DeepSeek V4架构学习笔记~
- 2026-04-28 14:20:07
✅我是丁师兄,专注于智能驾驶大模型,持续分享LLM面试干货。
✅大模型1v1辅导,已帮助多名同学成功上岸
offer捷报
恭喜学员拿下大模型独角兽月之暗面offer,总包60w+。从最开始面试被卡,回来做面试复盘,每场面试都录音回听,补齐短板。训练营这边,我布置的实战作业一个都没有落下,项目手动复现吃透。
上岸靠的不是运气,而是方法+强度,逼你在实战中,一步步把能力练出来!!~需要大模型1v1辅导的同学快上车哦~
本人做大模型推理方向,因此本文着重在 DeepSeek V4 推理相关内容,训练相关内容略过。
01
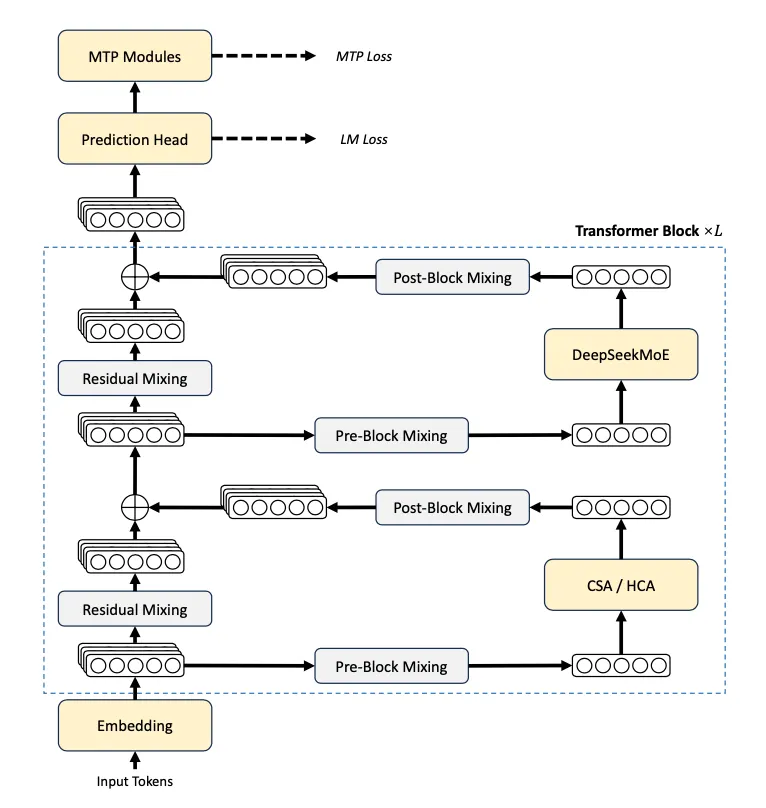
架构
02
继承自 DeepSeek V3 的组件
DeepSeekMoE:激活函数从 Sigmoid(.) 改为 Sqrt(Softplus(.));移除 V3 中前几个 Dense 层,全部采用 MoE(Hash 路由)。
MTP:与V3保持一致。
mHC
mHC 的核心思想是将残差映射约束到特定的流形上,在保持模型表达能力的同时,增强信号在各层间传播的稳定性。
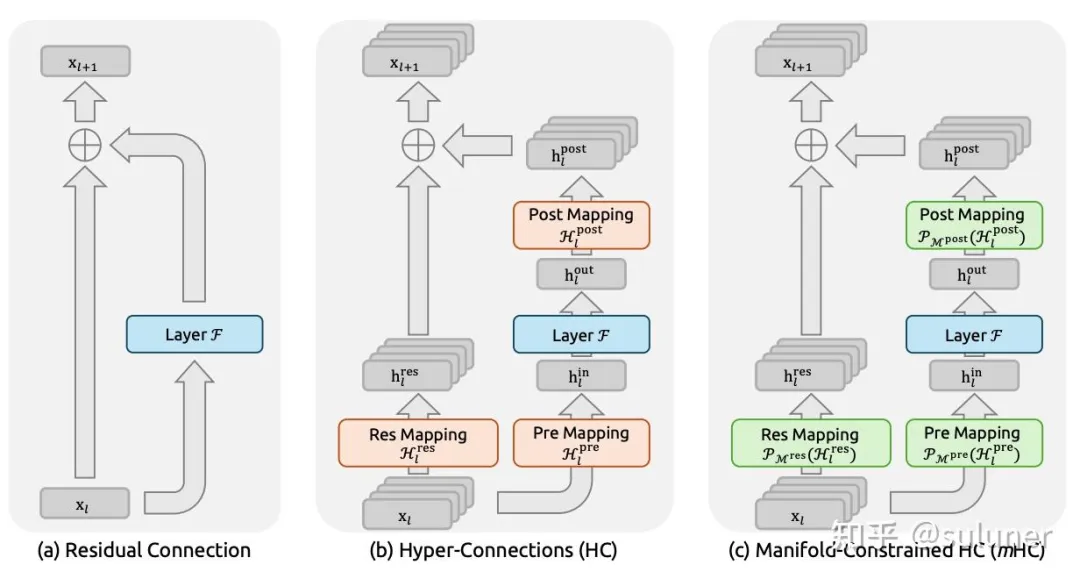
mHC 的思想源自字节 HC,HC 的思路是:
主路拓宽 n 倍,主路上有 res map 融合映射
Layer 前后映射回 C 维,计算量不变
n=1,H=1 就是 ResNet
HC 证明拓宽主路能增加模型容量,提升模型效果。
HC 存在的问题:
多层传递会有累乘项
累乘项分布没有任何约束,失去了残差直连语义。对比 ResNet
激活值梯度传递发散,大规模训练不稳定
更直观点,Hres 累乘项幅值爆炸
虽然旁路计算 flops 没增加,但是主路访存增大 n 倍,mapping 引入额外访存(不做 fuse 的话)
mHC 提出流形约束解决 HC 的问题:
将 res map 映射矩阵限制为双随机矩阵的流形空间
一来可以提升前向反向的数据稳定性
二来映射矩阵对乘法是封闭的,保证了在深度堆叠的模型结构中的稳定性
mHC 具体内容可以参考论文:
https://arxiv.org/pdf/2512.2488003
CSA&HCA 混合注意力机制
使用 CSA 和 HCA 交替混合配置。
CSA
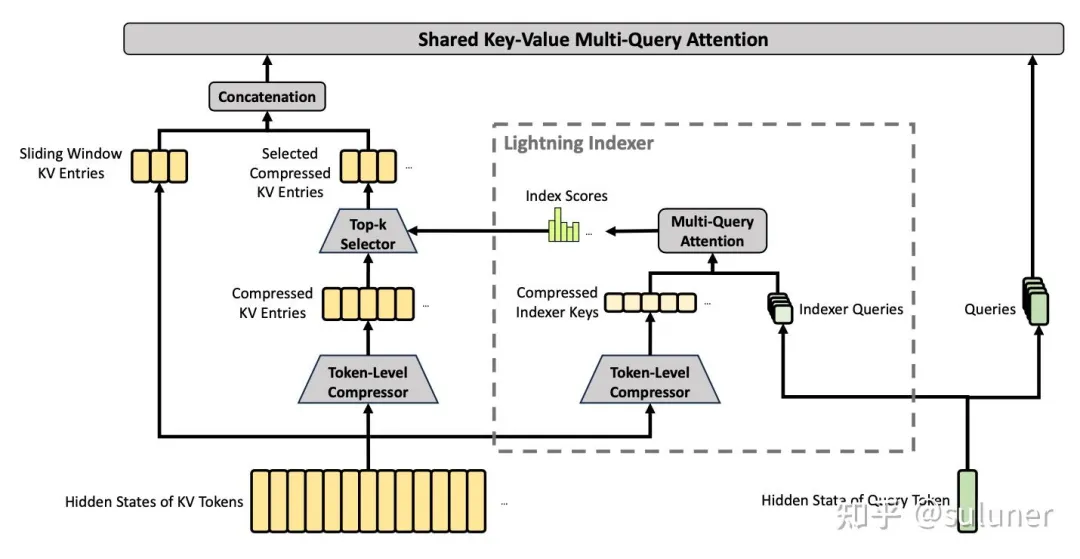
CSA 结合了 KV-Cache 压缩和稀疏 Attention 策略:
KV-Cache 压缩:每 m 个 token 的 KV-Cache 压缩为一份 KV-Cache
DSA:对压缩后的 KV-Cache 应用 DSA 稀疏注意力机制
HCA
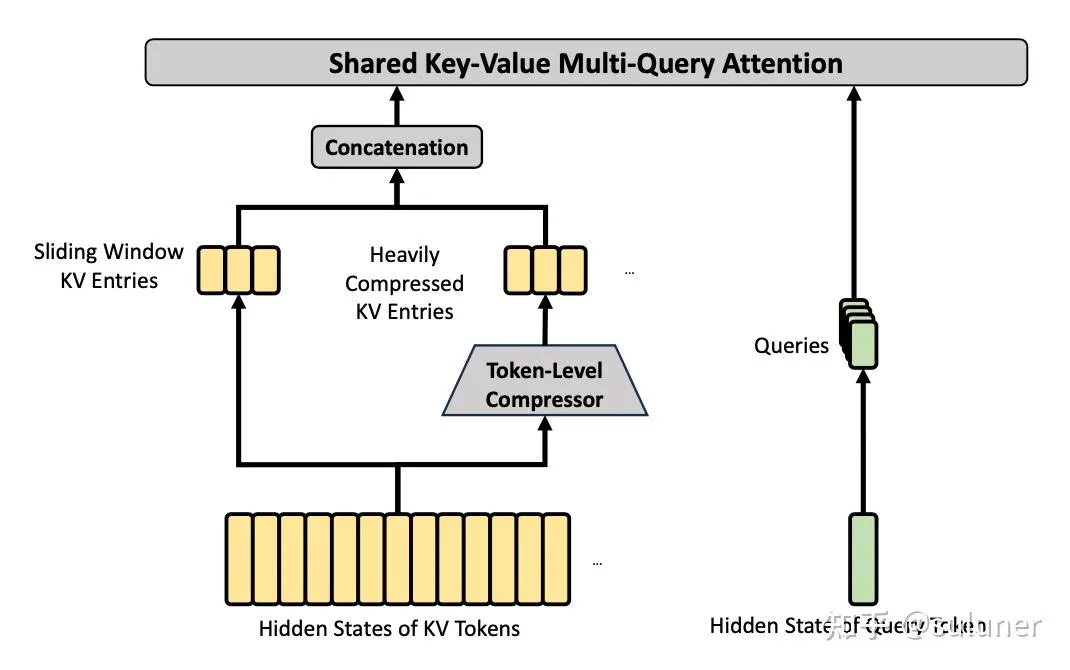
HCA 使用比 CSA 更高的压缩率压缩 KV-Cache,不使用稀疏 Attention 机制。
效率考虑
KV-Cache 混合格式存储:BF16 存储 ROPE 维度,FP8 存储 NOPE 维度
Lightning Indexer 中的 Attention 用 FP4 计算
对比 V3,选用更小的 TOPK 值
Muon Optimizer
通用基础设施
专家并行中的通算掩盖
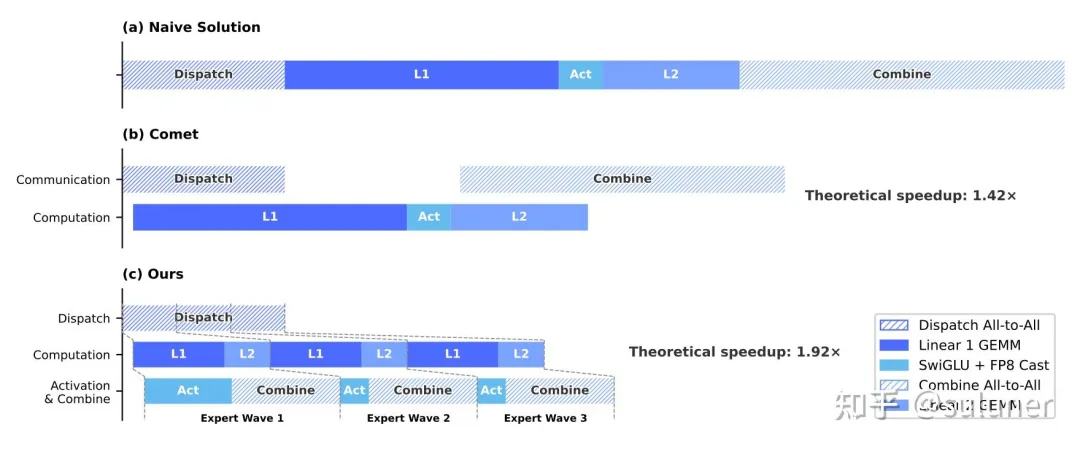
核心思想是将专家分为不同的 wave,一旦本 wave 的专家通信或者计算结束,无需等待其他专家,马上开始下一阶段的工作,达到通信和计算并行的效果。
基于 TileLang 的灵活高效算子开发
TileLang 开发算子兼顾了开发效率和算子性能,DS 团队对 TileLang 有很多定制优化。
高性能 Batch-Invariant 和确定性算子库
Batch-Invariant
Attention
不能使用 Split-KV 的方式将一个序列放在不同的 SM 上计算。为了解决 wave 量化问题,使用双-Kernel 策略:
第一个 Kernel 在单个 SM 上计算完整序列,第二个 Kernel 使用部分占用的 wave,在多个 SM 上以最低延时计算完整的序列。
为了保证 bitwise 相同,第二个 Kernel 计算顺序需要保证和第一个 Kernel 一致。
MatMul
使用 DeepGEMM 全面替代 cuBLAS。
对于小 batch size,弃用 split-k 计算策略,使用其他方式优化性能。
确定性
计算结果不确定性通常由不确定的累加顺序引起的,比如使用 atomic add 指令。
Attention Backward:为每个 SM 分配单独的累加 buffer,全局确定性顺序累加。
MoE Backward:来自不同 rank 的多个 SM 同时向接收 rank 的 buffer 写入数据会引起不确定性。
解决方案:在每个 rank 内使用 token 顺序预处理机制,并且配备独立的 buffer。
mHC 中的 MatMul:mHC 中的 MatMul 输出维度很小 (24),必须使用 split-k 机制。为了解决这个问题,分别输出部分结果并且在另一个算子中以确定的顺序 reduce。
04
FP4 量化感知训练
MoE 权重。
CSA indexer 中的 QK 计算路径,QK 激活值以 FP4 缓存,加载,计算。
另外,Indexer score,从 FP32 量化到 BF16。
训练框架
推理框架
KV-Cache 结构和管理
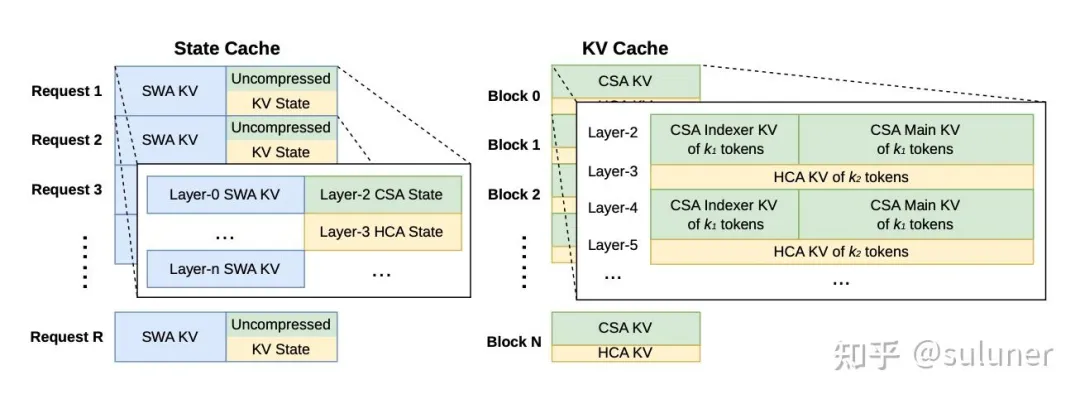
KV-Cache 分为 State Cache 和经典 KV-Cache。
State Cache
在 State Cache 中,每个请求分配的 state cache 空间是固定大小的。
一部分用来存储 nwin 个 token 的滑动窗口 KV-Cache,另一部分用来存储 CSA 和 HCA 的尾块 token 的 KV-Cache 值。
以 DeepSeek-V4-Flash 为例,滑动窗口为 128,CSA 压缩率为 4,HCA 压缩率为 128。
那么对于每个请求,需要分配 128 个 token 的滑动窗口 KV-Cache 空间,4 个 token 的 CSA 未压缩 KV-Cache 空间,128 个 token 的 HCA 未压缩 KV-Cache 空间。
05
经典 KV-Cache
在经典 KV-Cache 中,每个请求分配多个 block。每个 block 覆盖 lcm(m, m’) 个原始 token。
其中 lcm 是最小公倍数的意思,还是以 DeepSeek-V4-Flash 为例,CSA 压缩率为 m=4,HCA 压缩率为 m’=128,那么最小公倍数 lcm(m, m’)=128。
每个 block 中包含 lcm(m, m’)/m = 32 个 CSA indexer KV-Cache,32 个 CSA 主 KV-Cache;包含 lcm(m,m’)/m’ = 1个HCA KV-Cache。
稀疏 Attention Kernel co-design
为了保证稀疏 Attention Kernel 计算的效率,每个 block 覆盖的原始 token 数量是 lcm(m, m’) 的整数倍。
Disk KV-Cache 存储
CSA 和 HCA 压缩 KV-Cache
将所有压缩后的 KV-Cache 存储到磁盘上。当请求命中 prefix-cache 之后,直接从磁盘读取压缩后的 KV-Cache,对于未压缩的尾块 CSA 和 HCA KV-Cache 则进行重算,因为尾块的 KV-Cache 没有保存。
SWA 滑动窗口 KV-Cache
对于滑动窗口的 KV-Cache,由于没有进行压缩,并且每层都有,体量比较大,为了平衡存储开销和计算延迟,提供了三种策略:
SWA 全缓存:Cache 所有 token 的滑动窗口 KV-Cache,无需计算,但是对存储系统不友好。
周期性 Checkpoint:每 p 个 token 缓存最后 nwin token 的 KVCache。
当 prefix 命中后,读取最近的 checkpoint,并且重计算剩下的尾块 KV-Cache 值。通过调节 p 值,可以在存储和计算间进行平衡。
SWA 不缓存:完全不缓存 KV-Cache,命中 prefix-cache 之后,重算 nwin 个 token 的滑动窗口 KV-Cache。
作者:suluner,已获作者授权发布
来源:https://zhuanlan.zhihu.com/p/2031401308553487387
✅我是丁师兄,专注于智能驾驶大模型,持续分享LLM面试干货。
✅大模型1v1辅导,已帮助多名同学成功上岸
微信:dsxaigc


