在上一篇文章中,我们拆解了 ObjectPool 的三层无锁分配设计。它用 TLS 让每个线程独享 Block 和 FreeChunk,将对象分配和归还的锁竞争降到最低。
但 ObjectPool 有一个局限:对象只能通过指针访问。归还后,对象被缓存复用,外部不再持有引用。如果需要一种轻量级的全局标识——比如用一个整数而非指针来跨模块、跨线程、甚至跨网络引用一个对象——ObjectPool 就无能为力了。
brpc 的 butil::ResourcePool 正是为这种场景设计的。它在 ObjectPool 的架构基础上增加了 ResourceId 机制,每个对象拥有全局唯一的 64 位 ID,任何时候都可通过 ID 在 O(1) 时间内定位到对象地址。
本文从源码出发,拆解 ResourcePool 的设计,重点分析它与 ObjectPool 的异同。
一、ResourcePool 是什么?
ResourcePool 与 ObjectPool 的架构几乎相同——同样采用 LocalPool(线程本地)+ BlockGroup(全局索引)+ FreeChunk(空闲列表)的三层结构,同样通过 TLS 实现无锁分配。
核心区别只有一个:ResourcePool 为每个对象分配全局唯一的 ResourceId。
这意味着:
- 获取资源时,同时返回对象指针和 ResourceId
- 任何时候都可通过 ResourceId 在 O(1) 内定位对象
二、ResourceId:64 位编码
template <typename T>struct ResourceId { uint64_t value; // 全局唯一标识符};
ResourceId 的 value 编码了对象在三级索引中的位置:value = block_index × BLOCK_NITEM + offset_in_block
其中:
block_index:Block 在全局中的序号(通过二级索引进一步分解)offset_in_block
解码过程:
block_index = value / BLOCK_NITEMgroup_index = block_index >> 16 // 高位 → BlockGroup 编号block_in_group = block_index & 0xFFFF // 低位 → BlockGroup 内的槽位offset = value - block_index × BLOCK_NITEM
这种编码让 ID 既紧凑(仅 8 字节)又高效——解码只需几次位运算和除法。
ResourceId 还提供了类型安全的转换:
template <typename T2>ResourceId<T2> cast()const{ ResourceId<T2> id = { value }; return id;}
用于不同类型资源池之间的 ID 传递(值不变,仅类型包装改变)。
三、整体架构
与 ObjectPool 相同的三层结构:
ResourcePool<T>(全局单例) ├─ LocalPool(线程本地,每线程一个) │ ├─ _cur_block ← 当前 Block(线程独占,无锁分配) │ └─ _cur_free ← 本地 FreeChunk(存储 ResourceId,而非 T*) ├─ BlockGroup[](全局 Block 索引) │ └─ Block*[](每个 BlockGroup 管理 65536 个 Block) └─ _free_chunks(全局空闲列表,存储 ResourceId)
Block、BlockGroup、LocalPool 的定义与 ObjectPool 几乎完全一致(BlockItem 对齐存储、Block 缓存行对齐、BlockGroup 二级索引、LocalPool TLS 线程本地等),此处不再赘述。下面重点分析与 ObjectPool 不同的部分。
四、FreeChunk:存储 ID 而非指针
template <typename T, size_t NITEM>struct ResourcePoolFreeChunk { size_t nfree; // 当前空闲 ID 数量 ResourceId<T> ids[NITEM]; // 空闲资源 ID 数组(注意:是 ID,不是指针)};
与 ObjectPool 的 FreeChunk 对比:
| | |
|---|
| T* ptrs[] | ResourceId<T> ids[] |
| | |
| | |
为什么用 ID 而非指针?因为 ID 是稳定的——对象在 Block 中的位置从不改变(Block 创建后不移动),ID 编码了位置信息。即使对象被归还再重新分配,同一个 ID 始终指向同一块内存。
同样有 DynamicFreeChunk 变体(柔性数组),用于全局空闲列表中变长的 FreeChunk 存储。
五、获取资源:get_resource
与 ObjectPool 的 get() 类似的四级优先级,但每个分支都需要同时处理 ID:
1. 本地 FreeChunk ──→ 2. 全局 FreeChunk ──→ 3. 本地 Block ──→ 4. 新建 Block (无锁) (加锁) (无锁) (原子操作)
第一级:本地 FreeChunk(最快,无锁)
if (_cur_free.nfree) { const ResourceId<T> free_id = _cur_free.ids[--_cur_free.nfree]; *id = free_id; // 输出 ID return unsafe_address_resource(free_id); // 通过 ID 定位对象}
注意这里与 ObjectPool 的区别:ObjectPool 直接返回 ptrs[] 中的指针,而 ResourcePool 取出的是 ID,需要通过 unsafe_address_resource 转换为指针。if (_pool->pop_free_chunk(_cur_free)) { --_cur_free.nfree; const ResourceId<T> free_id = _cur_free.ids[_cur_free.nfree]; *id = free_id; return unsafe_address_resource(free_id);}
第三级:本地 Block(placement new,生成新 ID)if (_cur_block && _cur_block->nitem < BLOCK_NITEM) { // 计算新对象的 ID id->value = _cur_block_index * BLOCK_NITEM + _cur_block->nitem; auto item = _cur_block->items + _cur_block->nitem; p = new (item->void_data()) T; if (!ResourcePoolValidator<T>::validate(p)) { p->~T(); return NULL; } ++_cur_block->nitem; return p;}
这是与 ObjectPool 的关键差异之一:从 Block 分配新对象时,需要计算并生成新的 ResourceId。ID 的值由 Block 的全局索引和对象在 Block 内的偏移共同决定。
此外,ResourcePool 增加了 ResourcePoolValidator 验证步骤——构造后检查对象是否有效(如构造函数内部 ENOMEM 失败),无效则立即析构并返回 NULL。ObjectPool 没有这个机制。
第四级:新建 Block
当前 Block 已满时,调用 add_block 创建新 Block,再从中分配第一个对象并生成 ID。
六、归还资源:return_resource
归还资源 ├─ 本地 FreeChunk 未满 → 直接放入 ID(无锁) └─ 本地 FreeChunk 已满 → 整批推送全局 → 放入清空后的本地 FreeChunk
inline int return_resource(ResourceId<T> id) { // 优先放回本地 FreeChunk(无锁,最快路径) if (_cur_free.nfree < ResourcePool::free_chunk_nitem()) { _cur_free.ids[_cur_free.nfree++] = id; // 存储 ID,而非指针 return 0; } // 本地已满,推送到全局 if (_pool->push_free_chunk(_cur_free)) { _cur_free.nfree = 1; _cur_free.ids[0] = id; return 0; } return -1;}
与 ObjectPool 的 return_object() 流程一致,区别仅在于存储的是 ID 而非指针。归还 ID 意味着调用者不需要持有对象指针——只需持有 8 字节的 ID,后续需要时再通过 address_resource 获取指针。
七、address_resource:O(1) 定位对象
这是 ResourcePool 的核心能力——通过 ID 在 O(1) 时间内定位对象。有两个版本:
7.1 unsafe_address_resource(无安全检查,快速路径)
staticinline T* unsafe_address_resource(ResourceId<T> id){ const size_t block_index = id.value / BLOCK_NITEM; return (T*)(_block_groups[(block_index >> RP_GROUP_NBLOCK_NBIT)] .load(butil::memory_order_consume) ->blocks[(block_index & (RP_GROUP_NBLOCK - 1))] .load(butil::memory_order_consume)->items) + id.value - block_index * BLOCK_NITEM;}
整个过程:一次除法 + 两次位运算 + 三次数组索引 + 一次指针加法,全部 O(1),无任何分支判断。
解码链路:
ResourceId.value │ ├─ block_index = value / BLOCK_NITEM │ │ │ ├─ group_index = block_index >> 16 │ │ └─ _block_groups[group_index] → BlockGroup* │ │ │ └─ block_in_group = block_index & 0xFFFF │ └─ BlockGroup->blocks[block_in_group] → Block* │ └─ offset = value - block_index × BLOCK_NITEM └─ Block->items + offset → T*
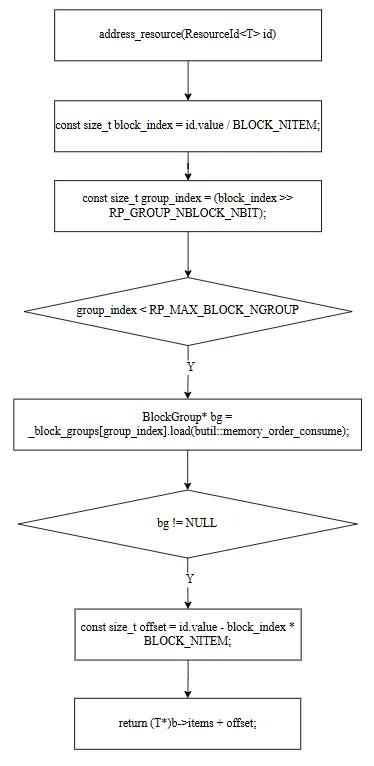
7.2 address_resource(带边界检查)
staticinline T* address_resource(ResourceId<T> id){ const size_t block_index = id.value / BLOCK_NITEM; const size_t group_index = (block_index >> RP_GROUP_NBLOCK_NBIT); if (__builtin_expect(group_index < RP_MAX_BLOCK_NGROUP, 1)) { BlockGroup* bg = _block_groups[group_index].load(butil::memory_order_consume); if (__builtin_expect(bg != NULL, 1)) { Block* b = bg->blocks[block_index & (RP_GROUP_NBLOCK - 1)] .load(butil::memory_order_consume); if (__builtin_expect(b != NULL, 1)) { const size_t offset = id.value - block_index * BLOCK_NITEM; if (__builtin_expect(offset < b->nitem, 1)) { return (T*)b->items + offset; } } } } return NULL; // ID 无效}
依次验证 group_index → BlockGroup → Block → offset 的有效性。四处 __builtin_expect 标记正常路径,让 CPU 分支预测更准确。返回 NULL 表示 ID 无效(未分配或超出范围)。
注意:已归还(空闲)的 ID 仍然返回非 NULL——因为 Block 和其中的对象内存仍然存在,只是该 ID 被标记为可复用。
八、与 ObjectPool 的异同对比
相同点
| |
|---|
| LocalPool + BlockGroup + 全局 FreeChunk |
| |
| |
| |
| Block、LocalPool 均 64 字节对齐 |
| thread_atexit 自动清理,最后一个线程可回收全局资源 |
| 全局 ObjectPool/ResourcePool 实例通过双检锁创建 |
| fetch_add 原子预占位 + BlockGroup 扩容 |
不同点
| | |
|---|
| | |
| T* | ResourceId<T> |
| T* | ResourceId<T> |
| | address_resource |
| | 返回 T* + 输出参数 ResourceId<T>* |
| | ResourcePoolValidator |
| | |
什么时候用哪个?
- ObjectPool:只需要分配和归还对象,通过指针直接访问。适用于 RPC Context、临时对象等短生命周期场景。
- ResourcePool:需要全局唯一标识符,或需要跨模块/跨线程以轻量级方式引用对象的场景。典型如 bthread 的 TaskMeta——调度器通过 bthread ID 在 O(1) 时间内定位到对应的 TaskMeta 结构。
九、总结
ResourcePool 的设计可以归纳为一句话:在 ObjectPool 的无锁分配基础上,增加了 ID 索引机制,实现了 O(1) 的 ID→对象寻址。
三个关键设计:
1. 紧凑的 ID 编码。 ResourceId 仅 8 字节,编码了 group_index + block_in_group + offset 三级位置信息。传递 ID 比传递指针更轻量,且不受对象生命周期影响——ID 始终指向固定的内存位置。
2. O(1) 寻址。 通过二级索引(BlockGroup → Block → offset),几次位运算和数组索引即可从 ID 定位到对象。快速路径(unsafe_address_resource)无任何分支判断,适合热路径调用。
3. 与 ObjectPool 共享架构,最小化新代码。 LocalPool、Block、BlockGroup 的设计完全复用 ObjectPool 的模式,仅在需要处理 ID 的地方做调整——FreeChunk 存 ID 而非指针、get 时计算并输出 ID、return 时归还 ID。这意味着 ObjectPool 的全部性能优势(无锁分配、批量搬运、零碎片)同样适用于 ResourcePool。
这套设计让 brpc 在需要全局标识的场景下(如 bthread 调度),既能享受对象池的性能,又能通过 ID 高效索引——这是 brpc 高并发能力的又一个基石。
本文基于 Apache brpc 源码(src/butil/resource_pool.h、src/butil/resource_pool_inl.h)撰写。