摘要:这是「算法学习笔记」系列的第一篇,用 Numpy 实现线性回归,在 Kaggle 房价数据集上从单变量开始,R² 只有 0.54;发现问题后加入更多特征,R² 直接跳到 0.84。没换算法没调参,只加了几个特征。ChatGPT很火,大模型很火。但如果只会调API,你永远只是使用者。
所以我决定开一个系列,从最基础的算法开始,一个个实现、记录下来。每篇围绕一个算法,用数据集跑一遍,说清楚逻辑和踩过的坑。
这是第一篇:线性回归。这次用的数据是Kaggle上的House Prices竞赛题,79 个特征,从面积、质量到地下室、车库。这个数据集在ML圈子里被用了无数遍。
一、先试试最简单的:只用面积来预测
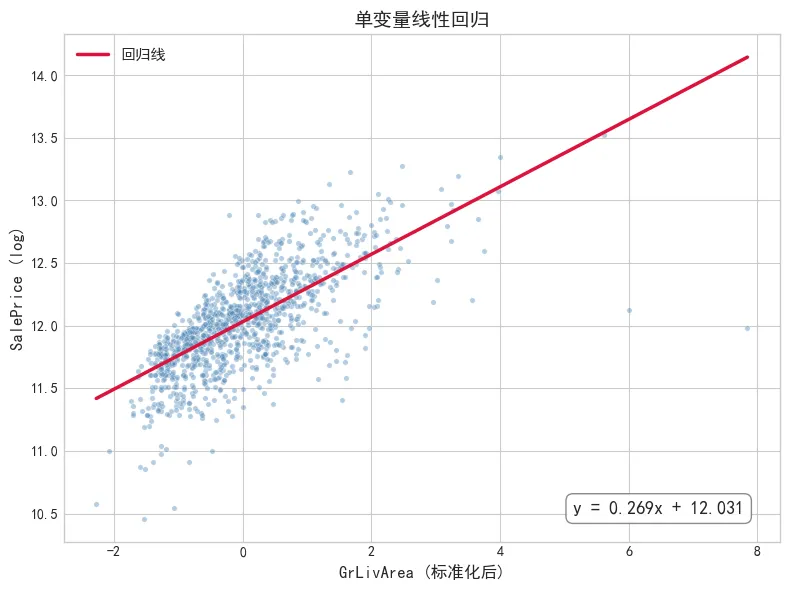
我的第一反应和大多数人一样,房价,跟面积最相关,越大越贵。那就先从GrLivArea(地上居住面积) 这一个特征开始。
线性回归说到底就是找一条直线:
w 是斜率,b 是截距。问题是怎么让机器自己找到最好的 w 和 b?核心代码其实就 20 多行
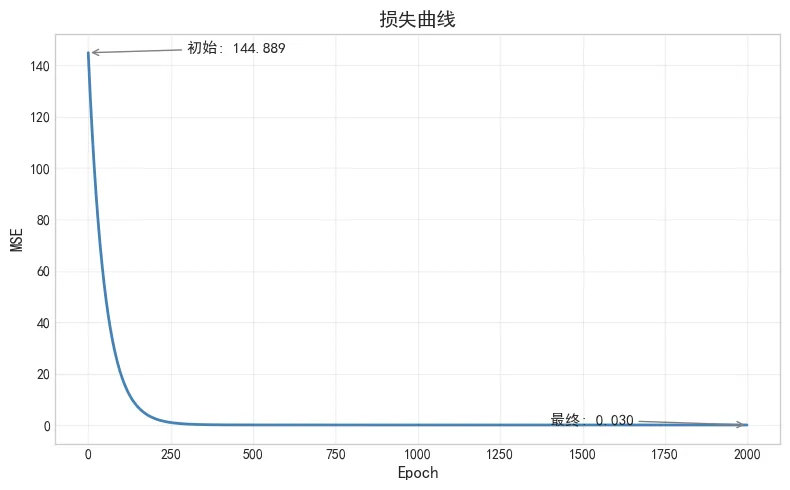
class LinearRegression: def fit(self, X, y): self.w = np.zeros(X.shape[1]) self.b = 0 for _ in range(self.epochs): y_pred = np.dot(X, self.w) + self.b # 预测 loss = np.mean((y_pred - y) ** 2) # 算误差 dw = (1/n) * np.dot(X.T, (y_pred - y)) # 算梯度 db = (1/n) * np.sum(y_pred - y) self.w -= self.lr * dw # 更新参数 self.b -= self.lr * db
循环里就三件事:预测 → 算误差 → 调参数。这就是梯度下降,也是现在训练大模型最底层的逻辑,只是规模放大了无数倍。
你可能会想:线性回归跟大模型能是一回事?本质上的确是的。代码里调的 w 和 b 加起来才几个参数,GPT 是几千亿个参数;我用的数据是几百条房价,GPT 是整个互联网的文本。但从数学上看,都是用误差信号去更新参数,让模型下一次输出更接近目标。大模型强在参数量和数据量,不是强在底层算法。
1、数据不能瞎喂
一开始我差点犯一个低级错误——拿全部数据去训练,再用全部数据评估。这种方式其实是"背答案",不是学习。模型把答案都记住了,换一套新数据立马露馅。
正确做法是划分训练集和测试集, 本次使用的是80% 训练、20% 测试,测试集是模型从没见过的数据,才能看出真实水平。还有数据标准化。面积、年份、质量评分,量纲完全不一样,面积几百平,年份两千多年,不缩放到统一范围,梯度下降会像醉汉走路一样震荡。
另外还对房价做了log变换。因为房价分布是右偏的,大部分房子在中间价位,少数豪宅能贵好几倍。线性回归希望误差均匀分布,但原始房价下,豪宅那几万的误差会主导梯度,模型变成"豪宅拟合器",反而把主流价格区间忽视了。取log后分布更接近正态,模型能均衡地学习所有价格区间。
2、结果出来,有点失望
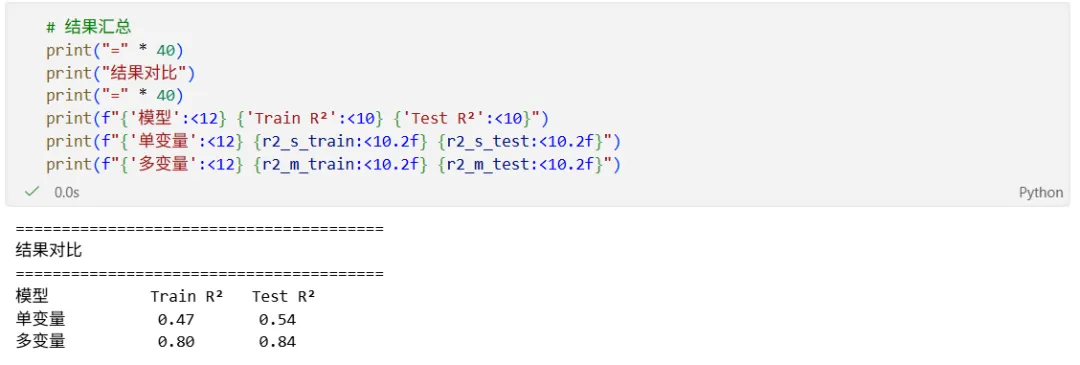
模型跑完,测试集 R² 为0.54。R² 越接近 1 越好,0.54 意味着模型只能解释一半多的房价波动——剩下将近一半的差异完全没抓住。说实话,比我预想的低。
3、 0.54 够用吗?当然不
回头一想,只用面积预测房价,本来就不太可能准:
那怎么办?一个特征不够,那就加特征。
二、多变量:把更多信息喂给模型
线性回归的一个好处是,它天然支持多个特征——公式从一条直线变成一个超平面:
价格 = w₁×面积 + w₂×质量 + w₃×地下室面积 + ... + b
代码一行都不用改,同样的梯度下降,只是输入从一列变成多列。
不是有 79 个特征吗,全塞进去不就行了?没那么简单。大部分特征是类别型的(比如 Neighborhood、MSZoning),不能直接喂,得先做独热编码;还有不少列有缺失值,得先填充;有些是文本描述,得转成数值评分。这些都需要额外处理。
作为第一轮实验,我挑了 数值型、没缺失、跟房价相关性高的特征,快速跑个 baseline。剩下的后面再处理。选了 5 个,加上原来的 GrLivArea,一共 6 个:
| | |
OverallQual(整体质量) | | 跟房价相关性最高的特征(r ≈ 0.79),建材和装修质量直接决定房价 |
TotalBsmtSF(地下室面积) | | |
YearBuilt (建造年份) | | |
GarageCars(车库容量) | | |
FullBath (卫生间数量) | | |
结果R² 直接跳到 0.84。
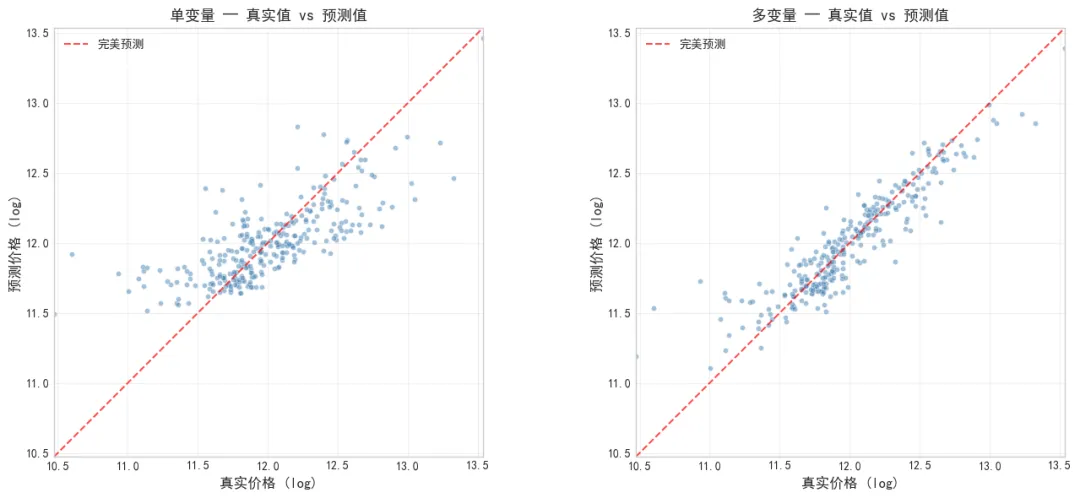
看到这个结果的时候,说实话有点意外。R²涨了0.30,比调任何超参数都管用。对比散点图更直观:单变量的预测点散得到处都是,多变量的点明显更贴近对角线。
三、下一篇预告
R²=0.84 看着不错了,但还有提升空间。这次只用了数值型特征,类别特征还没碰。下一篇会用Ridge和Lasso,加上类别特征的编码处理,看看能不能推到更高。
这个系列会持续更新:线性模型 → 决策树 → 随机森林 → GBDT → SVM → 聚类 → PCA → MLP → CNN → RNN → ...
如果觉得有帮助,欢迎关注。代码和数据集在 [GitHub](https://github.com/HuangWuwutelling/ml-learning),所有实验都可以复现。