摘要:上一篇文章拆解了 bthread_cond_t 的实现——用序列号 butex 实现 wait/signal/broadcast 语义,用 butex_requeue 优化广播性能。本文继续拆解另一个基于 butex 的同步原语:信号量 bthread_sem_t。与互斥锁的二态(锁/未锁)和条件变量的等待/通知模式不同,信号量的核心是"计数"——butex 的值直接就是信号量的计数值。trywait 用 CAS 原子递减,wait 在计数为零时通过 butex_wait 挂起,post 用 fetch_add 原子递增并通过 butex_wake_n 唤醒等待者。此外,bthread 独有的 post_n 批量操作和内置的竞争分析能力也是值得关注的亮点。在上一篇文章中,我们拆解了 bthread_cond_t——协程友好的条件变量。我们看到它用一个序列号 butex 实现 wait/signal/broadcast 语义,用 butex_requeue 优化广播性能,避免惊群效应。
现在我们继续拆解另一个基于 butex 的同步原语:信号量。
信号量与互斥锁、条件变量都不同。互斥锁只有两个状态(锁/未锁),条件变量是纯粹的等待/通知机制,而信号量的核心是计数——一个非负整数,表示可用资源的数量。P 操作(wait)递减计数,计数为零时阻塞;V 操作(post)递增计数,唤醒等待者。
bthread 的信号量是如何基于 butex 实现这种"计数"语义的?让我们从数据结构开始。
一、bthread_sem_t:butex 就是计数器
typedef struct bthread_sem_t { unsigned* butex; // butex 指针,值就是信号量计数值 bool enable_csite; // 是否启用竞争统计} bthread_sem_t;
与互斥锁和条件变量都不同,信号量的 butex 值直接就是信号量的计数,不需要额外的编码或拆分:
这使得信号量的实现比互斥锁更直观——不需要 MutexInternal 那样的位拆分,也不需要条件变量的序列号。butex 的值就是业务含义本身。
enable_csite 控制竞争分析采样(与互斥锁的 enable_csite 相同),默认启用。
二、初始化与销毁
2.1 bthread_sem_init
intbthread_sem_init(bthread_sem_t* sem, unsigned value){ sem->butex = bthread::butex_create_checked<unsigned>(); if (!sem->butex) { return ENOMEM; } *sem->butex = value; sem->enable_csite = true; return 0;}
从 ObjectPool 分配一个 butex(参见本系列第四篇),设置初始计数值 value。与 pthread_sem_init 的区别:不支持进程共享(无 pshared 参数),因为 butex 是进程内私有的。
2.2 bthread_sem_destroy
intbthread_sem_destroy(bthread_sem_t* semaphore){ bthread::butex_destroy(semaphore->butex); return 0;}
归还 butex 到 ObjectPool。与所有 butex 用户一样,butex_destroy 和 butex_wake 之间存在竞态,ObjectPool 的"永不释放"特性保证了安全。
三、trywait:非阻塞获取
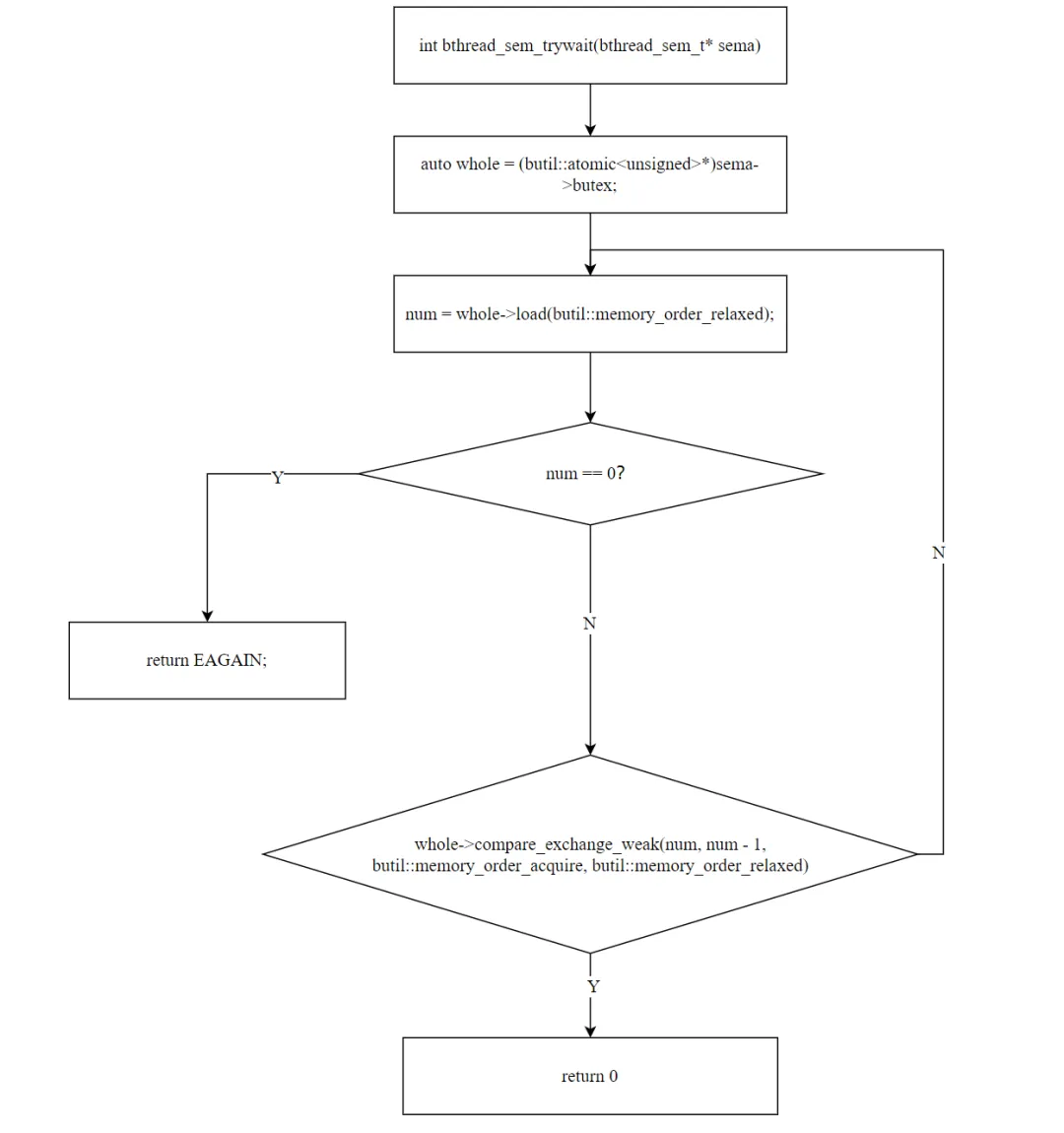
staticinlineintbthread_sem_trywait(bthread_sem_t* sema){ auto whole = (butil::atomic<unsigned>*)sema->butex; while (true) { unsigned num = whole->load(butil::memory_order_relaxed); if (num == 0) { return EAGAIN; // 计数为 0,无法获取 } if (whole->compare_exchange_weak(num, num - 1, butil::memory_order_acquire, butil::memory_order_relaxed)) { return 0; // CAS 成功,计数减 1 } // CAS 失败(num 被其他线程改了),重试 }}
trywait 是信号量的"快速路径"——不阻塞,只尝试获取。实现是一个 CAS 循环:load(num) → num == 0? → 返回 EAGAIN → num > 0? → CAS(num, num-1) → 成功:返回 0 → 失败:重试
为什么用 CAS 而不是互斥锁中的 exchange? 这是一个关键的设计选择。
互斥锁的 exchange(CONTENDED=3) 是独占操作——"原子地标记为已占用",不需要先检查值。信号量则不同:它是共享的(多个线程可以同时持有),必须"先读 → 判断 > 0 → 再减",需要 CAS 的两步语义。CAS 的 compare 步骤确保了"判断 > 0"和"减 1"是原子的——中间不会被其他线程抢先减到负数。
使用 compare_exchange_weak 而非 strong 是性能考虑:在某些架构上 weak 更高效,而循环中 weak 的虚假失败只是多一次重试,不影响正确性。
四、wait:阻塞获取
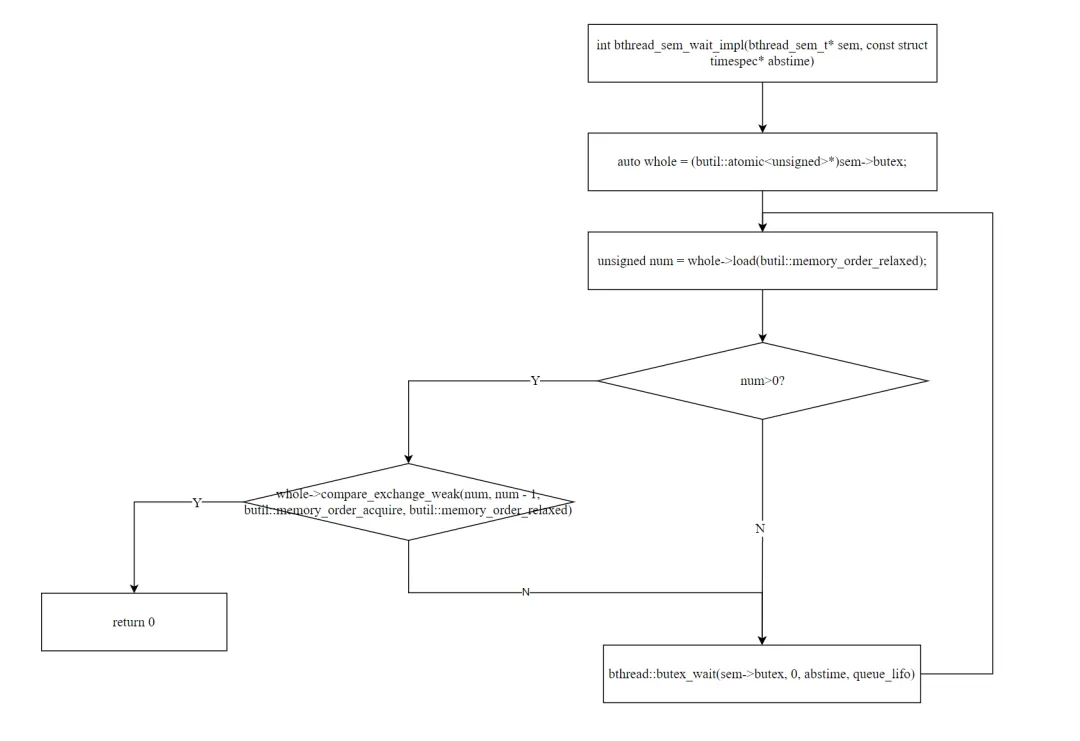
staticintbthread_sem_wait_impl(bthread_sem_t* sem, conststruct timespec* abstime){ bool queue_lifo = false; bool first_wait = true; // ... auto whole = (butil::atomic<unsigned>*)sem->butex; while (true) { unsigned num = whole->load(butil::memory_order_relaxed); if (num > 0) { if (whole->compare_exchange_weak(num, num - 1, butil::memory_order_acquire, butil::memory_order_relaxed)) { return 0; // CAS 成功,获取信号量 } continue; // CAS 失败,重试 } // num == 0,需要等待 if (bthread::butex_wait(sem->butex, 0, abstime, queue_lifo) < 0 && errno != EWOULDBLOCK && errno != EINTR) { return errno; // 超时或错误 } // EWOULDBLOCK:值已经不是 0(被 post 了),重试 // EINTR:被中断,重试 if (first_wait && 0 == errno) { first_wait = false; } if (!first_wait) { queue_lifo = true; // 被唤醒后下次插队(LIFO 防饥饿) } }}
wait 是信号量的核心操作。与 trywait 相比,多了一个阻塞等待的分支。整体是一个循环,每轮尝试两件事:
4.1 快速路径:CAS 获取
unsigned num = whole->load(butil::memory_order_relaxed);if (num > 0) { if (whole->compare_exchange_weak(num, num - 1, ...)) { return 0; // 成功 } continue; // CAS 失败,重试}
与 trywait 完全相同的 CAS 逻辑。如果计数 > 0 且 CAS 成功,直接获取信号量。
4.2 慢速路径:butex_wait
if (bthread::butex_wait(sem->butex, 0, abstime, queue_lifo) < 0 && errno != EWOULDBLOCK && errno != EINTR) { return errno;}
当计数为 0 时,调用 butex_wait(butex, 0, ...) ——期望值为 0,表示"当 butex 仍然是 0 时就等待"。如果 butex 值已经被 post 改变(不再是 0),butex_wait 立即返回 EWOULDBLOCK,循环继续,下一轮 CAS 可能成功。
4.3 FIFO → LIFO 防饥饿策略
if (first_wait && 0 == errno) { first_wait = false;}if (!first_wait) { queue_lifo = true;}
这与互斥锁的策略完全相同(参见本系列第六篇):
- 第一次等待:FIFO(排到队尾)
- 被唤醒后再次等待:LIFO(插到队头)——被唤醒的 bthread 需要与新到达的 bthread 竞争信号量。新到达者已经在 CPU 上运行,有巨大优势。LIFO 插队给被唤醒者更高的优先级,避免被反复"抢跑"导致饥饿
4.4 完整流程图
wait()┌──────────────────────────────────────────┐│ load(num) ││ num > 0? ││ Yes → CAS(num, num-1) ││ → 成功:return 0 ││ → 失败:continue ││ No → butex_wait(butex, 0) ││ → EWOULDBLOCK: continue(值变了)││ → 被唤醒: continue(重新 CAS) ││ → ETIMEDOUT: return errno │└──────────────────────────────────────────┘
关键观察:wait 的循环天然处理了虚假唤醒。 被唤醒后不会假设自己拿到了信号量,而是回到循环顶部重新 load + CAS。这比条件变量的"必须用 while 循环"更自然——信号量的循环本身就是标准用法。
五、post:释放信号量
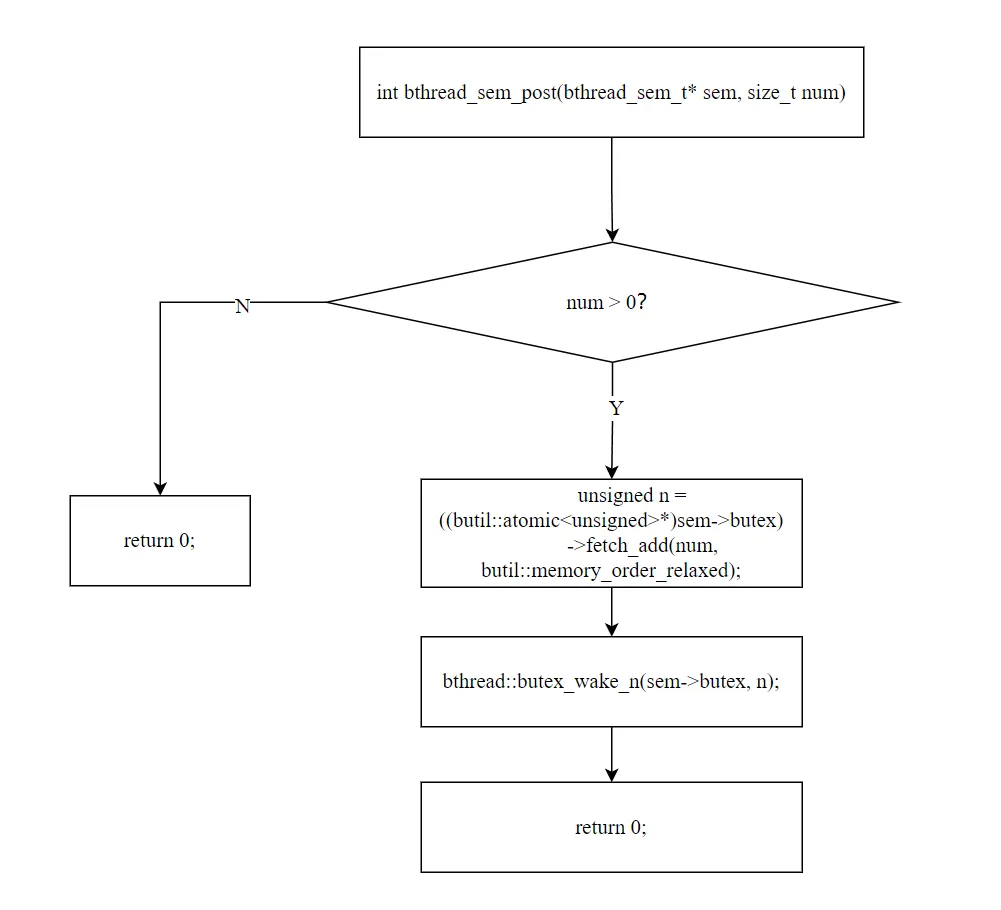
staticinlineintbthread_sem_post(bthread_sem_t* sem, size_t num){ if (num > 0) { unsigned n = ((butil::atomic<unsigned>*)sem->butex) ->fetch_add(num, butil::memory_order_relaxed); bthread::butex_wake_n(sem->butex, n); } return 0;}
post 只需两步:fetch_add 递增计数 + butex_wake_n 唤醒等待者。
5.1 fetch_add:原子递增
unsigned n = ((butil::atomic<unsigned>*)sem->butex) ->fetch_add(num, butil::memory_order_relaxed);
fetch_add 返回旧值n,同时将计数增加 num。这个旧值 n 决定了唤醒策略。
5.2 butex_wake_n:按旧值唤醒
bthread::butex_wake_n(sem->butex, n);
butex_wake_n 的语义:最多唤醒 n 个等待者。但 n 是 post 前的旧值:
n == 0:post 前计数为 0,可能有等待者。butex_wake_n(butex, 0) 会唤醒所有等待者n > 0:post 前计数已大于 0,可能没有等待者。butex_wake_n(butex, n) 最多唤醒 n 个(如果没有等待者,什么也不做)
5.3 为什么 n==0 时唤醒所有?
这是一个容易混淆的设计。考虑一个例子:
初始:butex = 0,3 个等待者在 butex_wait(0) 上挂起post(sem, 2): n = fetch_add(2) → n = 0(旧值) butex 变成 2 butex_wake_n(butex, 0) → 唤醒所有等待者(3 个)3 个等待者都被唤醒后,在 CAS 循环中竞争: 等待者 A: CAS(2→1) 成功,获取信号量 等待者 B: CAS(1→0) 成功,获取信号量 等待者 C: CAS(0→?) 失败,回到 butex_wait 继续等待
唤醒所有等待者 ≠ 所有等待者都能获取信号量。butex_wake_n 的作用是"打破挂起状态",让等待者有机会竞争。 多余的等待者在 CAS 循环中失败后会重新挂起。这是正确的——最多 num(本例中为 2)个等待者能成功获取信号量。
从另一个角度看:如果 n > 0(post 前已有资源),说明当时没有等待者(否则它们早就获取了),所以 butex_wake_n(butex, n) 唤醒 0 个是正确的。
5.4 post_n:批量释放
intbthread_sem_post_n(bthread_sem_t* sem, size_t n){ return bthread::bthread_sem_post(sem, n);}
bthread 独有的功能——标准 POSIX 信号量没有等价操作。一次增加 n 个计数,然后按旧值唤醒等待者。典型场景:生产者一次生产多个资源,一次性通知所有等待者。
普通的 bthread_sem_post 是 post_n 的特例:
intbthread_sem_post(bthread_sem_t* sem){ return bthread::bthread_sem_post(sem, 1);}
六、竞争分析(Contention Profiling)
与互斥锁(本系列第六篇)一样,信号量内置了竞争分析能力。关键代码在 wait_impl 中:
// 等待开始时采样if (NULL != bthread::g_cp && start_ns == 0 && sem->enable_csite && !bvar::is_sampling_range_valid(sampling_range)) { sampling_range = bvar::is_collectable(&bthread::g_cp_sl); start_ns = bvar::is_sampling_range_valid(sampling_range) ? butil::cpuwide_time_ns() : -1;}// 获取成功后提交采样if (start_ns > 0) { const int64_t end_ns = butil::cpuwide_time_ns(); const bthread_contention_site_t csite{end_ns - start_ns, sampling_range}; bthread::submit_contention(csite, end_ns);}
工作流程:
- 进入竞争路径时(CAS 失败或计数为 0),检查竞争分析器是否启动
bthread_sem_disable_csite 可以关闭单个信号量的竞争统计:
intbthread_sem_disable_csite(bthread_sem_t* sema){ sema->enable_csite = false; return 0;}
七、信号量 vs 互斥锁 vs 条件变量
三种同步原语都基于 butex,但设计思路各有不同:
| | | |
|---|
| | | |
| | fetch_add + butex_wake/requeue | |
| | | |
| | signal: butex_wake; broadcast: butex_requeue | |
| | | |
关键区别在于 butex 值的语义:
- 互斥锁:butex 值是编码后的状态(0/1/3),用 exchange 实现"设状态 + 检查旧状态"的原子操作
- 条件变量:butex 值是序列号,每次通知递增,等待者通过比较序列号判断是否被通知
- 信号量:butex 值直接就是计数值,用 CAS 实现原子递减,用 fetch_add 实现原子递增
信号量是三者中最"直接"的——butex 值就是业务含义本身,不需要额外的编码层。
八、与 pthread 信号量的对比
| | |
|---|
| | |
| | butex_wait(bthread 让出 CPU) |
| | bthread_sem_trywait(CAS 循环) |
| | |
| | |
| | |
最后一点是 bthread 同步原语的共同优势:同一个信号量上,bthread 和 pthread 可以互相 wait/post。底层 butex 的 ButexWaiter 通过 tid 区分等待者类型(参见本系列第四篇),唤醒时按类型分发。
九、总结
bthread_sem_t 的设计可以归纳为一句话:butex 的值就是信号量的计数值,用 CAS 消费、fetch_add 生产、butex_wait 阻塞、butex_wake_n 唤醒。
四个关键设计:
1. butex 即计数器。 与互斥锁的位拆分和条件变量的序列号不同,信号量的 butex 值直接就是计数值。这使得实现最直观——读值就是读计数,CAS(num, num-1) 就是获取资源,fetch_add(n) 就是释放资源。
2. CAS 循环 + butex_wait 的组合。 wait 操作在一个循环中交替尝试 CAS 获取和 butex_wait 等待。CAS 失败或计数为零时进入 butex_wait;被唤醒后不假设成功,回到循环顶部重新尝试。这种"乐观尝试 → 悲观等待 → 重新乐观尝试"的模式天然处理了所有竞态和虚假唤醒。
3. post 的按旧值唤醒策略。fetch_add 返回旧值 n,butex_wake_n(butex, n) 按 n 决定唤醒数量。n==0 时唤醒所有等待者——多余的等待者在 CAS 循环中失败后重新挂起。这个设计避免了"精确唤醒"的复杂性。
4. FIFO → LIFO 防饥饿策略。 与互斥锁相同的设计:第一次等待排到队尾(公平),被唤醒后插到队头(避免被新到达者饿死)。在公平性和性能之间取得平衡。
本文基于 Apache brpc 源码(src/bthread/semaphore.cpp、src/bthread/types.h)撰写。