instrumentation Diagram,管道与仪表流程图)
工程图纸、拓扑结构图
操作数据、时间序列
分子结构、材料结构
这些内容本质上是图结构、表格、数值、多模态信息,而不是自然语言句子。这就带来了两个关键差异:
模态不同:
通用 LLM 擅长英文、代码、自然语言
化工领域的主流信息载体却是图纸、流程拓扑、属性表格
知识形式不同:
通用 LLM 基于“统计共现”:下一个词概率最大
工程设计依赖“机理知识”:物理、化学、热力学、安全规范……
因此,把 LLM直接拿来让它“画工艺流程图”,结果往往是——
图是画出来了,但对化工工程完全没用。
🧩 3、面向化工的 GenAI:四大核心应用愿景
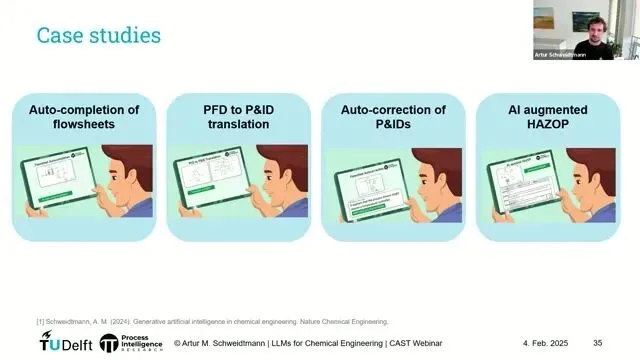
即便如此,LLM / GenAI 在化工过程工程中仍有巨大想象空间。Schweidtmann 教授提出了四个非常具体、且工程师一听就能共鸣的方向:
1️⃣ 自动补全工艺流程(PFD/P&ID 自动完成)✨
类比 GitHub Copilot 自动补全代码:
输入:已有的部分流程图 / 单元操作
输出:建议:
下一个可能的单元操作
可能需要的换热、分离、缓冲设备
典型的控制回路、仪表布置
典型的操作条件/设计参数范围
适用场景:
概念设计 / 初步工艺方案脑暴
给新人设计思路参考
对“少见工艺”提供类似案例启发
2️⃣ 工艺“翻译”:从早期设计到详细设计🔄
延伸机器翻译的思路:
PFD → P&ID(增加管道、阀门、仪表、控制回路)
概念流程图 → 可实施的详细流程方案
文本描述 → 初步流程结构草图
注意这不是严格意义上的“翻译”,而更像:
LLM学习工程师从粗略设计逐步细化到详细设计的习惯和模式。
3️⃣ 自动发现图纸错误(P&ID/PFD 自动校错)🛡️
就像 Grammarly 查语法错一样:
在 PFD / P&ID 中自动识别:
典型安全缺陷(无安全泄放、无隔离阀等)
管道错误连接
逻辑不一致的仪表回路
标注缺失、设备编号不一致
这可以用在:
设计阶段的自动检查
老装置图纸数字化后做安全审查
作为 HAZOP 会议准备的先验筛查工具
案例: 假如你设计了一个设计压力大于 3 PSI 的储罐,但忘记加装压力释放阀。LLM会立刻标记出来:“根据规则,这里需要一个安全阀,要我帮你加上吗?”
4️⃣ 半自动 HAZOP 报告生成📑
基于 P&ID + 设计参数 + 操作条件,LLM自动预生成:
各节点/单元的潜在偏差(高压、低温、流量丢失等)
可能原因(阀门失效、换热异常、控制回路失灵……)
潜在后果(泄漏、设备损坏、火灾爆炸…)
现有保护层
建议改进措施草案
再由安全工程师 & 生产工程师进行审核、修改和确认。
目标不是“替代 HAZOP 团队”,而是“让 HAZOP 团队从更高的信息起点出发”。
🧱4、最大的绊脚石:数据不是“大”,而是“乱”
❌ 4.1、为什么总说化工“不是大数据领域”?
在互联网/图像/NLP 领域,训练数据可以从:
开源代码库
维基百科、网页文本
开放图片网站
多语种平行语料
轻松获得数十亿规模样本。
而化学工程:
数据大量存在于:
企业内部仿真文件(Aspen、DW-Sim、CFD 等)
设计图纸(PFD、P&ID)
实验记录本、实验报告
邮件、Word 报告、PDF 规范
这些数据:
格式高度异构(PDF、图片、专用软件文件、扫描件…)
机器不可读 / 不可检索
大部分是保密数据,不会开放
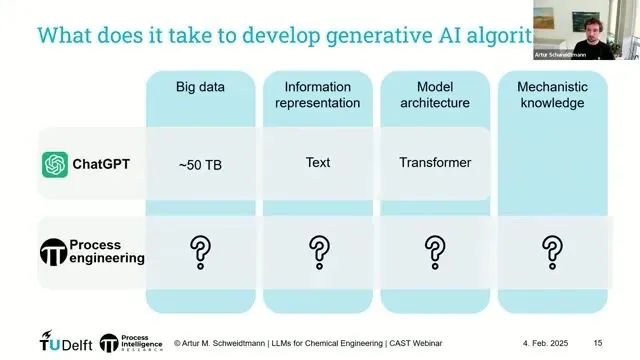
所以,问题不是“没有数据”,而是:
“数据对人类很多,对LLM几乎为零。”
🔐4.2、行业数据的保密 & 不可公开困境

真正反映工业复杂度的 P&ID/PFD,基本都在公司内部
专利上的流程图往往:
被严重简化
只给出局部
甚至为了保密故意模糊
这意味着:
学术界很难获得真实大规模工业 P&ID 数据集
当前研究多基于:
教科书、论文中简化过的流程图
手工构造的合成数据
📄 5、关键一步:让LLM消化P&ID进而变聪明——智能数字化
Schweidtmann教授团队过去几年重点做的一件事情:
把 PFD / P&ID 从“给人看的 PDF”变成“给机器用的结构化数据”。
🔍 5.1、P&ID 数字化:从像素到“智能 P&ID”
他们开发了一套“数字化伴侣(Digital Companion)”:
针对 P&ID PDF / 图片,利用多种模型:
对象检测:识别设备、阀门、仪表等符号
连通性检测:识别管线、连接关系
文本检测:读取标签、参数、编号
表格抽取:提取表格中的参数
输出的是:
每个设备是什么类型
与哪些设备相连
对应的标签、设计参数等
这一步的目标,是让 P&ID 不再只是图片,而是“带语义的图结构”。
🕸️ 5.2、用“图”来表达流程:从图纸到知识图谱
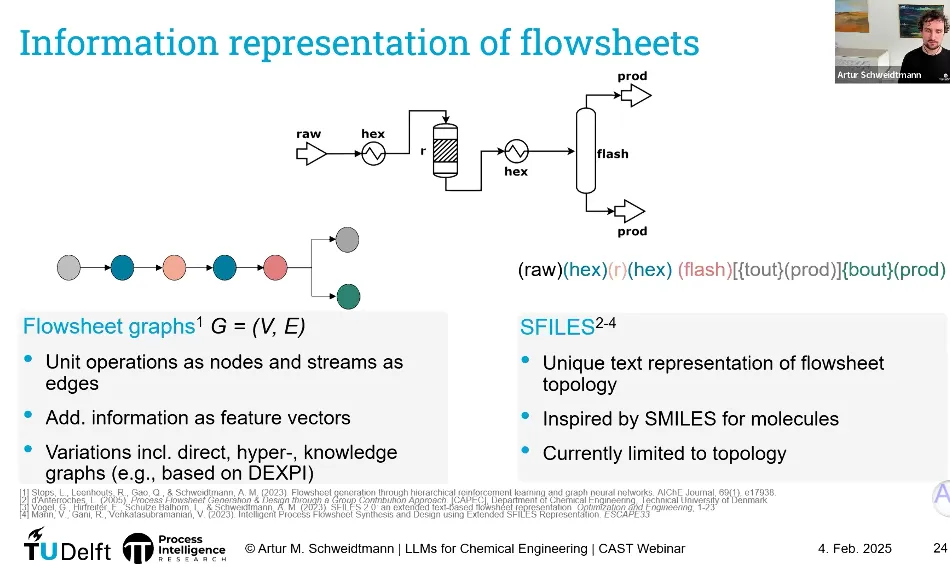
把工艺流程表示为图(Graph):
节点(Node):
设备(反应器、换热器、塔、泵…)
仪表(温度、压力、流量等)
阀门、管线节点等
边(Edge):
物流连接(物料、能量、信息流)
控制信号连接
在此基础上可叠加:
设计压力、温度
管径、材质
换热面积、传热系数
设备位号、回路号
这就形成了知识图谱(Knowledge Graph),可存储在例如 Neo4j 这类图数据库中。
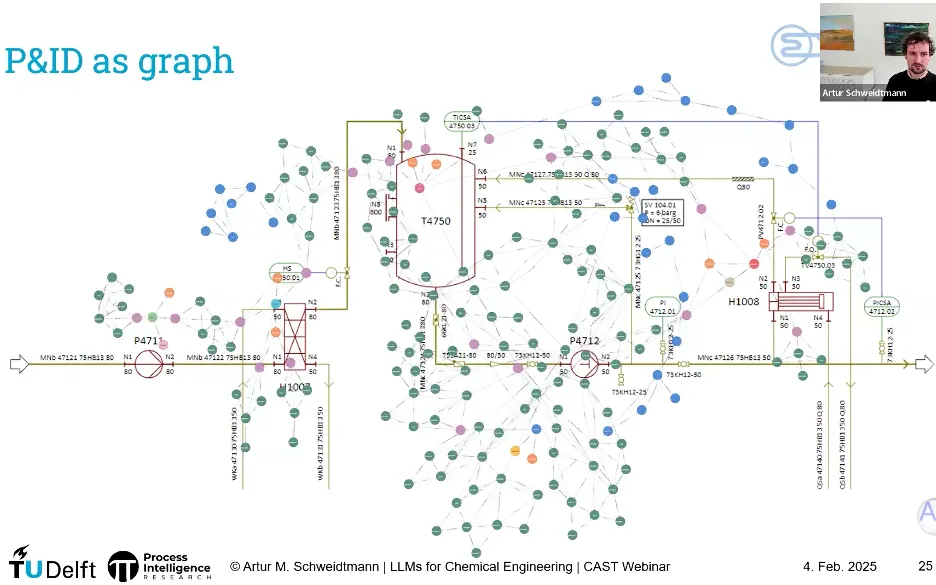
🧠 5.3、LLM + 图数据库:不用重新训练,也能“聊图纸”
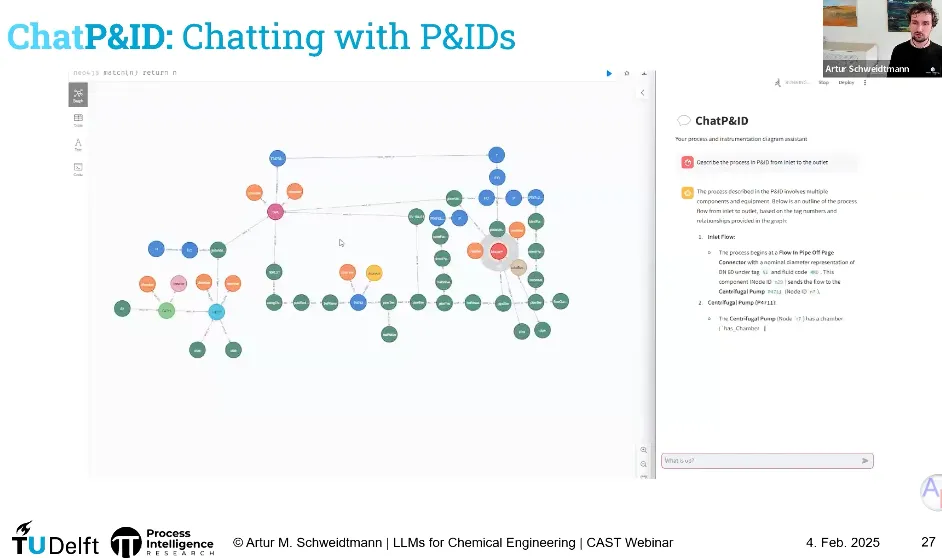
有了结构化图数据后,可以直接把 LLM 接入:
LLM 不需要重训,只需要:
接受用户自然语言问题
翻译成对图数据库的访问(查询)
再把结果以人类可读方式表达出来
示例交互:
“请从原料入口开始,用自然语言描述整个流程的工艺走向。”
“列出所有阀门及其设计压力。”
“这个容器有哪些安全保护措施?”
LLM 会:
在图数据库中定位节点
聚合相关属性信息
再以文字形式解释给工程师
这已经是一个“基于 P&ID 的智能问答系统雏形”。
🧬6、模型选择:文本?还是图?还是混合?
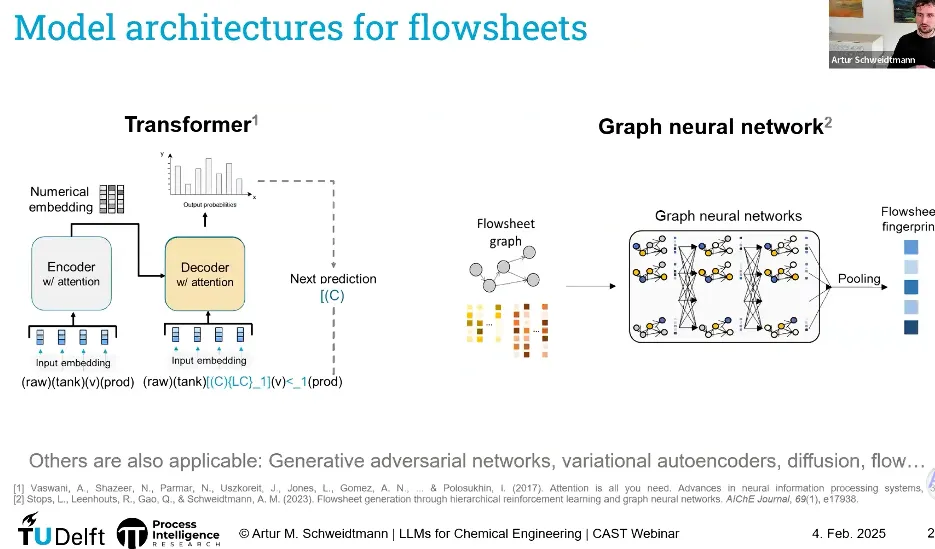
如果你的数据是:
文本、字符串、线性序列→ 优先使用:Transformer / LLM
如果你的数据是:
图结构(流程图、P&ID、分子图)→ 优先使用:图神经网络(GNN)
当然,还可以组合:
图编码器 + Transformer 解码器
GAN、VAE、扩散模型生成结构化流程
在工程数据基础上做专用 LLM 微调
核心不是“一定要用 LLM”,而是“用适合数据结构的模型架构”。
✅ 7、案例研究:PFD 自动纠错,从规则到 Transformer
🧩 7.1、基于规则的自动校正:工程版“语法检查”
先看一个最接近“生产可用”的方案——基于规则的图模式匹配。
规则本质上是:
一种典型错误模式 + 对应的修复模式。

例如安全规则:
“所有设计压力 > 3 barg 的储罐必须安装安全泄放阀(PSV)。”
在图里表现为:
Node:储罐(Design Pressure > 3 barg)
Pattern:该节点上没有任何连接到放空/火炬系统的安全阀
规则引擎可以:
在整张 P&ID 图上搜索所有匹配此模式的节点
标记为“错误”
自动生成一个带 PSV 的修正方案(或直接添加到图中)
给工程师发出提示:“已在此处应用规则 #23,是否确认?”
优点:
速度快:大 P&ID 可在几百毫秒内检查完
可解释、安全可控:每条规则来源清晰
工程师信任度高:符合现有规范逻辑
缺点:
设计和维护规则本身成本高:
数据模型复杂、细节多
规则适用范围窄
稍写不严谨,就会“误报/漏报”
因此:规则很好,但难以覆盖所有场景,需要 AI 来“提炼潜在模式”。
🤖 7.2、基于 Transformer 的自动校正:让模型学“错误模式”
为了解答一个问题:
“如果我们有足够多的带错误流程图数据,模型能学会自动纠错吗?”
Schweidtmann教授团队先做了一个合成实验:
先把流程图编码成字符串(类似 SMILES 表达分子)
使用序列到序列的 Transformer 模型:
输入:带潜在错误的流程图字符串
输出:被“纠正后”的流程图字符串
用大量人工生成的“错误–正确”流程对进行训练
结果:
模型可以学会典型的“错误 → 修正”模式
例如:
给加热器出口加上温度测量与控制回路
为某容器建议加上控制阀控制压力
问题也同样明显:
模型只看到“拓扑结构”,
但完全不知道过程物料、操作目的、工艺约束。
所以:
模型提出的“修正”有时看起来合理,但我们无法判断它是不是真正错误,还是工程师的有意简化。
本质核心问题:
缺少 process context(过程上下文)
模型“看图不知意”:
不知道是氢化反应还是蒸馏
不知道是否有后备保护
不知道操作策略和风险容忍度
下一步研究方向:
如何把更多上下文注入模型:
物料性质、操作条件
安全规范、公司标准
过往 HAZOP、事故案例
🌐 8、从单一模型到“多智能体 + 工具”的工程生态
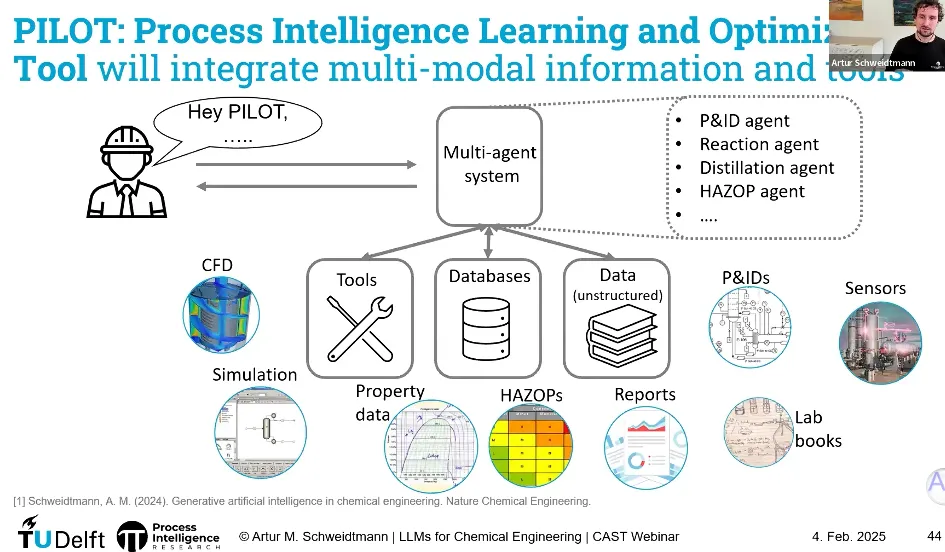
不要指望“一个大模型”一口气完成整个工艺开发流程。
更现实、更强大的路线是:
多模型协同:
流程拓扑生成模型
参数估计模型
安全检查规则引擎
控制结构推荐模型
多智能体系统:
模型之间通过中间格式(图结构、JSON、文本)对话
与现有工程工具集成:
属性数据库(物性库)
仿真软件(Aspen、Modelica、gPROMS 等)
文档存储(HAZOP 报告、操作规程)
示例:
LLM 生成 SQL 查询 → 去物性数据库取数据
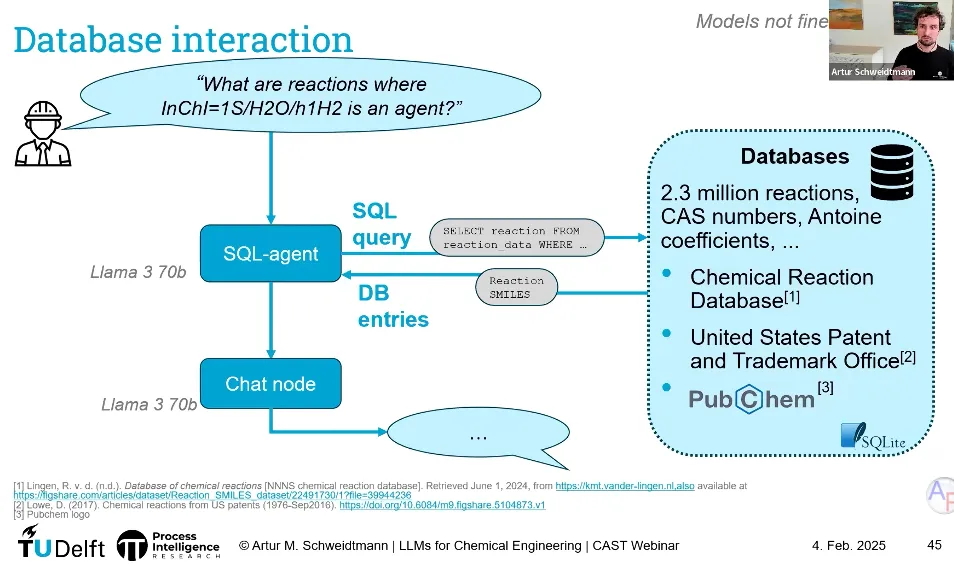
LLM 生成 Modelica 代码 → 自动搭建反应器动态模型
LLM 调用外部 Python 工具 → 进行热力学计算/线性优化

🧑🔬 9、面向不同色的落地建议
对化学工程师 / 过程工程师
立刻可以尝试的用法:
用 ChatGPT / 其他 LLM 做文献综述初稿
让模型解释复杂方程、控制策略逻辑
辅助整理会议纪要、操作规程、培训材料
向团队提出:
把关键 P&ID / PFD 做数字化,逐步构建“智能图纸库”
探索在非核心机密上试用 AI 工具,评估性价比
对学生 / 研究人员
研究切入点:
工程图纸数字化与图结构建模
物理机理约束下的机器学习(Physics-informed ML)
Graph + Transformer 混合架构
HAZOP 自动化、风险分析与 AI 辅助
技能建议:
扎实的过程系统工程基础(建模、优化、控制)
熟悉 Python / 数据处理 / 常用 ML 框架
了解图数据库(Neo4j 等)和知识图谱技术
对企业管理者 / 技术负责人
战略价值:
提升设计效率(少走弯路、减少重复劳动)
降低安全风险(早期发现图纸问题)
加强知识资产沉淀(从“人脑 + PDF”到“可查询的图谱”)
推荐行动:
评估内部工程数据现状(可用性、格式、集中度)
从一个局部应用切入(如 P&ID 规则检查、HAZOP 前处理)
与高校 / 研究机构建立联合项目,共建基础设施和模型
🔚10、总结:数字化 + 生成式 AI,将重塑化工设计方式

Schweidtmann教授的核心结论,可以浓缩为:
数字工程数据是前提:没有结构化的 P&ID/PFD、物性数据库和机理知识,谈 LLM 只是空中楼阁。
生成能力是关键:模型不仅要“理解”和“检索”,还要能“生成”新的流程方案和改动建议,否则难以真正改变工程实践。
LLM 有潜力改变流程设计范式:就像 Copilot 改变写代码的方式,专用 LLM/GenAI 有望成为“过程工程副驾驶”,把工程师从大量重复性、结构化工作中解放出来,让人类聚焦在判断、创新和决策。
未来的化学工程,很可能是:人类工程师 + 多模态工程大模型 + 机理仿真工具 的协同系统。
💡11、一点个人看法
1、LLM技术发展革新了诸多研究领域研究思路。这一点在2024年参加某国际合作项目交流时深有体会。虽然ChatGPT是22年底出现并应用的,但2023年该项目内部无人提及,但从2024年开始,各项目子团队、各研究方向的思路、技术栈全面转向LLM(老外没有“大模型”这种叫法,只有“大语言模型”),尽可能地将LLM集成到各类系统中以实现功能突破,项目组内甚至自发成立了LLM兴趣小组,专门探讨其技术应用边界。
2、LLM在流程工业应用的局限性。这点冯恩波老师某天在群里提过,大致意思是“LLM无法很好的描述/表达化工过程”,毕竟LLM本质上是基于概率的语言模型,而化工过程的底层逻辑是物理和化学定律,更适合用(偏)微分方程来精准表征。试图用概率模型去“猜”的物理/化学过程,往往会产生幻觉或偏差。这意味着,LLM在工业场景的应用,必须走“融合”之路——即“LLM + 传统模型(规则、机理等)”。在Schweidtmann教授的讲座中,他也特别强调了“规则”的重要性,且并未提及将LLM直接用于过程控制等在线闭环场景。
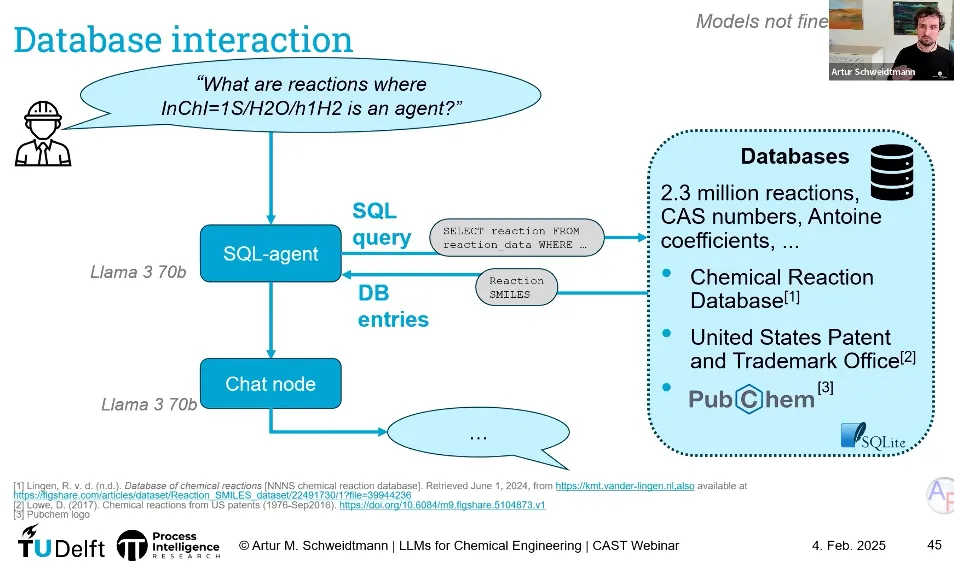
3、LLM与现有软件系统的实用性结合。Schweidtmann教授在PPT中贴了这张图,很实用,可有效扩展出软件系统的自然语言交互接口,用户可以基于自然语言交互方式获取数据。目前软件开发模式是IT根据OT需求开发软件供OT使用,OT有了新需求或业务调整IT再改。相信借助LLM强大的代码能力,马上就会有这种软件(可能已经有了)面市:IT人员负责打好数据地基、定义代码规则;而OT用户只需输入自然语言需求,LLM就能利用其强大的代码能力,自动生成业务功能,尤其是UI。目前,我们团队已经开发并上线了基于LLM技术的工业报警系统,并获得了专利授权。这正是我们探索“LLM与生产管控系统技术融合”的一次实践——让软件听懂人话,让数据服务于人。
本文基于 Artur Schweidtmann 教授于2025年2月4日关于“LLMs for Chemical Engineering”的讲座内容整理。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 反义词主题英语学习素材,含5套精美课件、6套练习,还有卡片和教具等!
- 四川省档案馆专题学习贯彻全国档案局长馆长会议精神
- 全网找疯了的托福”语境学习法”素材,终于被我整理好了!(文末附下载方法)
- 档案学习 | 有关档案开放审核方面的几个概念
- 人教版新起点四年级下册学习资料合集(中英互译课文跟读+单元词汇+歌曲歌谣+教学视频)汇总
- 学习素材丨3D建模教程:留声机
- 学习素材丨3D模型:榴弹发射器
- 无偿分享 | 宠物主题英语学习素材,5套精美课件、10套手工教具和写作练习和视频都齐全了~
- 一起学习毛笔字,送书法资料
- 2026初中化学教辅资料汇总(无偿分享)全版本+网课+教材+重点笔记+试卷+练习册【初中】电子版网盘下载链接
