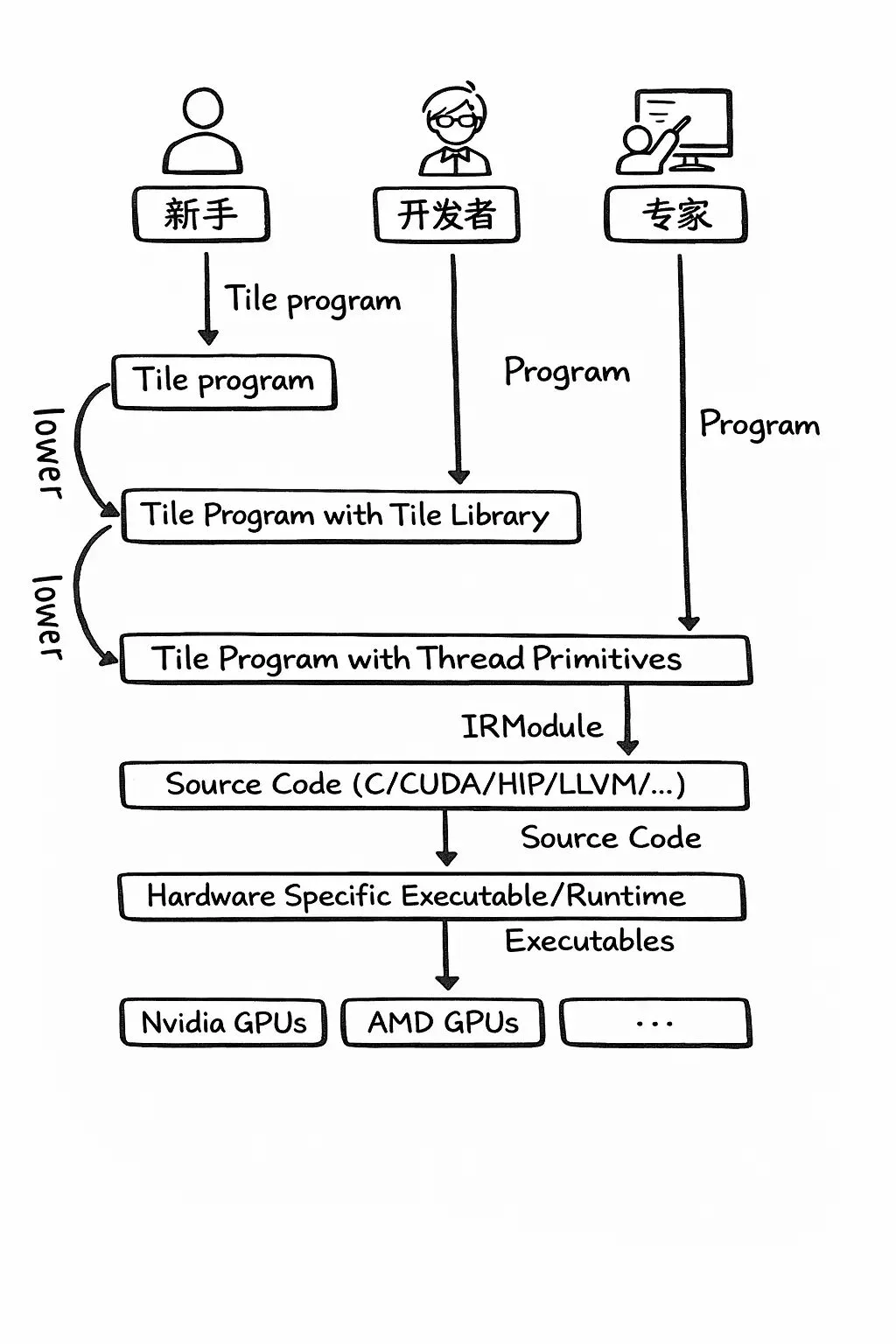
importtilelang
importtilelang.languageasT
fromtilelangimport jit
@jit # infers target from tensors at first call
defadd(N: int, block: int = 256, dtype: str = 'float32'):
@T.prim_func
defadd_kernel(
A: T.Tensor((N,), dtype),
B: T.Tensor((N,), dtype),
C: T.Tensor((N,), dtype),
):
with T.Kernel(T.ceildiv(N, block), threads=block) as bx:
for i in T.Parallel(block):
gi = bx * block + i
# Optional — LegalizeSafeMemoryAccess inserts a guard when an access may be OOB
C[gi] = A[gi] + B[gi]
return add_kernel
# Host side (PyTorch shown; NumPy/DLPack also supported)
importtorch
N = 1 << 20
A = torch.randn(N, device='cuda', dtype=torch.float32)
B = torch.randn(N, device='cuda', dtype=torch.float32)
C = torch.empty(N, device='cuda', dtype=torch.float32)
kernel = add(N)
kernel(A, B, C) # runs on GPU
torch.testing.assert_close(C, A + B)