Frida学习笔记(一):Frida 入门 · 原理与架构
- 2026-05-05 14:41:45
Frida学习笔记(一):Frida 入门 · 原理与架构
本篇目标:不只是知道 Frida「能做什么」,而是真正理解它「怎么做到的」。理解了底层原理,你在后续实战中遇到的各种奇怪问题(闪退、Hook 无效、检测被绕不过去)才有思路去排查。
一、从一个实际场景说起
假设你正在做安全测试,面前有一个 Android App。你想知道它登录时把密码加密成了什么、用了什么算法、密钥是什么。
传统做法是用 jadx 反编译 APK,搜关键词、读代码、用 Python 复现——遇到混淆或 Native 层加密会更痛苦。完整的工具链对比与协作流程见 §七。
Frida 提供了一条完全不同的路径:你不需要完全读懂加密代码,只需要在加密函数执行的那一刻「截获」它——看看传进去了什么、吐出来了什么、密钥是什么。整个过程可能只需要写十几行 JavaScript 代码,几分钟就能拿到结果。
这就是动态插桩(Dynamic Instrumentation)的魅力:不需要修改 App,不需要重新编译,在 App 运行的过程中实时拦截任意函数,查看参数,修改返回值。
打个比方:静态分析就像拿到一本加密的菜谱,你要逐字逐句翻译才能知道做了什么菜;动态插桩则是直接站在厨房门口,看食材进去了什么、成品出来了什么——你甚至可以偷偷换掉其中一味调料,看看出品有什么变化。
二、动态插桩的本质:在别人的进程里执行你的代码
要真正理解 Frida,需要先理解一个核心概念:进程地址空间(Process Address Space)。
每个 Android App 运行时都是一个独立的 Linux 进程。这个进程有自己的内存空间,里面装着 App 的代码、数据、运行时栈、Java 虚拟机(ART,即 Android Runtime)等所有内容。正常情况下,进程之间是互相隔离的——你的代码无法直接读写另一个进程的内存。这种隔离是操作系统提供的安全保障:每个进程都认为自己独占了整个内存空间,地址从 0x0 到 0xFFFFFFFFFFFFFFFF(64 位系统),但实际上操作系统通过虚拟内存机制将不同进程的虚拟地址映射到不同的物理内存页上,从而实现隔离。
动态插桩工具的核心能力就是打破这个隔离:把你的代码注入到目标进程的地址空间中去执行。 一旦你的代码运行在目标进程内部,你就拥有了和 App 自身代码完全相同的权限——可以读取它的内存、调用它的函数、修改它的数据。
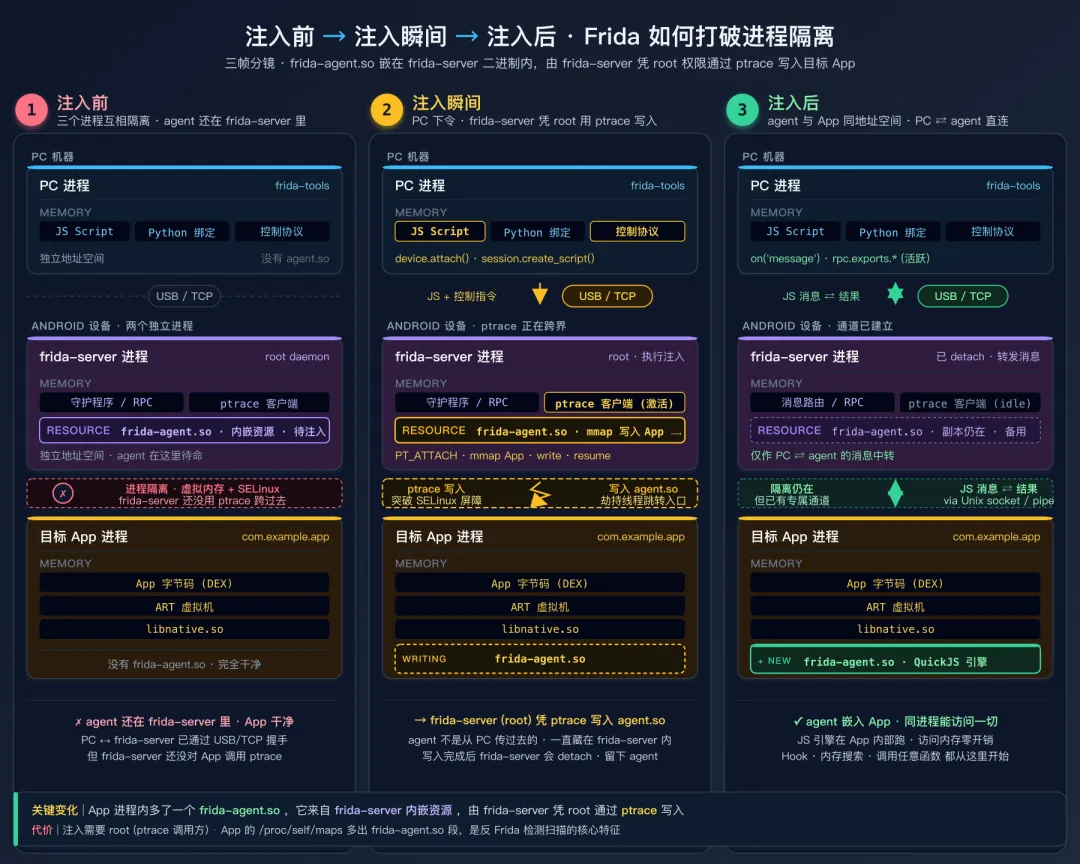
上图用三帧分镜展示了这个过程:注入前 PC、frida-server、目标 App 三个进程互相隔离——PC 已经通过 USB/TCP 跟 frida-server 握上手了,但 frida-server 还没动手 ptrace;这时 frida-agent.so嵌在 frida-server 二进制内部作为只读资源(不在 PC 上、也不在 App 里),App 的内存空间还一片干净(虚拟内存 + SELinux 双重屏障保证它谁都看不见)。注入瞬间,frida-server 凭 root 权限对目标进程发起 ptrace,把自己内嵌的那份 frida-agent.so 写到 App 的地址空间里。注入后,agent 与 App 代码同居一个地址空间,从此 JS 引擎在 App 内部跑,访问 App 任何内存都不需要跨进程系统调用——这就是后续所有能力(Hook / 内存搜索 / 调用任意函数)的根基。
Frida 在此基础上更进一步:它在目标进程内嵌入了一个完整的 JavaScript 引擎,让你用 JS 编写注入逻辑。选 JS 而非 C/Python 的关键理由——轻量、即时解释执行(无编译链接)、几行代码就能完成 Hook。对于需要大量「试错 → 调整 → 再试」的逆向分析,这种不重启 App 就能热加载脚本的交互式体验是 Frida 成为首选的根本原因。
三、Frida 的完整架构:三个组件如何协作
Frida 的工作涉及三个组件,分布在你的电脑和 Android 设备上。理解它们各自的角色和通信方式,对后续的环境搭建和问题排查至关重要。
3.1 整体架构
Frida 架构图
三个核心组件:电脑端 frida-tools、设备端 frida-server、注入到目标 App 进程的 frida-agent,两端通过 USB 或 TCP 通信。
3.2 三个组件的角色
第一个组件:frida-tools(运行在你的电脑上)
这是你在电脑上通过 pip install frida-tools 安装的命令行工具集。它包含多个实用命令:
frida:交互式 REPL(Read-Eval-Print Loop,读取-求值-输出循环),可以实时输入 JS 代码并看到执行结果frida-ps:列出设备上的进程列表,类似 Android 的ps命令frida-trace:快速追踪函数调用,自动生成 Hook 模板frida-ls-devices:列出所有已连接的设备
它的职责是:接收你编写的 JavaScript 脚本,通过 USB 或 TCP 发送给设备上的 frida-server,然后接收并显示脚本的执行结果(比如 console.log 的输出)。
你也可以用 Python 编写自动化脚本来代替命令行——Frida 提供了完整的 Python 绑定(import frida),适用于 RPC 调用和批量自动化场景。
第二个组件:frida-server(运行在 Android 设备上)
这是一个需要 root 权限运行的可执行文件,你需要手动下载并推送到设备上。它接收来自电脑的指令,对目标 App 进程执行注入操作——核心流程见「注入前 / 注入瞬间 / 注入后」三帧分镜图:ptrace attach → 把 frida-agent.so 写入 App 地址空间 → 劫持目标线程跳转到 agent 入口。注入完成后 frida-server 就可以放手了,后续 PC 与 agent 的通讯消息只是借道 frida-server 转发。
ptrace(Process Trace)是 Linux 内核提供的调试接口,调试器(如 gdb)也是通过它控制被调试进程。这就是为什么 frida-server 需要 root 权限——普通权限无法 ptrace 其他 App 的进程(Android 的 SELinux 策略进一步限制了这一点)。
ptrace 注入有两个绕不开的副作用值得注意:
TracerPid痕迹 —— ptrace attach 期间/proc/self/status的TracerPid字段会变成 frida-server 的 PID。注入完成后 server 通常会 detach,TracerPid短暂闪过即归零;但目标进程的/proc/self/maps里多出来的frida-agent.so内存段是无法消除的痕迹——很多反 Frida 检测就靠扫描 maps 抓这个特征。写入跳转指令的瞬时卡顿 —— 这里专指 Native Inline Hook(详见 4.2 小节):Frida 要把目标 Native 函数最开头几条机器指令覆写成「跳转到 trampoline」的指令,相当于在一段正在执行的代码上做"开颅手术"。为了避免覆写期间另一个线程恰好执行到这几条指令、读到半旧半新的字节流而崩溃,Gum 引擎会先 SIGSTOP暂停目标进程里所有其他线程,写完跳转再SIGCONT恢复。一停一启通常在极短时间内完成;但短时间内一次性 Hook 几百个 Native 函数时,暂停时长会累加到几十毫秒级,可能看到画面顿一下。
第三个组件:frida-agent(注入到目标进程中的共享库)
这是 Frida 的核心。它运行在目标 App 的进程空间内,包含两个关键子系统:
第一个是 JavaScript 引擎。Frida 历史上默认用的是 Duktape(一个轻量级嵌入式 JS 引擎,体积小、启动快),V8(Chrome 和 Node.js 用的那个)作为可选高性能引擎一直存在;近年(16.x 起)默认引擎换成了 QuickJS——同样轻量但 ES2020 语法支持更完整。三个引擎可以通过 Script.runtime 切换,常规 Hook 用默认即可,只有在 Stalker 这类需要高频 JS 执行的场景才考虑切到 V8。
你编写的所有 JS 脚本都在这个引擎里执行。因为 JS 引擎本身就在目标进程内部,所以你的脚本可以直接访问目标进程的内存和函数——这不是远程调用,而是真正的「同进程执行」。
第二个是 Gum 引擎——这是 Frida 的 Hook 核心。Gum 是 Frida 团队开发的一个跨平台插桩库,用 C 语言编写,支持 x86、x86_64、ARM、ARM64 等多种架构。Gum 提供了两套 Hook 机制,分别对应 Java 层和 Native 层的函数拦截。当你在 JS 脚本里写 Java.use("SomeClass").someMethod.implementation = ... 时,背后就是 Gum 引擎在工作。
3.3 版本必须精确匹配
理解了这三个组件的关系后,你就能理解为什么 Frida 最常见的报错是版本不匹配。frida-tools(电脑端)和 frida-server(设备端)之间通过 frida-core 协议通信,最低要求是 major.minor 版本对齐——比如 16.5.x 系列内通常可以互通(patch 版本一般不破坏协议),但跨 minor(16.4 ↔ 16.5)或跨 major(15 ↔ 16)几乎肯定握手失败。
可以通过以下命令确认版本是否一致:
# 查看电脑端 frida-tools 的版本
frida --version
# 输出示例: 16.5.2
# 查看设备端 frida-server 的版本(需要先启动 frida-server)
frida-ps -U
# 如果能正常列出进程列表,说明版本匹配
# 如果报错 "unable to communicate with remote frida-server",先核对到 minor
排查技巧:遇到
unable to communicate类错误,先比对 frida-tools 和 frida-server 的 major.minor 是否一致。工程稳妥做法是完全对齐——用pip install frida-tools==<版本号>钉在同一个具体版本号上,这样换设备、切环境时不需要再花心思排查兼容性。
四、Hook 的底层原理:Frida 是怎么拦截函数调用的
「Hook」是安卓逆向中最核心的操作。所谓 Hook(钩子),就是在目标函数执行前后插入你的自定义逻辑。理解 Frida 是如何实现 Hook 的,能帮你在遇到 Hook 不生效、App 崩溃等问题时快速定位原因。
Frida 的 Gum 引擎提供了两套完全不同的 Hook 机制,分别针对 Java 层和 Native 层。
4.1 Java 层 Hook:修改 ArtMethod 的入口指针
Android App 的 Java/Kotlin 代码运行在 ART 虚拟机上。ART 内部为每个 Java 方法维护了一个叫做 ArtMethod 的数据结构,其中有一个关键字段:entry_point_from_quick_compiled_code_。这个字段是一个函数指针,指向该方法编译后的机器码入口地址。当这个 Java 方法被调用时,ART 虚拟机会跳转到这个指针指向的地址去执行。
补充说明:ART 有两种执行模式——解释执行(Interpreter)和编译执行(Quick Compiled Code)。现代 Android 设备上,大部分热点方法在安装时就被 AOT(Ahead-Of-Time)编译成了机器码,存储在 OAT 文件中。
entry_point_from_quick_compiled_code_指向的就是这些预编译好的机器码。对于还没有被编译的方法,这个指针指向解释器的入口,由解释器逐条执行 DEX 字节码。
Frida 的 Java Hook 原理就是修改这个指针:
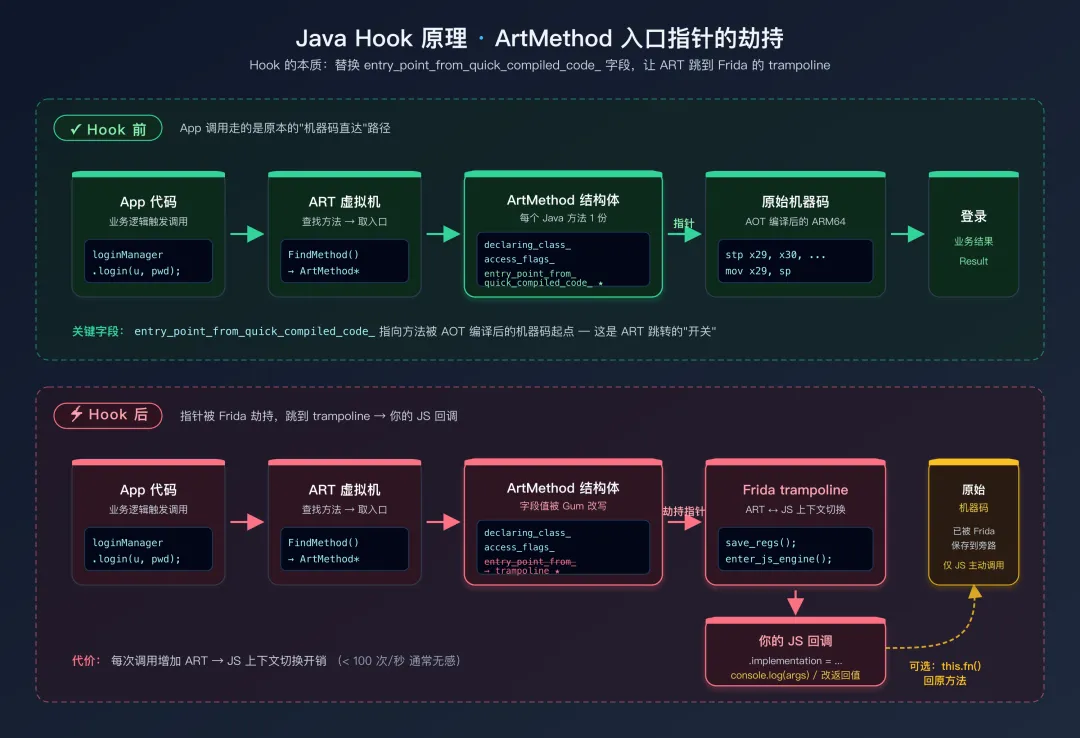
上图清晰地展示了 Hook 前后 ArtMethod 入口指针的变化:修改前指向原始方法的机器码,修改后指向 Frida 的 trampoline(跳板)代码。trampoline 负责在 ART 上下文和 JS 引擎之间来回切换,确保你的 JS 回调能正确执行,同时不破坏原始方法的正常逻辑。
当你在 Frida 脚本中写下这样的代码时:
// Java 层 Hook 的基本形式
Java.perform(function() {
// 在 Java.perform 顶部一次性 use(脚本启动时执行一次,缓存到本地变量)
// 不要在循环或回调内反复 Java.use —— 它会通过 JNI 枚举类的所有方法和字段,开销大
var LoginManager = Java.use("com.example.app.LoginManager");
// 替换 login 方法的实现
// .implementation 赋值会触发 Gum 引擎修改 ArtMethod 的入口指针
LoginManager.login.implementation = function(username, password) {
// 这里的代码会在每次 login 被调用时执行(复用上面缓存的 LoginManager)
// 可以查看传入的参数值
console.log("拦截到登录请求: " + username + " / " + password);
// 调用原始方法,让 App 正常执行登录逻辑
// this 指向 LoginManager 的实例对象
var result = this.login(username, password);
// 也可以查看原始方法的返回值
console.log("登录结果: " + result);
return result;
};
});
Frida 在背后做了以下事情:
Java.perform把当前线程注册到 ART 虚拟机——内部调的是 JNI 的AttachCurrentThread:ART 给这个线程分配一个JNIEnv*指针并存进线程局部存储(TLS),这个指针就是后续所有 Java 操作(Java.use、调用方法、读字段)跟 ART 内部对话的票据。Java.use("com.example.app.LoginManager")通过 JNI 的FindClass查找这个类(注意 JNI 中用/而不是.作为包名分隔符,Frida 会自动转换),然后创建一个 JavaScript 代理对象(Wrapper),把这个类的所有方法和字段都映射到 JS 属性上。.login.implementation = function(...) {...}这一行触发了真正的 Hook:Gum 引擎找到login方法对应的ArtMethod结构体,保存原始的entry_point_from_quick_compiled_code_,然后把它替换为 Frida trampoline 的地址。之后每次 App 代码调用
loginManager.login(user, pwd)时,ART 会跳转到 Frida 的 trampoline 而不是原始方法。trampoline 将执行流切换到 JS 引擎,调用你的回调函数。回调中的this.login(username, password)会通过之前保存的原始入口点调用真正的方法实现。
从这个原理中可以推导出几个重要结论:
第一,Java Hook 是方法级别的——你只能 Hook 整个方法,无法 Hook 方法内部的某一行代码。如果你想在方法执行到一半时插入逻辑,那是做不到的(这种需求需要 smali patch 或 dex 修改)。
第二,Hook 有性能开销。每次被 Hook 的方法被调用,都会经历「ART 上下文保存 -> 切换到 JS 引擎 -> 执行 JS 代码 -> 切换回 ART -> 恢复上下文」这样一个完整的流程。对于偶尔调用的方法(比如登录),这个开销完全可以忽略;但如果你 Hook 了一个每帧都会调用几百次的渲染方法,App 可能会明显变卡。经验法则是:Hook 调用频率低于每秒 100 次的方法通常没有明显感知。
顺便提一个常见坑:
Java.use("...")本身的开销也不可忽略——它会通过 JNI 枚举类的所有方法和字段来构造 Wrapper。在大类(比如android.app.Activity这种几百个方法的)上反复调用Java.use会让脚本启动明显变慢。正确做法是:在脚本顶部一次性Java.use,把 Wrapper 缓存到变量里,循环或回调中复用——不要每次都重新 use。
第三,this 关键字在 Hook 回调中指向的是被 Hook 方法所属对象的 Java Wrapper。这意味着你不仅可以调用被 Hook 的方法,还可以通过 this 调用该对象的其他任何方法,或者读取修改它的字段。对于静态方法,this 指向类本身。这是一个非常强大的能力——比如你 Hook 了某个方法后,发现需要调用同一对象的另一个私有方法来获取上下文信息,直接通过 this 就能做到。
4.2 Native 层 Hook:Inline Hook(内联钩子)
当你需要 Hook C/C++ 编写的 Native 函数(比如 SO 库中的加密函数)时,Frida 使用的是一种叫做 Inline Hook 的技术。与 Java Hook 修改虚拟机内部数据结构不同,Inline Hook 直接操作的是 CPU 将要执行的机器指令本身。
Inline Hook 的原理非常直接:直接修改目标函数开头的几条机器指令,把它们替换成一条跳转指令(jump),跳到 Frida 的 trampoline 代码。原始的几条被覆盖的指令会被保存到一个「跳板」区域,在调用原始函数时通过跳板来执行它们。

上图分两段:上半部分是修改前后的指令对比(左 = 原始 / 右 = 跳转 patch),下半部分是 trampoline 的 5 步执行流程。
Frida 的 trampoline 代码会:
保存所有 CPU 寄存器(ARM64 有 31 个通用寄存器 X0-X30,加上 SP、PC 等特殊寄存器) 调用你的 onEnter回调,把寄存器值作为args数组暴露给你恢复寄存器,跳到保存原始指令的跳板区域执行被覆盖的指令 执行完原始指令后跳回目标函数的第三条指令,继续正常执行 当函数返回时,再次跳到 trampoline,调用你的 onLeave回调
对应到 Frida 脚本:
// Native Hook 的基本形式
// 先通过模块名和导出函数名找到目标函数的内存地址
var targetFunc = Module.findExportByName("libnative.so", "encrypt");
// 使用 Interceptor.attach 进行 Inline Hook
Interceptor.attach(targetFunc, {
// onEnter: 函数被调用时触发(在原始函数执行之前)
onEnter: function(args) {
// args[0], args[1], ... 是 CPU 寄存器中的函数参数
// 对于 ARM64 调用约定 (AAPCS64),前 8 个参数通过 X0-X7 寄存器传递
// 超过 8 个的参数通过栈传递
console.log("encrypt 被调用");
console.log(" 参数1 (X0): " + args[0]); // 通常是输入数据的指针
console.log(" 参数2 (X1): " + args[1]); // 通常是数据长度或密钥
// 如果参数是指针,可以读取它指向的内存内容
// 例如读取一个 C 字符串:
// console.log(" 输入数据: " + Memory.readUtf8String(args[0]));
// 保存参数供 onLeave 使用
this.arg0 = args[0];
},
// onLeave: 函数返回时触发(在原始函数执行之后)
onLeave: function(retval) {
// retval 是返回值(ARM64 中通过 X0 寄存器返回)
console.log("encrypt 返回: " + retval);
// 可以修改返回值(谨慎使用)
// retval.replace(0x0); // 把返回值改为 0
}
});
Inline Hook 的几个重要细节:
第一,ARM32 和 ARM64 的跳转指令编码不同——ARM32 用的是 LDR PC, [PC, #-4] 这种 4 字节指令(紧跟一个 4 字节地址常量,整个 patch 共 8 字节),ARM64 用的是 LDR X16, [PC, #8]; BR X16 这种 8 字节指令序列(再加 8 字节地址常量,整个 patch 共 16 字节)。所以你在用 IDA 看 SO 时,函数前 16 字节如果突然变成 ldr/br/.quad 这种模式,那就是被 Frida hook 过的特征。Frida 内部会自动检测目标架构并使用正确的编码,你不需要关心这个差异。
第二,ARM32 还有一个 Thumb 模式 的问题。ARM32 支持两种指令集:32 位的 ARM 指令和 16 位的 Thumb 指令(Thumb-2 扩展后也支持 32 位指令)。如果目标函数使用 Thumb 指令编译(现代 Android NDK 默认使用 Thumb),函数地址的最低位会被设为 1 来标记 Thumb 模式。Frida 同样会自动处理这个细节,但如果你用 IDA 分析 SO 时看到函数地址是奇数(比如 0x1001),不要困惑——实际地址是 0x1000,最低位只是 Thumb 标记。
实用技巧:在 Frida 脚本中使用
Module.findBaseAddress("libnative.so")获取 SO 的基地址后,加上 IDA 中看到的函数偏移就能得到运行时的真实地址。如果 IDA 显示的地址是 Thumb 模式的奇数地址,记得保留那个 +1,因为 Frida 需要这个标记来识别 Thumb 模式。
第三,Inline Hook 会有线程安全的问题。想象一下:线程 A 正在执行目标函数的第二条指令(即将执行第三条),而此时 Frida 开始修改前三条指令为跳转代码。如果时机恰好,线程 A 可能会跳转到不完整的代码,导致崩溃。Frida 的 Gum 引擎通过在修改指令前暂停目标进程的所有其他线程来规避这个问题,修改完成后再恢复。这也是为什么大量并发 Hook 可能导致短暂的 App 卡顿。
五、Spawn 模式 vs Attach 模式:不只是「启动方式」的区别
这两种模式的选择直接影响你能 Hook 到哪些代码,理解它们的差异是写出有效脚本的基础。
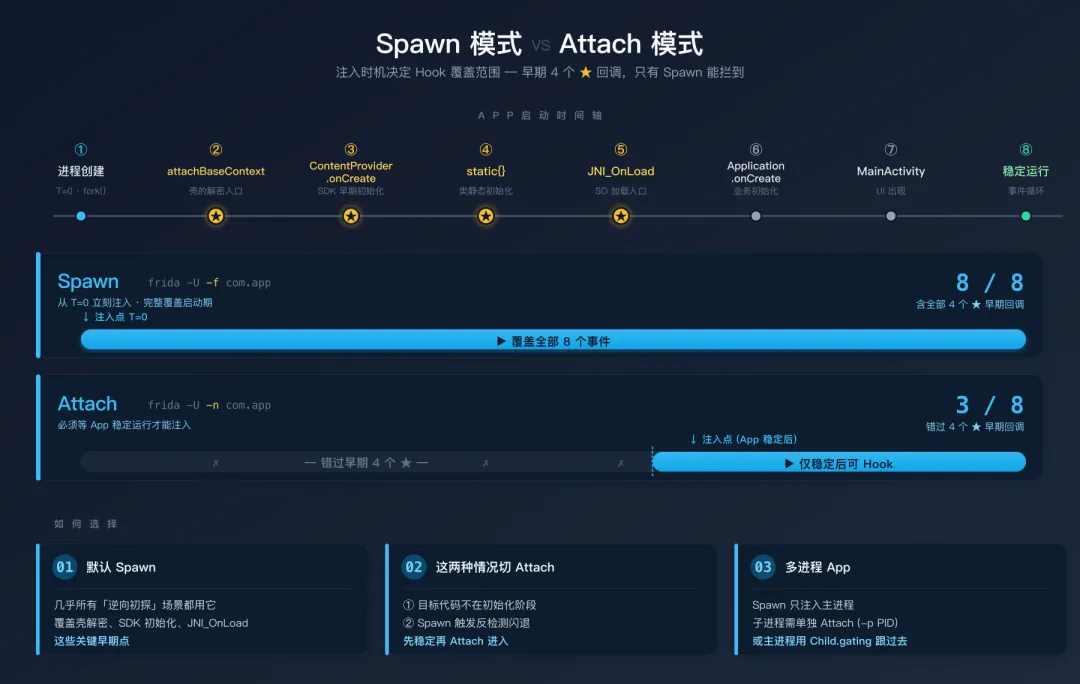
上图以时间轴的形式标出了 App 启动过程中的 8 个关键节点(从 fork() 开始,依次经过 attachBaseContext → ContentProvider.onCreate → static{} → JNI_OnLoad → Application.onCreate → MainActivity → 稳定运行)。Spawn 模式的注入点在最左端(进程创建后立刻),所以青色覆盖区贯穿整条时间轴;Attach 模式的注入点要等 App 稳定运行后才落下,玫红覆盖区只在右端——4 个标了 ★ 的早期回调(壳的解密入口、SDK 早期初始化、类静态块、JNI_OnLoad)就这样被全部错过。
记住这个时间轴,后面遇到"为什么我 Hook 了 attachBaseContext 却没生效"这种问题就有判断依据了——大概率你用的是 Attach 模式。
5.1 Spawn 模式
命令格式:frida -U -f com.example.app -l script.js
在这种模式下,Frida 负责启动目标 App(通过 Android 的 am start 命令)。但关键在于:Frida 会在进程创建后、App 的任何 Java 代码执行之前就完成注入。
旧版 Frida (≤ 12.x) 在
-f模式下默认会暂停进程等你 resume,需要加--no-pause才不暂停;16.x 起默认即非暂停模式,这个 flag 已不需要再写。
这意味着你的 Hook 脚本可以拦截到 App 生命周期中最早期的代码,包括:
Application.attachBaseContext() —— 这是 Android 应用生命周期中最早的回调。几乎所有的加固壳(360 加固、腾讯乐固、梆梆加固等)都在这个方法中完成 DEX 解密和加载。如果你想 Hook 壳的行为或者在壳解密后立刻 dump DEX,必须用 Spawn 模式。
ContentProvider.onCreate() —— 这个回调比 Application.onCreate() 还要早(Android 系统会在 Application 创建后、onCreate 调用前,先初始化所有在 AndroidManifest 中声明的 ContentProvider)。部分 SDK 和分析框架(如 Facebook SDK、Firebase)会利用 ContentProvider 的这个特性来做早期初始化,避免开发者忘记在 Application 中手动初始化。
static {} 静态初始化块 —— 当一个类第一次被加载时执行。部分安全检测逻辑放在静态初始化块中,以确保在任何方法调用之前完成检测。
JNI_OnLoad() —— 当 System.loadLibrary() 加载一个 Native 库时,ART 会调用该库的 JNI_OnLoad 函数。很多动态注册 JNI 方法的逻辑都在这里完成——这意味着如果你想知道某个 native 方法最终指向哪个 C 函数,就需要在 JNI_OnLoad 阶段进行追踪。
5.2 Attach 模式
命令格式:frida -U -n com.example.app -l script.js
附加到一个已经在运行的 App 进程。-n 显式声明这是按进程"名字"匹配,避免在多进程 App(同名 + :remote 子进程)上歧义;如果你已经知道目标 PID,更精确的写法是 frida -U -p <pid>。优点是不需要重启 App,适合分析 App 已经进入稳定运行状态后的行为。缺点是你的 Hook 在 App 启动之后才生效,上面提到的所有早期代码你都会错过。
5.3 如何选择
在实际工作中,默认使用 Spawn 模式 是一个安全的策略。只有以下场景才需要 Attach 模式:
场景一:目标代码明确不在初始化阶段。 比如你要分析一个特定页面的行为,而 App 已经在这个页面上了,Attach 可以避免重新导航到目标页面。
场景二:Spawn 模式会触发反 Frida 检测导致闪退。 有些 App 在启动早期(JNI_OnLoad 或 Application.attachBaseContext 中)就运行了检测线程。如果检测逻辑在你的绕过脚本生效之前就执行了,App 会闪退。这时可以尝试先让 App 正常启动(通过检测窗口),等 App 稳定后再 Attach 注入绕过脚本。当然,更好的做法是在 Spawn 模式的脚本中把反检测逻辑放在最前面。
场景三:多进程 App。 部分 App 使用多进程架构(在 AndroidManifest 中给某些 Service 或 Activity 设置了 android:process 属性)。Spawn 模式只会注入主进程。如果你要 Hook 子进程的代码,需要先用 frida-ps -U 找到子进程的 PID,然后 Attach 到它。
进阶技巧:对于多进程场景,Frida 还提供了
Child.gatingAPI,可以在主进程 fork 子进程时自动注入到子进程中。这在后续的进阶篇中会详细介绍。
六、Frida 能做什么:能力清单与边界
在正式动手之前,明确 Frida 能做什么和不能做什么,可以帮你避免走弯路。
6.1 Frida 擅长的事情
拦截函数调用 —— 这是 Frida 的核心能力。Java 方法和 Native 函数都可以拦截,查看参数和返回值,甚至修改它们。比如把一个返回 false 的 Root 检测函数强制改成返回 true。
运行时类和对象分析 —— 枚举已加载的类(Java.enumerateLoadedClasses)、查看类的方法和字段、在 Java 堆中搜索特定类型的活跃对象实例(Java.choose)、读取和修改对象的字段值。这在分析运行时状态时极其有用。
绕过安全检测 —— SSL Pinning(证书锁定)、Root 检测、模拟器检测、反调试检测、Frida 自身检测等各种防护手段,都可以通过 Hook 相关检测函数来绕过。这是安全测试中最常用的功能之一。
内存操作 —— 搜索进程内存中的特定字节模式(Memory.scan)、读写指定地址的内存内容(Memory.read* / Memory.write*)、分配新的内存区域(Memory.alloc)。
RPC 调用 —— 将 App 内部的函数暴露给外部 Python 脚本调用。比如把 App 的加密函数变成一个可以远程调用的 API,然后用 Python 批量调用它来生成签名——这在接口自动化测试中非常实用。
指令级追踪 —— 通过 Stalker 引擎追踪 Native 代码的执行流程,获取每一条被执行的机器指令,生成代码覆盖率报告。Stalker 是 Frida 中最高级的功能之一,可以帮你理解高度混淆的 Native 代码的执行路径。
6.2 Frida 的局限
不能 Hook 方法内部的某一行 —— Frida 的 Hook 粒度是函数级别。如果你需要在一个函数内部的特定位置插入逻辑(比如修改某个 if 判断的条件),需要用 smali patch 或 Xposed 等方案。不过,对于 Native 函数,你可以通过 Interceptor.attach 到函数内部的特定地址来实现更细粒度的控制。
不能在没有 Root 的设备上使用 frida-server —— frida-server 依赖 ptrace 系统调用,而 ptrace 需要 root 权限才能附加到其他进程。不过,有一种替代方案叫 Frida Gadget,可以将 Frida 的 agent 打包进 APK 中(通过修改 APK 的 lib 目录并在 smali 代码中添加 System.loadLibrary("frida-gadget") 调用),这样即使设备没有 Root 也能使用(代价是需要重新打包 APK 并重新签名)。
对高度混淆/虚拟化保护的代码效果有限 —— 如果 App 使用了虚拟机保护(VMP,如梆梆加固的高级保护),Java 方法的字节码被替换成了自定义虚拟机指令,标准的 Java Hook 可能失效(因为方法已经变成了 native 方法,实际逻辑在自定义解释器中执行)。这种情况需要分析虚拟机解释器本身,复杂度显著上升。不过你仍然可以 Hook 解释器的入口函数,通过分析其输入输出来间接理解被保护的逻辑。
多进程支持有限 —— frida CLI 默认一次只附加一个进程,如果 App 使用了多进程架构,你需要分别 Attach 到每个进程(可以用 frida-ps -U | grep com.example 查看该 App 的所有进程)。frida-server 本身其实是个并发 daemon,可以同时管理多个会话——只是 CLI 没把这个能力直接暴露出来。如果你是用 Python 编写自动化脚本,可以多次调用 device.attach() 在同一个 frida-server 上并发注入多个进程;要在主进程 fork 子进程的瞬间自动跟过去,则用 Child.gating API(后续进阶篇详细介绍)。
七、Frida 与其他逆向工具的对比与协作
Frida 不是孤立使用的,而是整个逆向工具链中的一环。理解它在工具生态中的位置,能帮你建立正确的工作流。
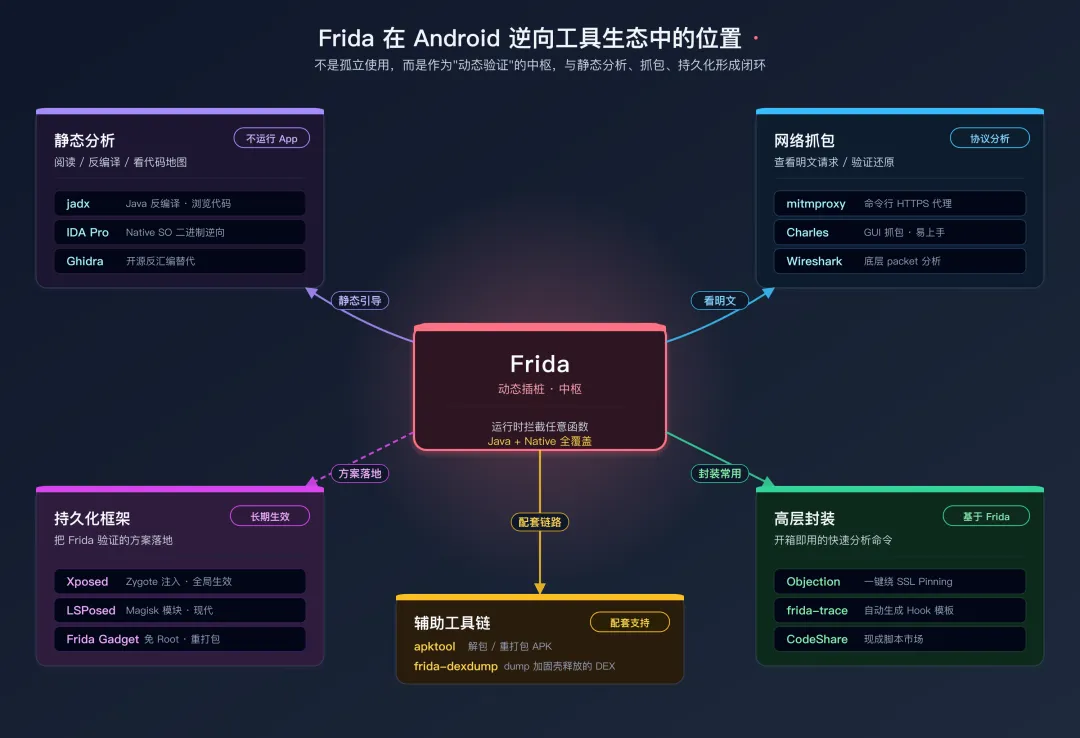
上图展示了 Frida 在安卓逆向工具生态中的核心位置,以及它与静态分析工具、网络抓包工具、持久化框架之间的协作关系。
7.1 Frida vs Xposed(LSPosed)
简单来说:Frida 适合「分析和研究」,Xposed 适合「持久化修改」。 在实际工作中,常见的模式是先用 Frida 快速搞清楚目标逻辑,验证方案可行后,再把成果移植到 Xposed 模块中做持久化。两者是互补而非竞争关系。
7.2 Frida 与静态分析工具的协作
Frida 是动态分析工具,它需要 App 实际运行才能工作。而 jadx、IDA Pro、Ghidra 等静态分析工具可以在不运行 App 的情况下分析代码。两者是互补关系,结合使用效果最佳。
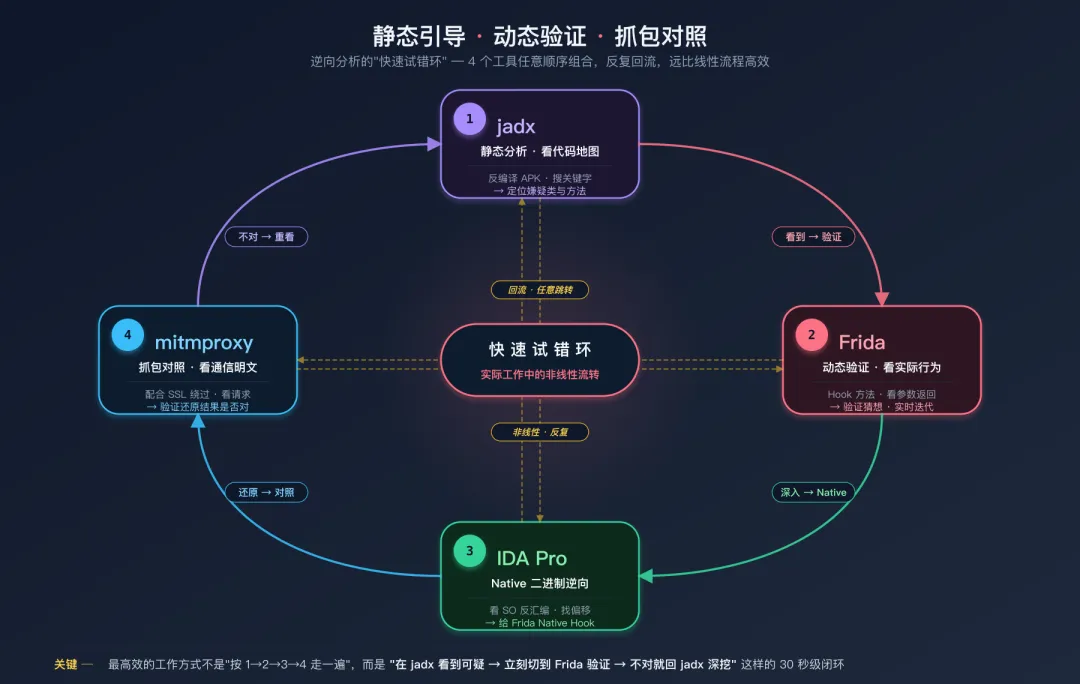
上图展示了 4 个工具的协作关系:jadx 建代码地图 → Frida 动态验证 → IDA 啃 Native → mitmproxy 抓包对照 是理想顺序的外圈主循环;但实际工作里你会在任意两个工具之间反复回流(中间的琥珀色虚线箭头)——在 jadx 看到一个可疑方法名,立刻切到 Frida 验证;Frida 发现逻辑跑到了 SO 里,立刻切 IDA;IDA 找到偏移后又回 Frida 装 Hook;最后用 mitmproxy 核对加密结果。
效率提示:这是"静态引导、动态验证"的 30 秒级闭环——在 jadx 中看到可疑方法,立刻切 Frida Hook 看实际行为,根据结果再回 jadx 深挖。线性走完一圈反而效率低,能在两个工具之间快速回切才是高效逆向的核心节奏。
7.3 Frida 与 Objection
Objection 是基于 Frida 的一个高层封装工具,提供了很多开箱即用的功能(启动方式:objection -g com.example.app explore,进入交互式 shell 后执行下列命令):
一键绕过 SSL Pinning( android sslpinning disable)列出所有 Activity、Service、BroadcastReceiver dump KeyStore 中的密钥 枚举已加载的类和方法 搜索内存中的字符串
适合在拿到一个新 App 时做快速信息收集。但它的灵活性不如直接写 Frida 脚本——当你需要精确控制 Hook 逻辑、处理复杂参数类型、或者做自动化分析时,还是需要回到 Frida 脚本。
建议的使用策略是:拿到一个新 App 时,先用 Objection 做一轮快速扫描,了解 App 的基本结构和防护情况。确定具体的分析目标后,再用 Frida 脚本做精确的 Hook。
总结
回顾一下本篇的核心内容:
Frida 是什么? 一个动态插桩工具,它通过在目标进程中注入包含 JavaScript 引擎和 Hook 引擎的 agent(frida-agent.so),让你能够在 App 运行的过程中实时拦截任意函数调用。
架构如何工作? 由三个组件构成:你电脑上的 frida-tools、设备上以 root 权限运行的 frida-server、以及注入到目标进程中的 frida-agent。三者通过 USB/TCP 通信,版本至少要 major.minor 一致(实际部署建议完全对齐)。
Hook 是怎么实现的? Java 层 Hook 通过修改 ART 虚拟机中 ArtMethod 的入口指针实现;Native 层 Hook 通过 Inline Hook(修改目标函数开头的机器指令)实现。两种机制的原理不同,但在 Frida 脚本层面的使用方式都被封装成了简洁的 JavaScript API。
两种注入模式有什么区别? Spawn 模式在 App 启动前注入,能 Hook 到最早期的代码;Attach 模式附加到已运行的进程,适合不需要 Hook 初始化逻辑的场景。

