从"能看"到"会想":一文看懂多模态大模型的三代演进之路
当你对着手机拍一张照片问"这是什么花?",或者上传一份PDF让AI帮你总结内容时,你正在使用多模态大模型的核心能力——视觉与语言的融合理解。
过去五年,多模态AI经历了翻天覆地的变化。从最初只能识别简单物体,到现在能看懂复杂图表、理解视频内容、甚至进行跨模态逻辑推理,这背后是技术架构的三次革命性演进。今天我们就从最基础的视觉-语言任务讲起,带你一步步看懂多模态大模型是如何"学会看世界"的。
点击下方卡片,关注“人工智能陈小白”
视觉/大模型/图像重磅干货,第一时间送达!
1. 视觉-语言任务:AI看懂世界的五大基本功
在深入技术架构之前,我们首先要搞清楚:AI的"视觉理解能力"到底包含哪些具体技能?学术界和工业界普遍将视觉-语言任务划分为五大类,它们构成了所有多模态应用的基础。
1.1 视觉问答(VQA):AI版"看图说话问答"
这是最直观也最常用的多模态任务。给定一张图像和一个自然语言问题,模型需要生成准确的文本答案。
- • 简单例子:"图中有几只猫?""这个杯子是什么颜色的?"
- • 复杂例子:"图中这个人为什么会戴墨镜?""桌子上的物品中,哪个最贵?"
- • 核心挑战:不仅要识别物体,还要理解物体之间的关系,并结合常识进行推理。
1.2 视觉定位(Grounding):按文字找东西
根据自然语言描述,在图像中精准定位对应的区域或对象,输出边界框(Bounding Box)或分割掩码。
- • 例子:"找出图中穿红色衣服的人""定位桌子上的笔记本电脑"
- • 重要性:这是所有高级视觉任务的基础。如果AI不能准确找到物体,就谈不上计数、推理或生成。
- • 最新进展:以Grounding DINO为代表的开放词汇模型,已经能识别训练时从未见过的任意物体。
1.3 图像计数(Counting):数清楚有多少个
统计图像中特定对象或类别的数量,分为固定类别计数和开放词汇计数。
- • 复杂场景:密集人群计数、细胞计数、重叠物体计数
- • 技术难点:物体重叠、遮挡、尺度变化都会严重影响计数精度。
1.4 视觉推理(Visual Reasoning):从观察到思考
基于图像和语言输入进行多步逻辑推理,生成复杂答案或决策。这是当前多模态AI最具挑战性的任务之一。
- • 多步推理:"先找出图中的所有交通工具,然后告诉我其中速度最快的是什么颜色?"
1.5 图像-文本生成:双向转换
包括两个方向:
- • 图像转文本(I2T):根据图像生成描述性文本,也就是"看图说话"
- • 文本转图像(T2I):根据文字描述生成图像,比如Midjourney、Stable Diffusion
这五大任务不是孤立的,而是存在明确的层级依赖关系:
2. 多模态架构的三代进化:从勉强融合到原生理解
为了实现上述能力,研究者们探索了三种截然不同的技术架构,分别对应多模态AI发展的三个阶段。每一代架构都解决了上一代的核心痛点,但也带来了新的挑战。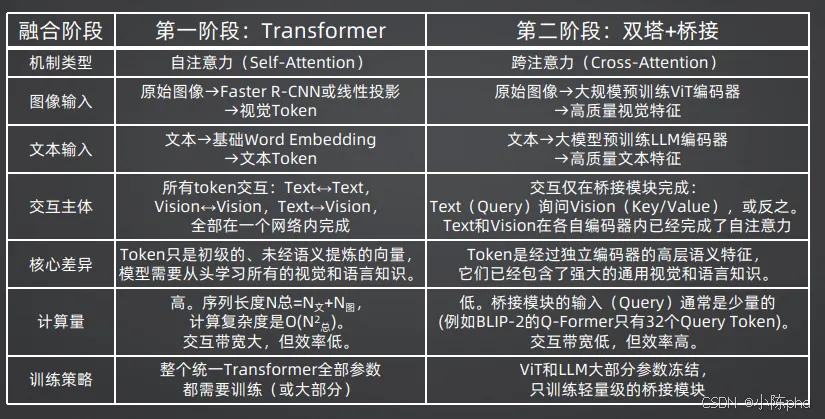
2.1 第一阶段:统一Transformer(2019-2022)
核心思想:把图像和文本都转换成Token,扔进同一个Transformer里一起训练。
代表模型:ViLBERT(2019)
这是第一个将BERT引入多模态领域的模型,首次提出了双流(Two-Stream)架构:
- 1. 用Faster R-CNN提取图像的区域特征,转换成视觉Token
- 2. 用标准BERT流程处理文本,转换成文本Token
- 3. 在编码层中加入Co-Transformer机制,让视觉和文本Token进行双向交互
优点
- • 首次证明了基于注意力的深度交互是视觉-语言融合的关键
致命缺点
- 1. 计算效率极低:总序列长度约150,自注意力计算复杂度是O(N²),训练和推理都非常慢
- 2. 通用性差:需要从头学习所有跨模态知识,很难迁移到新任务
- 3. 视觉质量受限:完全依赖Faster R-CNN提取区域特征,最多只能提取100个区域,会丢失大量细节
第一阶段解决了"能不能融合"的问题,但效率和性能都远达不到工业界的要求。
2.2 第二阶段:双塔+桥接(2022-至今)
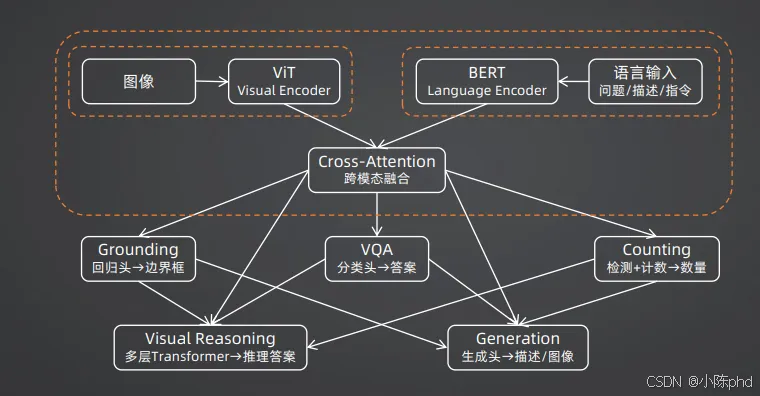
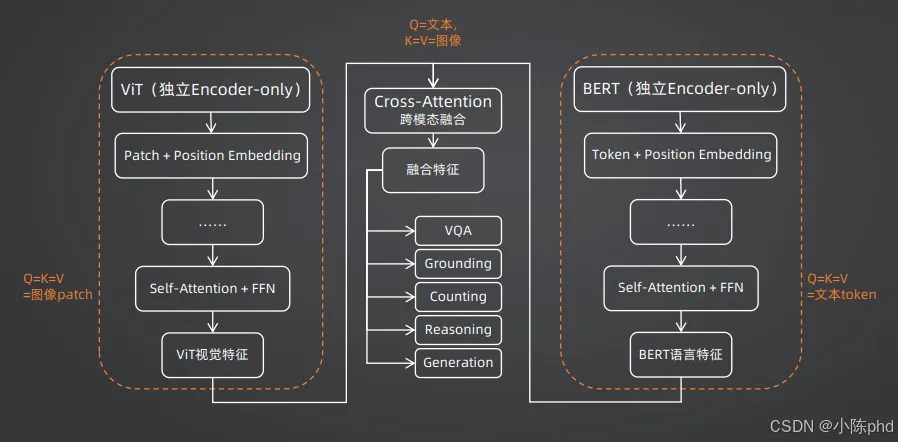
核心思想:视觉和语言分别用独立的大模型编码,只通过一个轻量级的"桥接模块"进行交互。
这是目前工业界绝对的主流架构,约80%的商用多模态模型都采用这种设计。
代表模型1:BLIP-2(2023)
BLIP-2最大的贡献是发明了Q-Former(查询转换器),完美解决了连接大视觉模型和大语言模型的效率问题:
- 1. 用预训练好的ViT(视觉Transformer)提取图像特征,得到256个图像Patch Token
- 2. 用32个可学习的Query Token作为"探针",通过交叉注意力从256个图像Token中提取最关键的信息
- 3. 把这32个精炼后的视觉Token输入给预训练好的大语言模型(如OPT、FlanT5)
代表模型2:LLaVA-Next(2024)
LLaVA将"极简主义"发挥到了极致,它发现:只要语言模型足够强大,用最简单的MLP(多层感知机)作为桥接,效果反而更好。
LLaVA的架构简单到令人发指:
- 2. 一个MLP层将视觉特征投影到与文本Token相同的维度
第二阶段的革命性优势
- 1. 训练成本极低:ViT和LLM的参数完全冻结,只需要训练桥接模块(几千万参数),普通实验室也能训练
- 2. 可插拔性极强:可以随时更换更好的视觉编码器或语言模型,不需要重新训练整个系统
局限性
- • 融合深度有限:视觉和语言只在桥接模块进行一次交互,无法进行深层的跨模态推理
- • 存在"模态墙":视觉信息需要经过压缩和转换才能被语言模型理解,会丢失部分细节
2.3 第三阶段:超大规模统一融合(2024-未来)
核心思想:视觉和语言不再是两个独立的模块,而是同一个统一Transformer的一部分,从底层就实现了原生融合。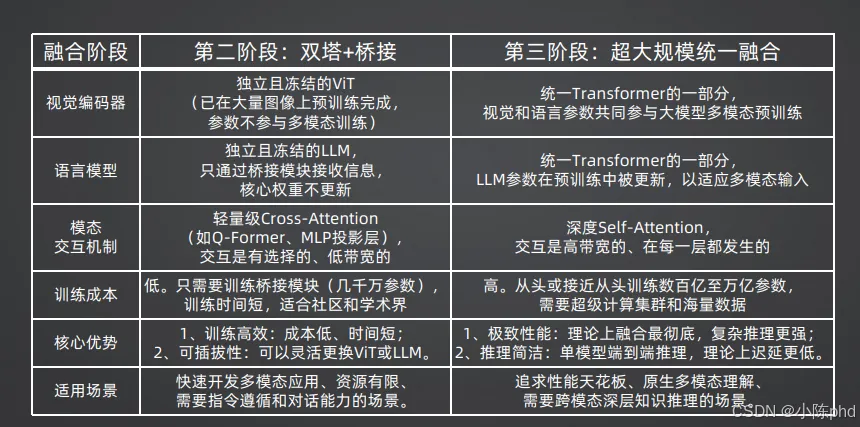
代表模型:GPT-4o(2024)、Claude 3.5 Sonnet(2025)
这些闭源大模型采用了统一的Transformer架构,视觉和语言参数共同参与预训练,在每一层都进行深度的自注意力交互。
理论优势
- 1. 极致性能:融合最彻底,在复杂推理任务上表现远超第二阶段模型
- 3. 原生多模态:能够无缝处理文本、图像、音频、视频等多种模态
巨大挑战
- 1. 训练成本天文数字:需要从头训练数百亿至万亿参数,只有少数科技巨头能负担得起
- 2. 调试难度极大:完全的黑盒模型,很难定位和修复问题
2.4 三代架构全面对比
为了让你更清晰地看到差异,我整理了一张对比表: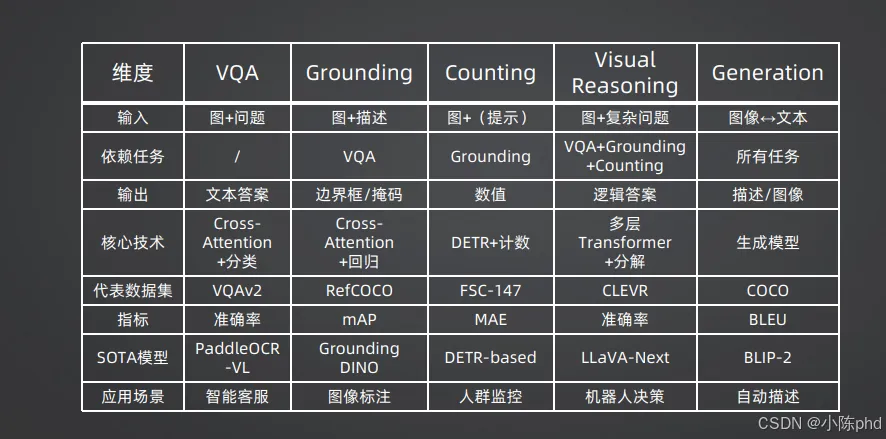
3. 行业现状与未来趋势
3.1 当前格局:双塔架构统治工业界
目前,第二阶段的双塔+桥接架构是绝对的主流。对于绝大多数企业和开发者来说,它提供了最佳的性价比:
- • 开源生态极其完善:LLaVA、Qwen-VL、InternVL等开源模型已经能满足大部分应用需求
- • 开发速度快:基于开源模型微调,几天就能做出一个可用的多模态应用
而第三阶段的统一融合模型目前还只有少数科技巨头能够研发和部署,主要用于对性能要求极高的场景。
3.2 未来方向:效率与性能的平衡
多模态AI的下一个突破点在于如何在保持第二阶段效率优势的同时,达到第三阶段的性能。目前有几个很有前景的方向:
- 1. 混合架构:在双塔架构的基础上,增加少量的跨模态交互层,平衡效率和融合深度
- 2. 模型压缩:通过量化、蒸馏等技术,让大模型能在边缘设备上运行
- 3. 专用硬件:为多模态推理设计专用的AI芯片,大幅降低推理成本
4. 写在最后
从ViLBERT到GPT-4o,多模态大模型只用了短短五年时间,就完成了从"勉强能看"到"能理解会推理"的巨大飞跃。
今天我们讲的这三代架构,本质上是在回答同一个问题:如何让计算机像人类一样,自然地融合视觉和语言信息。人类的大脑就是一个完美的统一多模态系统,我们看东西、听声音、说话、思考,都是同一个大脑在处理。未来的多模态AI,也一定会朝着这个方向不断演进。
对于我们普通人来说,不需要纠结于复杂的技术细节。我们只需要知道:多模态AI正在变得越来越强大,越来越便宜,它将彻底改变我们与计算机交互的方式,渗透到生活的每一个角落。